Social Work Research Methods That Drive the Practice

Social workers advocate for the well-being of individuals, families and communities. But how do social workers know what interventions are needed to help an individual? How do they assess whether a treatment plan is working? What do social workers use to write evidence-based policy?
Social work involves research-informed practice and practice-informed research. At every level, social workers need to know objective facts about the populations they serve, the efficacy of their interventions and the likelihood that their policies will improve lives. A variety of social work research methods make that possible.

Data-Driven Work
Data is a collection of facts used for reference and analysis. In a field as broad as social work, data comes in many forms.
Quantitative vs. Qualitative
As with any research, social work research involves both quantitative and qualitative studies.
Quantitative Research
Answers to questions like these can help social workers know about the populations they serve — or hope to serve in the future.
- How many students currently receive reduced-price school lunches in the local school district?
- How many hours per week does a specific individual consume digital media?
- How frequently did community members access a specific medical service last year?
Quantitative data — facts that can be measured and expressed numerically — are crucial for social work.
Quantitative research has advantages for social scientists. Such research can be more generalizable to large populations, as it uses specific sampling methods and lends itself to large datasets. It can provide important descriptive statistics about a specific population. Furthermore, by operationalizing variables, it can help social workers easily compare similar datasets with one another.
Qualitative Research
Qualitative data — facts that cannot be measured or expressed in terms of mere numbers or counts — offer rich insights into individuals, groups and societies. It can be collected via interviews and observations.
- What attitudes do students have toward the reduced-price school lunch program?
- What strategies do individuals use to moderate their weekly digital media consumption?
- What factors made community members more or less likely to access a specific medical service last year?
Qualitative research can thereby provide a textured view of social contexts and systems that may not have been possible with quantitative methods. Plus, it may even suggest new lines of inquiry for social work research.
Mixed Methods Research
Combining quantitative and qualitative methods into a single study is known as mixed methods research. This form of research has gained popularity in the study of social sciences, according to a 2019 report in the academic journal Theory and Society. Since quantitative and qualitative methods answer different questions, merging them into a single study can balance the limitations of each and potentially produce more in-depth findings.
However, mixed methods research is not without its drawbacks. Combining research methods increases the complexity of a study and generally requires a higher level of expertise to collect, analyze and interpret the data. It also requires a greater level of effort, time and often money.
The Importance of Research Design
Data-driven practice plays an essential role in social work. Unlike philanthropists and altruistic volunteers, social workers are obligated to operate from a scientific knowledge base.
To know whether their programs are effective, social workers must conduct research to determine results, aggregate those results into comprehensible data, analyze and interpret their findings, and use evidence to justify next steps.
Employing the proper design ensures that any evidence obtained during research enables social workers to reliably answer their research questions.
Research Methods in Social Work
The various social work research methods have specific benefits and limitations determined by context. Common research methods include surveys, program evaluations, needs assessments, randomized controlled trials, descriptive studies and single-system designs.
Surveys involve a hypothesis and a series of questions in order to test that hypothesis. Social work researchers will send out a survey, receive responses, aggregate the results, analyze the data, and form conclusions based on trends.
Surveys are one of the most common research methods social workers use — and for good reason. They tend to be relatively simple and are usually affordable. However, surveys generally require large participant groups, and self-reports from survey respondents are not always reliable.
Program Evaluations
Social workers ally with all sorts of programs: after-school programs, government initiatives, nonprofit projects and private programs, for example.
Crucially, social workers must evaluate a program’s effectiveness in order to determine whether the program is meeting its goals and what improvements can be made to better serve the program’s target population.
Evidence-based programming helps everyone save money and time, and comparing programs with one another can help social workers make decisions about how to structure new initiatives. Evaluating programs becomes complicated, however, when programs have multiple goal metrics, some of which may be vague or difficult to assess (e.g., “we aim to promote the well-being of our community”).
Needs Assessments
Social workers use needs assessments to identify services and necessities that a population lacks access to.
Common social work populations that researchers may perform needs assessments on include:
- People in a specific income group
- Everyone in a specific geographic region
- A specific ethnic group
- People in a specific age group
In the field, a social worker may use a combination of methods (e.g., surveys and descriptive studies) to learn more about a specific population or program. Social workers look for gaps between the actual context and a population’s or individual’s “wants” or desires.
For example, a social worker could conduct a needs assessment with an individual with cancer trying to navigate the complex medical-industrial system. The social worker may ask the client questions about the number of hours they spend scheduling doctor’s appointments, commuting and managing their many medications. After learning more about the specific client needs, the social worker can identify opportunities for improvements in an updated care plan.
In policy and program development, social workers conduct needs assessments to determine where and how to effect change on a much larger scale. Integral to social work at all levels, needs assessments reveal crucial information about a population’s needs to researchers, policymakers and other stakeholders. Needs assessments may fall short, however, in revealing the root causes of those needs (e.g., structural racism).
Randomized Controlled Trials
Randomized controlled trials are studies in which a randomly selected group is subjected to a variable (e.g., a specific stimulus or treatment) and a control group is not. Social workers then measure and compare the results of the randomized group with the control group in order to glean insights about the effectiveness of a particular intervention or treatment.
Randomized controlled trials are easily reproducible and highly measurable. They’re useful when results are easily quantifiable. However, this method is less helpful when results are not easily quantifiable (i.e., when rich data such as narratives and on-the-ground observations are needed).
Descriptive Studies
Descriptive studies immerse the researcher in another context or culture to study specific participant practices or ways of living. Descriptive studies, including descriptive ethnographic studies, may overlap with and include other research methods:
- Informant interviews
- Census data
- Observation
By using descriptive studies, researchers may glean a richer, deeper understanding of a nuanced culture or group on-site. The main limitations of this research method are that it tends to be time-consuming and expensive.
Single-System Designs
Unlike most medical studies, which involve testing a drug or treatment on two groups — an experimental group that receives the drug/treatment and a control group that does not — single-system designs allow researchers to study just one group (e.g., an individual or family).
Single-system designs typically entail studying a single group over a long period of time and may involve assessing the group’s response to multiple variables.
For example, consider a study on how media consumption affects a person’s mood. One way to test a hypothesis that consuming media correlates with low mood would be to observe two groups: a control group (no media) and an experimental group (two hours of media per day). When employing a single-system design, however, researchers would observe a single participant as they watch two hours of media per day for one week and then four hours per day of media the next week.
These designs allow researchers to test multiple variables over a longer period of time. However, similar to descriptive studies, single-system designs can be fairly time-consuming and costly.
Learn More About Social Work Research Methods
Social workers have the opportunity to improve the social environment by advocating for the vulnerable — including children, older adults and people with disabilities — and facilitating and developing resources and programs.
Learn more about how you can earn your Master of Social Work online at Virginia Commonwealth University . The highest-ranking school of social work in Virginia, VCU has a wide range of courses online. That means students can earn their degrees with the flexibility of learning at home. Learn more about how you can take your career in social work further with VCU.
From M.S.W. to LCSW: Understanding Your Career Path as a Social Worker
How Palliative Care Social Workers Support Patients With Terminal Illnesses
How to Become a Social Worker in Health Care
Gov.uk, Mixed Methods Study
MVS Open Press, Foundations of Social Work Research
Open Social Work Education, Scientific Inquiry in Social Work
Open Social Work, Graduate Research Methods in Social Work: A Project-Based Approach
Routledge, Research for Social Workers: An Introduction to Methods
SAGE Publications, Research Methods for Social Work: A Problem-Based Approach
Theory and Society, Mixed Methods Research: What It Is and What It Could Be
READY TO GET STARTED WITH OUR ONLINE M.S.W. PROGRAM FORMAT?
Bachelor’s degree is required.
