

Effective Use of Tables and Figures in Research Papers
Research papers are often based on copious amounts of data that can be summarized and easily read through tables and graphs. When writing a research paper , it is important for data to be presented to the reader in a visually appealing way. The data in figures and tables, however, should not be a repetition of the data found in the text. There are many ways of presenting data in tables and figures, governed by a few simple rules. An APA research paper and MLA research paper both require tables and figures, but the rules around them are different. When writing a research paper, the importance of tables and figures cannot be underestimated. How do you know if you need a table or figure? The rule of thumb is that if you cannot present your data in one or two sentences, then you need a table .
Using Tables
Tables are easily created using programs such as Excel. Tables and figures in scientific papers are wonderful ways of presenting data. Effective data presentation in research papers requires understanding your reader and the elements that comprise a table. Tables have several elements, including the legend, column titles, and body. As with academic writing, it is also just as important to structure tables so that readers can easily understand them. Tables that are disorganized or otherwise confusing will make the reader lose interest in your work.
- Title: Tables should have a clear, descriptive title, which functions as the “topic sentence” of the table. The titles can be lengthy or short, depending on the discipline.
- Column Titles: The goal of these title headings is to simplify the table. The reader’s attention moves from the title to the column title sequentially. A good set of column titles will allow the reader to quickly grasp what the table is about.
- Table Body: This is the main area of the table where numerical or textual data is located. Construct your table so that elements read from up to down, and not across.
Related: Done organizing your research data effectively in tables? Check out this post on tips for citing tables in your manuscript now!
The placement of figures and tables should be at the center of the page. It should be properly referenced and ordered in the number that it appears in the text. In addition, tables should be set apart from the text. Text wrapping should not be used. Sometimes, tables and figures are presented after the references in selected journals.
Using Figures
Figures can take many forms, such as bar graphs, frequency histograms, scatterplots, drawings, maps, etc. When using figures in a research paper, always think of your reader. What is the easiest figure for your reader to understand? How can you present the data in the simplest and most effective way? For instance, a photograph may be the best choice if you want your reader to understand spatial relationships.
- Figure Captions: Figures should be numbered and have descriptive titles or captions. The captions should be succinct enough to understand at the first glance. Captions are placed under the figure and are left justified.
- Image: Choose an image that is simple and easily understandable. Consider the size, resolution, and the image’s overall visual attractiveness.
- Additional Information: Illustrations in manuscripts are numbered separately from tables. Include any information that the reader needs to understand your figure, such as legends.
Common Errors in Research Papers
Effective data presentation in research papers requires understanding the common errors that make data presentation ineffective. These common mistakes include using the wrong type of figure for the data. For instance, using a scatterplot instead of a bar graph for showing levels of hydration is a mistake. Another common mistake is that some authors tend to italicize the table number. Remember, only the table title should be italicized . Another common mistake is failing to attribute the table. If the table/figure is from another source, simply put “ Note. Adapted from…” underneath the table. This should help avoid any issues with plagiarism.
Using tables and figures in research papers is essential for the paper’s readability. The reader is given a chance to understand data through visual content. When writing a research paper, these elements should be considered as part of good research writing. APA research papers, MLA research papers, and other manuscripts require visual content if the data is too complex or voluminous. The importance of tables and graphs is underscored by the main purpose of writing, and that is to be understood.
Frequently Asked Questions
"Consider the following points when creating figures for research papers: Determine purpose: Clarify the message or information to be conveyed. Choose figure type: Select the appropriate type for data representation. Prepare and organize data: Collect and arrange accurate and relevant data. Select software: Use suitable software for figure creation and editing. Design figure: Focus on clarity, labeling, and visual elements. Create the figure: Plot data or generate the figure using the chosen software. Label and annotate: Clearly identify and explain all elements in the figure. Review and revise: Verify accuracy, coherence, and alignment with the paper. Format and export: Adjust format to meet publication guidelines and export as suitable file."
"To create tables for a research paper, follow these steps: 1) Determine the purpose and information to be conveyed. 2) Plan the layout, including rows, columns, and headings. 3) Use spreadsheet software like Excel to design and format the table. 4) Input accurate data into cells, aligning it logically. 5) Include column and row headers for context. 6) Format the table for readability using consistent styles. 7) Add a descriptive title and caption to summarize and provide context. 8) Number and reference the table in the paper. 9) Review and revise for accuracy and clarity before finalizing."
"Including figures in a research paper enhances clarity and visual appeal. Follow these steps: Determine the need for figures based on data trends or to explain complex processes. Choose the right type of figure, such as graphs, charts, or images, to convey your message effectively. Create or obtain the figure, properly citing the source if needed. Number and caption each figure, providing concise and informative descriptions. Place figures logically in the paper and reference them in the text. Format and label figures clearly for better understanding. Provide detailed figure captions to aid comprehension. Cite the source for non-original figures or images. Review and revise figures for accuracy and consistency."
"Research papers use various types of tables to present data: Descriptive tables: Summarize main data characteristics, often presenting demographic information. Frequency tables: Display distribution of categorical variables, showing counts or percentages in different categories. Cross-tabulation tables: Explore relationships between categorical variables by presenting joint frequencies or percentages. Summary statistics tables: Present key statistics (mean, standard deviation, etc.) for numerical variables. Comparative tables: Compare different groups or conditions, displaying key statistics side by side. Correlation or regression tables: Display results of statistical analyses, such as coefficients and p-values. Longitudinal or time-series tables: Show data collected over multiple time points with columns for periods and rows for variables/subjects. Data matrix tables: Present raw data or matrices, common in experimental psychology or biology. Label tables clearly, include titles, and use footnotes or captions for explanations."

Enago is a very useful site. It covers nearly all topics of research writing and publishing in a simple, clear, attractive way. Though I’m a journal editor having much knowledge and training in these issues, I always find something new in this site. Thank you
“Thank You, your contents really help me :)”
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles

- Reporting Research
Explanatory & Response Variable in Statistics — A quick guide for early career researchers!
Often researchers have a difficult time choosing the parameters and variables (like explanatory and response…

- Manuscript Preparation
- Publishing Research
How to Use Creative Data Visualization Techniques for Easy Comprehension of Qualitative Research
“A picture is worth a thousand words!”—an adage used so often stands true even whilst…

- Figures & Tables
Effective Use of Statistics in Research – Methods and Tools for Data Analysis
Remember that impending feeling you get when you are asked to analyze your data! Now…
- Old Webinars
- Webinar Mobile App
SCI中稿技巧: 提升研究数据的说服力
如何寻找原创研究课题 快速定位目标文献的有效搜索策略 如何根据期刊指南准备手稿的对应部分 论文手稿语言润色实用技巧分享,快速提高论文质量

Distill: A Journal With Interactive Images for Machine Learning Research
Research is a wide and extensive field of study. This field has welcomed a plethora…
Explanatory & Response Variable in Statistics — A quick guide for early career…
How to Create and Use Gantt Charts

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

What should universities' stance be on AI tools in research and academic writing?

- Manuscript Preparation
How to Use Tables and Figures effectively in Research Papers
- 3 minute read
- 42.9K views
Table of Contents
Data is the most important component of any research. It needs to be presented effectively in a paper to ensure that readers understand the key message in the paper. Figures and tables act as concise tools for clear presentation . Tables display information arranged in rows and columns in a grid-like format, while figures convey information visually, and take the form of a graph, diagram, chart, or image. Be it to compare the rise and fall of GDPs among countries over the years or to understand how COVID-19 has impacted incomes all over the world, tables and figures are imperative to convey vital findings accurately.
So, what are some of the best practices to follow when creating meaningful and attractive tables and figures? Here are some tips on how best to present tables and figures in a research paper.
Guidelines for including tables and figures meaningfully in a paper:
- Self-explanatory display items: Sometimes, readers, reviewers and journal editors directly go to the tables and figures before reading the entire text. So, the tables need to be well organized and self-explanatory.
- Avoidance of repetition: Tables and figures add clarity to the research. They complement the research text and draw attention to key points. They can be used to highlight the main points of the paper, but values should not be repeated as it defeats the very purpose of these elements.
- Consistency: There should be consistency in the values and figures in the tables and figures and the main text of the research paper.
- Informative titles: Titles should be concise and describe the purpose and content of the table. It should draw the reader’s attention towards the key findings of the research. Column heads, axis labels, figure labels, etc., should also be appropriately labelled.
- Adherence to journal guidelines: It is important to follow the instructions given in the target journal regarding the preparation and presentation of figures and tables, style of numbering, titles, image resolution, file formats, etc.
Now that we know how to go about including tables and figures in the manuscript, let’s take a look at what makes tables and figures stand out and create impact.
How to present data in a table?
For effective and concise presentation of data in a table, make sure to:
- Combine repetitive tables: If the tables have similar content, they should be organized into one.
- Divide the data: If there are large amounts of information, the data should be divided into categories for more clarity and better presentation. It is necessary to clearly demarcate the categories into well-structured columns and sub-columns.
- Keep only relevant data: The tables should not look cluttered. Ensure enough spacing.
Example of table presentation in a research paper

For comprehensible and engaging presentation of figures:
- Ensure clarity: All the parts of the figure should be clear. Ensure the use of a standard font, legible labels, and sharp images.
- Use appropriate legends: They make figures effective and draw attention towards the key message.
- Make it precise: There should be correct use of scale bars in images and maps, appropriate units wherever required, and adequate labels and legends.
It is important to get tables and figures correct and precise for your research paper to convey your findings accurately and clearly. If you are confused about how to suitably present your data through tables and figures, do not worry. Elsevier Author Services are well-equipped to guide you through every step to ensure that your manuscript is of top-notch quality.

- Research Process
What is a Problem Statement? [with examples]

What is the Background of a Study and How Should it be Written?
You may also like.

Make Hook, Line, and Sinker: The Art of Crafting Engaging Introductions

Can Describing Study Limitations Improve the Quality of Your Paper?

A Guide to Crafting Shorter, Impactful Sentences in Academic Writing

6 Steps to Write an Excellent Discussion in Your Manuscript

How to Write Clear and Crisp Civil Engineering Papers? Here are 5 Key Tips to Consider

The Clear Path to An Impactful Paper: ②

The Essentials of Writing to Communicate Research in Medicine

Changing Lines: Sentence Patterns in Academic Writing
Input your search keywords and press Enter.
How to Present Results in a Research Paper
- First Online: 01 October 2023
Cite this chapter

- Aparna Mukherjee 4 ,
- Gunjan Kumar 4 &
- Rakesh Lodha 5
689 Accesses
The results section is the core of a research manuscript where the study data and analyses are presented in an organized, uncluttered manner such that the reader can easily understand and interpret the findings. This section is completely factual; there is no place for opinions or explanations from the authors. The results should correspond to the objectives of the study in an orderly manner. Self-explanatory tables and figures add value to this section and make data presentation more convenient and appealing. The results presented in this section should have a link with both the preceding methods section and the following discussion section. A well-written, articulate results section lends clarity and credibility to the research paper and the study as a whole. This chapter provides an overview and important pointers to effective drafting of the results section in a research manuscript and also in theses.
This is a preview of subscription content, log in via an institution to check access.
Access this chapter
- Available as PDF
- Read on any device
- Instant download
- Own it forever
- Available as EPUB and PDF
- Durable hardcover edition
- Dispatched in 3 to 5 business days
- Free shipping worldwide - see info
Tax calculation will be finalised at checkout
Purchases are for personal use only
Institutional subscriptions
Kallestinova ED (2011) How to write your first research paper. Yale J Biol Med 84(3):181–190
PubMed PubMed Central Google Scholar
STROBE. STROBE. [cited 2022 Nov 10]. https://www.strobe-statement.org/
Consort—Welcome to the CONSORT Website. http://www.consort-statement.org/ . Accessed 10 Nov 2022
Korevaar DA, Cohen JF, Reitsma JB, Bruns DE, Gatsonis CA, Glasziou PP et al (2016) Updating standards for reporting diagnostic accuracy: the development of STARD 2015. Res Integr Peer Rev 1(1):7
Article PubMed PubMed Central Google Scholar
Page MJ, McKenzie JE, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD et al (2021) The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ 372:n71
Page MJ, Moher D, Bossuyt PM, Boutron I, Hoffmann TC, Mulrow CD et al (2021) PRISMA 2020 explanation and elaboration: updated guidance and exemplars for reporting systematic reviews. BMJ 372:n160
Consolidated criteria for reporting qualitative research (COREQ): a 32-item checklist for interviews and focus groups | EQUATOR Network. https://www.equator-network.org/reporting-guidelines/coreq/ . Accessed 10 Nov 2022
Aggarwal R, Sahni P (2015) The results section. In: Aggarwal R, Sahni P (eds) Reporting and publishing research in the biomedical sciences, 1st edn. National Medical Journal of India, Delhi, pp 24–44
Google Scholar
Mukherjee A, Lodha R (2016) Writing the results. Indian Pediatr 53(5):409–415
Article PubMed Google Scholar
Lodha R, Randev S, Kabra SK (2016) Oral antibiotics for community acquired pneumonia with chest indrawing in children aged below five years: a systematic review. Indian Pediatr 53(6):489–495
Anderson C (2010) Presenting and evaluating qualitative research. Am J Pharm Educ 74(8):141
Roberts C, Kumar K, Finn G (2020) Navigating the qualitative manuscript writing process: some tips for authors and reviewers. BMC Med Educ 20:439
Bigby C (2015) Preparing manuscripts that report qualitative research: avoiding common pitfalls and illegitimate questions. Aust Soc Work 68(3):384–391
Article Google Scholar
Vincent BP, Kumar G, Parameswaran S, Kar SS (2019) Barriers and suggestions towards deceased organ donation in a government tertiary care teaching hospital: qualitative study using socio-ecological model framework. Indian J Transplant 13(3):194
McCormick JB, Hopkins MA (2021) Exploring public concerns for sharing and governance of personal health information: a focus group study. JAMIA Open 4(4):ooab098
Groenland -emeritus professor E. Employing the matrix method as a tool for the analysis of qualitative research data in the business domain. Rochester, NY; 2014. https://papers.ssrn.com/abstract=2495330 . Accessed 10 Nov 2022
Download references
Acknowledgments
The book chapter is derived in part from our article “Mukherjee A, Lodha R. Writing the Results. Indian Pediatr. 2016 May 8;53(5):409-15.” We thank the Editor-in-Chief of the journal “Indian Pediatrics” for the permission for the same.
Author information
Authors and affiliations.
Clinical Studies, Trials and Projection Unit, Indian Council of Medical Research, New Delhi, India
Aparna Mukherjee & Gunjan Kumar
Department of Pediatrics, All India Institute of Medical Sciences, New Delhi, India
Rakesh Lodha
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Rakesh Lodha .
Editor information
Editors and affiliations.
Retired Senior Expert Pharmacologist at the Office of Cardiology, Hematology, Endocrinology, and Nephrology, Center for Drug Evaluation and Research, US Food and Drug Administration, Silver Spring, MD, USA
Gowraganahalli Jagadeesh
Professor & Director, Research Training and Publications, The Office of Research and Development, Periyar Maniammai Institute of Science & Technology (Deemed to be University), Vallam, Tamil Nadu, India
Pitchai Balakumar
Division Cardiology & Nephrology, Office of Cardiology, Hematology, Endocrinology and Nephrology, Center for Drug Evaluation and Research, US Food and Drug Administration, Silver Spring, MD, USA
Fortunato Senatore
Ethics declarations
Rights and permissions.
Reprints and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter
Mukherjee, A., Kumar, G., Lodha, R. (2023). How to Present Results in a Research Paper. In: Jagadeesh, G., Balakumar, P., Senatore, F. (eds) The Quintessence of Basic and Clinical Research and Scientific Publishing. Springer, Singapore. https://doi.org/10.1007/978-981-99-1284-1_44
Download citation
DOI : https://doi.org/10.1007/978-981-99-1284-1_44
Published : 01 October 2023
Publisher Name : Springer, Singapore
Print ISBN : 978-981-99-1283-4
Online ISBN : 978-981-99-1284-1
eBook Packages : Biomedical and Life Sciences Biomedical and Life Sciences (R0)
Share this chapter
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Publish with us
Policies and ethics
- Find a journal
- Track your research
Get science-backed answers as you write with Paperpal's Research feature
How to Present Data and Statistics in Your Research Paper: Language Matters

Statistics is an inexact science as it is based on probabilities rather than certainties. However, the language used to present data and statistics in your thesis or research paper needs to be accurate to avoid misunderstandings when your work is read by others. If the written descriptions of your data and statistics are not clear and accurate, experienced researchers may lose confidence in your entire study and dismiss your results, no matter how compelling they may be.
The presentation of data in research and effective communication of statistical results requires writers to be very careful in their word choices. You must be confident that you understand the analysis you performed and the meaning of the results to really know how to present the data and statistics in your research paper effectively. Here are some terms and concepts that are often misused and may be confusing to early career researchers.
Averages, the measures of the central tendency of a dataset, can be calculated in several different ways. The word “average” in non-scholarly writings typically refers to the arithmetic mean. However, the median and mode are two other frequently used measures. In your research paper, it is critical to state exactly what measure you are using. Therefore, don’t report an average but a mean, median, or mode.
Percentages
Percentages are commonly used in presentations of data in research. They can indicate concentrations, probabilities, or comparisons, and they are frequently used to report changes in values. For example, the annual crime rate increased by 25%. However, unless you have a basis for this number, it’s difficult to judge the meaningfulness of this increase 1 . Did the number of crimes increase from 4 incidents to 5 or from 4,000 incidents to 5,000? Be sure to include enough information for the reader to understand the context.
In addition, when used for comparison, make sure your comparison is complete. For instance, if the temperature was 17% higher in 2022, be sure to include that it was 17% higher than the temperature in 2017.
Descriptive vs. inferential statistics
Descriptive statistics deal with populations, while inferential statistics deal with samples. A population is a group of objects or measurements that includes all possible instances, and a sample is a subset of that population. For example, you measure the mass of all the 1.1 kg jars of peanut butter at your favorite grocery store and report the mean and standard deviation. These are descriptive statistics for this population of peanut butter jars. However, if you then say that this is the mean of all such jars of peanut butter produced, you are engaging in inferential statistics because you now have measured only a sample of jars. You are inferring a characteristic of a population based on a sample. Inferential statistics are usually reported with a margin of error or confidence interval, such as 1.1 ± .02 kg.

A hypothesis is a testable statement about the relationship between two or more groups or variables that forms the basis of the scientific method. The appropriate language around the topic of hypotheses and hypothesis testing can be confusing for even seasoned researchers.
The alternative hypothesis is generally the researcher’s prediction for the study, and the null hypothesis is the negation of the alternative hypothesis. The aim of the study is to find evidence to reject the null hypothesis, which supports the truth of the alternative hypothesis.
When writing up the results of your hypothesis test, it is important to understand exactly what the results mean. Remember, hypothesis testing can never “prove” anything – it merely provides evidence for either rejecting or not rejecting the null hypothesis. Also, be careful that you don’t overgeneralize the meaning of the results. Just because you find evidence that the null hypothesis can be rejected in this case does not mean the same is true under all conditions.
Tips for effectively presenting statistics in academic writing
Presenting your data and statistical results can be very challenging. For researchers without extensive experience or statistical training, writing this part of the study report can be especially daunting. Here are some things to keep in mind when presenting your data and statistical results 1 .
- If you don’t completely understand a statistical procedure, do not attempt to write it up without guidance from an expert. This is the most important thing you can do.
- Keep your audience in mind. When you present your data and statistical results, think about how familiar your readers may be with the analysis and include the amount of detail needed for them to be comfortable 2 .
- Use tables and graphics to illustrate your results more clearly and make your writing more understandable.
We hope the points above help answer the question of how to present data and statistics in your research paper correctly. All the best!
- The University of North Carolina at Chapel Hill Writing Center. Statistics. https://writingcenter.unc.edu/tips-and-tools/statistics/ [Accessed October 10, 2022]
- Purdue University Online Writing Lab. Writing with statistics. https://owl.purdue.edu/owl/research_and_citation/using_research/writing_with_statistics/index.html [Accessed October 10, 2022]
Paperpal is a comprehensive AI writing toolkit that helps students and researchers achieve 2x the writing in half the time. It leverages 21+ years of STM experience and insights from millions of research articles to provide in-depth academic writing, language editing, and submission readiness support to help you write better, faster.
Get accurate academic translations, rewriting support, grammar checks, vocabulary suggestions, and generative AI assistance that delivers human precision at machine speed. Try for free or upgrade to Paperpal Prime starting at US$19 a month to access premium features, including consistency, plagiarism, and 30+ submission readiness checks to help you succeed.
Experience the future of academic writing – Sign up to Paperpal and start writing for free!
Related Reads:
- How to Write a Research Paper Outline: Simple Steps for Researchers
- Manuscript Withdrawal: Reasons, Consequences, and How to Withdraw Submitted Manuscripts
- Supplementary Materials in Research: 5 Tips for Authors
- What is an Expository Essay and How to Write It
Confusing Elements of a Research Paper That Trip Up Most Academics
How to fix sentence fragments in your writing , you may also like, measuring academic success: definition & strategies for excellence, phd qualifying exam: tips for success , ai in education: it’s time to change the..., is it ethical to use ai-generated abstracts without..., what are journal guidelines on using generative ai..., should you use ai tools like chatgpt for..., 9 steps to publish a research paper, how to make translating academic papers less challenging, self-plagiarism in research: what it is and how..., 6 tips for post-doc researchers to take their....
How To Present Data Successfully in Academic & Scientific Research
How To Present Data Successfully in Academic and Scientific Research The main point of most academic and scientific writing is to report the findings of advanced research. Doing so necessarily involves the successful presentation of research data, but communicating data can be surprisingly challenging, even when the study is a small one and the results are relatively straightforward. For large or collaborative projects that generate enormous and complicated data sets, the task can be truly daunting. Clarity is essential, as are accuracy and precision, and a style that is as concise as possible yet also conveys all the information necessary for readers to assess and understand the findings is required. Choosing appropriate formats for organising and presenting data is an essential aspect of reporting research results effectively. Data can be presented in running text, in framed boxes, in lists, in tables or in figures, with each of these having a marked effect not only on how readers perceive and understand the research results, but also on how authors analyse and interpret those results in the first place. Making the right choice for each piece of information can be among the most difficult aspects of deciding how to present data in research papers and other documents. Text is the primary format for reporting research to an academic or scientific community as well as other readers. Running text is used to relate the overall story of a research project, from introductory and background material to final conclusions and implications, so text will play a central role in presenting data in the section of a research document dedicated to results or findings. The main body of text will be particularly useful for conveying information about the research findings that is relatively straightforward and neither too complex nor too convoluted. For example, comparative presentations of the discoveries about two historical objects or the results associated with two groups of participants may prove effective in the running text of a paper, but if comparison of five or ten objects or groups is necessary, one of the more visual formats described below will usually convey the information to readers more quickly and more successfully. Text is also the right format for explaining and interpreting research data that is presented in more visual forms, such as the tables and figures discussed below. Regardless of content, the text in an academic or scientific document intended for publication or degree credit should always be written in a formal and authoritative style in keeping with the standards and conventions of the relevant discipline(s). Careful proofreading are also necessary to remove all errors and inappropriate inconsistencies in data, grammar, spelling, punctuation and paragraph structure in order to ensure clear and precise presentation of research data. PhD Thesis Editing Services It is important to remember when considering how to present data in research that text can itself be offered in a more visual format than the normal running sentences and paragraphs in the main body of a document. The headings and subheadings within an academic or scientific paper or report are a simple example: spacing as well as font style and size make these short bits of text stand out and provide a clear structure and logical transitions for presenting data in an accessible fashion. Effective headings guide readers successfully through long and complex reports of research findings, and they also divide the presentation of data according to chronology, research methods, thematic categories or other organisational principles, rendering the information more comprehensible. Longer chunks of textual material that offer necessary or helpful information for the reader, such as examples of key findings, summaries of case studies, descriptions of data analysis or insightful authorial reflections on results can be separated from the main text and framed in a box to attract the attention of readers. The font in such boxes might be slightly different than that in the running text and the background may be shaded, perhaps with colour if the publication allows it, but neither is necessary to achieve the meaningful and lasting impact that makes framed boxes so common in textbooks and other publications intended for an audience of learners. Indeed, using chunks of text in this visual way can even increase the use of a document and the number of times it is cited. Lists of research data can have a similar effect whether they are framed or simply laid out down a normal page, but a parallel grammatical structure should always be used for all the items in a list, and accuracy is paramount because readers are likely to return to lists as well as framed boxes to refresh their memories about important data. Tables tend to be the format of choice for presenting data in research documents. The experimental results of quantitative research are often collected and analysed as well as shared with readers in carefully designed tables that offer a column and row structure to enable efficient presentation, consultation, comparison and evaluation of precise data or data sets. Numerical information fills most tables, so authors should take extra care to specify units of measure, round off long numbers, limit decimal places and otherwise make the data clear, consistent and useful and the table as a whole effective and uncluttered. The information must be grouped and arranged in the columns and rows in such a way that reading down from top to bottom and across from left to right to compare, contrast and establish relationships is an easy and intuitive process. Textual data can also be presented in a table, which might alternately be referred to as a matrix, particularly in qualitative as opposed to quantitative research. Like tables, matrices are useful for presenting and comparing data about two or more variables or concepts of relevance. Whether table or matrix, this kind of visual display of tabulated information requires a concise title or heading that usually appears at the top of the table, describes the purpose or content of the table and directs readers to whatever the author wants them to observe. Columns and rows within tables also require clear headings, and footnotes at the bottom of the table (and usually in a smaller font than the rest of the table) should define any nonstandard abbreviations, unusual symbols, specialised terms or other potentially confusing elements so that the table can function meaningfully on its own without the reader referring to the main text. If aspects of a table or matrix have been borrowed from a published source, that source must be acknowledged, usually in the table footnotes or sometimes in its heading. When a document contains more than one table or matrix, a consistent format and style across all of them is advisable, and they should also be numbered according to the order in which they are first mentioned in the main text (e.g., ‘Table 1,’ ‘Table 2’ etc.) . These numbers can then be used, alone or along with the relevant titles, to refer readers to the tables or matrices at appropriate points in the main text. PhD Thesis Editing Services Figures are also frequently used tools for presenting data in research, and they too should be numbered according to the order in which they are mentioned in the main body of a paper or other document. They are usually distinguished from tables (e.g., ‘Figure 1,’ ‘Figure 2’ etc.) and since several different kinds of figures are used in academic and scientific writing, the figures might also be divided into separate groups for numbering (e.g., ‘Chart 1,’ ‘Map 1’ etc.). The type of figure used to present a specific kind or cluster of research data will depend on both the nature of the data and the way in which the author is using the data to address research problems or questions. Bar charts or bar graphs are particularly common for revealing patterns and trends in research variables and they are especially effective when presenting discrete data in groups or categories for comparison and assessment. Line graphs or line charts also reveal trends and patterns and can successfully represent the changing values of several continuous variables over time, highlighting significant changes and turning points and enabling effective comparison. These types of visual displays can be combined in a single figure using both bars and lines along with careful shading and colour to expand comparisons among variables or categories and save valuable space in a document. Each figure in a research document should be given a concise but descriptive caption or heading, which might appear just above or just beneath the figure. The footnotes that explain elements of a table or matrix usually do not feature in a figure, but a figure legend can be used to define abbreviations, explain symbols, acknowledge sources (though that sometimes appears in the caption instead) and clarify any aspect of a figure for readers. Consistency in formatting and style across all the figures used in a research document is desirable, particularly when it comes to key features for understanding the information such as the x and y axes and scale bars in charts and graphs, but if different types of figures are used, each type may have its own format or style. Clear labelling should be provided for all important or potentially confusing parts of a figure (for those axes and scale bars, for instance) and if a photograph is used to illustrate or present data, consent must be obtained from any participants who appear in the photo and identities should usually be obscured. When a list, table or figure used for presenting data proves to be particularly large or complicated, it is often better to divide it into two or more lists, tables or figures in order to simplify and clarify the intended messages or purposes. This will be especially important for deciding how to present data in research when speaking to listeners instead of writing for readers. Lists, tables and figures offered via slides as a presenter speaks are viewed by the audience for a very short period of time, so simple is best, but longer lists, tables and figures can be distributed as handouts if necessary. When presenting data in research-based writing, the inclusion of even extremely complex lists, tables or figures may be acceptable, but keeping the needs of readers in mind is imperative and so is observing the relevant instructions or guidelines. Course instructors will often have specific requirements that must be met by students, university departments will usually offer formatting specifications for theses and dissertations, and scholarly journals will always have some kind of author guidelines that must be followed. There may be limits on the number of tables and figures allowed, specific requirements for the use of lines or rules within tables, or detailed instructions for ensuring appropriate resolution in photographs. PhD Thesis Editing Services All such requirements must be met, but many academic and scientific journals permit authors to submit appendices or supplementary materials with a manuscript, offering an opportunity to include, for instance, a detailed table of precise research data as an appendix or supplementary document while using simpler graphs in the paper itself to show important trends that are discussed and interpreted by the author. Relegating detailed data to supplementary files can also help with shortening a manuscript, and proofreaders, reviewers and researchers will appreciate the extra data while general readers will be able to encounter the main argument of the paper without the distraction that too much information might introduce. You may even want to include a list of tables, figures or both to draw attention to the presence of those elements whether the guidelines indicate the need for such a list or not. Do be sure, however, to exercise consistency with any information repeated across different formats, including supplementary materials (the same terminology should be used for an important concept or group, for instance, every time it is mentioned), and remember to use the specified file formats for those supplementary materials as well as for the tables and figures in the main document. Along with the relevant guidelines, authors should be prepared to take a close look at successful models of how other authors have presented research data. A published research article with especially clear and effective tables and figures will prove helpful if you are preparing a manuscript for submission to the journal that published that research article. A successful thesis recently written by a candidate in your university department who made particularly good use of lists and matrices will provide creative ideas as you design your own thesis. A conference presentation with excellent slides that significantly increased the impact of the spoken message might effectively be emulated as you plan your own presentation. Whatever sort of research document you are writing, it is always essential to plan carefully and give the formats in which you will present your research data considerable thought before you begin writing in order to avoid overlaps, repetitions and wasted time. You may also find that organising data into clear and appealing formats such as tables and charts will reveal or highlight details and patterns that you had not detected or considered important when assessing the raw data from your research. Using a variety of formats throughout a study and ensuring that the best format is chosen and designed for each bit of information as you determine how to present data in research documents means creating an effective comprehension tool not only for your readers, but also for yourself as you draft, revise and perfect your work.
Why Our Editing and Proofreading Services? At Proof-Reading-Service.com we offer the highest quality journal article editing , phd thesis editing and proofreading services via our large and extremely dedicated team of academic and scientific professionals. All of our proofreaders are native speakers of English who have earned their own postgraduate degrees, and their areas of specialisation cover such a wide range of disciplines that we are able to help our international clientele with research editing to improve and perfect all kinds of academic manuscripts for successful publication. Many of the carefully trained members of our expert editing and proofreading team work predominantly on articles intended for publication in scholarly journals, applying painstaking journal editing standards to ensure that the references and formatting used in each paper are in conformity with the journal’s instructions for authors and to correct any grammar, spelling, punctuation or simple typing errors. In this way, we enable our clients to report their research in the clear and accurate ways required to impress acquisitions proofreaders and achieve publication.
Our scientific proofreading services for the authors of a wide variety of scientific journal papers are especially popular, but we also offer manuscript proofreading services and have the experience and expertise to proofread and edit manuscripts in all scholarly disciplines, as well as beyond them. We have team members who specialise in medical proofreading services , and some of our experts dedicate their time exclusively to PhD proofreading and master’s proofreading , offering research students the opportunity to improve their use of formatting and language through the most exacting PhD thesis editing and dissertation proofreading practices. Whether you are preparing a conference paper for presentation, polishing a progress report to share with colleagues, or facing the daunting task of editing and perfecting any kind of scholarly document for publication, a qualified member of our professional team can provide invaluable assistance and give you greater confidence in your written work.
If you are in the process of preparing an article for an academic or scientific journal, or planning one for the near future, you may well be interested in a new book, Guide to Journal Publication , which is available on our Tips and Advice on Publishing Research in Journals website.
Guide to Academic and Scientific Publication
How to get your writing published in scholarly journals.
It provides practical advice on planning, preparing and submitting articles for publication in scholarly journals.
PhD Success
How to write a doctoral thesis.
If you are in the process of preparing a PhD thesis for submission, or planning one for the near future, you may well be interested in the book, How to Write a Doctoral Thesis , which is available on our thesis proofreading website.
PhD Success: How to Write a Doctoral Thesis provides guidance for students familiar with English and the procedures of English universities, but it also acknowledges that many theses in the English language are now written by candidates whose first language is not English, so it carefully explains the scholarly styles, conventions and standards expected of a successful doctoral thesis in the English language.
Why Is Proofreading Important?
To improve the quality of papers.
Effective proofreading is absolutely vital to the production of high-quality scholarly and professional documents. When done carefully, correctly and thoroughly, proofreading can make the difference between writing that communicates successfully with its intended readers and writing that does not. No author creates a perfect text without reviewing, reflecting on and revising what he or she has written, and proofreading is an extremely important part of this process.

Princeton Correspondents on Undergraduate Research
How to Make a Successful Research Presentation
Turning a research paper into a visual presentation is difficult; there are pitfalls, and navigating the path to a brief, informative presentation takes time and practice. As a TA for GEO/WRI 201: Methods in Data Analysis & Scientific Writing this past fall, I saw how this process works from an instructor’s standpoint. I’ve presented my own research before, but helping others present theirs taught me a bit more about the process. Here are some tips I learned that may help you with your next research presentation:
More is more
In general, your presentation will always benefit from more practice, more feedback, and more revision. By practicing in front of friends, you can get comfortable with presenting your work while receiving feedback. It is hard to know how to revise your presentation if you never practice. If you are presenting to a general audience, getting feedback from someone outside of your discipline is crucial. Terms and ideas that seem intuitive to you may be completely foreign to someone else, and your well-crafted presentation could fall flat.
Less is more
Limit the scope of your presentation, the number of slides, and the text on each slide. In my experience, text works well for organizing slides, orienting the audience to key terms, and annotating important figures–not for explaining complex ideas. Having fewer slides is usually better as well. In general, about one slide per minute of presentation is an appropriate budget. Too many slides is usually a sign that your topic is too broad.

Limit the scope of your presentation
Don’t present your paper. Presentations are usually around 10 min long. You will not have time to explain all of the research you did in a semester (or a year!) in such a short span of time. Instead, focus on the highlight(s). Identify a single compelling research question which your work addressed, and craft a succinct but complete narrative around it.
You will not have time to explain all of the research you did. Instead, focus on the highlights. Identify a single compelling research question which your work addressed, and craft a succinct but complete narrative around it.
Craft a compelling research narrative
After identifying the focused research question, walk your audience through your research as if it were a story. Presentations with strong narrative arcs are clear, captivating, and compelling.
- Introduction (exposition — rising action)
Orient the audience and draw them in by demonstrating the relevance and importance of your research story with strong global motive. Provide them with the necessary vocabulary and background knowledge to understand the plot of your story. Introduce the key studies (characters) relevant in your story and build tension and conflict with scholarly and data motive. By the end of your introduction, your audience should clearly understand your research question and be dying to know how you resolve the tension built through motive.
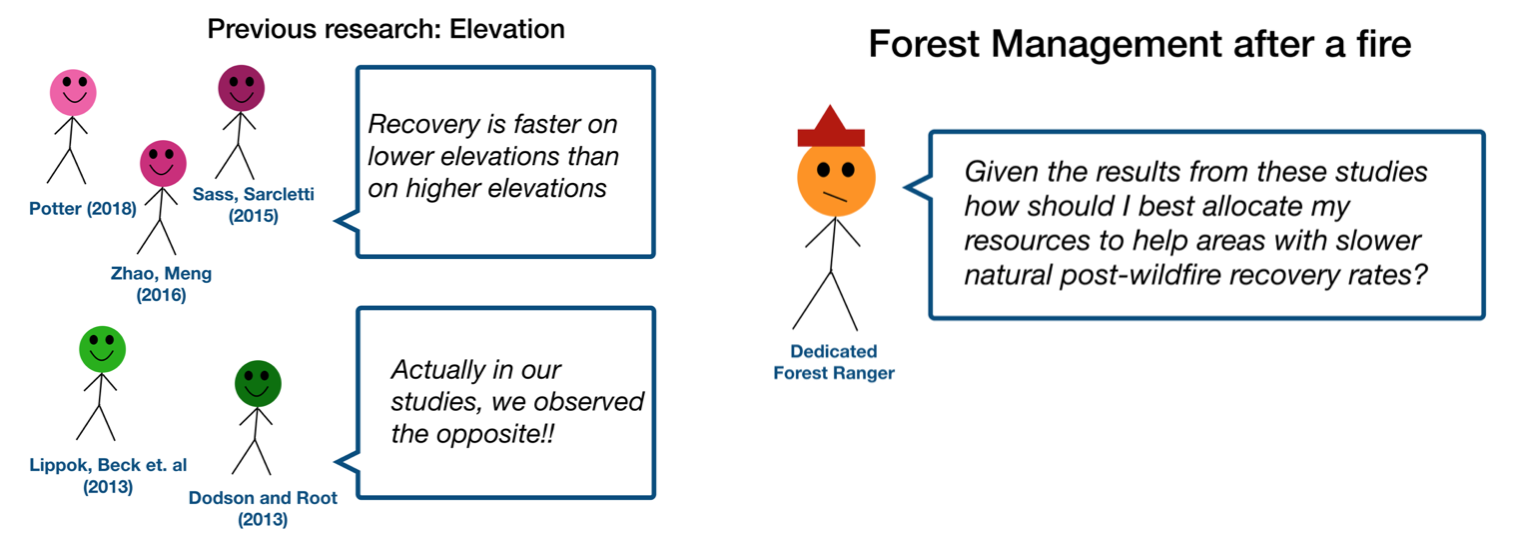
- Methods (rising action)
The methods section should transition smoothly and logically from the introduction. Beware of presenting your methods in a boring, arc-killing, ‘this is what I did.’ Focus on the details that set your story apart from the stories other people have already told. Keep the audience interested by clearly motivating your decisions based on your original research question or the tension built in your introduction.
- Results (climax)
Less is usually more here. Only present results which are clearly related to the focused research question you are presenting. Make sure you explain the results clearly so that your audience understands what your research found. This is the peak of tension in your narrative arc, so don’t undercut it by quickly clicking through to your discussion.
- Discussion (falling action)
By now your audience should be dying for a satisfying resolution. Here is where you contextualize your results and begin resolving the tension between past research. Be thorough. If you have too many conflicts left unresolved, or you don’t have enough time to present all of the resolutions, you probably need to further narrow the scope of your presentation.
- Conclusion (denouement)
Return back to your initial research question and motive, resolving any final conflicts and tying up loose ends. Leave the audience with a clear resolution of your focus research question, and use unresolved tension to set up potential sequels (i.e. further research).
Use your medium to enhance the narrative
Visual presentations should be dominated by clear, intentional graphics. Subtle animation in key moments (usually during the results or discussion) can add drama to the narrative arc and make conflict resolutions more satisfying. You are narrating a story written in images, videos, cartoons, and graphs. While your paper is mostly text, with graphics to highlight crucial points, your slides should be the opposite. Adapting to the new medium may require you to create or acquire far more graphics than you included in your paper, but it is necessary to create an engaging presentation.
The most important thing you can do for your presentation is to practice and revise. Bother your friends, your roommates, TAs–anybody who will sit down and listen to your work. Beyond that, think about presentations you have found compelling and try to incorporate some of those elements into your own. Remember you want your work to be comprehensible; you aren’t creating experts in 10 minutes. Above all, try to stay passionate about what you did and why. You put the time in, so show your audience that it’s worth it.
For more insight into research presentations, check out these past PCUR posts written by Emma and Ellie .
— Alec Getraer, Natural Sciences Correspondent
Share this:
- Share on Tumblr


The Ultimate Guide to Qualitative Research - Part 3: Presenting Qualitative Data

- Introduction
How do you present qualitative data?
Data visualization.
- Research paper writing
- Transparency and rigor in research
- How to publish a research paper
Table of contents
- Transparency and rigor
Navigate to other guide parts:
Part 1: The Basics or Part 2: Handling Qualitative Data
- Presenting qualitative data
In the end, presenting qualitative research findings is just as important a skill as mastery of qualitative research methods for the data collection and data analysis process . Simply uncovering insights is insufficient to the research process; presenting a qualitative analysis holds the challenge of persuading your audience of the value of your research. As a result, it's worth spending some time considering how best to report your research to facilitate its contribution to scientific knowledge.

When it comes to research, presenting data in a meaningful and accessible way is as important as gathering it. This is particularly true for qualitative research , where the richness and complexity of the data demand careful and thoughtful presentation. Poorly written research is taken less seriously and left undiscussed by the greater scholarly community; quality research reporting that persuades its audience stands a greater chance of being incorporated in discussions of scientific knowledge.
Qualitative data presentation differs fundamentally from that found in quantitative research. While quantitative data tend to be numerical and easily lend themselves to statistical analysis and graphical representation, qualitative data are often textual and unstructured, requiring an interpretive approach to bring out their inherent meanings. Regardless of the methodological approach , the ultimate goal of data presentation is to communicate research findings effectively to an audience so they can incorporate the generated knowledge into their research inquiry.
As the section on research rigor will suggest, an effective presentation of your research depends on a thorough scientific process that organizes raw data into a structure that allows for a thorough analysis for scientific understanding.
Preparing the data
The first step in presenting qualitative data is preparing the data. This preparation process often begins with cleaning and organizing the data. Cleaning involves checking the data for accuracy and completeness, removing any irrelevant information, and making corrections as needed. Organizing the data often entails arranging the data into categories or groups that make sense for your research framework.

Coding the data
Once the data are cleaned and organized, the next step is coding , a crucial part of qualitative data analysis. Coding involves assigning labels to segments of the data to summarize or categorize them. This process helps to identify patterns and themes in the data, laying the groundwork for subsequent data interpretation and presentation. Qualitative research often involves multiple iterations of coding, creating new and meaningful codes while discarding unnecessary ones , to generate a rich structure through which data analysis can occur.
Uncovering insights
As you navigate through these initial steps, keep in mind the broader aim of qualitative research, which is to provide rich, detailed, and nuanced understandings of people's experiences, behaviors, and social realities. These guiding principles will help to ensure that your data presentation is not only accurate and comprehensive but also meaningful and impactful.
While this process might seem intimidating at first, it's an essential part of any qualitative research project. It's also a skill that can be learned and refined over time, so don't be discouraged if you find it challenging at first. Remember, the goal of presenting qualitative data is to make your research findings accessible and understandable to others. This requires careful preparation, a clear understanding of your data, and a commitment to presenting your findings in a way that respects and honors the complexity of the phenomena you're studying.
In the following sections, we'll delve deeper into how to create a comprehensive narrative from your data, the visualization of qualitative data , and the writing and publication processes . Let's briefly excerpt some of the content in the articles in this part of the guide.
ATLAS.ti helps you make sense of your data
Find out how with a free trial of our powerful data analysis interface.
How often do you read a research article and skip straight to the tables and figures? That's because data visualizations representing qualitative and quantitative data have the power to make large and complex research projects with thousands of data points comprehensible when authors present data to research audiences. Researchers create visual representations to help summarize the data generated from their study and make clear the pathways for actionable insights.
In everyday situations, a picture is always worth a thousand words. Illustrations, figures, and charts convey messages that words alone cannot. In research, data visualization can help explain scientific knowledge, evidence for data insights, and key performance indicators in an orderly manner based on data that is otherwise unstructured.
For all of the various data formats available to researchers, a significant portion of qualitative and social science research is still text-based. Essays, reports, and research articles still rely on writing practices aimed at repackaging research in prose form. This can create the impression that simply writing more will persuade research audiences. Instead, framing research in terms that are easy for your target readers to understand makes it easier for your research to become published in peer-reviewed scholarly journals or find engagement at scholarly conferences. Even in market or professional settings, data visualization is an essential concept when you need to convince others about the insights of your research and the recommendations you make based on the data.
Importance of data visualization
Data visualization is important because it makes it easy for your research audience to understand your data sets and your findings. Also, data visualization helps you organize your data more efficiently. As the explanation of ATLAS.ti's tools will illustrate in this section, data visualization might point you to research inquiries that you might not even be aware of, helping you get the most out of your data. Strictly speaking, the primary role of data visualization is to make the analysis of your data , if not the data itself, clear. Especially in social science research, data visualization makes it easy to see how data scientists collect and analyze data.
Prerequisites for generating data visualizations
Data visualization is effective in explaining research to others only if the researcher or data scientist can make sense of the data in front of them. Traditional research with unstructured data usually calls for coding the data with short, descriptive codes that can be analyzed later, whether statistically or thematically. These codes form the basic data points of a meaningful qualitative analysis. They represent the structure of qualitative data sets, without which a scientific visualization with research rigor would be extremely difficult to achieve. In most respects, data visualization of a qualitative research project requires coding the entire data set so that the codes adequately represent the collected data.
A successfully crafted research study culminates in the writing of the research paper . While a pilot study or preliminary research might guide the research design , a full research study leads to discussion that highlights avenues for further research. As such, the importance of the research paper cannot be overestimated in the overall generation of scientific knowledge.