VCU Program Helper
This AI chatbot provides automated responses, which may not always be accurate. By continuing with this conversation, you agree that the contents of this chat session may be transcribed and retained. You also consent that this chat session and your interactions, including cookie usage, are subject to our privacy policy .
- Subject List
- Take a Tour
- For Authors
- Subscriber Services
- Publications
- African American Studies
- African Studies
- American Literature
- Anthropology
- Architecture Planning and Preservation
- Art History
- Atlantic History
- Biblical Studies
- British and Irish Literature
- Childhood Studies
- Chinese Studies
- Cinema and Media Studies
- Communication
- Criminology
- Environmental Science
- Evolutionary Biology
- International Law
- International Relations
- Islamic Studies
- Jewish Studies
- Latin American Studies
- Latino Studies
- Linguistics
- Literary and Critical Theory
- Medieval Studies
- Military History
- Political Science
- Public Health
- Renaissance and Reformation
Social Work
- Urban Studies
- Victorian Literature
- Browse All Subjects
How to Subscribe
- Free Trials
In This Article Expand or collapse the "in this article" section Social Work Research Methods
Introduction.
- History of Social Work Research Methods
- Feasibility Issues Influencing the Research Process
- Measurement Methods
- Existing Scales
- Group Experimental and Quasi-Experimental Designs for Evaluating Outcome
- Single-System Designs for Evaluating Outcome
- Program Evaluation
- Surveys and Sampling
- Introductory Statistics Texts
- Advanced Aspects of Inferential Statistics
- Qualitative Research Methods
- Qualitative Data Analysis
- Historical Research Methods
- Meta-Analysis and Systematic Reviews
- Research Ethics
- Culturally Competent Research Methods
- Teaching Social Work Research Methods
Related Articles Expand or collapse the "related articles" section about
About related articles close popup.
Lorem Ipsum Sit Dolor Amet
Vestibulum ante ipsum primis in faucibus orci luctus et ultrices posuere cubilia Curae; Aliquam ligula odio, euismod ut aliquam et, vestibulum nec risus. Nulla viverra, arcu et iaculis consequat, justo diam ornare tellus, semper ultrices tellus nunc eu tellus.
- Community-Based Participatory Research
- Economic Evaluation
- Evidence-based Social Work Practice
- Evidence-based Social Work Practice: Finding Evidence
- Evidence-based Social Work Practice: Issues, Controversies, and Debates
- Experimental and Quasi-Experimental Designs
- Impact of Emerging Technology in Social Work Practice
- Implementation Science and Practice
- Interviewing
- Measurement, Scales, and Indices
- Meta-analysis
- Occupational Social Work
- Postmodernism and Social Work
- Qualitative Research
- Research, Best Practices, and Evidence-based Group Work
- Social Intervention Research
- Social Work Profession
- Systematic Review Methods
- Technology for Social Work Interventions
Other Subject Areas
Forthcoming articles expand or collapse the "forthcoming articles" section.
- Abolitionist Perspectives in Social Work
- Randomized Controlled Trials in Social Work
- Social Work Practice with Transgender and Gender Expansive Youth
- Find more forthcoming articles...
- Export Citations
- Share This Facebook LinkedIn Twitter
Social Work Research Methods by Allen Rubin LAST REVIEWED: 14 December 2009 LAST MODIFIED: 14 December 2009 DOI: 10.1093/obo/9780195389678-0008
Social work research means conducting an investigation in accordance with the scientific method. The aim of social work research is to build the social work knowledge base in order to solve practical problems in social work practice or social policy. Investigating phenomena in accordance with the scientific method requires maximal adherence to empirical principles, such as basing conclusions on observations that have been gathered in a systematic, comprehensive, and objective fashion. The resources in this entry discuss how to do that as well as how to utilize and teach research methods in social work. Other professions and disciplines commonly produce applied research that can guide social policy or social work practice. Yet no commonly accepted distinction exists at this time between social work research methods and research methods in allied fields relevant to social work. Consequently useful references pertaining to research methods in allied fields that can be applied to social work research are included in this entry.
This section includes basic textbooks that are used in courses on social work research methods. Considerable variation exists between textbooks on the broad topic of social work research methods. Some are comprehensive and delve into topics deeply and at a more advanced level than others. That variation is due in part to the different needs of instructors at the undergraduate and graduate levels of social work education. Most instructors at the undergraduate level prefer shorter and relatively simplified texts; however, some instructors teaching introductory master’s courses on research prefer such texts too. The texts in this section that might best fit their preferences are by Yegidis and Weinbach 2009 and Rubin and Babbie 2007 . The remaining books might fit the needs of instructors at both levels who prefer a more comprehensive and deeper coverage of research methods. Among them Rubin and Babbie 2008 is perhaps the most extensive and is often used at the doctoral level as well as the master’s and undergraduate levels. Also extensive are Drake and Jonson-Reid 2007 , Grinnell and Unrau 2007 , Kreuger and Neuman 2006 , and Thyer 2001 . What distinguishes Drake and Jonson-Reid 2007 is its heavy inclusion of statistical and Statistical Package for the Social Sciences (SPSS) content integrated with each chapter. Grinnell and Unrau 2007 and Thyer 2001 are unique in that they are edited volumes with different authors for each chapter. Kreuger and Neuman 2006 takes Neuman’s social sciences research text and adapts it to social work. The Practitioner’s Guide to Using Research for Evidence-based Practice ( Rubin 2007 ) emphasizes the critical appraisal of research, covering basic research methods content in a relatively simplified format for instructors who want to teach research methods as part of the evidence-based practice process instead of with the aim of teaching students how to produce research.
Drake, Brett, and Melissa Jonson-Reid. 2007. Social work research methods: From conceptualization to dissemination . Boston: Allyn and Bacon.
This introductory text is distinguished by its use of many evidence-based practice examples and its heavy coverage of statistical and computer analysis of data.
Grinnell, Richard M., and Yvonne A. Unrau, eds. 2007. Social work research and evaluation: Quantitative and qualitative approaches . 8th ed. New York: Oxford Univ. Press.
Contains chapters written by different authors, each focusing on a comprehensive range of social work research topics.
Kreuger, Larry W., and W. Lawrence Neuman. 2006. Social work research methods: Qualitative and quantitative applications . Boston: Pearson, Allyn, and Bacon.
An adaptation to social work of Neuman's social sciences research methods text. Its framework emphasizes comparing quantitative and qualitative approaches. Despite its title, quantitative methods receive more attention than qualitative methods, although it does contain considerable qualitative content.
Rubin, Allen. 2007. Practitioner’s guide to using research for evidence-based practice . Hoboken, NJ: Wiley.
This text focuses on understanding quantitative and qualitative research methods and designs for the purpose of appraising research as part of the evidence-based practice process. It also includes chapters on instruments for assessment and monitoring practice outcomes. It can be used at the graduate or undergraduate level.
Rubin, Allen, and Earl R. Babbie. 2007. Essential research methods for social work . Belmont, CA: Thomson Brooks Cole.
This is a shorter and less advanced version of Rubin and Babbie 2008 . It can be used for research methods courses at the undergraduate or master's levels of social work education.
Rubin, Allen, and Earl R. Babbie. Research Methods for Social Work . 6th ed. Belmont, CA: Thomson Brooks Cole, 2008.
This comprehensive text focuses on producing quantitative and qualitative research as well as utilizing such research as part of the evidence-based practice process. It is widely used for teaching research methods courses at the undergraduate, master’s, and doctoral levels of social work education.
Thyer, Bruce A., ed. 2001 The handbook of social work research methods . Thousand Oaks, CA: Sage.
This comprehensive compendium includes twenty-nine chapters written by esteemed leaders in social work research. It covers quantitative and qualitative methods as well as general issues.