The physical and natural sciences tend to have a clinical structure for a research paper that mirrors the scientific method: outline the background research, explain the materials and methods of the study, outline the research findings generated from data analysis, and discuss the implications. Qualitative research tends to preserve much of this structure, but there are notable and numerous variations from a traditional research paper that it's worth emphasizing the flexibility in the social sciences with respect to the writing process.
Requirements for research writing
While there aren't any hard and fast rules regarding what belongs in a qualitative research paper , readers expect to find a number of pieces of relevant information in a rigorously-written report. The best way to know what belongs in a full research paper is to look at articles in your target journal or articles that share a particular topic similar to yours and examine how successfully published papers are written.
It's important to emphasize the more mundane but equally important concerns of proofreading and formatting guidelines commonly found when you write a research paper. Research publication shouldn't strictly be a test of one's writing skills, but acknowledging the importance of convincing peer reviewers of the credibility of your research means accepting the responsibility of preparing your research manuscript to commonly accepted standards in research.
As a result, seemingly insignificant things such as spelling mistakes, page numbers, and proper grammar can make a difference with a particularly strict reviewer. Even when you expect to develop a paper through reviewer comments and peer feedback, your manuscript should be as close to a polished final draft as you can make it prior to submission.
Qualitative researchers face particular challenges in convincing their target audience of the value and credibility of their subsequent analysis. Numbers and quantifiable concepts in quantitative studies are relatively easier to understand than their counterparts associated with qualitative methods . Think about how easy it is to make conclusions about the value of items at a store based on their prices, then imagine trying to compare those items based on their design, function, and effectiveness.
Qualitative research involves and requires these sorts of discussions. The goal of qualitative data analysis is to allow a qualitative researcher and their audience to make such determinations, but before the audience can accept these determinations, the process of conducting research that produces the qualitative analysis must first be seen as trustworthy. As a result, it is on the researcher to persuade their audience that their data collection process and subsequent analysis is rigorous.
Qualitative rigor refers to the meticulousness, consistency, and transparency of the research. It is the application of systematic, disciplined, and stringent methods to ensure the credibility, dependability, confirmability, and transferability of research findings. In qualitative inquiry, these attributes ensure the research accurately reflects the phenomenon it is intended to represent, that its findings can be understood or used by others, and that its processes and results are open to scrutiny and validation.
Transparency
It is easier to believe the information presented to you if there is a rigorous analysis process behind that information, and if that process is explicitly detailed. The same is true for qualitative research results, making transparency a key element in qualitative research methodologies. Transparency is a fundamental aspect of rigor in qualitative research. It involves the clear, detailed, and explicit documentation of all stages of the research process. This allows other researchers to understand, evaluate, replicate, and build upon the study. Transparency in qualitative research is essential for maintaining rigor, trustworthiness, and ethical integrity. By being transparent, researchers allow their work to be scrutinized, critiqued, and improved upon, contributing to the ongoing development and refinement of knowledge in their field.
Research papers are only as useful as their audience in the scientific community is wide. To reach that audience, a paper needs to pass the peer review process of an academic journal. However, the idea of having research published in peer-reviewed journals may seem daunting to newer researchers, so it's important to provide a guide on how an academic journal looks at your research paper as well as how to determine what is the right journal for your research.

In simple terms, a research article is good if it is accepted as credible and rigorous by the scientific community. A study that isn't seen as a valid contribution to scientific knowledge shouldn't be published; ultimately, it is up to peers within the field in which the study is being considered to determine the study's value. In established academic research, this determination is manifest in the peer review process. Journal editors at a peer-reviewed journal assign papers to reviewers who will determine the credibility of the research. A peer-reviewed article that completed this process and is published in a reputable journal can be seen as credible with novel research that can make a profound contribution to scientific knowledge.
The process of research publication
The process has been codified and standardized within the scholarly community to include three main stages. These stages include the initial submission stage where the editor reviews the relevance of the paper, the review stage where experts in your field offer feedback, and, if reviewers approve your paper, the copyediting stage where you work with the journal to prepare the paper for inclusion in their journal.
Publishing a research paper may seem like an opaque process where those involved with academic journals make arbitrary decisions about the worthiness of research manuscripts. In reality, reputable publications assign a rubric or a set of guidelines that reviewers need to keep in mind when they review a submission. These guidelines will most likely differ depending on the journal, but they fall into a number of typical categories that are applicable regardless of the research area or the type of methods employed in a research study, including the strength of the literature review , rigor in research methodology , and novelty of findings.
Choosing the right journal isn't simply a matter of which journal is the most famous or has the broadest reach. Many universities keep lists of prominent journals where graduate students and faculty members should publish a research paper , but oftentimes this list is determined by a journal's impact factor and their inclusion in major academic databases.

Guide your research to publication with ATLAS.ti
Turn insights into visualizations with our easy-to-use interface. Download a free trial today.
This section is part of an entire guide. Use this table of contents to jump to any page in the guide.
Part 1: The Basics
- What is qualitative data?
- 10 examples of qualitative data
- Qualitative vs. quantitative research
- What is mixed methods research?
- Theoretical perspective
- Theoretical framework
- Literature reviews
- Research questions
- Conceptual framework
- Conceptual vs. theoretical framework
- Focus groups
- Observational research
- Case studies
- Survey research
- What is ethnographic research?
- Confidentiality and privacy in research
- Bias in research
- Power dynamics in research
- Reflexivity
Part 2: Handling Qualitative Data
- Research transcripts
- Field notes in research
- Research memos
- Survey data
- Images, audio, and video in qualitative research
- Coding qualitative data
- Coding frame
- Auto-coding and smart coding
- Organizing codes
- Content analysis
- Thematic analysis
- Thematic analysis vs. content analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- What is inductive reasoning?
- Inductive vs. deductive reasoning
- What is data interpretation?
- Qualitative analysis software
Part 3: Presenting Qualitative Data
- Data visualization - What is it and why is it important?
Skills for Learning : Research Skills
Data analysis is an ongoing process that should occur throughout your research project. Suitable data-analysis methods must be selected when you write your research proposal. The nature of your data (i.e. quantitative or qualitative) will be influenced by your research design and purpose. The data will also influence the analysis methods selected.
We run interactive workshops to help you develop skills related to doing research, such as data analysis, writing literature reviews and preparing for dissertations. Find out more on the Skills for Learning Workshops page.
We have online academic skills modules within MyBeckett for all levels of university study. These modules will help your academic development and support your success at LBU. You can work through the modules at your own pace, revisiting them as required. Find out more from our FAQ What academic skills modules are available?
Quantitative data analysis
Broadly speaking, 'statistics' refers to methods, tools and techniques used to collect, organise and interpret data. The goal of statistics is to gain understanding from data. Therefore, you need to know how to:
- Produce data – for example, by handing out a questionnaire or doing an experiment.
- Organise, summarise, present and analyse data.
- Draw valid conclusions from findings.
There are a number of statistical methods you can use to analyse data. Choosing an appropriate statistical method should follow naturally, however, from your research design. Therefore, you should think about data analysis at the early stages of your study design. You may need to consult a statistician for help with this.
Tips for working with statistical data
- Plan so that the data you get has a good chance of successfully tackling the research problem. This will involve reading literature on your subject, as well as on what makes a good study.
- To reach useful conclusions, you need to reduce uncertainties or 'noise'. Thus, you will need a sufficiently large data sample. A large sample will improve precision. However, this must be balanced against the 'costs' (time and money) of collection.
- Consider the logistics. Will there be problems in obtaining sufficient high-quality data? Think about accuracy, trustworthiness and completeness.
- Statistics are based on random samples. Consider whether your sample will be suited to this sort of analysis. Might there be biases to think about?
- How will you deal with missing values (any data that is not recorded for some reason)? These can result from gaps in a record or whole records being missed out.
- When analysing data, start by looking at each variable separately. Conduct initial/exploratory data analysis using graphical displays. Do this before looking at variables in conjunction or anything more complicated. This process can help locate errors in the data and also gives you a 'feel' for the data.
- Look out for patterns of 'missingness'. They are likely to alert you if there’s a problem. If the 'missingness' is not random, then it will have an impact on the results.
- Be vigilant and think through what you are doing at all times. Think critically. Statistics are not just mathematical tricks that a computer sorts out. Rather, analysing statistical data is a process that the human mind must interpret!
Top tips! Try inventing or generating the sort of data you might get and see if you can analyse it. Make sure that your process works before gathering actual data. Think what the output of an analytic procedure will look like before doing it for real.
(Note: it is actually difficult to generate realistic data. There are fraud-detection methods in place to identify data that has been fabricated. So, remember to get rid of your practice data before analysing the real stuff!)
Statistical software packages
Software packages can be used to analyse and present data. The most widely used ones are SPSS and NVivo.
SPSS is a statistical-analysis and data-management package for quantitative data analysis. Click on ‘ How do I install SPSS? ’ to learn how to download SPSS to your personal device. SPSS can perform a wide variety of statistical procedures. Some examples are:
- Data management (i.e. creating subsets of data or transforming data).
- Summarising, describing or presenting data (i.e. mean, median and frequency).
- Looking at the distribution of data (i.e. standard deviation).
- Comparing groups for significant differences using parametric (i.e. t-test) and non-parametric (i.e. Chi-square) tests.
- Identifying significant relationships between variables (i.e. correlation).
NVivo can be used for qualitative data analysis. It is suitable for use with a wide range of methodologies. Click on ‘ How do I access NVivo ’ to learn how to download NVivo to your personal device. NVivo supports grounded theory, survey data, case studies, focus groups, phenomenology, field research and action research.
- Process data such as interview transcripts, literature or media extracts, and historical documents.
- Code data on screen and explore all coding and documents interactively.
- Rearrange, restructure, extend and edit text, coding and coding relationships.
- Search imported text for words, phrases or patterns, and automatically code the results.
Qualitative data analysis
Miles and Huberman (1994) point out that there are diverse approaches to qualitative research and analysis. They suggest, however, that it is possible to identify 'a fairly classic set of analytic moves arranged in sequence'. This involves:
- Affixing codes to a set of field notes drawn from observation or interviews.
- Noting reflections or other remarks in the margins.
- Sorting/sifting through these materials to identify: a) similar phrases, relationships between variables, patterns and themes and b) distinct differences between subgroups and common sequences.
- Isolating these patterns/processes and commonalties/differences. Then, taking them out to the field in the next wave of data collection.
- Highlighting generalisations and relating them to your original research themes.
- Taking the generalisations and analysing them in relation to theoretical perspectives.
(Miles and Huberman, 1994.)
Patterns and generalisations are usually arrived at through a process of analytic induction (see above points 5 and 6). Qualitative analysis rarely involves statistical analysis of relationships between variables. Qualitative analysis aims to gain in-depth understanding of concepts, opinions or experiences.
Presenting information
There are a number of different ways of presenting and communicating information. The particular format you use is dependent upon the type of data generated from the methods you have employed.
Here are some appropriate ways of presenting information for different types of data:
Bar charts: These may be useful for comparing relative sizes. However, they tend to use a large amount of ink to display a relatively small amount of information. Consider a simple line chart as an alternative.
Pie charts: These have the benefit of indicating that the data must add up to 100%. However, they make it difficult for viewers to distinguish relative sizes, especially if two slices have a difference of less than 10%.
Other examples of presenting data in graphical form include line charts and scatter plots .
Qualitative data is more likely to be presented in text form. For example, using quotations from interviews or field diaries.
- Plan ahead, thinking carefully about how you will analyse and present your data.
- Think through possible restrictions to resources you may encounter and plan accordingly.
- Find out about the different IT packages available for analysing your data and select the most appropriate.
- If necessary, allow time to attend an introductory course on a particular computer package. You can book SPSS and NVivo workshops via MyHub .
- Code your data appropriately, assigning conceptual or numerical codes as suitable.
- Organise your data so it can be analysed and presented easily.
- Choose the most suitable way of presenting your information, according to the type of data collected. This will allow your information to be understood and interpreted better.
Primary, secondary and tertiary sources
Information sources are sometimes categorised as primary, secondary or tertiary sources depending on whether or not they are ‘original’ materials or data. For some research projects, you may need to use primary sources as well as secondary or tertiary sources. However the distinction between primary and secondary sources is not always clear and depends on the context. For example, a newspaper article might usually be categorised as a secondary source. But it could also be regarded as a primary source if it were an article giving a first-hand account of a historical event written close to the time it occurred.
- Primary sources
- Secondary sources
- Tertiary sources
- Grey literature
Primary sources are original sources of information that provide first-hand accounts of what is being experienced or researched. They enable you to get as close to the actual event or research as possible. They are useful for getting the most contemporary information about a topic.
Examples include diary entries, newspaper articles, census data, journal articles with original reports of research, letters, email or other correspondence, original manuscripts and archives, interviews, research data and reports, statistics, autobiographies, exhibitions, films, and artists' writings.
Some information will be available on an Open Access basis, freely accessible online. However, many academic sources are paywalled, and you may need to login as a Leeds Beckett student to access them. Where Leeds Beckett does not have access to a source, you can use our Request It! Service .
Secondary sources interpret, evaluate or analyse primary sources. They're useful for providing background information on a topic, or for looking back at an event from a current perspective. The majority of your literature searching will probably be done to find secondary sources on your topic.
Examples include journal articles which review or interpret original findings, popular magazine articles commenting on more serious research, textbooks and biographies.
The term tertiary sources isn't used a great deal. There's overlap between what might be considered a secondary source and a tertiary source. One definition is that a tertiary source brings together secondary sources.
Examples include almanacs, fact books, bibliographies, dictionaries and encyclopaedias, directories, indexes and abstracts. They can be useful for introductory information or an overview of a topic in the early stages of research.
Depending on your subject of study, grey literature may be another source you need to use. Grey literature includes technical or research reports, theses and dissertations, conference papers, government documents, white papers, and so on.
Artificial intelligence tools
Before using any generative artificial intelligence or paraphrasing tools in your assessments, you should check if this is permitted on your course.
If their use is permitted on your course, you must acknowledge any use of generative artificial intelligence tools such as ChatGPT or paraphrasing tools (e.g., Grammarly, Quillbot, etc.), even if you have only used them to generate ideas for your assessments or for proofreading.
- Academic Integrity Module in MyBeckett
- Assignment Calculator
- Building on Feedback
- Disability Advice
- Essay X-ray tool
- International Students' Academic Introduction
- Manchester Academic Phrasebank
- Quote, Unquote
- Skills and Subject Suppor t
- Turnitin Grammar Checker
{{You can add more boxes below for links specific to this page [this note will not appear on user pages] }}
- Research Methods Checklist
- Sampling Checklist
Skills for Learning FAQs

0113 812 1000
- University Disclaimer
- Accessibility
How to present research data consistently in a scientific paper
Affiliation.
- 1 Department of Diagnostic Radiology, Eberhard-Karls-Universität Tübingen, Germany.
- PMID: 9204317
The paper analyzes, on a subjective basis, aspects of how to write scientific papers that will be accepted for publication in peer review journals. For each individual section of the manuscript, i.e. Introduction, Materials and methods, Results, Discussion, Abstract, and References, general comments and examples are given. It is concluded that writing scientific articles is a form of mental exercise that has to be practised to be successful.
- Peer Review
- Publishing / standards
- Science / methods
- Writing / standards*
Our approach
- Responsibility
- Infrastructure
- Try Meta AI
RECOMMENDED READS
- 5 Steps to Getting Started with Llama 2
- The Llama Ecosystem: Past, Present, and Future
- Introducing Code Llama, a state-of-the-art large language model for coding
- Meta and Microsoft Introduce the Next Generation of Llama
- Today, we’re introducing Meta Llama 3, the next generation of our state-of-the-art open source large language model.
- Llama 3 models will soon be available on AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM WatsonX, Microsoft Azure, NVIDIA NIM, and Snowflake, and with support from hardware platforms offered by AMD, AWS, Dell, Intel, NVIDIA, and Qualcomm.
- We’re dedicated to developing Llama 3 in a responsible way, and we’re offering various resources to help others use it responsibly as well. This includes introducing new trust and safety tools with Llama Guard 2, Code Shield, and CyberSec Eval 2.
- In the coming months, we expect to introduce new capabilities, longer context windows, additional model sizes, and enhanced performance, and we’ll share the Llama 3 research paper.
- Meta AI, built with Llama 3 technology, is now one of the world’s leading AI assistants that can boost your intelligence and lighten your load—helping you learn, get things done, create content, and connect to make the most out of every moment. You can try Meta AI here .
Today, we’re excited to share the first two models of the next generation of Llama, Meta Llama 3, available for broad use. This release features pretrained and instruction-fine-tuned language models with 8B and 70B parameters that can support a broad range of use cases. This next generation of Llama demonstrates state-of-the-art performance on a wide range of industry benchmarks and offers new capabilities, including improved reasoning. We believe these are the best open source models of their class, period. In support of our longstanding open approach, we’re putting Llama 3 in the hands of the community. We want to kickstart the next wave of innovation in AI across the stack—from applications to developer tools to evals to inference optimizations and more. We can’t wait to see what you build and look forward to your feedback.
Our goals for Llama 3
With Llama 3, we set out to build the best open models that are on par with the best proprietary models available today. We wanted to address developer feedback to increase the overall helpfulness of Llama 3 and are doing so while continuing to play a leading role on responsible use and deployment of LLMs. We are embracing the open source ethos of releasing early and often to enable the community to get access to these models while they are still in development. The text-based models we are releasing today are the first in the Llama 3 collection of models. Our goal in the near future is to make Llama 3 multilingual and multimodal, have longer context, and continue to improve overall performance across core LLM capabilities such as reasoning and coding.
State-of-the-art performance
Our new 8B and 70B parameter Llama 3 models are a major leap over Llama 2 and establish a new state-of-the-art for LLM models at those scales. Thanks to improvements in pretraining and post-training, our pretrained and instruction-fine-tuned models are the best models existing today at the 8B and 70B parameter scale. Improvements in our post-training procedures substantially reduced false refusal rates, improved alignment, and increased diversity in model responses. We also saw greatly improved capabilities like reasoning, code generation, and instruction following making Llama 3 more steerable.

*Please see evaluation details for setting and parameters with which these evaluations are calculated.
In the development of Llama 3, we looked at model performance on standard benchmarks and also sought to optimize for performance for real-world scenarios. To this end, we developed a new high-quality human evaluation set. This evaluation set contains 1,800 prompts that cover 12 key use cases: asking for advice, brainstorming, classification, closed question answering, coding, creative writing, extraction, inhabiting a character/persona, open question answering, reasoning, rewriting, and summarization. To prevent accidental overfitting of our models on this evaluation set, even our own modeling teams do not have access to it. The chart below shows aggregated results of our human evaluations across of these categories and prompts against Claude Sonnet, Mistral Medium, and GPT-3.5.

Preference rankings by human annotators based on this evaluation set highlight the strong performance of our 70B instruction-following model compared to competing models of comparable size in real-world scenarios.
Our pretrained model also establishes a new state-of-the-art for LLM models at those scales.

To develop a great language model, we believe it’s important to innovate, scale, and optimize for simplicity. We adopted this design philosophy throughout the Llama 3 project with a focus on four key ingredients: the model architecture, the pretraining data, scaling up pretraining, and instruction fine-tuning.
Model architecture
In line with our design philosophy, we opted for a relatively standard decoder-only transformer architecture in Llama 3. Compared to Llama 2, we made several key improvements. Llama 3 uses a tokenizer with a vocabulary of 128K tokens that encodes language much more efficiently, which leads to substantially improved model performance. To improve the inference efficiency of Llama 3 models, we’ve adopted grouped query attention (GQA) across both the 8B and 70B sizes. We trained the models on sequences of 8,192 tokens, using a mask to ensure self-attention does not cross document boundaries.
Training data
To train the best language model, the curation of a large, high-quality training dataset is paramount. In line with our design principles, we invested heavily in pretraining data. Llama 3 is pretrained on over 15T tokens that were all collected from publicly available sources. Our training dataset is seven times larger than that used for Llama 2, and it includes four times more code. To prepare for upcoming multilingual use cases, over 5% of the Llama 3 pretraining dataset consists of high-quality non-English data that covers over 30 languages. However, we do not expect the same level of performance in these languages as in English.
To ensure Llama 3 is trained on data of the highest quality, we developed a series of data-filtering pipelines. These pipelines include using heuristic filters, NSFW filters, semantic deduplication approaches, and text classifiers to predict data quality. We found that previous generations of Llama are surprisingly good at identifying high-quality data, hence we used Llama 2 to generate the training data for the text-quality classifiers that are powering Llama 3.
We also performed extensive experiments to evaluate the best ways of mixing data from different sources in our final pretraining dataset. These experiments enabled us to select a data mix that ensures that Llama 3 performs well across use cases including trivia questions, STEM, coding, historical knowledge, etc.
Scaling up pretraining
To effectively leverage our pretraining data in Llama 3 models, we put substantial effort into scaling up pretraining. Specifically, we have developed a series of detailed scaling laws for downstream benchmark evaluations. These scaling laws enable us to select an optimal data mix and to make informed decisions on how to best use our training compute. Importantly, scaling laws allow us to predict the performance of our largest models on key tasks (for example, code generation as evaluated on the HumanEval benchmark—see above) before we actually train the models. This helps us ensure strong performance of our final models across a variety of use cases and capabilities.
We made several new observations on scaling behavior during the development of Llama 3. For example, while the Chinchilla-optimal amount of training compute for an 8B parameter model corresponds to ~200B tokens, we found that model performance continues to improve even after the model is trained on two orders of magnitude more data. Both our 8B and 70B parameter models continued to improve log-linearly after we trained them on up to 15T tokens. Larger models can match the performance of these smaller models with less training compute, but smaller models are generally preferred because they are much more efficient during inference.
To train our largest Llama 3 models, we combined three types of parallelization: data parallelization, model parallelization, and pipeline parallelization. Our most efficient implementation achieves a compute utilization of over 400 TFLOPS per GPU when trained on 16K GPUs simultaneously. We performed training runs on two custom-built 24K GPU clusters . To maximize GPU uptime, we developed an advanced new training stack that automates error detection, handling, and maintenance. We also greatly improved our hardware reliability and detection mechanisms for silent data corruption, and we developed new scalable storage systems that reduce overheads of checkpointing and rollback. Those improvements resulted in an overall effective training time of more than 95%. Combined, these improvements increased the efficiency of Llama 3 training by ~three times compared to Llama 2.
Instruction fine-tuning
To fully unlock the potential of our pretrained models in chat use cases, we innovated on our approach to instruction-tuning as well. Our approach to post-training is a combination of supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct preference optimization (DPO). The quality of the prompts that are used in SFT and the preference rankings that are used in PPO and DPO has an outsized influence on the performance of aligned models. Some of our biggest improvements in model quality came from carefully curating this data and performing multiple rounds of quality assurance on annotations provided by human annotators.
Learning from preference rankings via PPO and DPO also greatly improved the performance of Llama 3 on reasoning and coding tasks. We found that if you ask a model a reasoning question that it struggles to answer, the model will sometimes produce the right reasoning trace: The model knows how to produce the right answer, but it does not know how to select it. Training on preference rankings enables the model to learn how to select it.
Building with Llama 3
Our vision is to enable developers to customize Llama 3 to support relevant use cases and to make it easier to adopt best practices and improve the open ecosystem. With this release, we’re providing new trust and safety tools including updated components with both Llama Guard 2 and Cybersec Eval 2, and the introduction of Code Shield—an inference time guardrail for filtering insecure code produced by LLMs.
We’ve also co-developed Llama 3 with torchtune , the new PyTorch-native library for easily authoring, fine-tuning, and experimenting with LLMs. torchtune provides memory efficient and hackable training recipes written entirely in PyTorch. The library is integrated with popular platforms such as Hugging Face, Weights & Biases, and EleutherAI and even supports Executorch for enabling efficient inference to be run on a wide variety of mobile and edge devices. For everything from prompt engineering to using Llama 3 with LangChain we have a comprehensive getting started guide and takes you from downloading Llama 3 all the way to deployment at scale within your generative AI application.
A system-level approach to responsibility
We have designed Llama 3 models to be maximally helpful while ensuring an industry leading approach to responsibly deploying them. To achieve this, we have adopted a new, system-level approach to the responsible development and deployment of Llama. We envision Llama models as part of a broader system that puts the developer in the driver’s seat. Llama models will serve as a foundational piece of a system that developers design with their unique end goals in mind.

Instruction fine-tuning also plays a major role in ensuring the safety of our models. Our instruction-fine-tuned models have been red-teamed (tested) for safety through internal and external efforts. Our red teaming approach leverages human experts and automation methods to generate adversarial prompts that try to elicit problematic responses. For instance, we apply comprehensive testing to assess risks of misuse related to Chemical, Biological, Cyber Security, and other risk areas. All of these efforts are iterative and used to inform safety fine-tuning of the models being released. You can read more about our efforts in the model card .
Llama Guard models are meant to be a foundation for prompt and response safety and can easily be fine-tuned to create a new taxonomy depending on application needs. As a starting point, the new Llama Guard 2 uses the recently announced MLCommons taxonomy, in an effort to support the emergence of industry standards in this important area. Additionally, CyberSecEval 2 expands on its predecessor by adding measures of an LLM’s propensity to allow for abuse of its code interpreter, offensive cybersecurity capabilities, and susceptibility to prompt injection attacks (learn more in our technical paper ). Finally, we’re introducing Code Shield which adds support for inference-time filtering of insecure code produced by LLMs. This offers mitigation of risks around insecure code suggestions, code interpreter abuse prevention, and secure command execution.
With the speed at which the generative AI space is moving, we believe an open approach is an important way to bring the ecosystem together and mitigate these potential harms. As part of that, we’re updating our Responsible Use Guide (RUG) that provides a comprehensive guide to responsible development with LLMs. As we outlined in the RUG, we recommend that all inputs and outputs be checked and filtered in accordance with content guidelines appropriate to the application. Additionally, many cloud service providers offer content moderation APIs and other tools for responsible deployment, and we encourage developers to also consider using these options.
Deploying Llama 3 at scale
Llama 3 will soon be available on all major platforms including cloud providers, model API providers, and much more. Llama 3 will be everywhere .
Our benchmarks show the tokenizer offers improved token efficiency, yielding up to 15% fewer tokens compared to Llama 2. Also, Group Query Attention (GQA) now has been added to Llama 3 8B as well. As a result, we observed that despite the model having 1B more parameters compared to Llama 2 7B, the improved tokenizer efficiency and GQA contribute to maintaining the inference efficiency on par with Llama 2 7B.
For examples of how to leverage all of these capabilities, check out Llama Recipes which contains all of our open source code that can be leveraged for everything from fine-tuning to deployment to model evaluation.
What’s next for Llama 3?
The Llama 3 8B and 70B models mark the beginning of what we plan to release for Llama 3. And there’s a lot more to come.
Our largest models are over 400B parameters and, while these models are still training, our team is excited about how they’re trending. Over the coming months, we’ll release multiple models with new capabilities including multimodality, the ability to converse in multiple languages, a much longer context window, and stronger overall capabilities. We will also publish a detailed research paper once we are done training Llama 3.
To give you a sneak preview for where these models are today as they continue training, we thought we could share some snapshots of how our largest LLM model is trending. Please note that this data is based on an early checkpoint of Llama 3 that is still training and these capabilities are not supported as part of the models released today.

We’re committed to the continued growth and development of an open AI ecosystem for releasing our models responsibly. We have long believed that openness leads to better, safer products, faster innovation, and a healthier overall market. This is good for Meta, and it is good for society. We’re taking a community-first approach with Llama 3, and starting today, these models are available on the leading cloud, hosting, and hardware platforms with many more to come.
Try Meta Llama 3 today
We’ve integrated our latest models into Meta AI, which we believe is the world’s leading AI assistant. It’s now built with Llama 3 technology and it’s available in more countries across our apps.
You can use Meta AI on Facebook, Instagram, WhatsApp, Messenger, and the web to get things done, learn, create, and connect with the things that matter to you. You can read more about the Meta AI experience here .
Visit the Llama 3 website to download the models and reference the Getting Started Guide for the latest list of all available platforms.
You’ll also soon be able to test multimodal Meta AI on our Ray-Ban Meta smart glasses.
As always, we look forward to seeing all the amazing products and experiences you will build with Meta Llama 3.
Our latest updates delivered to your inbox
Subscribe to our newsletter to keep up with Meta AI news, events, research breakthroughs, and more.
Join us in the pursuit of what’s possible with AI.

Product experiences
Foundational models
Latest news
Meta © 2024
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 17 April 2024
The economic commitment of climate change
- Maximilian Kotz ORCID: orcid.org/0000-0003-2564-5043 1 , 2 ,
- Anders Levermann ORCID: orcid.org/0000-0003-4432-4704 1 , 2 &
- Leonie Wenz ORCID: orcid.org/0000-0002-8500-1568 1 , 3
Nature volume 628 , pages 551–557 ( 2024 ) Cite this article
80k Accesses
3415 Altmetric
Metrics details
- Environmental economics
- Environmental health
- Interdisciplinary studies
- Projection and prediction
Global projections of macroeconomic climate-change damages typically consider impacts from average annual and national temperatures over long time horizons 1 , 2 , 3 , 4 , 5 , 6 . Here we use recent empirical findings from more than 1,600 regions worldwide over the past 40 years to project sub-national damages from temperature and precipitation, including daily variability and extremes 7 , 8 . Using an empirical approach that provides a robust lower bound on the persistence of impacts on economic growth, we find that the world economy is committed to an income reduction of 19% within the next 26 years independent of future emission choices (relative to a baseline without climate impacts, likely range of 11–29% accounting for physical climate and empirical uncertainty). These damages already outweigh the mitigation costs required to limit global warming to 2 °C by sixfold over this near-term time frame and thereafter diverge strongly dependent on emission choices. Committed damages arise predominantly through changes in average temperature, but accounting for further climatic components raises estimates by approximately 50% and leads to stronger regional heterogeneity. Committed losses are projected for all regions except those at very high latitudes, at which reductions in temperature variability bring benefits. The largest losses are committed at lower latitudes in regions with lower cumulative historical emissions and lower present-day income.
Similar content being viewed by others

Climate damage projections beyond annual temperature

Investment incentive reduced by climate damages can be restored by optimal policy

Climate economics support for the UN climate targets
Projections of the macroeconomic damage caused by future climate change are crucial to informing public and policy debates about adaptation, mitigation and climate justice. On the one hand, adaptation against climate impacts must be justified and planned on the basis of an understanding of their future magnitude and spatial distribution 9 . This is also of importance in the context of climate justice 10 , as well as to key societal actors, including governments, central banks and private businesses, which increasingly require the inclusion of climate risks in their macroeconomic forecasts to aid adaptive decision-making 11 , 12 . On the other hand, climate mitigation policy such as the Paris Climate Agreement is often evaluated by balancing the costs of its implementation against the benefits of avoiding projected physical damages. This evaluation occurs both formally through cost–benefit analyses 1 , 4 , 5 , 6 , as well as informally through public perception of mitigation and damage costs 13 .
Projections of future damages meet challenges when informing these debates, in particular the human biases relating to uncertainty and remoteness that are raised by long-term perspectives 14 . Here we aim to overcome such challenges by assessing the extent of economic damages from climate change to which the world is already committed by historical emissions and socio-economic inertia (the range of future emission scenarios that are considered socio-economically plausible 15 ). Such a focus on the near term limits the large uncertainties about diverging future emission trajectories, the resulting long-term climate response and the validity of applying historically observed climate–economic relations over long timescales during which socio-technical conditions may change considerably. As such, this focus aims to simplify the communication and maximize the credibility of projected economic damages from future climate change.
In projecting the future economic damages from climate change, we make use of recent advances in climate econometrics that provide evidence for impacts on sub-national economic growth from numerous components of the distribution of daily temperature and precipitation 3 , 7 , 8 . Using fixed-effects panel regression models to control for potential confounders, these studies exploit within-region variation in local temperature and precipitation in a panel of more than 1,600 regions worldwide, comprising climate and income data over the past 40 years, to identify the plausibly causal effects of changes in several climate variables on economic productivity 16 , 17 . Specifically, macroeconomic impacts have been identified from changing daily temperature variability, total annual precipitation, the annual number of wet days and extreme daily rainfall that occur in addition to those already identified from changing average temperature 2 , 3 , 18 . Moreover, regional heterogeneity in these effects based on the prevailing local climatic conditions has been found using interactions terms. The selection of these climate variables follows micro-level evidence for mechanisms related to the impacts of average temperatures on labour and agricultural productivity 2 , of temperature variability on agricultural productivity and health 7 , as well as of precipitation on agricultural productivity, labour outcomes and flood damages 8 (see Extended Data Table 1 for an overview, including more detailed references). References 7 , 8 contain a more detailed motivation for the use of these particular climate variables and provide extensive empirical tests about the robustness and nature of their effects on economic output, which are summarized in Methods . By accounting for these extra climatic variables at the sub-national level, we aim for a more comprehensive description of climate impacts with greater detail across both time and space.
Constraining the persistence of impacts
A key determinant and source of discrepancy in estimates of the magnitude of future climate damages is the extent to which the impact of a climate variable on economic growth rates persists. The two extreme cases in which these impacts persist indefinitely or only instantaneously are commonly referred to as growth or level effects 19 , 20 (see Methods section ‘Empirical model specification: fixed-effects distributed lag models’ for mathematical definitions). Recent work shows that future damages from climate change depend strongly on whether growth or level effects are assumed 20 . Following refs. 2 , 18 , we provide constraints on this persistence by using distributed lag models to test the significance of delayed effects separately for each climate variable. Notably, and in contrast to refs. 2 , 18 , we use climate variables in their first-differenced form following ref. 3 , implying a dependence of the growth rate on a change in climate variables. This choice means that a baseline specification without any lags constitutes a model prior of purely level effects, in which a permanent change in the climate has only an instantaneous effect on the growth rate 3 , 19 , 21 . By including lags, one can then test whether any effects may persist further. This is in contrast to the specification used by refs. 2 , 18 , in which climate variables are used without taking the first difference, implying a dependence of the growth rate on the level of climate variables. In this alternative case, the baseline specification without any lags constitutes a model prior of pure growth effects, in which a change in climate has an infinitely persistent effect on the growth rate. Consequently, including further lags in this alternative case tests whether the initial growth impact is recovered 18 , 19 , 21 . Both of these specifications suffer from the limiting possibility that, if too few lags are included, one might falsely accept the model prior. The limitations of including a very large number of lags, including loss of data and increasing statistical uncertainty with an increasing number of parameters, mean that such a possibility is likely. By choosing a specification in which the model prior is one of level effects, our approach is therefore conservative by design, avoiding assumptions of infinite persistence of climate impacts on growth and instead providing a lower bound on this persistence based on what is observable empirically (see Methods section ‘Empirical model specification: fixed-effects distributed lag models’ for further exposition of this framework). The conservative nature of such a choice is probably the reason that ref. 19 finds much greater consistency between the impacts projected by models that use the first difference of climate variables, as opposed to their levels.
We begin our empirical analysis of the persistence of climate impacts on growth using ten lags of the first-differenced climate variables in fixed-effects distributed lag models. We detect substantial effects on economic growth at time lags of up to approximately 8–10 years for the temperature terms and up to approximately 4 years for the precipitation terms (Extended Data Fig. 1 and Extended Data Table 2 ). Furthermore, evaluation by means of information criteria indicates that the inclusion of all five climate variables and the use of these numbers of lags provide a preferable trade-off between best-fitting the data and including further terms that could cause overfitting, in comparison with model specifications excluding climate variables or including more or fewer lags (Extended Data Fig. 3 , Supplementary Methods Section 1 and Supplementary Table 1 ). We therefore remove statistically insignificant terms at later lags (Supplementary Figs. 1 – 3 and Supplementary Tables 2 – 4 ). Further tests using Monte Carlo simulations demonstrate that the empirical models are robust to autocorrelation in the lagged climate variables (Supplementary Methods Section 2 and Supplementary Figs. 4 and 5 ), that information criteria provide an effective indicator for lag selection (Supplementary Methods Section 2 and Supplementary Fig. 6 ), that the results are robust to concerns of imperfect multicollinearity between climate variables and that including several climate variables is actually necessary to isolate their separate effects (Supplementary Methods Section 3 and Supplementary Fig. 7 ). We provide a further robustness check using a restricted distributed lag model to limit oscillations in the lagged parameter estimates that may result from autocorrelation, finding that it provides similar estimates of cumulative marginal effects to the unrestricted model (Supplementary Methods Section 4 and Supplementary Figs. 8 and 9 ). Finally, to explicitly account for any outstanding uncertainty arising from the precise choice of the number of lags, we include empirical models with marginally different numbers of lags in the error-sampling procedure of our projection of future damages. On the basis of the lag-selection procedure (the significance of lagged terms in Extended Data Fig. 1 and Extended Data Table 2 , as well as information criteria in Extended Data Fig. 3 ), we sample from models with eight to ten lags for temperature and four for precipitation (models shown in Supplementary Figs. 1 – 3 and Supplementary Tables 2 – 4 ). In summary, this empirical approach to constrain the persistence of climate impacts on economic growth rates is conservative by design in avoiding assumptions of infinite persistence, but nevertheless provides a lower bound on the extent of impact persistence that is robust to the numerous tests outlined above.
Committed damages until mid-century
We combine these empirical economic response functions (Supplementary Figs. 1 – 3 and Supplementary Tables 2 – 4 ) with an ensemble of 21 climate models (see Supplementary Table 5 ) from the Coupled Model Intercomparison Project Phase 6 (CMIP-6) 22 to project the macroeconomic damages from these components of physical climate change (see Methods for further details). Bias-adjusted climate models that provide a highly accurate reproduction of observed climatological patterns with limited uncertainty (Supplementary Table 6 ) are used to avoid introducing biases in the projections. Following a well-developed literature 2 , 3 , 19 , these projections do not aim to provide a prediction of future economic growth. Instead, they are a projection of the exogenous impact of future climate conditions on the economy relative to the baselines specified by socio-economic projections, based on the plausibly causal relationships inferred by the empirical models and assuming ceteris paribus. Other exogenous factors relevant for the prediction of economic output are purposefully assumed constant.
A Monte Carlo procedure that samples from climate model projections, empirical models with different numbers of lags and model parameter estimates (obtained by 1,000 block-bootstrap resamples of each of the regressions in Supplementary Figs. 1 – 3 and Supplementary Tables 2 – 4 ) is used to estimate the combined uncertainty from these sources. Given these uncertainty distributions, we find that projected global damages are statistically indistinguishable across the two most extreme emission scenarios until 2049 (at the 5% significance level; Fig. 1 ). As such, the climate damages occurring before this time constitute those to which the world is already committed owing to the combination of past emissions and the range of future emission scenarios that are considered socio-economically plausible 15 . These committed damages comprise a permanent income reduction of 19% on average globally (population-weighted average) in comparison with a baseline without climate-change impacts (with a likely range of 11–29%, following the likelihood classification adopted by the Intergovernmental Panel on Climate Change (IPCC); see caption of Fig. 1 ). Even though levels of income per capita generally still increase relative to those of today, this constitutes a permanent income reduction for most regions, including North America and Europe (each with median income reductions of approximately 11%) and with South Asia and Africa being the most strongly affected (each with median income reductions of approximately 22%; Fig. 1 ). Under a middle-of-the road scenario of future income development (SSP2, in which SSP stands for Shared Socio-economic Pathway), this corresponds to global annual damages in 2049 of 38 trillion in 2005 international dollars (likely range of 19–59 trillion 2005 international dollars). Compared with empirical specifications that assume pure growth or pure level effects, our preferred specification that provides a robust lower bound on the extent of climate impact persistence produces damages between these two extreme assumptions (Extended Data Fig. 3 ).

Estimates of the projected reduction in income per capita from changes in all climate variables based on empirical models of climate impacts on economic output with a robust lower bound on their persistence (Extended Data Fig. 1 ) under a low-emission scenario compatible with the 2 °C warming target and a high-emission scenario (SSP2-RCP2.6 and SSP5-RCP8.5, respectively) are shown in purple and orange, respectively. Shading represents the 34% and 10% confidence intervals reflecting the likely and very likely ranges, respectively (following the likelihood classification adopted by the IPCC), having estimated uncertainty from a Monte Carlo procedure, which samples the uncertainty from the choice of physical climate models, empirical models with different numbers of lags and bootstrapped estimates of the regression parameters shown in Supplementary Figs. 1 – 3 . Vertical dashed lines show the time at which the climate damages of the two emission scenarios diverge at the 5% and 1% significance levels based on the distribution of differences between emission scenarios arising from the uncertainty sampling discussed above. Note that uncertainty in the difference of the two scenarios is smaller than the combined uncertainty of the two respective scenarios because samples of the uncertainty (climate model and empirical model choice, as well as model parameter bootstrap) are consistent across the two emission scenarios, hence the divergence of damages occurs while the uncertainty bounds of the two separate damage scenarios still overlap. Estimates of global mitigation costs from the three IAMs that provide results for the SSP2 baseline and SSP2-RCP2.6 scenario are shown in light green in the top panel, with the median of these estimates shown in bold.
Damages already outweigh mitigation costs
We compare the damages to which the world is committed over the next 25 years to estimates of the mitigation costs required to achieve the Paris Climate Agreement. Taking estimates of mitigation costs from the three integrated assessment models (IAMs) in the IPCC AR6 database 23 that provide results under comparable scenarios (SSP2 baseline and SSP2-RCP2.6, in which RCP stands for Representative Concentration Pathway), we find that the median committed climate damages are larger than the median mitigation costs in 2050 (six trillion in 2005 international dollars) by a factor of approximately six (note that estimates of mitigation costs are only provided every 10 years by the IAMs and so a comparison in 2049 is not possible). This comparison simply aims to compare the magnitude of future damages against mitigation costs, rather than to conduct a formal cost–benefit analysis of transitioning from one emission path to another. Formal cost–benefit analyses typically find that the net benefits of mitigation only emerge after 2050 (ref. 5 ), which may lead some to conclude that physical damages from climate change are simply not large enough to outweigh mitigation costs until the second half of the century. Our simple comparison of their magnitudes makes clear that damages are actually already considerably larger than mitigation costs and the delayed emergence of net mitigation benefits results primarily from the fact that damages across different emission paths are indistinguishable until mid-century (Fig. 1 ).
Although these near-term damages constitute those to which the world is already committed, we note that damage estimates diverge strongly across emission scenarios after 2049, conveying the clear benefits of mitigation from a purely economic point of view that have been emphasized in previous studies 4 , 24 . As well as the uncertainties assessed in Fig. 1 , these conclusions are robust to structural choices, such as the timescale with which changes in the moderating variables of the empirical models are estimated (Supplementary Figs. 10 and 11 ), as well as the order in which one accounts for the intertemporal and international components of currency comparison (Supplementary Fig. 12 ; see Methods for further details).
Damages from variability and extremes
Committed damages primarily arise through changes in average temperature (Fig. 2 ). This reflects the fact that projected changes in average temperature are larger than those in other climate variables when expressed as a function of their historical interannual variability (Extended Data Fig. 4 ). Because the historical variability is that on which the empirical models are estimated, larger projected changes in comparison with this variability probably lead to larger future impacts in a purely statistical sense. From a mechanistic perspective, one may plausibly interpret this result as implying that future changes in average temperature are the most unprecedented from the perspective of the historical fluctuations to which the economy is accustomed and therefore will cause the most damage. This insight may prove useful in terms of guiding adaptation measures to the sources of greatest damage.