Yegidis, Bonnie L., and Robert W. Weinbach. 2009. Research methods for social workers . 6th ed. Boston: Allyn and Bacon.
This introductory paperback text covers a broad range of social work research methods and does so in a briefer fashion than most lengthier, hardcover introductory research methods texts.
back to top
Users without a subscription are not able to see the full content on this page. Please subscribe or login .
Oxford Bibliographies Online is available by subscription and perpetual access to institutions. For more information or to contact an Oxford Sales Representative click here .
- About Social Work »
- Meet the Editorial Board »
- Adolescent Depression
- Adolescent Pregnancy
- Adolescents
- Adoption Home Study Assessments
- Adult Protective Services in the United States
- African Americans
- Aging out of foster care
- Aging, Physical Health and
- Alcohol and Drug Abuse Problems
- Alcohol and Drug Problems, Prevention of Adolescent and Yo...
- Alcohol Problems: Practice Interventions
- Alcohol Use Disorder
- Alzheimer's Disease and Other Dementias
- Anti-Oppressive Practice
- Asian Americans
- Asian-American Youth
- Autism Spectrum Disorders
- Baccalaureate Social Workers
- Behavioral Health
- Behavioral Social Work Practice
- Bereavement Practice
- Bisexuality
- Brief Therapies in Social Work: Task-Centered Model and So...
- Bullying and Social Work Intervention
- Canadian Social Welfare, History of
- Case Management in Mental Health in the United States
- Central American Migration to the United States
- Child Maltreatment Prevention
- Child Neglect and Emotional Maltreatment
- Child Poverty
- Child Sexual Abuse
- Child Welfare
- Child Welfare and Child Protection in Europe, History of
- Child Welfare and Parents with Intellectual and/or Develop...
- Child Welfare Effectiveness
- Child Welfare, Immigration and
- Child Welfare Practice with LGBTQ Youth and Families
- Children of Incarcerated Parents
- Christianity and Social Work
- Chronic Illness
- Clinical Social Work Practice with Adult Lesbians
- Clinical Social Work Practice with Males
- Cognitive Behavior Therapies with Diverse and Stressed Pop...
- Cognitive Processing Therapy
- Cognitive-Behavioral Therapy
- Community Development
- Community Policing
- Community-Needs Assessment
- Comparative Social Work
- Computational Social Welfare: Applying Data Science in Soc...
- Conflict Resolution
- Council on Social Work Education
- Counseling Female Offenders
- Criminal Justice
- Crisis Interventions
- Cultural Competence and Ethnic Sensitive Practice
- Culture, Ethnicity, Substance Use, and Substance Use Disor...
- Dementia Care
- Dementia Care, Ethical Aspects of
- Depression and Cancer
- Development and Infancy (Birth to Age Three)
- Differential Response in Child Welfare
- Digital Storytelling for Social Work Interventions
- Direct Practice in Social Work
- Disabilities
- Disability and Disability Culture
- Domestic Violence Among Immigrants
- Early Pregnancy and Parenthood Among Child Welfare–Involve...
- Eating Disorders
- Ecological Framework
- Elder Mistreatment
- End-of-Life Decisions
- Epigenetics for Social Workers
- Ethical Issues in Social Work and Technology
- Ethics and Values in Social Work
- European Institutions and Social Work
- European Union, Justice and Home Affairs in the
- Evidence-based Social Work Practice: Issues, Controversies...
- Families with Gay, Lesbian, or Bisexual Parents
- Family Caregiving
- Family Group Conferencing
- Family Policy
- Family Services
- Family Therapy
- Family Violence
- Fathering Among Families Served By Child Welfare
- Fetal Alcohol Spectrum Disorders
- Field Education
- Financial Literacy and Social Work
- Financing Health-Care Delivery in the United States
- Forensic Social Work
- Foster Care
- Foster care and siblings
- Gender, Violence, and Trauma in Immigration Detention in t...
- Generalist Practice and Advanced Generalist Practice
- Grounded Theory
- Group Work across Populations, Challenges, and Settings
- Group Work, Research, Best Practices, and Evidence-based
- Harm Reduction
- Health Care Reform
- Health Disparities
- Health Social Work
- History of Social Work and Social Welfare, 1900–1950
- History of Social Work and Social Welfare, 1950-1980
- History of Social Work and Social Welfare, pre-1900
- History of Social Work from 1980-2014
- History of Social Work in China
- History of Social Work in Northern Ireland
- History of Social Work in the Republic of Ireland
- History of Social Work in the United Kingdom
- HIV/AIDS and Children
- HIV/AIDS Prevention with Adolescents
- Homelessness
- Homelessness: Ending Homelessness as a Grand Challenge
- Homelessness Outside the United States
- Human Needs
- Human Trafficking, Victims of
- Immigrant Integration in the United States
- Immigrant Policy in the United States
- Immigrants and Refugees
- Immigrants and Refugees: Evidence-based Social Work Practi...
- Immigration and Health Disparities
- Immigration and Intimate Partner Violence
- Immigration and Poverty
- Immigration and Spirituality
- Immigration and Substance Use
- Immigration and Trauma
- Impaired Professionals
- Indigenous Peoples
- Individual Placement and Support (IPS) Supported Employmen...
- In-home Child Welfare Services
- Intergenerational Transmission of Maltreatment
- International Human Trafficking
- International Social Welfare
- International Social Work
- International Social Work and Education
- International Social Work and Social Welfare in Southern A...
- Internet and Video Game Addiction
- Interpersonal Psychotherapy
- Intervention with Traumatized Populations
- Intimate-Partner Violence
- Juvenile Justice
- Kinship Care
- Korean Americans
- Latinos and Latinas
- Law, Social Work and the
- LGBTQ Populations and Social Work
- Mainland European Social Work, History of
- Major Depressive Disorder
- Management and Administration in Social Work
- Maternal Mental Health
- Medical Illness
- Men: Health and Mental Health Care
- Mental Health
- Mental Health Diagnosis and the Addictive Substance Disord...
- Mental Health Needs of Older People, Assessing the
- Mental Health Services from 1990 to 2023
- Mental Illness: Children
- Mental Illness: Elders
- Microskills
- Middle East and North Africa, International Social Work an...
- Military Social Work
- Mixed Methods Research
- Moral distress and injury in social work
- Motivational Interviewing
- Multiculturalism
- Native Americans
- Native Hawaiians and Pacific Islanders
- Neighborhood Social Cohesion
- Neuroscience and Social Work
- Nicotine Dependence
- Organizational Development and Change
- Pain Management
- Palliative Care
- Palliative Care: Evolution and Scope of Practice
- Pandemics and Social Work
- Parent Training
- Personalization
- Person-in-Environment
- Philosophy of Science and Social Work
- Physical Disabilities
- Podcasts and Social Work
- Police Social Work
- Political Social Work in the United States
- Positive Youth Development
- Postsecondary Education Experiences and Attainment Among Y...
- Post-Traumatic Stress Disorder (PTSD)
- Practice Interventions and Aging
- Practice Interventions with Adolescents
- Practice Research
- Primary Prevention in the 21st Century
- Productive Engagement of Older Adults
- Profession, Social Work
- Program Development and Grant Writing
- Promoting Smart Decarceration as a Grand Challenge
- Psychiatric Rehabilitation
- Psychoanalysis and Psychodynamic Theory
- Psychoeducation
- Psychometrics
- Psychopathology and Social Work Practice
- Psychopharmacology and Social Work Practice
- Psychosocial Framework
- Psychosocial Intervention with Women
- Psychotherapy and Social Work
- Race and Racism
- Readmission Policies in Europe
- Redefining Police Interactions with People Experiencing Me...
- Refugee Children, Unaccompanied Immigrant and
- Rehabilitation
- Religiously Affiliated Agencies
- Reproductive Health
- Restorative Justice
- Risk Assessment in Child Protection Services
- Risk Management in Social Work
- Rural Social Work in China
- Rural Social Work Practice
- School Social Work
- School Violence
- School-Based Delinquency Prevention
- Services and Programs for Pregnant and Parenting Youth
- Severe and Persistent Mental Illness: Adults
- Sexual and Gender Minority Immigrants, Refugees, and Asylu...
- Sexual Assault
- Single-System Research Designs
- Social and Economic Impact of US Immigration Policies on U...
- Social Development
- Social Insurance and Social Justice
- Social Justice and Social Work
- Social Movements
- Social Planning
- Social Policy
- Social Policy in Denmark
- Social Security in the United States (OASDHI)
- Social Work and Islam
- Social Work and Social Welfare in East, West, and Central ...
- Social Work and Social Welfare in Europe
- Social Work Education and Research
- Social Work Leadership
- Social Work Luminaries: Luminaries Contributing to the Cla...
- Social Work Luminaries: Luminaries contributing to the fou...
- Social Work Luminaries: Luminaries Who Contributed to Soci...
- Social Work Practice, Rare and Orphan Diseases and
- Social Work Regulation
- Social Work Research Methods
- Social Work with Interpreters
- Solution-Focused Therapy
- Strategic Planning
- Strengths Perspective
- Strengths-Based Models in Social Work
- Supplemental Security Income
- Survey Research
- Sustainability: Creating Social Responses to a Changing En...
- Syrian Refugees in Turkey
- Task-Centered Practice
- Technology Adoption in Social Work Education
- Technology, Human Relationships, and Human Interaction
- Technology in Social Work
- Terminal Illness
- The Impact of Systemic Racism on Latinxs’ Experiences with...
- Transdisciplinary Science
- Translational Science and Social Work
- Transnational Perspectives in Social Work
- Transtheoretical Model of Change
- Trauma-Informed Care
- Triangulation
- Tribal child welfare practice in the United States
- United States, History of Social Welfare in the
- Universal Basic Income
- Veteran Services
- Vicarious Trauma and Resilience in Social Work Practice wi...
- Vicarious Trauma Redefining PTSD
- Victim Services
- Virtual Reality and Social Work
- Welfare State Reform in France
- Welfare State Theory
- Women and Macro Social Work Practice
- Women's Health Care
- Work and Family in the German Welfare State
- Workforce Development of Social Workers Pre- and Post-Empl...
- Working with Non-Voluntary and Mandated Clients
- Young and Adolescent Lesbians
- Youth at Risk
- Youth Services
- Privacy Policy
- Cookie Policy
- Legal Notice
- Accessibility
Powered by:
- [81.177.182.154]
- 81.177.182.154
Scientific Inquiry in Social Work
(9 reviews)
Matthew DeCarlo, Radford University
Copyright Year: 2018
ISBN 13: 9781975033729
Publisher: Open Social Work Education
Language: English
Formats Available
Conditions of use.
Learn more about reviews.
Reviewed by Shannon Blajeski, Assistant Professor, Portland State University on 3/10/23
This book provides an introduction to research and inquiry in social work with an applied focus geared for the MSW student. The text covers 16 chapters, including several dedicated to understanding how to begin the research process, a chapter on... read more
Comprehensiveness rating: 5 see less
This book provides an introduction to research and inquiry in social work with an applied focus geared for the MSW student. The text covers 16 chapters, including several dedicated to understanding how to begin the research process, a chapter on ethics, and then eight chapters dedicated to research methods. The subchapters (1-5 per chapter) are concise and focused while also being tied to current knowledge and events so as to hold the reader's attention. It is comprehensive, but some of the later chapters covering research methods as well as the final chapter seem a bit scant and could be expanded. The glossary at the end of each chapter is helpful as is the index that is always accessible from the left-hand drop-down menu.
Content Accuracy rating: 4
The author pulls in relevant current and recent public events to illustrate important points about social research throughout the book. Each sub-chapter reads as accurate. I did not come across any inaccuracies in the text, however I would recommend a change in the title of Chapter 15 as "real world research" certainly encompasses more than program evaluation, single-subject designs, and action research.
Relevance/Longevity rating: 5
Another major strength of this book is that it adds currency to engage the reader while also maintaining its relevance to research methods. None of the current events/recent events that are described seem dated nor will they fade from relevance in a number of years. In addition, the concise nature of the modules should make them easy to update when needed to maintain relevancy in future editions.
Clarity rating: 5
Clarity is a major strength of this textbook. As described in the interface section, this book is written to be clear and concise, without unnecessary extra text that detracts from the concise content provided in each chapter. Any lengthy excerpts are also very engaging which lends itself to a clear presentation of content for the reader.
Consistency rating: 5
The text and content seems to be presented consistently throughout the book. Terminology and frameworks are balanced with real-world examples and current events.
Modularity rating: 5
The chapters of this textbook are appropriately spaced and easily digestible, particularly for readers with time constraints. Each chapter contains 3-5 sub-chapters that build upon each other in a scaffolding style. This makes it simple for the instructor to assign each chapter (sometimes two) per weekly session as well as add in additional assigned readings to complement the text.
Organization/Structure/Flow rating: 5
The overall organization of the chapters flow well. The book begins with a typical introduction to research aimed at social work practitioners or new students in social work. It then moves into a set of chapters on beginning a research project, reviewing literature, and asking research questions, followed by a chapter on ethics. Next, the text transitions to three chapters covering constructs, measurement, and sampling, followed by five chapters covering research methods, and a closing chapter on dissemination of research. This is one of the more logically-organized research methods texts that I have used as an instructor.
Interface rating: 5
The modular chapters are easy to navigate and the interface of each chapter follows a standard presentation style with the reading followed by a short vocabulary glossary and references. This presentation lends itself to a familiarity for students that helps them become more efficient with completing reading assignments, even in short bursts of time. This is particularly important for online and returning learners who may juggle their assignment time with family and work obligations.
Grammatical Errors rating: 5
No grammatical errors were noted.
Cultural Relevance rating: 4
At first glance at the table of contents, the book doesn't seem to be overtly committed to cultural representation, however, upon reading the chapters, it becomes clear that the author does try to represent and reference marginalized groups (e.g., women, individuals with disabilities, racial/ethnic/gender intersectionality) within the examples used. I also am very appreciative that the bottom of each introduction page for each chapter contains content trigger warnings for any possible topics that could be upsetting, e.g., substance abuse, violence.
As the author likely knows, social work students are eager to engage in learning that is current and relevant to their social causes. This book is written in a way that engages a non-researcher social worker into reading about research by weaving research information into topics that they might find compelling. It also does this in a concise way where short bits of pertinent information are presented, making the text accessible without needing to sustain long periods of attention. This is particularly important for online and returning learners who may need to sit with their readings in short bursts due to attending school while juggling work and family obligations.
Reviewed by Lynn Goerdt, Associate Professor, University of Wisconsin - Superior on 9/17/21
Text appears to be comprehensive in covering steps for typical SWK research class, taking students from the introduction of the purpose and importance of research to how to design and analyze research. Author covers the multitude of ways that... read more
Text appears to be comprehensive in covering steps for typical SWK research class, taking students from the introduction of the purpose and importance of research to how to design and analyze research. Author covers the multitude of ways that social workers engage in research as way of building knowledge and ways that social work practitioners conduct research to evaluate their practice, including outcome evaluation, single subject design, and action research. I particularly appreciated the last section on reporting research, which should be very practical.
Overall, content appears mostly accurate which few errors. Definitions and citations are mostly thorough and clear. Author does cite Wikipedia in at least one occasion which could be credible, depending on the source of the Wikipedia content. There were a few references within the text to comic or stories but the referenced material was not always apparent.