Estimates of the median projected reduction in sub-national income per capita across emission scenarios (SSP2-RCP2.6 and SSP2-RCP8.5) as well as climate model, empirical model and model parameter uncertainty in the year in which climate damages diverge at the 5% level (2049, as identified in Fig. 1 ). a , Impacts arising from all climate variables. b – f , Impacts arising separately from changes in annual mean temperature ( b ), daily temperature variability ( c ), total annual precipitation ( d ), the annual number of wet days (>1 mm) ( e ) and extreme daily rainfall ( f ) (see Methods for further definitions). Data on national administrative boundaries are obtained from the GADM database version 3.6 and are freely available for academic use ( https://gadm.org/ ).
Nevertheless, future damages based on empirical models that consider changes in annual average temperature only and exclude the other climate variables constitute income reductions of only 13% in 2049 (Extended Data Fig. 5a , likely range 5–21%). This suggests that accounting for the other components of the distribution of temperature and precipitation raises net damages by nearly 50%. This increase arises through the further damages that these climatic components cause, but also because their inclusion reveals a stronger negative economic response to average temperatures (Extended Data Fig. 5b ). The latter finding is consistent with our Monte Carlo simulations, which suggest that the magnitude of the effect of average temperature on economic growth is underestimated unless accounting for the impacts of other correlated climate variables (Supplementary Fig. 7 ).
In terms of the relative contributions of the different climatic components to overall damages, we find that accounting for daily temperature variability causes the largest increase in overall damages relative to empirical frameworks that only consider changes in annual average temperature (4.9 percentage points, likely range 2.4–8.7 percentage points, equivalent to approximately 10 trillion international dollars). Accounting for precipitation causes smaller increases in overall damages, which are—nevertheless—equivalent to approximately 1.2 trillion international dollars: 0.01 percentage points (−0.37–0.33 percentage points), 0.34 percentage points (0.07–0.90 percentage points) and 0.36 percentage points (0.13–0.65 percentage points) from total annual precipitation, the number of wet days and extreme daily precipitation, respectively. Moreover, climate models seem to underestimate future changes in temperature variability 25 and extreme precipitation 26 , 27 in response to anthropogenic forcing as compared with that observed historically, suggesting that the true impacts from these variables may be larger.
The distribution of committed damages
The spatial distribution of committed damages (Fig. 2a ) reflects a complex interplay between the patterns of future change in several climatic components and those of historical economic vulnerability to changes in those variables. Damages resulting from increasing annual mean temperature (Fig. 2b ) are negative almost everywhere globally, and larger at lower latitudes in regions in which temperatures are already higher and economic vulnerability to temperature increases is greatest (see the response heterogeneity to mean temperature embodied in Extended Data Fig. 1a ). This occurs despite the amplified warming projected at higher latitudes 28 , suggesting that regional heterogeneity in economic vulnerability to temperature changes outweighs heterogeneity in the magnitude of future warming (Supplementary Fig. 13a ). Economic damages owing to daily temperature variability (Fig. 2c ) exhibit a strong latitudinal polarisation, primarily reflecting the physical response of daily variability to greenhouse forcing in which increases in variability across lower latitudes (and Europe) contrast decreases at high latitudes 25 (Supplementary Fig. 13b ). These two temperature terms are the dominant determinants of the pattern of overall damages (Fig. 2a ), which exhibits a strong polarity with damages across most of the globe except at the highest northern latitudes. Future changes in total annual precipitation mainly bring economic benefits except in regions of drying, such as the Mediterranean and central South America (Fig. 2d and Supplementary Fig. 13c ), but these benefits are opposed by changes in the number of wet days, which produce damages with a similar pattern of opposite sign (Fig. 2e and Supplementary Fig. 13d ). By contrast, changes in extreme daily rainfall produce damages in all regions, reflecting the intensification of daily rainfall extremes over global land areas 29 , 30 (Fig. 2f and Supplementary Fig. 13e ).
The spatial distribution of committed damages implies considerable injustice along two dimensions: culpability for the historical emissions that have caused climate change and pre-existing levels of socio-economic welfare. Spearman’s rank correlations indicate that committed damages are significantly larger in countries with smaller historical cumulative emissions, as well as in regions with lower current income per capita (Fig. 3 ). This implies that those countries that will suffer the most from the damages already committed are those that are least responsible for climate change and which also have the least resources to adapt to it.