Relevance/Longevity rating: 4
The content of Scientific Inquiry for Social Work is relevant, as the field of social work research methods does not appear to change quickly, although there are innovations. The author referenced examples which appear to be recent and likely relatable to interests of current students. Primary area of innovation is in using technology for the collection and analysis of data, which could be expanded, particularly using social media for soliciting research participants.
Style is personable and content appears to be accessible, which is a unique attribute for a research textbook. Author uses first person in many instances, particularly in the beginning to present the content as relatable.
Format appears to be consistent in format and relative length. Each chapter includes learning objectives, content advisory (if applicable), key takeaways and glossary. Author uses color and text boxes to draw attention to these sections.
Modularity rating: 4
Text is divided into modules which could easily be assigned and reviewed in a class. The text modules could also be re-structured if desired to fit curricular uniqueness’s. Author uses images to illuminate the concepts of the module or chapter, but they often take about 1/3 of the page, which extends the size of the textbook quite a bit. Unclear if benefit of images outweighs additional cost if PDF version is printed.
Textbook is organized in a very logical and clear fashion. Each section appears to be approximately 6-10 pages in length which seems to be an optimal length for student attention and comprehension.
Interface rating: 4
There were some distortions of the text (size and visibility) but they were a fairly minor distraction and did not appear to reduce access to the content. Otherwise text was easy to navigate.
Grammatical Errors rating: 4
No grammatical errors were noted but hyperlinks to outside content were referenced but not always visible which occasionally resulted in an awkward read. Specific link may be in resources section of each chapter but occasionally they were also included in the text.
I did not recognize any text which was culturally insensitive or offensive. Images used which depicted people, appeared to represent diverse experiences, cultures, settings and persons. Did notice image depicting homelessness appeared to be stereotypical person sleeping on sidewalk, which can perpetuate a common perception of homelessness. Would encourage author to consider images representing a wider range of experiences of a social phenomena. Content advisories are used for each section, which is not necessarily cultural relevance but is respectful and recognizes the diversity of experiences and triggers that the readers may have.
Overall, I was very impressed and encouraged with the well organized content and thoughtful flow of this important textbook for social work students and instructors. The length and readability of each chapter would likely be appreciated by instructors as well as students, increasing the extent that the learning outcomes would be achieved. Teaching research is very challenging because the content and application can feel very intimidating. The author also has provided access to supplemental resources such as presentations and assignments.
Reviewed by elaine gatewood, Adjunct Faculty, Bridgewater State University on 6/15/21
The book provides concrete and clear information on using research as consumers, It provides a comprehensive review of each step to take to develop a research project from beginning to completion, with examples. read more
The book provides concrete and clear information on using research as consumers, It provides a comprehensive review of each step to take to develop a research project from beginning to completion, with examples.
Content Accuracy rating: 5
From my perspective, content is highly accurate in the field of learning research method and unbiased. It's all there!
The content is highly relevant and up-to-date in the field. The book is written and arranged in a way that its easy to follow along with adding updates.
The book is written in clear and concise. The book provides appropriate context for any jargon/technical terminology used along with examples which readers are able to follow along and understand.
The contents of the book flow quite well. The framework in the book is consistent.
The text appears easily adaptable for readers and the author also provides accompanying PowerPoint presentations; these are a good foundation tools for readers to use and implement.
Organization/Structure/Flow rating: 4
The contents of the book flow very well. Readers would be able to put into practice the key reading strategies shared in the book ) because its organization is laid out nicely
Interface rating: 3
The interface is generally good, but I was only able to download the .pdf. This may present issues for some student readers.
There are no grammatical errors.
The text was culturally relevant and provided diverse research and practice examples. The text could have benefited from sexamples of intersectional and anti-oppressive lenses for students to consider in their practice.
This text is a comprehensive introduction to research that can be easily adapted for a BSW/MSW research course.
Reviewed by Taylor Hall, Assistant Professor, Bridgewater State University on 6/30/20
This text is more comprehensive than the text I currently use in my Research Methods in Social Work course, which students have to pay for. This text not only covers both qualitative and quantitative research methods, but also all parts of the... read more
This text is more comprehensive than the text I currently use in my Research Methods in Social Work course, which students have to pay for. This text not only covers both qualitative and quantitative research methods, but also all parts of the research process from thinking about research ideas to questions all the way to evaluation after social work programs/policies have been employed.
Not much to say here- with research methods, things are black and white; it is or isn't. This content is accurate. I also like to way the content is explained in light of social work values and ethics. This is something our students can struggle with, and this is helpful in terms of showing why social work needs to pay attention to research.
There are upcoming changes to CSWE's competencies, therefore lots of text materials are going to need to be updated soon. Otherwise, case examples are pertinent and timely.
Clarity rating: 4
I think that research methods for social workers is a difficult field of study. Many go into the field to be clinicians, and few understand (off the bat) the importance of understanding methods of research. I think this textbook makes it clear to me, but hard to rate a 5 as I know from a student's perspective, lots of the terminology is so new.
Appears to be so- I was able to follow, seems consistent.
Yes- and I think this is a strong point of this text. This was easy to follow and read, and I could see myself easily divvying up different sections for students to work on in groups.
Yes- makes sense to me and the way I teach this course. I like the 30,000 ft view then honing in on specific types of research, all along the way explaining the different pieces of the research process and in writing a research paper.
I sometimes struggle with online platforms versus in person texts to read, and this OER is visually appealing- there is not too much text on the pages, it is spaced in a way that makes it easier to read. Colors are used well to highlight pertinent information.
Not something I found in this text.
Cultural Relevance rating: 3
This is a place where I feel the text could use some work. A nod to past wrongdoings in research methods on oppressed groups, and more of a discussion on social work's role in social justice with an eye towards righting the wrongs of the past. Updated language re: person first language, more diverse examples, etc.
This is a very useful text, and I am going to recommend my department check it out for future use, especially as many of our students are first gen and working class and would love to save money on textbooks where possible.
Reviewed by Olubunmi Oyewuwo-Gassikia, Assistant Professor, Northeastern Illinois University on 5/5/20
This text is an appropriate and comprehensive introduction to research methods for BSW students. It guides the reader through each stage of the research project, including identifying a research question, conducting and writing a literature... read more
This text is an appropriate and comprehensive introduction to research methods for BSW students. It guides the reader through each stage of the research project, including identifying a research question, conducting and writing a literature review, research ethics, theory, research design, methodology, sampling, and dissemination. The author explains complex concepts - such as paradigms, epistemology, and ontology - in clear, simple terms and through the use of practical, social work examples for the reader. I especially appreciated the balanced attention to quantitative and qualitative methods, including the explanation of data collection and basic analysis techniques for both. The text could benefit from the inclusion of an explanation of research design notations.
The text is accurate and unbiased. Additionally, the author effectively incorporates referenced sources, including sources one can use for further learning.
The content is relevant and timely. The author incorporates real, recent research examples that reflects the applicability of research at each level of social practice (micro, meso, and macro) throughout the text. The text will benefit from regular updates in research examples.
The text is written in a clear, approachable manner. The chapters are a reasonable length without sacrificing appropriate depth into the subject manner.
The text is consistent throughout. The author is effective in reintroducing previously explained terms from previous chapters.
The text appears easily adaptable. The instructions provided by the author on how to adapt the text for one's course are helpful to one who would like to use the text but not in its entirety. The author also provides accompanying PowerPoint presentations; these are a good foundation but will likely require tailoring based on the teaching style of the instructor.
Generally, the text flows well. However, chapter 5 (Ethics) should come earlier, preferably before chapter 3 (Reviewing & Evaluating the Literature). It is important that students understand research ethics as ethical concerns are an important aspect of evaluating the quality of research studies. Chapter 15 (Real-World Research) should also come earlier in the text, most suitably before or after chapter 7 (Design and Causality).
The interface is generally good, but I was only able to download the .pdf. The setup of the .pdf is difficult to navigate, especially if one wants to jump from chapter to chapter. This may present issues for the student reader.
The text was culturally relevant and provided diverse research and practice examples. The text could have benefited from more critical research examples, such as examples of research studies that incorporate intersectional and anti-oppressive lenses.
This text is a comprehensive introduction to research that can be easily adapted for a BSW level research course.
Reviewed by Smita Dewan, Assistant Professor, New York City College of Technology, Department of Human Services on 12/6/19
This is a very good introductory research methodology textbook for undergraduate students of social work or human services. For students who might be intimidated by social research, the text provides assurance that by learning basic concepts of... read more
Comprehensiveness rating: 4 see less
This is a very good introductory research methodology textbook for undergraduate students of social work or human services. For students who might be intimidated by social research, the text provides assurance that by learning basic concepts of research methodology, students will be better scholars and social work or human service practitioners. The content and flow of the text book supports a basic assignment of most research methodology courses which is to develop a research proposal or a research project. Each stage of research is explained well with many examples from social work practice that has the potential to keep the student engaged.
The glossary at the end of each chapter is very comprehensive but does not include the page number/s where the content is located. The glossary at the end of the book also lacks page numbers which might make it cumbersome for students seeking a quick reference.
The content is accurate and unbiased. Suggested exercises and prompts for students to engage in critical thinking and to identify biases in research that informs practice may help students understand the complexities of social research.
Content is up-to-date and concepts of research methodology presented is unlikely to be obsolete in the coming years. However, recent trends in research such as data mining, using algorithms for social policy and practice implications, privacy concerns, role of social media are topics that could be considered for inclusion in the forthcoming editions.
Content is presented very clearly for undergraduate students. Key takeaways and glossary for each section of the chapter is very useful for students.
Presentation of content, format and organization is consistent throughout the book.
Subsections within each chapter is very helpful for the students who might be assigned readings just in parts for the class.
Students would benefit from reading about research ethics right after the introductory chapter. I would also move Chapter 8 to right after the literature review which might inform creating and refining the research question. Content on evaluation research could also be moved up to follow the chapter on experimental designs. Regardless of the organization, the course instructors can assign chapters according to the course requirements.
PDF version of the book is very easy to use especially as students can save a copy on their computers and do not have to be online. Charts and tables are well presented but some of the images/photographs do not necessarily serve to enhance learning. Image attributions could be provided at the end of the chapter instead of being listed under the glossary. Students might also find it useful to be able to highlight the content and make annotations. This requires that students sign-in. Students should be able to highlight and annotate a downloaded version through Adobe Reader.
I did not find any grammatical errors.
Cultural Relevance rating: 5
Content is not insensitive or offensive in any way. Supporting examples in chapters are very diverse. Students would benefit from some examples of international research (both positive and negative examples) of protection of human subjects.
Reviewed by Jill Hoffman, Assistant Professor, Portland State University on 10/29/19
This text includes 16 chapters that cover content related to the process of conducting research. From identifying a topic and reviewing the literature, to formulating a question, designing a study, and disseminating findings, the text includes... read more
This text includes 16 chapters that cover content related to the process of conducting research. From identifying a topic and reviewing the literature, to formulating a question, designing a study, and disseminating findings, the text includes research basics that most other introductory social work research texts include. Content on ethics, theory, and to a lesser extent evaluation, single-subject design, and action research are also included. There is a glossary at the end of the text that includes information on the location of the terms. There is a practice behaviors index, but not an index in the traditional sense. If using the text electronically, search functions make it easy to find necessary information despite not having an index. If using a printed version, this would be more difficult. The text includes examples to illustrate concepts that are relevant to settings in which social workers might work. As most other introductory social work research texts, this book appears to come from a mainly positivist view. I would have appreciated more of a discussion related to power, privilege, and oppression and the role these play in the research topics that get studied and who benefits, along with anti-oppressive research. Related to evaluations, a quick mention of logic models would be helpful.
The information appears to be accurate and error free. The language in the text seems to emphasize "right/wrong" choices/decisions instead of highlighting the complexities of research and practice. Using gender-neutral pronouns would also make the language more inclusive.
Content appears to be up-to-date and relevant. Any updating would be straightforward to carry out. I found at least one link that did not work (e.g., NREPP) so if you use this text it will be important to check and make sure things are updated.
The content is clearly written, using examples to illustrate various concepts. I appreciated prompts for questions throughout each chapter in order to engage students in the content. Key terms are bolded, which helps to easily identify important points.
Information is presented in a consistent manner throughout the text.
Each chapter is divided into subsections that help with readability. It is easy to pick and choose various pieces of the text for your course if you're not using the entire thing.
There are many ways you can organize a social work research text. Personally, I prefer to talk about ethics and theory early on, so that students have this as a framework as they read about other's studies and design their own. In the case of this text, I'd put those two chapters right after chapter 1. As others have suggested, I'd also move up the content on research questions, perhaps after chapter 4.
In the online version, no significant interface issues arose. The only thing that would be helpful is to have chapter titles clearly presented when navigating through the text in the online version. For example, when you click through to a new chapter, the title simply says "6.0 Chapter introduction." In order to see the chapter title you have to click into the contents tab. Not a huge issue but could help with navigating the online version. In the pdf version, the links in the table of contents allowed me to navigate through to various sections. I did notice that some of the external links were not complete (e.g., on page 290, the URL is linked as "http://baby-").
Cultural representation in the text is similar to many other introductory social work research texts. There's more of an emphasis on white, western, cis-gendered individuals, particularly in the images. In examples, it appeared that only male/female pronouns were used.
Reviewed by Monica Roth Day, Associate Professor, Social Work, Metropolitan State University (Saint Paul, Minnesota) on 12/26/18
The book provides concrete and clear information on using research as consumers, then developing research as producers of knowledge. It provides a comprehensive review of each step to take to develop a research project from beginning to... read more
The book provides concrete and clear information on using research as consumers, then developing research as producers of knowledge. It provides a comprehensive review of each step to take to develop a research project from beginning to completion, with appropriate examples. More specific social work links would be helpful as students learn more about the field and the uses of research.
The book is accurate and communicates information and largely without bias. Numerous examples are provided from varied sources, which are then used to discuss potential for bias in research. The addition of critical race theory concepts would add to this discussion, to ground students in the importance of understanding implicit bias as researchers and ways to develop their own awareness.
The book is highly relevant. It provides historical and current examples of research which communicate concepts using accessible language that is current to social work. The text is written so that updates should be easy. Links need to be updated on a regular basis.
The book is accessible for students at it uses common language to communicate concepts while helping students build their research vocabulary. Terminology is communicate both within the text and in glossaries, and technical terms are minimally used.
The book is consistent in its use of terminology and framework. It follows a pattern of development, from consuming research to producing research. The steps are predictable and walk students through appropriate actions to take.
The book is easily readable. Each chapter is divided in sections that are easy to navigate and understand. Pictures and tables are used to support text.
Chapters are in logical order and follow a common pattern.
When reading the book online, the text was largely free of interface issues. As a PDF, there were issues with formatting. Be aware that students who may wish to download the book into a Kindle or other book reader may experience issues.
The text was grammatically correct with no misspellings.
While the book is culturally relevant, it lacks the application of critical race theory. While students will learn about bias in research, critical race theory would ground students in the importance of understanding implicit bias as researchers and ways to develop their own awareness. It would also help students understand why the background of researchers is important in relation to the ways of knowing.