Estimates of the median projected change in national income per capita across emission scenarios (RCP2.6 and RCP8.5) as well as climate model, empirical model and model parameter uncertainty in the year in which climate damages diverge at the 5% level (2049, as identified in Fig. 1 ) are plotted against cumulative national emissions per capita in 2020 (from the Global Carbon Project) and coloured by national income per capita in 2020 (from the World Bank) in a and vice versa in b . In each panel, the size of each scatter point is weighted by the national population in 2020 (from the World Bank). Inset numbers indicate the Spearman’s rank correlation ρ and P -values for a hypothesis test whose null hypothesis is of no correlation, as well as the Spearman’s rank correlation weighted by national population.
To further quantify this heterogeneity, we assess the difference in committed damages between the upper and lower quartiles of regions when ranked by present income levels and historical cumulative emissions (using a population weighting to both define the quartiles and estimate the group averages). On average, the quartile of countries with lower income are committed to an income loss that is 8.9 percentage points (or 61%) greater than the upper quartile (Extended Data Fig. 6 ), with a likely range of 3.8–14.7 percentage points across the uncertainty sampling of our damage projections (following the likelihood classification adopted by the IPCC). Similarly, the quartile of countries with lower historical cumulative emissions are committed to an income loss that is 6.9 percentage points (or 40%) greater than the upper quartile, with a likely range of 0.27–12 percentage points. These patterns reemphasize the prevalence of injustice in climate impacts 31 , 32 , 33 in the context of the damages to which the world is already committed by historical emissions and socio-economic inertia.
Contextualizing the magnitude of damages
The magnitude of projected economic damages exceeds previous literature estimates 2 , 3 , arising from several developments made on previous approaches. Our estimates are larger than those of ref. 2 (see first row of Extended Data Table 3 ), primarily because of the facts that sub-national estimates typically show a steeper temperature response (see also refs. 3 , 34 ) and that accounting for other climatic components raises damage estimates (Extended Data Fig. 5 ). However, we note that our empirical approach using first-differenced climate variables is conservative compared with that of ref. 2 in regard to the persistence of climate impacts on growth (see introduction and Methods section ‘Empirical model specification: fixed-effects distributed lag models’), an important determinant of the magnitude of long-term damages 19 , 21 . Using a similar empirical specification to ref. 2 , which assumes infinite persistence while maintaining the rest of our approach (sub-national data and further climate variables), produces considerably larger damages (purple curve of Extended Data Fig. 3 ). Compared with studies that do take the first difference of climate variables 3 , 35 , our estimates are also larger (see second and third rows of Extended Data Table 3 ). The inclusion of further climate variables (Extended Data Fig. 5 ) and a sufficient number of lags to more adequately capture the extent of impact persistence (Extended Data Figs. 1 and 2 ) are the main sources of this difference, as is the use of specifications that capture nonlinearities in the temperature response when compared with ref. 35 . In summary, our estimates develop on previous studies by incorporating the latest data and empirical insights 7 , 8 , as well as in providing a robust empirical lower bound on the persistence of impacts on economic growth, which constitutes a middle ground between the extremes of the growth-versus-levels debate 19 , 21 (Extended Data Fig. 3 ).
Compared with the fraction of variance explained by the empirical models historically (<5%), the projection of reductions in income of 19% may seem large. This arises owing to the fact that projected changes in climatic conditions are much larger than those that were experienced historically, particularly for changes in average temperature (Extended Data Fig. 4 ). As such, any assessment of future climate-change impacts necessarily requires an extrapolation outside the range of the historical data on which the empirical impact models were evaluated. Nevertheless, these models constitute the most state-of-the-art methods for inference of plausibly causal climate impacts based on observed data. Moreover, we take explicit steps to limit out-of-sample extrapolation by capping the moderating variables of the interaction terms at the 95th percentile of the historical distribution (see Methods ). This avoids extrapolating the marginal effects outside what was observed historically. Given the nonlinear response of economic output to annual mean temperature (Extended Data Fig. 1 and Extended Data Table 2 ), this is a conservative choice that limits the magnitude of damages that we project. Furthermore, back-of-the-envelope calculations indicate that the projected damages are consistent with the magnitude and patterns of historical economic development (see Supplementary Discussion Section 5 ).
Missing impacts and spatial spillovers
Despite assessing several climatic components from which economic impacts have recently been identified 3 , 7 , 8 , this assessment of aggregate climate damages should not be considered comprehensive. Important channels such as impacts from heatwaves 31 , sea-level rise 36 , tropical cyclones 37 and tipping points 38 , 39 , as well as non-market damages such as those to ecosystems 40 and human health 41 , are not considered in these estimates. Sea-level rise is unlikely to be feasibly incorporated into empirical assessments such as this because historical sea-level variability is mostly small. Non-market damages are inherently intractable within our estimates of impacts on aggregate monetary output and estimates of these impacts could arguably be considered as extra to those identified here. Recent empirical work suggests that accounting for these channels would probably raise estimates of these committed damages, with larger damages continuing to arise in the global south 31 , 36 , 37 , 38 , 39 , 40 , 41 , 42 .
Moreover, our main empirical analysis does not explicitly evaluate the potential for impacts in local regions to produce effects that ‘spill over’ into other regions. Such effects may further mitigate or amplify the impacts we estimate, for example, if companies relocate production from one affected region to another or if impacts propagate along supply chains. The current literature indicates that trade plays a substantial role in propagating spillover effects 43 , 44 , making their assessment at the sub-national level challenging without available data on sub-national trade dependencies. Studies accounting for only spatially adjacent neighbours indicate that negative impacts in one region induce further negative impacts in neighbouring regions 45 , 46 , 47 , 48 , suggesting that our projected damages are probably conservative by excluding these effects. In Supplementary Fig. 14 , we assess spillovers from neighbouring regions using a spatial-lag model. For simplicity, this analysis excludes temporal lags, focusing only on contemporaneous effects. The results show that accounting for spatial spillovers can amplify the overall magnitude, and also the heterogeneity, of impacts. Consistent with previous literature, this indicates that the overall magnitude (Fig. 1 ) and heterogeneity (Fig. 3 ) of damages that we project in our main specification may be conservative without explicitly accounting for spillovers. We note that further analysis that addresses both spatially and trade-connected spillovers, while also accounting for delayed impacts using temporal lags, would be necessary to adequately address this question fully. These approaches offer fruitful avenues for further research but are beyond the scope of this manuscript, which primarily aims to explore the impacts of different climate conditions and their persistence.
Policy implications
We find that the economic damages resulting from climate change until 2049 are those to which the world economy is already committed and that these greatly outweigh the costs required to mitigate emissions in line with the 2 °C target of the Paris Climate Agreement (Fig. 1 ). This assessment is complementary to formal analyses of the net costs and benefits associated with moving from one emission path to another, which typically find that net benefits of mitigation only emerge in the second half of the century 5 . Our simple comparison of the magnitude of damages and mitigation costs makes clear that this is primarily because damages are indistinguishable across emissions scenarios—that is, committed—until mid-century (Fig. 1 ) and that they are actually already much larger than mitigation costs. For simplicity, and owing to the availability of data, we compare damages to mitigation costs at the global level. Regional estimates of mitigation costs may shed further light on the national incentives for mitigation to which our results already hint, of relevance for international climate policy. Although these damages are committed from a mitigation perspective, adaptation may provide an opportunity to reduce them. Moreover, the strong divergence of damages after mid-century reemphasizes the clear benefits of mitigation from a purely economic perspective, as highlighted in previous studies 1 , 4 , 6 , 24 .
Historical climate data
Historical daily 2-m temperature and precipitation totals (in mm) are obtained for the period 1979–2019 from the W5E5 database. The W5E5 dataset comes from ERA-5, a state-of-the-art reanalysis of historical observations, but has been bias-adjusted by applying version 2.0 of the WATCH Forcing Data to ERA-5 reanalysis data and precipitation data from version 2.3 of the Global Precipitation Climatology Project to better reflect ground-based measurements 49 , 50 , 51 . We obtain these data on a 0.5° × 0.5° grid from the Inter-Sectoral Impact Model Intercomparison Project (ISIMIP) database. Notably, these historical data have been used to bias-adjust future climate projections from CMIP-6 (see the following section), ensuring consistency between the distribution of historical daily weather on which our empirical models were estimated and the climate projections used to estimate future damages. These data are publicly available from the ISIMIP database. See refs. 7 , 8 for robustness tests of the empirical models to the choice of climate data reanalysis products.
Future climate data
Daily 2-m temperature and precipitation totals (in mm) are taken from 21 climate models participating in CMIP-6 under a high (RCP8.5) and a low (RCP2.6) greenhouse gas emission scenario from 2015 to 2100. The data have been bias-adjusted and statistically downscaled to a common half-degree grid to reflect the historical distribution of daily temperature and precipitation of the W5E5 dataset using the trend-preserving method developed by the ISIMIP 50 , 52 . As such, the climate model data reproduce observed climatological patterns exceptionally well (Supplementary Table 5 ). Gridded data are publicly available from the ISIMIP database.
Historical economic data
Historical economic data come from the DOSE database of sub-national economic output 53 . We use a recent revision to the DOSE dataset that provides data across 83 countries, 1,660 sub-national regions with varying temporal coverage from 1960 to 2019. Sub-national units constitute the first administrative division below national, for example, states for the USA and provinces for China. Data come from measures of gross regional product per capita (GRPpc) or income per capita in local currencies, reflecting the values reported in national statistical agencies, yearbooks and, in some cases, academic literature. We follow previous literature 3 , 7 , 8 , 54 and assess real sub-national output per capita by first converting values from local currencies to US dollars to account for diverging national inflationary tendencies and then account for US inflation using a US deflator. Alternatively, one might first account for national inflation and then convert between currencies. Supplementary Fig. 12 demonstrates that our conclusions are consistent when accounting for price changes in the reversed order, although the magnitude of estimated damages varies. See the documentation of the DOSE dataset for further discussion of these choices. Conversions between currencies are conducted using exchange rates from the FRED database of the Federal Reserve Bank of St. Louis 55 and the national deflators from the World Bank 56 .
Future socio-economic data
Baseline gridded gross domestic product (GDP) and population data for the period 2015–2100 are taken from the middle-of-the-road scenario SSP2 (ref. 15 ). Population data have been downscaled to a half-degree grid by the ISIMIP following the methodologies of refs. 57 , 58 , which we then aggregate to the sub-national level of our economic data using the spatial aggregation procedure described below. Because current methodologies for downscaling the GDP of the SSPs use downscaled population to do so, per-capita estimates of GDP with a realistic distribution at the sub-national level are not readily available for the SSPs. We therefore use national-level GDP per capita (GDPpc) projections for all sub-national regions of a given country, assuming homogeneity within countries in terms of baseline GDPpc. Here we use projections that have been updated to account for the impact of the COVID-19 pandemic on the trajectory of future income, while remaining consistent with the long-term development of the SSPs 59 . The choice of baseline SSP alters the magnitude of projected climate damages in monetary terms, but when assessed in terms of percentage change from the baseline, the choice of socio-economic scenario is inconsequential. Gridded SSP population data and national-level GDPpc data are publicly available from the ISIMIP database. Sub-national estimates as used in this study are available in the code and data replication files.
Climate variables
Following recent literature 3 , 7 , 8 , we calculate an array of climate variables for which substantial impacts on macroeconomic output have been identified empirically, supported by further evidence at the micro level for plausible underlying mechanisms. See refs. 7 , 8 for an extensive motivation for the use of these particular climate variables and for detailed empirical tests on the nature and robustness of their effects on economic output. To summarize, these studies have found evidence for independent impacts on economic growth rates from annual average temperature, daily temperature variability, total annual precipitation, the annual number of wet days and extreme daily rainfall. Assessments of daily temperature variability were motivated by evidence of impacts on agricultural output and human health, as well as macroeconomic literature on the impacts of volatility on growth when manifest in different dimensions, such as government spending, exchange rates and even output itself 7 . Assessments of precipitation impacts were motivated by evidence of impacts on agricultural productivity, metropolitan labour outcomes and conflict, as well as damages caused by flash flooding 8 . See Extended Data Table 1 for detailed references to empirical studies of these physical mechanisms. Marked impacts of daily temperature variability, total annual precipitation, the number of wet days and extreme daily rainfall on macroeconomic output were identified robustly across different climate datasets, spatial aggregation schemes, specifications of regional time trends and error-clustering approaches. They were also found to be robust to the consideration of temperature extremes 7 , 8 . Furthermore, these climate variables were identified as having independent effects on economic output 7 , 8 , which we further explain here using Monte Carlo simulations to demonstrate the robustness of the results to concerns of imperfect multicollinearity between climate variables (Supplementary Methods Section 2 ), as well as by using information criteria (Supplementary Table 1 ) to demonstrate that including several lagged climate variables provides a preferable trade-off between optimally describing the data and limiting the possibility of overfitting.
We calculate these variables from the distribution of daily, d , temperature, T x , d , and precipitation, P x , d , at the grid-cell, x , level for both the historical and future climate data. As well as annual mean temperature, \({\bar{T}}_{x,y}\) , and annual total precipitation, P x , y , we calculate annual, y , measures of daily temperature variability, \({\widetilde{T}}_{x,y}\) :
the number of wet days, Pwd x , y :
and extreme daily rainfall:
in which T x , d , m , y is the grid-cell-specific daily temperature in month m and year y , \({\bar{T}}_{x,m,{y}}\) is the year and grid-cell-specific monthly, m , mean temperature, D m and D y the number of days in a given month m or year y , respectively, H the Heaviside step function, 1 mm the threshold used to define wet days and P 99.9 x is the 99.9th percentile of historical (1979–2019) daily precipitation at the grid-cell level. Units of the climate measures are degrees Celsius for annual mean temperature and daily temperature variability, millimetres for total annual precipitation and extreme daily precipitation, and simply the number of days for the annual number of wet days.
We also calculated weighted standard deviations of monthly rainfall totals as also used in ref. 8 but do not include them in our projections as we find that, when accounting for delayed effects, their effect becomes statistically indistinct and is better captured by changes in total annual rainfall.
Spatial aggregation
We aggregate grid-cell-level historical and future climate measures, as well as grid-cell-level future GDPpc and population, to the level of the first administrative unit below national level of the GADM database, using an area-weighting algorithm that estimates the portion of each grid cell falling within an administrative boundary. We use this as our baseline specification following previous findings that the effect of area or population weighting at the sub-national level is negligible 7 , 8 .
Empirical model specification: fixed-effects distributed lag models
Following a wide range of climate econometric literature 16 , 60 , we use panel regression models with a selection of fixed effects and time trends to isolate plausibly exogenous variation with which to maximize confidence in a causal interpretation of the effects of climate on economic growth rates. The use of region fixed effects, μ r , accounts for unobserved time-invariant differences between regions, such as prevailing climatic norms and growth rates owing to historical and geopolitical factors. The use of yearly fixed effects, η y , accounts for regionally invariant annual shocks to the global climate or economy such as the El Niño–Southern Oscillation or global recessions. In our baseline specification, we also include region-specific linear time trends, k r y , to exclude the possibility of spurious correlations resulting from common slow-moving trends in climate and growth.
The persistence of climate impacts on economic growth rates is a key determinant of the long-term magnitude of damages. Methods for inferring the extent of persistence in impacts on growth rates have typically used lagged climate variables to evaluate the presence of delayed effects or catch-up dynamics 2 , 18 . For example, consider starting from a model in which a climate condition, C r , y , (for example, annual mean temperature) affects the growth rate, Δlgrp r , y (the first difference of the logarithm of gross regional product) of region r in year y :
which we refer to as a ‘pure growth effects’ model in the main text. Typically, further lags are included,
and the cumulative effect of all lagged terms is evaluated to assess the extent to which climate impacts on growth rates persist. Following ref. 18 , in the case that,
the implication is that impacts on the growth rate persist up to NL years after the initial shock (possibly to a weaker or a stronger extent), whereas if
then the initial impact on the growth rate is recovered after NL years and the effect is only one on the level of output. However, we note that such approaches are limited by the fact that, when including an insufficient number of lags to detect a recovery of the growth rates, one may find equation ( 6 ) to be satisfied and incorrectly assume that a change in climatic conditions affects the growth rate indefinitely. In practice, given a limited record of historical data, including too few lags to confidently conclude in an infinitely persistent impact on the growth rate is likely, particularly over the long timescales over which future climate damages are often projected 2 , 24 . To avoid this issue, we instead begin our analysis with a model for which the level of output, lgrp r , y , depends on the level of a climate variable, C r , y :
Given the non-stationarity of the level of output, we follow the literature 19 and estimate such an equation in first-differenced form as,
which we refer to as a model of ‘pure level effects’ in the main text. This model constitutes a baseline specification in which a permanent change in the climate variable produces an instantaneous impact on the growth rate and a permanent effect only on the level of output. By including lagged variables in this specification,
we are able to test whether the impacts on the growth rate persist any further than instantaneously by evaluating whether α L > 0 are statistically significantly different from zero. Even though this framework is also limited by the possibility of including too few lags, the choice of a baseline model specification in which impacts on the growth rate do not persist means that, in the case of including too few lags, the framework reverts to the baseline specification of level effects. As such, this framework is conservative with respect to the persistence of impacts and the magnitude of future damages. It naturally avoids assumptions of infinite persistence and we are able to interpret any persistence that we identify with equation ( 9 ) as a lower bound on the extent of climate impact persistence on growth rates. See the main text for further discussion of this specification choice, in particular about its conservative nature compared with previous literature estimates, such as refs. 2 , 18 .
We allow the response to climatic changes to vary across regions, using interactions of the climate variables with historical average (1979–2019) climatic conditions reflecting heterogenous effects identified in previous work 7 , 8 . Following this previous work, the moderating variables of these interaction terms constitute the historical average of either the variable itself or of the seasonal temperature difference, \({\hat{T}}_{r}\) , or annual mean temperature, \({\bar{T}}_{r}\) , in the case of daily temperature variability 7 and extreme daily rainfall, respectively 8 .
The resulting regression equation with N and M lagged variables, respectively, reads:
in which Δlgrp r , y is the annual, regional GRPpc growth rate, measured as the first difference of the logarithm of real GRPpc, following previous work 2 , 3 , 7 , 8 , 18 , 19 . Fixed-effects regressions were run using the fixest package in R (ref. 61 ).
Estimates of the coefficients of interest α i , L are shown in Extended Data Fig. 1 for N = M = 10 lags and for our preferred choice of the number of lags in Supplementary Figs. 1 – 3 . In Extended Data Fig. 1 , errors are shown clustered at the regional level, but for the construction of damage projections, we block-bootstrap the regressions by region 1,000 times to provide a range of parameter estimates with which to sample the projection uncertainty (following refs. 2 , 31 ).
Spatial-lag model
In Supplementary Fig. 14 , we present the results from a spatial-lag model that explores the potential for climate impacts to ‘spill over’ into spatially neighbouring regions. We measure the distance between centroids of each pair of sub-national regions and construct spatial lags that take the average of the first-differenced climate variables and their interaction terms over neighbouring regions that are at distances of 0–500, 500–1,000, 1,000–1,500 and 1,500–2000 km (spatial lags, ‘SL’, 1 to 4). For simplicity, we then assess a spatial-lag model without temporal lags to assess spatial spillovers of contemporaneous climate impacts. This model takes the form:
in which SL indicates the spatial lag of each climate variable and interaction term. In Supplementary Fig. 14 , we plot the cumulative marginal effect of each climate variable at different baseline climate conditions by summing the coefficients for each climate variable and interaction term, for example, for average temperature impacts as:
These cumulative marginal effects can be regarded as the overall spatially dependent impact to an individual region given a one-unit shock to a climate variable in that region and all neighbouring regions at a given value of the moderating variable of the interaction term.
Constructing projections of economic damage from future climate change
We construct projections of future climate damages by applying the coefficients estimated in equation ( 10 ) and shown in Supplementary Tables 2 – 4 (when including only lags with statistically significant effects in specifications that limit overfitting; see Supplementary Methods Section 1 ) to projections of future climate change from the CMIP-6 models. Year-on-year changes in each primary climate variable of interest are calculated to reflect the year-to-year variations used in the empirical models. 30-year moving averages of the moderating variables of the interaction terms are calculated to reflect the long-term average of climatic conditions that were used for the moderating variables in the empirical models. By using moving averages in the projections, we account for the changing vulnerability to climate shocks based on the evolving long-term conditions (Supplementary Figs. 10 and 11 show that the results are robust to the precise choice of the window of this moving average). Although these climate variables are not differenced, the fact that the bias-adjusted climate models reproduce observed climatological patterns across regions for these moderating variables very accurately (Supplementary Table 6 ) with limited spread across models (<3%) precludes the possibility that any considerable bias or uncertainty is introduced by this methodological choice. However, we impose caps on these moderating variables at the 95th percentile at which they were observed in the historical data to prevent extrapolation of the marginal effects outside the range in which the regressions were estimated. This is a conservative choice that limits the magnitude of our damage projections.
Time series of primary climate variables and moderating climate variables are then combined with estimates of the empirical model parameters to evaluate the regression coefficients in equation ( 10 ), producing a time series of annual GRPpc growth-rate reductions for a given emission scenario, climate model and set of empirical model parameters. The resulting time series of growth-rate impacts reflects those occurring owing to future climate change. By contrast, a future scenario with no climate change would be one in which climate variables do not change (other than with random year-to-year fluctuations) and hence the time-averaged evaluation of equation ( 10 ) would be zero. Our approach therefore implicitly compares the future climate-change scenario to this no-climate-change baseline scenario.
The time series of growth-rate impacts owing to future climate change in region r and year y , δ r , y , are then added to the future baseline growth rates, π r , y (in log-diff form), obtained from the SSP2 scenario to yield trajectories of damaged GRPpc growth rates, ρ r , y . These trajectories are aggregated over time to estimate the future trajectory of GRPpc with future climate impacts:
in which GRPpc r , y =2020 is the initial log level of GRPpc. We begin damage estimates in 2020 to reflect the damages occurring since the end of the period for which we estimate the empirical models (1979–2019) and to match the timing of mitigation-cost estimates from most IAMs (see below).
For each emission scenario, this procedure is repeated 1,000 times while randomly sampling from the selection of climate models, the selection of empirical models with different numbers of lags (shown in Supplementary Figs. 1 – 3 and Supplementary Tables 2 – 4 ) and bootstrapped estimates of the regression parameters. The result is an ensemble of future GRPpc trajectories that reflect uncertainty from both physical climate change and the structural and sampling uncertainty of the empirical models.
Estimates of mitigation costs
We obtain IPCC estimates of the aggregate costs of emission mitigation from the AR6 Scenario Explorer and Database hosted by IIASA 23 . Specifically, we search the AR6 Scenarios Database World v1.1 for IAMs that provided estimates of global GDP and population under both a SSP2 baseline and a SSP2-RCP2.6 scenario to maintain consistency with the socio-economic and emission scenarios of the climate damage projections. We find five IAMs that provide data for these scenarios, namely, MESSAGE-GLOBIOM 1.0, REMIND-MAgPIE 1.5, AIM/GCE 2.0, GCAM 4.2 and WITCH-GLOBIOM 3.1. Of these five IAMs, we use the results only from the first three that passed the IPCC vetting procedure for reproducing historical emission and climate trajectories. We then estimate global mitigation costs as the percentage difference in global per capita GDP between the SSP2 baseline and the SSP2-RCP2.6 emission scenario. In the case of one of these IAMs, estimates of mitigation costs begin in 2020, whereas in the case of two others, mitigation costs begin in 2010. The mitigation cost estimates before 2020 in these two IAMs are mostly negligible, and our choice to begin comparison with damage estimates in 2020 is conservative with respect to the relative weight of climate damages compared with mitigation costs for these two IAMs.
Data availability
Data on economic production and ERA-5 climate data are publicly available at https://doi.org/10.5281/zenodo.4681306 (ref. 62 ) and https://www.ecmwf.int/en/forecasts/datasets/reanalysis-datasets/era5 , respectively. Data on mitigation costs are publicly available at https://data.ene.iiasa.ac.at/ar6/#/downloads . Processed climate and economic data, as well as all other necessary data for reproduction of the results, are available at the public repository https://doi.org/10.5281/zenodo.10562951 (ref. 63 ).
Code availability
All code necessary for reproduction of the results is available at the public repository https://doi.org/10.5281/zenodo.10562951 (ref. 63 ).
Glanemann, N., Willner, S. N. & Levermann, A. Paris Climate Agreement passes the cost-benefit test. Nat. Commun. 11 , 110 (2020).
Article ADS CAS PubMed PubMed Central Google Scholar
Burke, M., Hsiang, S. M. & Miguel, E. Global non-linear effect of temperature on economic production. Nature 527 , 235–239 (2015).
Article ADS CAS PubMed Google Scholar
Kalkuhl, M. & Wenz, L. The impact of climate conditions on economic production. Evidence from a global panel of regions. J. Environ. Econ. Manag. 103 , 102360 (2020).
Article Google Scholar
Moore, F. C. & Diaz, D. B. Temperature impacts on economic growth warrant stringent mitigation policy. Nat. Clim. Change 5 , 127–131 (2015).
Article ADS Google Scholar
Drouet, L., Bosetti, V. & Tavoni, M. Net economic benefits of well-below 2°C scenarios and associated uncertainties. Oxf. Open Clim. Change 2 , kgac003 (2022).
Ueckerdt, F. et al. The economically optimal warming limit of the planet. Earth Syst. Dyn. 10 , 741–763 (2019).
Kotz, M., Wenz, L., Stechemesser, A., Kalkuhl, M. & Levermann, A. Day-to-day temperature variability reduces economic growth. Nat. Clim. Change 11 , 319–325 (2021).
Kotz, M., Levermann, A. & Wenz, L. The effect of rainfall changes on economic production. Nature 601 , 223–227 (2022).
Kousky, C. Informing climate adaptation: a review of the economic costs of natural disasters. Energy Econ. 46 , 576–592 (2014).
Harlan, S. L. et al. in Climate Change and Society: Sociological Perspectives (eds Dunlap, R. E. & Brulle, R. J.) 127–163 (Oxford Univ. Press, 2015).
Bolton, P. et al. The Green Swan (BIS Books, 2020).
Alogoskoufis, S. et al. ECB Economy-wide Climate Stress Test: Methodology and Results European Central Bank, 2021).
Weber, E. U. What shapes perceptions of climate change? Wiley Interdiscip. Rev. Clim. Change 1 , 332–342 (2010).
Markowitz, E. M. & Shariff, A. F. Climate change and moral judgement. Nat. Clim. Change 2 , 243–247 (2012).
Riahi, K. et al. The shared socioeconomic pathways and their energy, land use, and greenhouse gas emissions implications: an overview. Glob. Environ. Change 42 , 153–168 (2017).
Auffhammer, M., Hsiang, S. M., Schlenker, W. & Sobel, A. Using weather data and climate model output in economic analyses of climate change. Rev. Environ. Econ. Policy 7 , 181–198 (2013).
Kolstad, C. D. & Moore, F. C. Estimating the economic impacts of climate change using weather observations. Rev. Environ. Econ. Policy 14 , 1–24 (2020).
Dell, M., Jones, B. F. & Olken, B. A. Temperature shocks and economic growth: evidence from the last half century. Am. Econ. J. Macroecon. 4 , 66–95 (2012).
Newell, R. G., Prest, B. C. & Sexton, S. E. The GDP-temperature relationship: implications for climate change damages. J. Environ. Econ. Manag. 108 , 102445 (2021).
Kikstra, J. S. et al. The social cost of carbon dioxide under climate-economy feedbacks and temperature variability. Environ. Res. Lett. 16 , 094037 (2021).
Article ADS CAS Google Scholar
Bastien-Olvera, B. & Moore, F. Persistent effect of temperature on GDP identified from lower frequency temperature variability. Environ. Res. Lett. 17 , 084038 (2022).
Eyring, V. et al. Overview of the Coupled Model Intercomparison Project Phase 6 (CMIP6) experimental design and organization. Geosci. Model Dev. 9 , 1937–1958 (2016).
Byers, E. et al. AR6 scenarios database. Zenodo https://zenodo.org/records/7197970 (2022).
Burke, M., Davis, W. M. & Diffenbaugh, N. S. Large potential reduction in economic damages under UN mitigation targets. Nature 557 , 549–553 (2018).
Kotz, M., Wenz, L. & Levermann, A. Footprint of greenhouse forcing in daily temperature variability. Proc. Natl Acad. Sci. 118 , e2103294118 (2021).
Article CAS PubMed PubMed Central Google Scholar
Myhre, G. et al. Frequency of extreme precipitation increases extensively with event rareness under global warming. Sci. Rep. 9 , 16063 (2019).
Min, S.-K., Zhang, X., Zwiers, F. W. & Hegerl, G. C. Human contribution to more-intense precipitation extremes. Nature 470 , 378–381 (2011).
England, M. R., Eisenman, I., Lutsko, N. J. & Wagner, T. J. The recent emergence of Arctic Amplification. Geophys. Res. Lett. 48 , e2021GL094086 (2021).
Fischer, E. M. & Knutti, R. Anthropogenic contribution to global occurrence of heavy-precipitation and high-temperature extremes. Nat. Clim. Change 5 , 560–564 (2015).
Pfahl, S., O’Gorman, P. A. & Fischer, E. M. Understanding the regional pattern of projected future changes in extreme precipitation. Nat. Clim. Change 7 , 423–427 (2017).
Callahan, C. W. & Mankin, J. S. Globally unequal effect of extreme heat on economic growth. Sci. Adv. 8 , eadd3726 (2022).
Diffenbaugh, N. S. & Burke, M. Global warming has increased global economic inequality. Proc. Natl Acad. Sci. 116 , 9808–9813 (2019).
Callahan, C. W. & Mankin, J. S. National attribution of historical climate damages. Clim. Change 172 , 40 (2022).
Burke, M. & Tanutama, V. Climatic constraints on aggregate economic output. National Bureau of Economic Research, Working Paper 25779. https://doi.org/10.3386/w25779 (2019).
Kahn, M. E. et al. Long-term macroeconomic effects of climate change: a cross-country analysis. Energy Econ. 104 , 105624 (2021).
Desmet, K. et al. Evaluating the economic cost of coastal flooding. National Bureau of Economic Research, Working Paper 24918. https://doi.org/10.3386/w24918 (2018).
Hsiang, S. M. & Jina, A. S. The causal effect of environmental catastrophe on long-run economic growth: evidence from 6,700 cyclones. National Bureau of Economic Research, Working Paper 20352. https://doi.org/10.3386/w2035 (2014).
Ritchie, P. D. et al. Shifts in national land use and food production in Great Britain after a climate tipping point. Nat. Food 1 , 76–83 (2020).
Dietz, S., Rising, J., Stoerk, T. & Wagner, G. Economic impacts of tipping points in the climate system. Proc. Natl Acad. Sci. 118 , e2103081118 (2021).
Bastien-Olvera, B. A. & Moore, F. C. Use and non-use value of nature and the social cost of carbon. Nat. Sustain. 4 , 101–108 (2021).
Carleton, T. et al. Valuing the global mortality consequences of climate change accounting for adaptation costs and benefits. Q. J. Econ. 137 , 2037–2105 (2022).
Bastien-Olvera, B. A. et al. Unequal climate impacts on global values of natural capital. Nature 625 , 722–727 (2024).
Malik, A. et al. Impacts of climate change and extreme weather on food supply chains cascade across sectors and regions in Australia. Nat. Food 3 , 631–643 (2022).
Article ADS PubMed Google Scholar
Kuhla, K., Willner, S. N., Otto, C., Geiger, T. & Levermann, A. Ripple resonance amplifies economic welfare loss from weather extremes. Environ. Res. Lett. 16 , 114010 (2021).
Schleypen, J. R., Mistry, M. N., Saeed, F. & Dasgupta, S. Sharing the burden: quantifying climate change spillovers in the European Union under the Paris Agreement. Spat. Econ. Anal. 17 , 67–82 (2022).
Dasgupta, S., Bosello, F., De Cian, E. & Mistry, M. Global temperature effects on economic activity and equity: a spatial analysis. European Institute on Economics and the Environment, Working Paper 22-1 (2022).
Neal, T. The importance of external weather effects in projecting the macroeconomic impacts of climate change. UNSW Economics Working Paper 2023-09 (2023).
Deryugina, T. & Hsiang, S. M. Does the environment still matter? Daily temperature and income in the United States. National Bureau of Economic Research, Working Paper 20750. https://doi.org/10.3386/w20750 (2014).
Hersbach, H. et al. The ERA5 global reanalysis. Q. J. R. Meteorol. Soc. 146 , 1999–2049 (2020).
Cucchi, M. et al. WFDE5: bias-adjusted ERA5 reanalysis data for impact studies. Earth Syst. Sci. Data 12 , 2097–2120 (2020).
Adler, R. et al. The New Version 2.3 of the Global Precipitation Climatology Project (GPCP) Monthly Analysis Product 1072–1084 (University of Maryland, 2016).
Lange, S. Trend-preserving bias adjustment and statistical downscaling with ISIMIP3BASD (v1.0). Geosci. Model Dev. 12 , 3055–3070 (2019).
Wenz, L., Carr, R. D., Kögel, N., Kotz, M. & Kalkuhl, M. DOSE – global data set of reported sub-national economic output. Sci. Data 10 , 425 (2023).
Article PubMed PubMed Central Google Scholar
Gennaioli, N., La Porta, R., Lopez De Silanes, F. & Shleifer, A. Growth in regions. J. Econ. Growth 19 , 259–309 (2014).
Board of Governors of the Federal Reserve System (US). U.S. dollars to euro spot exchange rate. https://fred.stlouisfed.org/series/AEXUSEU (2022).
World Bank. GDP deflator. https://data.worldbank.org/indicator/NY.GDP.DEFL.ZS (2022).
Jones, B. & O’Neill, B. C. Spatially explicit global population scenarios consistent with the Shared Socioeconomic Pathways. Environ. Res. Lett. 11 , 084003 (2016).
Murakami, D. & Yamagata, Y. Estimation of gridded population and GDP scenarios with spatially explicit statistical downscaling. Sustainability 11 , 2106 (2019).
Koch, J. & Leimbach, M. Update of SSP GDP projections: capturing recent changes in national accounting, PPP conversion and Covid 19 impacts. Ecol. Econ. 206 (2023).
Carleton, T. A. & Hsiang, S. M. Social and economic impacts of climate. Science 353 , aad9837 (2016).
Article PubMed Google Scholar
Bergé, L. Efficient estimation of maximum likelihood models with multiple fixed-effects: the R package FENmlm. DEM Discussion Paper Series 18-13 (2018).
Kalkuhl, M., Kotz, M. & Wenz, L. DOSE - The MCC-PIK Database Of Subnational Economic output. Zenodo https://zenodo.org/doi/10.5281/zenodo.4681305 (2021).
Kotz, M., Wenz, L. & Levermann, A. Data and code for “The economic commitment of climate change”. Zenodo https://zenodo.org/doi/10.5281/zenodo.10562951 (2024).
Dasgupta, S. et al. Effects of climate change on combined labour productivity and supply: an empirical, multi-model study. Lancet Planet. Health 5 , e455–e465 (2021).
Lobell, D. B. et al. The critical role of extreme heat for maize production in the United States. Nat. Clim. Change 3 , 497–501 (2013).
Zhao, C. et al. Temperature increase reduces global yields of major crops in four independent estimates. Proc. Natl Acad. Sci. 114 , 9326–9331 (2017).
Wheeler, T. R., Craufurd, P. Q., Ellis, R. H., Porter, J. R. & Prasad, P. V. Temperature variability and the yield of annual crops. Agric. Ecosyst. Environ. 82 , 159–167 (2000).
Rowhani, P., Lobell, D. B., Linderman, M. & Ramankutty, N. Climate variability and crop production in Tanzania. Agric. For. Meteorol. 151 , 449–460 (2011).
Ceglar, A., Toreti, A., Lecerf, R., Van der Velde, M. & Dentener, F. Impact of meteorological drivers on regional inter-annual crop yield variability in France. Agric. For. Meteorol. 216 , 58–67 (2016).
Shi, L., Kloog, I., Zanobetti, A., Liu, P. & Schwartz, J. D. Impacts of temperature and its variability on mortality in New England. Nat. Clim. Change 5 , 988–991 (2015).
Xue, T., Zhu, T., Zheng, Y. & Zhang, Q. Declines in mental health associated with air pollution and temperature variability in China. Nat. Commun. 10 , 2165 (2019).
Article ADS PubMed PubMed Central Google Scholar
Liang, X.-Z. et al. Determining climate effects on US total agricultural productivity. Proc. Natl Acad. Sci. 114 , E2285–E2292 (2017).
Desbureaux, S. & Rodella, A.-S. Drought in the city: the economic impact of water scarcity in Latin American metropolitan areas. World Dev. 114 , 13–27 (2019).
Damania, R. The economics of water scarcity and variability. Oxf. Rev. Econ. Policy 36 , 24–44 (2020).
Davenport, F. V., Burke, M. & Diffenbaugh, N. S. Contribution of historical precipitation change to US flood damages. Proc. Natl Acad. Sci. 118 , e2017524118 (2021).
Dave, R., Subramanian, S. S. & Bhatia, U. Extreme precipitation induced concurrent events trigger prolonged disruptions in regional road networks. Environ. Res. Lett. 16 , 104050 (2021).
Download references
Acknowledgements
We gratefully acknowledge financing from the Volkswagen Foundation and the Deutsche Gesellschaft für Internationale Zusammenarbeit (GIZ) GmbH on behalf of the Government of the Federal Republic of Germany and Federal Ministry for Economic Cooperation and Development (BMZ).
Open access funding provided by Potsdam-Institut für Klimafolgenforschung (PIK) e.V.
Author information
Authors and affiliations.
Research Domain IV, Research Domain IV, Potsdam Institute for Climate Impact Research, Potsdam, Germany
Maximilian Kotz, Anders Levermann & Leonie Wenz
Institute of Physics, Potsdam University, Potsdam, Germany
Maximilian Kotz & Anders Levermann
Mercator Research Institute on Global Commons and Climate Change, Berlin, Germany
Leonie Wenz
You can also search for this author in PubMed Google Scholar
Contributions
All authors contributed to the design of the analysis. M.K. conducted the analysis and produced the figures. All authors contributed to the interpretation and presentation of the results. M.K. and L.W. wrote the manuscript.
Corresponding author
Correspondence to Leonie Wenz .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Peer review
Peer review information.
Nature thanks Xin-Zhong Liang, Chad Thackeray and the other, anonymous, reviewer(s) for their contribution to the peer review of this work. Peer reviewer reports are available.
Additional information
Publisher’s note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Extended data figures and tables
Extended data fig. 1 constraining the persistence of historical climate impacts on economic growth rates..
The results of a panel-based fixed-effects distributed lag model for the effects of annual mean temperature ( a ), daily temperature variability ( b ), total annual precipitation ( c ), the number of wet days ( d ) and extreme daily precipitation ( e ) on sub-national economic growth rates. Point estimates show the effects of a 1 °C or one standard deviation increase (for temperature and precipitation variables, respectively) at the lower quartile, median and upper quartile of the relevant moderating variable (green, orange and purple, respectively) at different lagged periods after the initial shock (note that these are not cumulative effects). Climate variables are used in their first-differenced form (see main text for discussion) and the moderating climate variables are the annual mean temperature, seasonal temperature difference, total annual precipitation, number of wet days and annual mean temperature, respectively, in panels a – e (see Methods for further discussion). Error bars show the 95% confidence intervals having clustered standard errors by region. The within-region R 2 , Bayesian and Akaike information criteria for the model are shown at the top of the figure. This figure shows results with ten lags for each variable to demonstrate the observed levels of persistence, but our preferred specifications remove later lags based on the statistical significance of terms shown above and the information criteria shown in Extended Data Fig. 2 . The resulting models without later lags are shown in Supplementary Figs. 1 – 3 .
Extended Data Fig. 2 Incremental lag-selection procedure using information criteria and within-region R 2 .
Starting from a panel-based fixed-effects distributed lag model estimating the effects of climate on economic growth using the real historical data (as in equation ( 4 )) with ten lags for all climate variables (as shown in Extended Data Fig. 1 ), lags are incrementally removed for one climate variable at a time. The resulting Bayesian and Akaike information criteria are shown in a – e and f – j , respectively, and the within-region R 2 and number of observations in k – o and p – t , respectively. Different rows show the results when removing lags from different climate variables, ordered from top to bottom as annual mean temperature, daily temperature variability, total annual precipitation, the number of wet days and extreme annual precipitation. Information criteria show minima at approximately four lags for precipitation variables and ten to eight for temperature variables, indicating that including these numbers of lags does not lead to overfitting. See Supplementary Table 1 for an assessment using information criteria to determine whether including further climate variables causes overfitting.
Extended Data Fig. 3 Damages in our preferred specification that provides a robust lower bound on the persistence of climate impacts on economic growth versus damages in specifications of pure growth or pure level effects.
Estimates of future damages as shown in Fig. 1 but under the emission scenario RCP8.5 for three separate empirical specifications: in orange our preferred specification, which provides an empirical lower bound on the persistence of climate impacts on economic growth rates while avoiding assumptions of infinite persistence (see main text for further discussion); in purple a specification of ‘pure growth effects’ in which the first difference of climate variables is not taken and no lagged climate variables are included (the baseline specification of ref. 2 ); and in pink a specification of ‘pure level effects’ in which the first difference of climate variables is taken but no lagged terms are included.
Extended Data Fig. 4 Climate changes in different variables as a function of historical interannual variability.
Changes in each climate variable of interest from 1979–2019 to 2035–2065 under the high-emission scenario SSP5-RCP8.5, expressed as a percentage of the historical variability of each measure. Historical variability is estimated as the standard deviation of each detrended climate variable over the period 1979–2019 during which the empirical models were identified (detrending is appropriate because of the inclusion of region-specific linear time trends in the empirical models). See Supplementary Fig. 13 for changes expressed in standard units. Data on national administrative boundaries are obtained from the GADM database version 3.6 and are freely available for academic use ( https://gadm.org/ ).
Extended Data Fig. 5 Contribution of different climate variables to overall committed damages.
a , Climate damages in 2049 when using empirical models that account for all climate variables, changes in annual mean temperature only or changes in both annual mean temperature and one other climate variable (daily temperature variability, total annual precipitation, the number of wet days and extreme daily precipitation, respectively). b , The cumulative marginal effects of an increase in annual mean temperature of 1 °C, at different baseline temperatures, estimated from empirical models including all climate variables or annual mean temperature only. Estimates and uncertainty bars represent the median and 95% confidence intervals obtained from 1,000 block-bootstrap resamples from each of three different empirical models using eight, nine or ten lags of temperature terms.
Extended Data Fig. 6 The difference in committed damages between the upper and lower quartiles of countries when ranked by GDP and cumulative historical emissions.
Quartiles are defined using a population weighting, as are the average committed damages across each quartile group. The violin plots indicate the distribution of differences between quartiles across the two extreme emission scenarios (RCP2.6 and RCP8.5) and the uncertainty sampling procedure outlined in Methods , which accounts for uncertainty arising from the choice of lags in the empirical models, uncertainty in the empirical model parameter estimates, as well as the climate model projections. Bars indicate the median, as well as the 10th and 90th percentiles and upper and lower sixths of the distribution reflecting the very likely and likely ranges following the likelihood classification adopted by the IPCC.
Supplementary information
Supplementary information, peer review file, rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Kotz, M., Levermann, A. & Wenz, L. The economic commitment of climate change. Nature 628 , 551–557 (2024). https://doi.org/10.1038/s41586-024-07219-0
Download citation
Received : 25 January 2023
Accepted : 21 February 2024
Published : 17 April 2024
Issue Date : 18 April 2024
DOI : https://doi.org/10.1038/s41586-024-07219-0
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.


An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Am J Pharm Educ
- v.74(8); 2010 Oct 11
Presenting and Evaluating Qualitative Research
The purpose of this paper is to help authors to think about ways to present qualitative research papers in the American Journal of Pharmaceutical Education . It also discusses methods for reviewers to assess the rigour, quality, and usefulness of qualitative research. Examples of different ways to present data from interviews, observations, and focus groups are included. The paper concludes with guidance for publishing qualitative research and a checklist for authors and reviewers.
INTRODUCTION
Policy and practice decisions, including those in education, increasingly are informed by findings from qualitative as well as quantitative research. Qualitative research is useful to policymakers because it often describes the settings in which policies will be implemented. Qualitative research is also useful to both pharmacy practitioners and pharmacy academics who are involved in researching educational issues in both universities and practice and in developing teaching and learning.
Qualitative research involves the collection, analysis, and interpretation of data that are not easily reduced to numbers. These data relate to the social world and the concepts and behaviors of people within it. Qualitative research can be found in all social sciences and in the applied fields that derive from them, for example, research in health services, nursing, and pharmacy. 1 It looks at X in terms of how X varies in different circumstances rather than how big is X or how many Xs are there? 2 Textbooks often subdivide research into qualitative and quantitative approaches, furthering the common assumption that there are fundamental differences between the 2 approaches. With pharmacy educators who have been trained in the natural and clinical sciences, there is often a tendency to embrace quantitative research, perhaps due to familiarity. A growing consensus is emerging that sees both qualitative and quantitative approaches as useful to answering research questions and understanding the world. Increasingly mixed methods research is being carried out where the researcher explicitly combines the quantitative and qualitative aspects of the study. 3 , 4
Like healthcare, education involves complex human interactions that can rarely be studied or explained in simple terms. Complex educational situations demand complex understanding; thus, the scope of educational research can be extended by the use of qualitative methods. Qualitative research can sometimes provide a better understanding of the nature of educational problems and thus add to insights into teaching and learning in a number of contexts. For example, at the University of Nottingham, we conducted in-depth interviews with pharmacists to determine their perceptions of continuing professional development and who had influenced their learning. We also have used a case study approach using observation of practice and in-depth interviews to explore physiotherapists' views of influences on their leaning in practice. We have conducted in-depth interviews with a variety of stakeholders in Malawi, Africa, to explore the issues surrounding pharmacy academic capacity building. A colleague has interviewed and conducted focus groups with students to explore cultural issues as part of a joint Nottingham-Malaysia pharmacy degree program. Another colleague has interviewed pharmacists and patients regarding their expectations before and after clinic appointments and then observed pharmacist-patient communication in clinics and assessed it using the Calgary Cambridge model in order to develop recommendations for communication skills training. 5 We have also performed documentary analysis on curriculum data to compare pharmacist and nurse supplementary prescribing courses in the United Kingdom.
It is important to choose the most appropriate methods for what is being investigated. Qualitative research is not appropriate to answer every research question and researchers need to think carefully about their objectives. Do they wish to study a particular phenomenon in depth (eg, students' perceptions of studying in a different culture)? Or are they more interested in making standardized comparisons and accounting for variance (eg, examining differences in examination grades after changing the way the content of a module is taught). Clearly a quantitative approach would be more appropriate in the last example. As with any research project, a clear research objective has to be identified to know which methods should be applied.
Types of qualitative data include:
- Audio recordings and transcripts from in-depth or semi-structured interviews
- Structured interview questionnaires containing substantial open comments including a substantial number of responses to open comment items.
- Audio recordings and transcripts from focus group sessions.
- Field notes (notes taken by the researcher while in the field [setting] being studied)
- Video recordings (eg, lecture delivery, class assignments, laboratory performance)
- Case study notes
- Documents (reports, meeting minutes, e-mails)
- Diaries, video diaries
- Observation notes
- Press clippings
- Photographs
RIGOUR IN QUALITATIVE RESEARCH
Qualitative research is often criticized as biased, small scale, anecdotal, and/or lacking rigor; however, when it is carried out properly it is unbiased, in depth, valid, reliable, credible and rigorous. In qualitative research, there needs to be a way of assessing the “extent to which claims are supported by convincing evidence.” 1 Although the terms reliability and validity traditionally have been associated with quantitative research, increasingly they are being seen as important concepts in qualitative research as well. Examining the data for reliability and validity assesses both the objectivity and credibility of the research. Validity relates to the honesty and genuineness of the research data, while reliability relates to the reproducibility and stability of the data.
The validity of research findings refers to the extent to which the findings are an accurate representation of the phenomena they are intended to represent. The reliability of a study refers to the reproducibility of the findings. Validity can be substantiated by a number of techniques including triangulation use of contradictory evidence, respondent validation, and constant comparison. Triangulation is using 2 or more methods to study the same phenomenon. Contradictory evidence, often known as deviant cases, must be sought out, examined, and accounted for in the analysis to ensure that researcher bias does not interfere with or alter their perception of the data and any insights offered. Respondent validation, which is allowing participants to read through the data and analyses and provide feedback on the researchers' interpretations of their responses, provides researchers with a method of checking for inconsistencies, challenges the researchers' assumptions, and provides them with an opportunity to re-analyze their data. The use of constant comparison means that one piece of data (for example, an interview) is compared with previous data and not considered on its own, enabling researchers to treat the data as a whole rather than fragmenting it. Constant comparison also enables the researcher to identify emerging/unanticipated themes within the research project.
STRENGTHS AND LIMITATIONS OF QUALITATIVE RESEARCH
Qualitative researchers have been criticized for overusing interviews and focus groups at the expense of other methods such as ethnography, observation, documentary analysis, case studies, and conversational analysis. Qualitative research has numerous strengths when properly conducted.
Strengths of Qualitative Research
- Issues can be examined in detail and in depth.
- Interviews are not restricted to specific questions and can be guided/redirected by the researcher in real time.
- The research framework and direction can be quickly revised as new information emerges.
- The data based on human experience that is obtained is powerful and sometimes more compelling than quantitative data.
- Subtleties and complexities about the research subjects and/or topic are discovered that are often missed by more positivistic enquiries.
- Data usually are collected from a few cases or individuals so findings cannot be generalized to a larger population. Findings can however be transferable to another setting.
Limitations of Qualitative Research
- Research quality is heavily dependent on the individual skills of the researcher and more easily influenced by the researcher's personal biases and idiosyncrasies.
- Rigor is more difficult to maintain, assess, and demonstrate.
- The volume of data makes analysis and interpretation time consuming.
- It is sometimes not as well understood and accepted as quantitative research within the scientific community
- The researcher's presence during data gathering, which is often unavoidable in qualitative research, can affect the subjects' responses.
- Issues of anonymity and confidentiality can present problems when presenting findings
- Findings can be more difficult and time consuming to characterize in a visual way.
PRESENTATION OF QUALITATIVE RESEARCH FINDINGS
The following extracts are examples of how qualitative data might be presented:
Data From an Interview.
The following is an example of how to present and discuss a quote from an interview.
The researcher should select quotes that are poignant and/or most representative of the research findings. Including large portions of an interview in a research paper is not necessary and often tedious for the reader. The setting and speakers should be established in the text at the end of the quote.
The student describes how he had used deep learning in a dispensing module. He was able to draw on learning from a previous module, “I found that while using the e learning programme I was able to apply the knowledge and skills that I had gained in last year's diseases and goals of treatment module.” (interviewee 22, male)
This is an excerpt from an article on curriculum reform that used interviews 5 :
The first question was, “Without the accreditation mandate, how much of this curriculum reform would have been attempted?” According to respondents, accreditation played a significant role in prompting the broad-based curricular change, and their comments revealed a nuanced view. Most indicated that the change would likely have occurred even without the mandate from the accreditation process: “It reflects where the profession wants to be … training a professional who wants to take on more responsibility.” However, they also commented that “if it were not mandated, it could have been a very difficult road.” Or it “would have happened, but much later.” The change would more likely have been incremental, “evolutionary,” or far more limited in its scope. “Accreditation tipped the balance” was the way one person phrased it. “Nobody got serious until the accrediting body said it would no longer accredit programs that did not change.”
Data From Observations
The following example is some data taken from observation of pharmacist patient consultations using the Calgary Cambridge guide. 6 , 7 The data are first presented and a discussion follows:
Pharmacist: We will soon be starting a stop smoking clinic. Patient: Is the interview over now? Pharmacist: No this is part of it. (Laughs) You can't tell me to bog off (sic) yet. (pause) We will be starting a stop smoking service here, Patient: Yes. Pharmacist: with one-to-one and we will be able to help you or try to help you. If you want it. In this example, the pharmacist has picked up from the patient's reaction to the stop smoking clinic that she is not receptive to advice about giving up smoking at this time; in fact she would rather end the consultation. The pharmacist draws on his prior relationship with the patient and makes use of a joke to lighten the tone. He feels his message is important enough to persevere but he presents the information in a succinct and non-pressurised way. His final comment of “If you want it” is important as this makes it clear that he is not putting any pressure on the patient to take up this offer. This extract shows that some patient cues were picked up, and appropriately dealt with, but this was not the case in all examples.
Data From Focus Groups
This excerpt from a study involving 11 focus groups illustrates how findings are presented using representative quotes from focus group participants. 8
Those pharmacists who were initially familiar with CPD endorsed the model for their peers, and suggested it had made a meaningful difference in the way they viewed their own practice. In virtually all focus groups sessions, pharmacists familiar with and supportive of the CPD paradigm had worked in collaborative practice environments such as hospital pharmacy practice. For these pharmacists, the major advantage of CPD was the linking of workplace learning with continuous education. One pharmacist stated, “It's amazing how much I have to learn every day, when I work as a pharmacist. With [the learning portfolio] it helps to show how much learning we all do, every day. It's kind of satisfying to look it over and see how much you accomplish.” Within many of the learning portfolio-sharing sessions, debates emerged regarding the true value of traditional continuing education and its outcome in changing an individual's practice. While participants appreciated the opportunity for social and professional networking inherent in some forms of traditional CE, most eventually conceded that the academic value of most CE programming was limited by the lack of a systematic process for following-up and implementing new learning in the workplace. “Well it's nice to go to these [continuing education] events, but really, I don't know how useful they are. You go, you sit, you listen, but then, well I at least forget.”
The following is an extract from a focus group (conducted by the author) with first-year pharmacy students about community placements. It illustrates how focus groups provide a chance for participants to discuss issues on which they might disagree.
Interviewer: So you are saying that you would prefer health related placements? Student 1: Not exactly so long as I could be developing my communication skill. Student 2: Yes but I still think the more health related the placement is the more I'll gain from it. Student 3: I disagree because other people related skills are useful and you may learn those from taking part in a community project like building a garden. Interviewer: So would you prefer a mixture of health and non health related community placements?
GUIDANCE FOR PUBLISHING QUALITATIVE RESEARCH
Qualitative research is becoming increasingly accepted and published in pharmacy and medical journals. Some journals and publishers have guidelines for presenting qualitative research, for example, the British Medical Journal 9 and Biomedcentral . 10 Medical Education published a useful series of articles on qualitative research. 11 Some of the important issues that should be considered by authors, reviewers and editors when publishing qualitative research are discussed below.
Introduction.
A good introduction provides a brief overview of the manuscript, including the research question and a statement justifying the research question and the reasons for using qualitative research methods. This section also should provide background information, including relevant literature from pharmacy, medicine, and other health professions, as well as literature from the field of education that addresses similar issues. Any specific educational or research terminology used in the manuscript should be defined in the introduction.
The methods section should clearly state and justify why the particular method, for example, face to face semistructured interviews, was chosen. The method should be outlined and illustrated with examples such as the interview questions, focusing exercises, observation criteria, etc. The criteria for selecting the study participants should then be explained and justified. The way in which the participants were recruited and by whom also must be stated. A brief explanation/description should be included of those who were invited to participate but chose not to. It is important to consider “fair dealing,” ie, whether the research design explicitly incorporates a wide range of different perspectives so that the viewpoint of 1 group is never presented as if it represents the sole truth about any situation. The process by which ethical and or research/institutional governance approval was obtained should be described and cited.
The study sample and the research setting should be described. Sampling differs between qualitative and quantitative studies. In quantitative survey studies, it is important to select probability samples so that statistics can be used to provide generalizations to the population from which the sample was drawn. Qualitative research necessitates having a small sample because of the detailed and intensive work required for the study. So sample sizes are not calculated using mathematical rules and probability statistics are not applied. Instead qualitative researchers should describe their sample in terms of characteristics and relevance to the wider population. Purposive sampling is common in qualitative research. Particular individuals are chosen with characteristics relevant to the study who are thought will be most informative. Purposive sampling also may be used to produce maximum variation within a sample. Participants being chosen based for example, on year of study, gender, place of work, etc. Representative samples also may be used, for example, 20 students from each of 6 schools of pharmacy. Convenience samples involve the researcher choosing those who are either most accessible or most willing to take part. This may be fine for exploratory studies; however, this form of sampling may be biased and unrepresentative of the population in question. Theoretical sampling uses insights gained from previous research to inform sample selection for a new study. The method for gaining informed consent from the participants should be described, as well as how anonymity and confidentiality of subjects were guaranteed. The method of recording, eg, audio or video recording, should be noted, along with procedures used for transcribing the data.
Data Analysis.
A description of how the data were analyzed also should be included. Was computer-aided qualitative data analysis software such as NVivo (QSR International, Cambridge, MA) used? Arrival at “data saturation” or the end of data collection should then be described and justified. A good rule when considering how much information to include is that readers should have been given enough information to be able to carry out similar research themselves.
One of the strengths of qualitative research is the recognition that data must always be understood in relation to the context of their production. 1 The analytical approach taken should be described in detail and theoretically justified in light of the research question. If the analysis was repeated by more than 1 researcher to ensure reliability or trustworthiness, this should be stated and methods of resolving any disagreements clearly described. Some researchers ask participants to check the data. If this was done, it should be fully discussed in the paper.
An adequate account of how the findings were produced should be included A description of how the themes and concepts were derived from the data also should be included. Was an inductive or deductive process used? The analysis should not be limited to just those issues that the researcher thinks are important, anticipated themes, but also consider issues that participants raised, ie, emergent themes. Qualitative researchers must be open regarding the data analysis and provide evidence of their thinking, for example, were alternative explanations for the data considered and dismissed, and if so, why were they dismissed? It also is important to present outlying or negative/deviant cases that did not fit with the central interpretation.
The interpretation should usually be grounded in interviewees or respondents' contributions and may be semi-quantified, if this is possible or appropriate, for example, “Half of the respondents said …” “The majority said …” “Three said…” Readers should be presented with data that enable them to “see what the researcher is talking about.” 1 Sufficient data should be presented to allow the reader to clearly see the relationship between the data and the interpretation of the data. Qualitative data conventionally are presented by using illustrative quotes. Quotes are “raw data” and should be compiled and analyzed, not just listed. There should be an explanation of how the quotes were chosen and how they are labeled. For example, have pseudonyms been given to each respondent or are the respondents identified using codes, and if so, how? It is important for the reader to be able to see that a range of participants have contributed to the data and that not all the quotes are drawn from 1 or 2 individuals. There is a tendency for authors to overuse quotes and for papers to be dominated by a series of long quotes with little analysis or discussion. This should be avoided.
Participants do not always state the truth and may say what they think the interviewer wishes to hear. A good qualitative researcher should not only examine what people say but also consider how they structured their responses and how they talked about the subject being discussed, for example, the person's emotions, tone, nonverbal communication, etc. If the research was triangulated with other qualitative or quantitative data, this should be discussed.
Discussion.
The findings should be presented in the context of any similar previous research and or theories. A discussion of the existing literature and how this present research contributes to the area should be included. A consideration must also be made about how transferrable the research would be to other settings. Any particular strengths and limitations of the research also should be discussed. It is common practice to include some discussion within the results section of qualitative research and follow with a concluding discussion.
The author also should reflect on their own influence on the data, including a consideration of how the researcher(s) may have introduced bias to the results. The researcher should critically examine their own influence on the design and development of the research, as well as on data collection and interpretation of the data, eg, were they an experienced teacher who researched teaching methods? If so, they should discuss how this might have influenced their interpretation of the results.
Conclusion.
The conclusion should summarize the main findings from the study and emphasize what the study adds to knowledge in the area being studied. Mays and Pope suggest the researcher ask the following 3 questions to determine whether the conclusions of a qualitative study are valid 12 : How well does this analysis explain why people behave in the way they do? How comprehensible would this explanation be to a thoughtful participant in the setting? How well does the explanation cohere with what we already know?
CHECKLIST FOR QUALITATIVE PAPERS
This paper establishes criteria for judging the quality of qualitative research. It provides guidance for authors and reviewers to prepare and review qualitative research papers for the American Journal of Pharmaceutical Education . A checklist is provided in Appendix 1 to assist both authors and reviewers of qualitative data.
ACKNOWLEDGEMENTS
Thank you to the 3 reviewers whose ideas helped me to shape this paper.
Appendix 1. Checklist for authors and reviewers of qualitative research.
Introduction
- □ Research question is clearly stated.
- □ Research question is justified and related to the existing knowledge base (empirical research, theory, policy).
- □ Any specific research or educational terminology used later in manuscript is defined.
- □ The process by which ethical and or research/institutional governance approval was obtained is described and cited.
- □ Reason for choosing particular research method is stated.
- □ Criteria for selecting study participants are explained and justified.
- □ Recruitment methods are explicitly stated.
- □ Details of who chose not to participate and why are given.
- □ Study sample and research setting used are described.
- □ Method for gaining informed consent from the participants is described.
- □ Maintenance/Preservation of subject anonymity and confidentiality is described.
- □ Method of recording data (eg, audio or video recording) and procedures for transcribing data are described.
- □ Methods are outlined and examples given (eg, interview guide).
- □ Decision to stop data collection is described and justified.
- □ Data analysis and verification are described, including by whom they were performed.
- □ Methods for identifying/extrapolating themes and concepts from the data are discussed.
- □ Sufficient data are presented to allow a reader to assess whether or not the interpretation is supported by the data.
- □ Outlying or negative/deviant cases that do not fit with the central interpretation are presented.
- □ Transferability of research findings to other settings is discussed.
- □ Findings are presented in the context of any similar previous research and social theories.
- □ Discussion often is incorporated into the results in qualitative papers.
- □ A discussion of the existing literature and how this present research contributes to the area is included.
- □ Any particular strengths and limitations of the research are discussed.
- □ Reflection of the influence of the researcher(s) on the data, including a consideration of how the researcher(s) may have introduced bias to the results is included.
Conclusions
- □ The conclusion states the main finings of the study and emphasizes what the study adds to knowledge in the subject area.
Facility for Rare Isotope Beams
At michigan state university, frib researchers lead team to merge nuclear physics experiments and astronomical observations to advance equation-of-state research, world-class particle-accelerator facilities and recent advances in neutron-star observation give physicists a new toolkit for describing nuclear interactions at a wide range of densities..
For most stars, neutron stars and black holes are their final resting places. When a supergiant star runs out of fuel, it expands and then rapidly collapses on itself. This act creates a neutron star—an object denser than our sun crammed into a space 13 to 18 miles wide. In such a heavily condensed stellar environment, most electrons combine with protons to make neutrons, resulting in a dense ball of matter consisting mainly of neutrons. Researchers try to understand the forces that control this process by creating dense matter in the laboratory through colliding neutron-rich nuclei and taking detailed measurements.
A research team—led by William Lynch and Betty Tsang at FRIB—is focused on learning about neutrons in dense environments. Lynch, Tsang, and their collaborators used 20 years of experimental data from accelerator facilities and neutron-star observations to understand how particles interact in nuclear matter under a wide range of densities and pressures. The team wanted to determine how the ratio of neutrons to protons influences nuclear forces in a system. The team recently published its findings in Nature Astronomy .
“In nuclear physics, we are often confined to studying small systems, but we know exactly what particles are in our nuclear systems. Stars provide us an unbelievable opportunity, because they are large systems where nuclear physics plays a vital role, but we do not know for sure what particles are in their interiors,” said Lynch, professor of nuclear physics at FRIB and in the Michigan State University (MSU) Department of Physics and Astronomy. “They are interesting because the density varies greatly within such large systems. Nuclear forces play a dominant role within them, yet we know comparatively little about that role.”
When a star with a mass that is 20-30 times that of the sun exhausts its fuel, it cools, collapses, and explodes in a supernova. After this explosion, only the matter in the deepest part of the star’s interior coalesces to form a neutron star. This neutron star has no fuel to burn and over time, it radiates its remaining heat into the surrounding space. Scientists expect that matter in the outer core of a cold neutron star is roughly similar to the matter in atomic nuclei but with three differences: neutron stars are much larger, they are denser in their interiors, and a larger fraction of their nucleons are neutrons. Deep within the inner core of a neutron star, the composition of neutron star matter remains a mystery.
“If experiments could provide more guidance about the forces that act in their interiors, we could make better predictions of their interior composition and of phase transitions within them. Neutron stars present a great research opportunity to combine these disciplines,” said Lynch.
Accelerator facilities like FRIB help physicists study how subatomic particles interact under exotic conditions that are more common in neutron stars. When researchers compare these experiments to neutron-star observations, they can calculate the equation of state (EOS) of particles interacting in low-temperature, dense environments. The EOS describes matter in specific conditions, and how its properties change with density. Solving EOS for a wide range of settings helps researchers understand the strong nuclear force’s effects within dense objects, like neutron stars, in the cosmos. It also helps us learn more about neutron stars as they cool.
“This is the first time that we pulled together such a wealth of experimental data to explain the equation of state under these conditions, and this is important,” said Tsang, professor of nuclear science at FRIB. “Previous efforts have used theory to explain the low-density and low-energy end of nuclear matter. We wanted to use all the data we had available to us from our previous experiences with accelerators to obtain a comprehensive equation of state.”
Researchers seeking the EOS often calculate it at higher temperatures or lower densities. They then draw conclusions for the system across a wider range of conditions. However, physicists have come to understand in recent years that an EOS obtained from an experiment is only relevant for a specific range of densities. As a result, the team needed to pull together data from a variety of accelerator experiments that used different measurements of colliding nuclei to replace those assumptions with data. “In this work, we asked two questions,” said Lynch. “For a given measurement, what density does that measurement probe? After that, we asked what that measurement tells us about the equation of state at that density.”
In its recent paper, the team combined its own experiments from accelerator facilities in the United States and Japan. It pulled together data from 12 different experimental constraints and three neutron-star observations. The researchers focused on determining the EOS for nuclear matter ranging from half to three times a nuclei’s saturation density—the density found at the core of all stable nuclei. By producing this comprehensive EOS, the team provided new benchmarks for the larger nuclear physics and astrophysics communities to more accurately model interactions of nuclear matter.
The team improved its measurements at intermediate densities that neutron star observations do not provide through experiments at the GSI Helmholtz Centre for Heavy Ion Research in Germany, the RIKEN Nishina Center for Accelerator-Based Science in Japan, and the National Superconducting Cyclotron Laboratory (FRIB’s predecessor). To enable key measurements discussed in this article, their experiments helped fund technical advances in data acquisition for active targets and time projection chambers that are being employed in many other experiments world-wide.
In running these experiments at FRIB, Tsang and Lynch can continue to interact with MSU students who help advance the research with their own input and innovation. MSU operates FRIB as a scientific user facility for the U.S. Department of Energy Office of Science (DOE-SC), supporting the mission of the DOE-SC Office of Nuclear Physics. FRIB is the only accelerator-based user facility on a university campus as one of 28 DOE-SC user facilities . Chun Yen Tsang, the first author on the Nature Astronomy paper, was a graduate student under Betty Tsang during this research and is now a researcher working jointly at Brookhaven National Laboratory and Kent State University.
“Projects like this one are essential for attracting the brightest students, which ultimately makes these discoveries possible, and provides a steady pipeline to the U.S. workforce in nuclear science,” Tsang said.
The proposed FRIB energy upgrade ( FRIB400 ), supported by the scientific user community in the 2023 Nuclear Science Advisory Committee Long Range Plan , will allow the team to probe at even higher densities in the years to come. FRIB400 will double the reach of FRIB along the neutron dripline into a region relevant for neutron-star crusts and to allow study of extreme, neutron-rich nuclei such as calcium-68.
Eric Gedenk is a freelance science writer.
Michigan State University operates the Facility for Rare Isotope Beams (FRIB) as a user facility for the U.S. Department of Energy Office of Science (DOE-SC), supporting the mission of the DOE-SC Office of Nuclear Physics. Hosting what is designed to be the most powerful heavy-ion accelerator, FRIB enables scientists to make discoveries about the properties of rare isotopes in order to better understand the physics of nuclei, nuclear astrophysics, fundamental interactions, and applications for society, including in medicine, homeland security, and industry.
The U.S. Department of Energy Office of Science is the single largest supporter of basic research in the physical sciences in the United States and is working to address some of today’s most pressing challenges. For more information, visit energy.gov/science.
Numbers, Facts and Trends Shaping Your World
Read our research on:
Full Topic List
Regions & Countries
- Publications
- Our Methods
- Short Reads
- Tools & Resources
Read Our Research On:
What the data says about crime in the U.S.
A growing share of Americans say reducing crime should be a top priority for the president and Congress to address this year. Around six-in-ten U.S. adults (58%) hold that view today, up from 47% at the beginning of Joe Biden’s presidency in 2021.
We conducted this analysis to learn more about U.S. crime patterns and how those patterns have changed over time.
The analysis relies on statistics published by the FBI, which we accessed through the Crime Data Explorer , and the Bureau of Justice Statistics (BJS), which we accessed through the National Crime Victimization Survey data analysis tool .
To measure public attitudes about crime in the U.S., we relied on survey data from Pew Research Center and Gallup.
Additional details about each data source, including survey methodologies, are available by following the links in the text of this analysis.