Reviewed by Jennifer Wareham, Associate Professor, Wayne State University on 11/30/18
The book provides a comprehensive introduction to research methods from the perspective of the discipline of Social Work. The book borrows heavily from Amy Blackstone’s Principles of Sociological Inquiry – Qualitative and Quantitative Methods open... read more
The book provides a comprehensive introduction to research methods from the perspective of the discipline of Social Work. The book borrows heavily from Amy Blackstone’s Principles of Sociological Inquiry – Qualitative and Quantitative Methods open textbook. The book is divided into 16 chapters, covering: differences in reasoning and scientific thought, starting a research project, writing a literature review, ethics in social science research, how theory relates to research, research design, causality, measurement, sampling, survey research, experimental design, qualitative interviews and focus groups, evaluation research, and reporting research. Some of the more advanced concepts and topics are only covered at superficial level, which limits the intended population of readers to high school students, undergraduate students, or those with no background in research methods. Since the book is geared toward Social Work undergraduate students, the chapters and content address methodologies commonly used in this field, but ignore methodologies that may be more popular in other social science fields. For example, the material on qualitative methods is narrow and focuses on commonly used qualitative methods in Social Work. In addition, the chapter on evaluation is limited to a general overview of evaluation research, which could be improved with more in-depth discussion of different types of evaluation (e.g., needs assessment, evaluability assessment, process evaluation, impact/outcomes evaluation) and real-world examples of different types of evaluation implemented in Social Work. Overall, the author provides examples that are easy for practitioners in Social Work to understand, which are also easily relatable for students in similar disciplines such as criminal justice. The book provides a glossary of key terms. There is no index; however, users can search for terms using the find (Ctrl-F) function in the PDF version of the book.
Overall, the content inside this book is accurate, error-free, and unbiased. However, the content is limited to the Social Work perspective, which may be considered somewhat biased or inaccurate from the perspective of others in different disciplines.
The book describes classic examples used in most texts on social science research methods. It also includes contemporary and relevant examples. Some of the content (such as web addresses and contemporary news pieces) will need to be updated every few years. The text is written and arranged in such a way that any necessary updates should be relatively easy and straightforward to implement.
The book is written in clear and accessible prose. The book provides appropriate context for any jargon/technical terminology used. Readers from any social science discipline should be able to understand the content and context of the material presented in the book.
The framework and use of terminology in the book are consistent.
This book is highly modular. The author has even improved upon the modularity of the book from Blackstone’s open text (which serves as the basis of the present text). Each chapter is divided into short, related subsections. The design of the chapters and their subsections make it easy to divide the material into units of study across a semester or quarter of instruction.
Generally, the book is organized in a similar manner as other texts on social science research methods. However, the organization could be improved slightly. Chapters 2 through 4 describe the process of beginning a research project and conducting a literature review. Chapter 8 describes refining a research question. This chapter could be moved to follow the Chapter 4. Chapter 12 describes experimental design, while Chapter 15 provides a description and examples of evaluation research. Since evaluation research tends to rely on experimental and quasi-experimental design, this chapter should follow the experimental design chapter.
For the online version of the book, there were no interface issues. The images and charts were clear and readable. The hyperlinks to sources mentioned in the text worked. The Contents menu allowed for easy and quick access to any section of the book. For the PDF version of the book, there were interface issues. The images and charts were clear and readable. However, the URLs and hyperlinks were not active in the PDF version. Furthermore, the PDF version was not bookmarked, which made it more difficult to access specific sections of the book.
I did not find grammatical errors in the book.
Overall, the cultural relevance and sensitivity were consistent with other social science research methods texts. The author does a good job of using both female and male pronouns in the prose. While there are pictures of people of color, there could be more. Most of the pictures are of white people. Also, the context is generally U.S.-centric.
Table of Contents
- Chapter 1: Introduction to research
- Chapter 2: Beginning a research project
- Chapter 3: Reading and evaluating literature
- Chapter 4: Conducting a literature review
- Chapter 5: Ethics in social work research
- Chapter 6: Linking methods with theory
- Chapter 7: Design and causality
- Chapter 8: Creating and refining a research question
- Chapter 9: Defining and measuring concepts
- Chapter 10: Sampling
- Chapter 11: Survey research
- Chapter 12: Experimental design
- Chapter 13: Interviews and focus groups
- Chapter 14: Unobtrusive research: Qualitative and quantitative approaches
- Chapter 15: Real-world research: Evaluation, single-subjects, and action research
- Chapter 16: Reporting and reading research
Ancillary Material
- Open Social Work Education
About the Book
As an introductory textbook for social work students studying research methods, this book guides students through the process of creating a research project. Students will learn how to discover a researchable topic that is interesting to them, examine scholarly literature, formulate a proper research question, design a quantitative or qualitative study to answer their question, carry out the design, interpret quantitative or qualitative results, and disseminate their findings to a variety of audiences. Examples are drawn from the author's practice and research experience, as well as topical articles from the literature.
There are ancillary materials available for this book.
About the Contributors
Matt DeCarlo earned his PhD in social work at Virginia Commonwealth University and is an Assistant Professor of Social Work at Radford University. He earned an MSW from George Mason University in 2010 and a BA in Psychology from the College of William and Mary in 2007. His research interests include open educational resources, self-directed Medicaid supports, and basic income. Matt is an Open Textbook Network Campus Leader for Radford University. He is the founder of Open Social Work Education, a non-profit collaborative advancing OER in social work education.
Get Citation
Research for Social Workers has built a strong reputation as an accessible guide to the key research methods and approaches used in the discipline. Ideal for beginners, the book outlines the importance of social work research, its guiding principles and explains how to choose a topic area, develop research questions together with describing the key steps in the research process. The authors outline the principles of sampling, systematic reviews and surveys and interviews, provide guidance on evaluation and statistical analysis and explain how research can influence policy and practice. This new edition includes: • an expanded discussion of rigour in qualitative research • more detailed analysis of systematic reviews • a new section on on-line surveys • enhanced examination of action research including recent examples of action research programs and • an expanded section on evidence-based practice. Featuring practical examples and end-of-chapter exercises and questions, and using non-technical language throughout, this is a vital reference tool for both students and practicing social workers.
TABLE OF CONTENTS
Part i | 109 pages, beginning social work research, chapter 1 | 36 pages, social work research, chapter 2 | 14 pages, choosing your topic area, chapter 3 | 28 pages, developing research questions, chapter 4 | 29 pages, steps in the research process, part ii | 114 pages, research methods for social work, chapter 5 | 20 pages, chapter 6 | 27 pages, systematic reviews, chapter 7 | 38 pages, surveys and interviews, chapter 8 | 27 pages, assessing community needs and strengths, part iii | 116 pages, chapter 9 | 25 pages, how do i evaluate my program, chapter 10 | 20 pages, action research, chapter 11 | 25 pages, evidence-based practice and best practice evaluation, chapter 12 | 23 pages, research in post-disaster recovery and other crisis situations: community-based rapid appraisals, chapter 13 | 21 pages, other methods, part iv | 110 pages, statistical analysis, chapter 14 | 24 pages, producing results: qualitative research, chapter 15 | 18 pages, producing results: quantitative research, chapter 16 | 33 pages, statistics for social workers: analysis of a single variable, chapter 17 | 33 pages, statistics for social workers: two or more variables, part v | 44 pages, bringing it all together, chapter 18 | 24 pages, influencing policy and practice, chapter 19 | 18 pages, developing a research proposal.
- Privacy Policy
- Terms & Conditions
- Cookie Policy
- Taylor & Francis Online
- Taylor & Francis Group
- Students/Researchers
- Librarians/Institutions
Connect with us
Registered in England & Wales No. 3099067 5 Howick Place | London | SW1P 1WG © 2024 Informa UK Limited
- Request new password
- Create a new account
Research Methods for Social Work: A Problem-Based Approach
Student resources, welcome to the sage edge site for research methods for social work , 1e.