With the issue likely to come up in this year’s presidential election, here’s what we know about crime in the United States, based on the latest available data from the federal government and other sources.
How much crime is there in the U.S.?
It’s difficult to say for certain. The two primary sources of government crime statistics – the Federal Bureau of Investigation (FBI) and the Bureau of Justice Statistics (BJS) – paint an incomplete picture.
The FBI publishes annual data on crimes that have been reported to law enforcement, but not crimes that haven’t been reported. Historically, the FBI has also only published statistics about a handful of specific violent and property crimes, but not many other types of crime, such as drug crime. And while the FBI’s data is based on information from thousands of federal, state, county, city and other police departments, not all law enforcement agencies participate every year. In 2022, the most recent full year with available statistics, the FBI received data from 83% of participating agencies .
BJS, for its part, tracks crime by fielding a large annual survey of Americans ages 12 and older and asking them whether they were the victim of certain types of crime in the past six months. One advantage of this approach is that it captures both reported and unreported crimes. But the BJS survey has limitations of its own. Like the FBI, it focuses mainly on a handful of violent and property crimes. And since the BJS data is based on after-the-fact interviews with crime victims, it cannot provide information about one especially high-profile type of offense: murder.
All those caveats aside, looking at the FBI and BJS statistics side-by-side does give researchers a good picture of U.S. violent and property crime rates and how they have changed over time. In addition, the FBI is transitioning to a new data collection system – known as the National Incident-Based Reporting System – that eventually will provide national information on a much larger set of crimes , as well as details such as the time and place they occur and the types of weapons involved, if applicable.
Which kinds of crime are most and least common?

Property crime in the U.S. is much more common than violent crime. In 2022, the FBI reported a total of 1,954.4 property crimes per 100,000 people, compared with 380.7 violent crimes per 100,000 people.
By far the most common form of property crime in 2022 was larceny/theft, followed by motor vehicle theft and burglary. Among violent crimes, aggravated assault was the most common offense, followed by robbery, rape, and murder/nonnegligent manslaughter.
BJS tracks a slightly different set of offenses from the FBI, but it finds the same overall patterns, with theft the most common form of property crime in 2022 and assault the most common form of violent crime.
How have crime rates in the U.S. changed over time?
Both the FBI and BJS data show dramatic declines in U.S. violent and property crime rates since the early 1990s, when crime spiked across much of the nation.
Using the FBI data, the violent crime rate fell 49% between 1993 and 2022, with large decreases in the rates of robbery (-74%), aggravated assault (-39%) and murder/nonnegligent manslaughter (-34%). It’s not possible to calculate the change in the rape rate during this period because the FBI revised its definition of the offense in 2013 .

The FBI data also shows a 59% reduction in the U.S. property crime rate between 1993 and 2022, with big declines in the rates of burglary (-75%), larceny/theft (-54%) and motor vehicle theft (-53%).
Using the BJS statistics, the declines in the violent and property crime rates are even steeper than those captured in the FBI data. Per BJS, the U.S. violent and property crime rates each fell 71% between 1993 and 2022.
While crime rates have fallen sharply over the long term, the decline hasn’t always been steady. There have been notable increases in certain kinds of crime in some years, including recently.
In 2020, for example, the U.S. murder rate saw its largest single-year increase on record – and by 2022, it remained considerably higher than before the coronavirus pandemic. Preliminary data for 2023, however, suggests that the murder rate fell substantially last year .
How do Americans perceive crime in their country?
Americans tend to believe crime is up, even when official data shows it is down.
In 23 of 27 Gallup surveys conducted since 1993 , at least 60% of U.S. adults have said there is more crime nationally than there was the year before, despite the downward trend in crime rates during most of that period.

While perceptions of rising crime at the national level are common, fewer Americans believe crime is up in their own communities. In every Gallup crime survey since the 1990s, Americans have been much less likely to say crime is up in their area than to say the same about crime nationally.
Public attitudes about crime differ widely by Americans’ party affiliation, race and ethnicity, and other factors . For example, Republicans and Republican-leaning independents are much more likely than Democrats and Democratic leaners to say reducing crime should be a top priority for the president and Congress this year (68% vs. 47%), according to a recent Pew Research Center survey.
How does crime in the U.S. differ by demographic characteristics?
Some groups of Americans are more likely than others to be victims of crime. In the 2022 BJS survey , for example, younger people and those with lower incomes were far more likely to report being the victim of a violent crime than older and higher-income people.
There were no major differences in violent crime victimization rates between male and female respondents or between those who identified as White, Black or Hispanic. But the victimization rate among Asian Americans (a category that includes Native Hawaiians and other Pacific Islanders) was substantially lower than among other racial and ethnic groups.
The same BJS survey asks victims about the demographic characteristics of the offenders in the incidents they experienced.
In 2022, those who are male, younger people and those who are Black accounted for considerably larger shares of perceived offenders in violent incidents than their respective shares of the U.S. population. Men, for instance, accounted for 79% of perceived offenders in violent incidents, compared with 49% of the nation’s 12-and-older population that year. Black Americans accounted for 25% of perceived offenders in violent incidents, about twice their share of the 12-and-older population (12%).
As with all surveys, however, there are several potential sources of error, including the possibility that crime victims’ perceptions about offenders are incorrect.
How does crime in the U.S. differ geographically?
There are big geographic differences in violent and property crime rates.
For example, in 2022, there were more than 700 violent crimes per 100,000 residents in New Mexico and Alaska. That compares with fewer than 200 per 100,000 people in Rhode Island, Connecticut, New Hampshire and Maine, according to the FBI.
The FBI notes that various factors might influence an area’s crime rate, including its population density and economic conditions.
What percentage of crimes are reported to police? What percentage are solved?

Most violent and property crimes in the U.S. are not reported to police, and most of the crimes that are reported are not solved.
In its annual survey, BJS asks crime victims whether they reported their crime to police. It found that in 2022, only 41.5% of violent crimes and 31.8% of household property crimes were reported to authorities. BJS notes that there are many reasons why crime might not be reported, including fear of reprisal or of “getting the offender in trouble,” a feeling that police “would not or could not do anything to help,” or a belief that the crime is “a personal issue or too trivial to report.”
Most of the crimes that are reported to police, meanwhile, are not solved , at least based on an FBI measure known as the clearance rate . That’s the share of cases each year that are closed, or “cleared,” through the arrest, charging and referral of a suspect for prosecution, or due to “exceptional” circumstances such as the death of a suspect or a victim’s refusal to cooperate with a prosecution. In 2022, police nationwide cleared 36.7% of violent crimes that were reported to them and 12.1% of the property crimes that came to their attention.
Which crimes are most likely to be reported to police? Which are most likely to be solved?

Around eight-in-ten motor vehicle thefts (80.9%) were reported to police in 2022, making them by far the most commonly reported property crime tracked by BJS. Household burglaries and trespassing offenses were reported to police at much lower rates (44.9% and 41.2%, respectively), while personal theft/larceny and other types of theft were only reported around a quarter of the time.
Among violent crimes – excluding homicide, which BJS doesn’t track – robbery was the most likely to be reported to law enforcement in 2022 (64.0%). It was followed by aggravated assault (49.9%), simple assault (36.8%) and rape/sexual assault (21.4%).
The list of crimes cleared by police in 2022 looks different from the list of crimes reported. Law enforcement officers were generally much more likely to solve violent crimes than property crimes, according to the FBI.
The most frequently solved violent crime tends to be homicide. Police cleared around half of murders and nonnegligent manslaughters (52.3%) in 2022. The clearance rates were lower for aggravated assault (41.4%), rape (26.1%) and robbery (23.2%).
When it comes to property crime, law enforcement agencies cleared 13.0% of burglaries, 12.4% of larcenies/thefts and 9.3% of motor vehicle thefts in 2022.
Are police solving more or fewer crimes than they used to?
Nationwide clearance rates for both violent and property crime are at their lowest levels since at least 1993, the FBI data shows.
Police cleared a little over a third (36.7%) of the violent crimes that came to their attention in 2022, down from nearly half (48.1%) as recently as 2013. During the same period, there were decreases for each of the four types of violent crime the FBI tracks:

- Police cleared 52.3% of reported murders and nonnegligent homicides in 2022, down from 64.1% in 2013.
- They cleared 41.4% of aggravated assaults, down from 57.7%.
- They cleared 26.1% of rapes, down from 40.6%.
- They cleared 23.2% of robberies, down from 29.4%.
The pattern is less pronounced for property crime. Overall, law enforcement agencies cleared 12.1% of reported property crimes in 2022, down from 19.7% in 2013. The clearance rate for burglary didn’t change much, but it fell for larceny/theft (to 12.4% in 2022 from 22.4% in 2013) and motor vehicle theft (to 9.3% from 14.2%).
Note: This is an update of a post originally published on Nov. 20, 2020.
- Criminal Justice

John Gramlich is an associate director at Pew Research Center
8 facts about Black Lives Matter
#blacklivesmatter turns 10, support for the black lives matter movement has dropped considerably from its peak in 2020, fewer than 1% of federal criminal defendants were acquitted in 2022, before release of video showing tyre nichols’ beating, public views of police conduct had improved modestly, most popular.
1615 L St. NW, Suite 800 Washington, DC 20036 USA (+1) 202-419-4300 | Main (+1) 202-857-8562 | Fax (+1) 202-419-4372 | Media Inquiries
Research Topics
- Age & Generations
- Coronavirus (COVID-19)
- Economy & Work
- Family & Relationships
- Gender & LGBTQ
- Immigration & Migration
- International Affairs
- Internet & Technology
- Methodological Research
- News Habits & Media
- Non-U.S. Governments
- Other Topics
- Politics & Policy
- Race & Ethnicity
- Email Newsletters
ABOUT PEW RESEARCH CENTER Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It is a subsidiary of The Pew Charitable Trusts .
Copyright 2024 Pew Research Center
Terms & Conditions
Privacy Policy
Cookie Settings
Reprints, Permissions & Use Policy
COMMENTS
Start with response rate and description of research participants (these information give the readers an idea of the representativeness of the research data), then the key findings and relevant statistical analyses. Data should answer the research questions identified earlier. Leave the process of data collection to the methods section.
Abstract. The present review is the first in an ongoing guide to medical statistics, using specific examples from intensive care. The first step in any analysis is to describe and summarize the data. As well as becoming familiar with the data, this is also an opportunity to look for unusually high or low values (outliers), to check the ...
Presenting research data and key findings in an organized, visually attractive, and meaningful manner is a key part of a good research paper. This is particularly important in instances where complex data and information, which cannot be easily communicated through text alone, need to be presented engagingly.
The present paper aims to provide basic guidelines to present epidemiological data using tables and graphs in Dermatology. ... or quantify the number of times a person uses sunscreen during summer. 1,2 All the information collected during research is generically named "data." A set of individual data makes it possible to perform statistical ...
Keep Tables simple, preferably in black and white. Avoid using shouting colours, if you must use colours select a gentle colour like blue. Pick complementary colours that visually match. The bottom line, stick to black and white whenever you can. Use the same font for the entire table.
Effective data presentation in research papers requires understanding the common errors that make data presentation ineffective. These common mistakes include using the wrong type of figure for the data. For instance, using a scatterplot instead of a bar graph for showing levels of hydration is a mistake. Another common mistake is that some ...
The results section of a quantitative research paper is where you summarize your data and report the findings of any relevant statistical analyses. The APA manual provides rigorous guidelines for what to report in quantitative research papers in the fields of psychology, education, and other social sciences. ... notes. Make sure to present data ...
Data is the most important component of any research. It needs to be presented effectively in a paper to ensure that readers understand the key message in the paper. Figures and tables act as concise tools for clear presentation. Tables display information arranged in rows and columns in a grid-like format, while figures convey information ...
The "Results" section is arguably the most important section in a research manuscript as the findings of a study, obtained diligently and painstakingly, are presented in this section. A well-written results section reflects a well-conducted study. This chapter provides helpful pointers for writing an effective, organized results section.
This is the most important thing you can do. Keep your audience in mind. When you present your data and statistical results, think about how familiar your readers may be with the analysis and include the amount of detail needed for them to be comfortable 2 . Use tables and graphics to illustrate your results more clearly and make your writing ...
The headings and subheadings within an academic or scientific paper or report are a simple example: spacing as well as font style and size make these short bits of text stand out and provide a clear structure and logical transitions for presenting data in an accessible fashion. Effective headings guide readers successfully through long and ...
Turning a research paper into a visual presentation is difficult; there are pitfalls, and navigating the path to a brief, informative presentation takes time and practice. As a TA for GEO/WRI 201: Methods in Data Analysis & Scientific Writing this past fall, I saw how this process works from an instructor's standpoint.
When it comes to research, presenting data in a meaningful and accessible way is as important as gathering it. ... The physical and natural sciences tend to have a clinical structure for a research paper that mirrors the scientific method: outline the background research, explain the materials and methods of the study, outline the research ...
Overview. Data analysis is an ongoing process that should occur throughout your research project. Suitable data-analysis methods must be selected when you write your research proposal. The nature of your data (i.e. quantitative or qualitative) will be influenced by your research design and purpose. The data will also influence the analysis ...
In a previous paper [1] the use of graphs in research papers was discussed. Tufte, [2] listed the data presentation choices as, the sentence, the table and the graphic, in this paper guidance on ...
The introduction to a research paper parallels the opening argument of a trial; the data and methods and results sections mirror the evidence portion of the tri al; and the discussion and ...
Tables should be comprehensible, and a reader should be able to express an opinion about the results just at looking at the tables without reading the main text. Data included in tables should comply with those mentioned in the main text, and percentages in rows, and columns should be summed up accurately.
DATA PRESENTATION, ANALYSIS AND INTERPRETATION. 4.0 Introduction. This chapter is concerned with data pres entation, of the findings obtained through the study. The. findings are presented in ...
Abstract. The paper analyzes, on a subjective basis, aspects of how to write scientific papers that will be accepted for publication in peer review journals. For each individual section of the manuscript, i.e. Introduction, Materials and methods, Results, Discussion, Abstract, and References, general comments and examples are given.
1 Answer to this question. Answer: Analyzing and presenting qualitative data in a research paper can be difficult. The Methods section is where one needs to justify and present the research design. As you have rightly said, there are stipulations on the word count for a manuscript. To present the interview data, you can consider using a table.
Don't make the reader do the analytic work for you. Now, on to some specific ways to structure your findings section. 1). Tables. Tables can be used to give an overview of what you're about to present in your findings, including the themes, some supporting evidence, and the meaning/explanation of the theme.
To give you a sneak preview for where these models are today as they continue training, we thought we could share some snapshots of how our largest LLM model is trending. Please note that this data is based on an early checkpoint of Llama 3 that is still training and these capabilities are not supported as part of the models released today.
The largest losses are committed at lower latitudes in regions with lower cumulative historical emissions and lower present-day income. ... data over the past 40 years ... Research, Working Paper ...
We present new estimates of earnings volatility over time and the lifecycle for men and women by race and human capital. Using a long panel of restricted-access administrative Social Security earnings linked to the Current Population Survey, we estimate volatility with both transparent summary measures, as well as decompositions into permanent and transitory components.
The purpose of this paper is to help authors to think about ways to present qualitative research papers in the American Journal of Pharmaceutical Education. It also discusses methods for reviewers to assess the rigour, quality, and usefulness of qualitative research. Examples of different ways to present data from interviews, observations, and ...
Sep 2018. Ekavi N Georgousopoulou. PDF | On Aug 31, 2006, Tong Seng Fah and others published How To Present Research Data? | Find, read and cite all the research you need on ResearchGate.
FRIB is the only accelerator-based user facility on a university campus as one of 28 DOE-SC user facilities. Chun Yen Tsang, the first author on the Nature Astronomy paper, was a graduate student under Betty Tsang during this research and is now a researcher working jointly at Brookhaven National Laboratory and Kent State University.
We conducted this analysis to learn more about U.S. crime patterns and how those patterns have changed over time. The analysis relies on statistics published by the FBI, which we accessed through the Crime Data Explorer, and the Bureau of Justice Statistics (BJS), which we accessed through the National Crime Victimization Survey data analysis tool. ...