Research Methods for Social Work: A Problem-Based Approach is a comprehensive introduction to methods instruction that engages students innovatively and interactively. Using a case study and problem-based learning (PBL) approach, authors Antoinette Y. Farmer and G. Lawrence Farmer utilize case examples to achieve a level of application that builds readers’ confidence in methodology and reinforces their understanding of research across all levels of social work practice. These real-case examples, along with critical thinking questions, research tips, and step-by-step problem-solving methods, will improve student mastery and help them see why research is relevant. With the guidance of this new and noteworthy textbook, readers will transform into both knowledgeable consumers of research and skilled practitioners who can effectively address the needs of their clients through research.
This site features an array of free resources you can access anytime, anywhere.
Acknowledgments
We gratefully acknowledge Antoinette Y. Farmer and G. Lawrence Farmer for writing an excellent text. Special thanks are also due to Kryss Shane for developing the resources on this site.
For instructors
Access resources that are only available to Faculty and Administrative Staff.
Want to explore the book further?
Order Review Copy
- USC Libraries
- Research Guides
- SOWK 546: The Science of Social Work
- Research Designs and Methods
SOWK 546: The Science of Social Work: Research Designs and Methods
- Finding Scholarly Articles
- Developing a Search Strategy
- Evaluating Research Effectively
- Appraising Research
- Evidence-based Practice Resources
- Understanding Journal Impact Factors
- Policy and Legislation Resources
- Demographics, Data & Statistics for Social Work
- Tests & Measurements
- Background on Theories/Reference Sources
- APA 7th Edition
Research Methods Map
Explore the methods map below from SAGE Research Methods online to learn more about various research methods and find definitions of research terms. Click on the image of the map to interact with the map online.

- Research Design and Design Notation Guide
Resources for Research Methods
Use the resources below to get more background and information on various research designs and methods.
Independent and Dependent Variables
The following information and examples are from the Encyclopedia of Research Design cited and linked above:
Independent Variables and Dependent Variables
In research design, independent variables are those that a researcher can manipulate, whereas dependent variables are the responses to the effects of independent variables (Salkind, 2010).
Independent variables are predetermined by researchers before an experiment is started. They are carefully controlled in controlled experiments or selected in observational studies (i.e., they are manipulated by the researcher according to the purpose of a study).
The dependent variable is the effect to be observed and is the primary interest of the study (Salkind, 2010).
Consider a study on the relationship between physical inactivity and obesity in young children: The parameter(s) that measures physical inactivity, such as the hours spent on watching television and playing video games, and the means of transportation to and from daycares/schools is the independent variable. These are chosen by the researcher based on his or her preliminary research or on other reports in literature on the same subject prior to the study. The parameter(s) that measure obesity, such as the body mass index, is (are) the dependent variable (Salkind, 2010)
*Salkind, N. J. (2010). Encyclopedia of research design. Thousand Oaks, CA: SAGE Publications, Inc. doi: 10.4135/9781412961288
Internal and External Validity
Types of validity , internal validity .
- refers to the accuracy of statements made about the causal relationship between two variables, namely, the manipulated (treatment or independent) variable and the measured variable (dependent)
- internal validity claims are based on the procedures and operations used to conduct a research study, including the choice of design and measurement of variables.
*From Salkind, N. J. (2010). Encyclopedia of research design. Thousand Oaks, CA: SAGE Publications, Inc. doi: 10.4135/9781412961288
External Validity
- refers to the degree to which the relations among variables observed in one sample of observations in one population will hold for other samples of observations within the same population or in other populations. i.e. how general are your results?
*From Frey, B. (2018). The SAGE encyclopedia of educational research, measurement, and evaluation (Vols. 1-4). Thousand Oaks,, CA: SAGE Publications, Inc. doi: 10.4135/9781506326139
Quick guide available from USC School of Social Work: Threats to Internal Validity quick guide
- << Previous: Developing a Search Strategy
- Next: Evaluating Research Effectively >>
- Last Updated: Jul 29, 2024 2:13 PM
- URL: https://libguides.usc.edu/sowk546

Social Work 3500: Methods of Social Work Research
What is empirical research, sections in empirical research.
- What to Look For
- Is this an Empirical article?
- Finding Empirical Articles
- AYSPS Online Students This link opens in a new window
- Library Services
- Citing Your Sources This link opens in a new window
- Contact Me / Online Drop-in Hours
Empirical Research is defined as research based on observed and measured phenomena. It is research that derives knowledge from actual experience rather than from theory or belief.
Requests for "Empirical" articles are usually from instructors in Education or Psychology; most other disciplines will ask for Scholarly, Peer Reviewed or Primary literature.
See if the article mentions a study, an observation, an analysis or a number of participants or subjects. Was data collected, a survey or questionnaire administered, an assessment or measurement used, an interview conducted? All of these terms indicate possible methodologies used in empirical research.
Empirical articles often contain these sections:
- Introduction
- Literature review
- Methodology
The sections may be combined, and may have different headings or no headings at all; however, the information that would fall within these sections should be present in an empirical article.
Abstract: A report of an empirical study includes an abstract that provides a very brief summary of the research.
Introduction: The introduction sets the research in a context, which provides a review of related research and develops the hypotheses for the research.
Method: The method section is a description of how the research was conducted, including who the participants were, the design of the study, what the participants did, and what measures were used.
Results: The results section describes the outcomes of the measures of the study.
Discussion : The discussion section contains the interpretations and implications of the study.
General Discussion: There may be more than one study in the report; in this case, there are usually separate Methods and Results sections for each study followed by a general discussion that ties all the research together.
References: A references section contains information about the articles and books cited in the report.
Length of Article: Empirical research articles are usually substantial (more than 1 or 2 pages) and include a bibliography or cited references section (usually at the end of the article).
Type of Publication: Empirical research articles are published in scholarly or academic journals . These publications are sometimes referred to as “peer-reviewed,” “academic” or “refereed” publications. Examples of such publications include: Social Work Research, Mental Health Practice, and Journal of Substance Abuse.
- << Previous: Welcome
- Next: What to Look For >>
- Last Updated: May 9, 2024 10:26 AM
- URL: https://research.library.gsu.edu/SW3500

Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Part 3: Using quantitative methods
13. Experimental design
Chapter outline.
- What is an experiment and when should you use one? (8 minute read)
- True experimental designs (7 minute read)
- Quasi-experimental designs (8 minute read)
- Non-experimental designs (5 minute read)
- Critical, ethical, and critical considerations (5 minute read)
Content warning : examples in this chapter contain references to non-consensual research in Western history, including experiments conducted during the Holocaust and on African Americans (section 13.6).
13.1 What is an experiment and when should you use one?
Learning objectives.
Learners will be able to…
- Identify the characteristics of a basic experiment
- Describe causality in experimental design
- Discuss the relationship between dependent and independent variables in experiments
- Explain the links between experiments and generalizability of results
- Describe advantages and disadvantages of experimental designs
The basics of experiments
The first experiment I can remember using was for my fourth grade science fair. I wondered if latex- or oil-based paint would hold up to sunlight better. So, I went to the hardware store and got a few small cans of paint and two sets of wooden paint sticks. I painted one with oil-based paint and the other with latex-based paint of different colors and put them in a sunny spot in the back yard. My hypothesis was that the oil-based paint would fade the most and that more fading would happen the longer I left the paint sticks out. (I know, it’s obvious, but I was only 10.)
I checked in on the paint sticks every few days for a month and wrote down my observations. The first part of my hypothesis ended up being wrong—it was actually the latex-based paint that faded the most. But the second part was right, and the paint faded more and more over time. This is a simple example, of course—experiments get a heck of a lot more complex than this when we’re talking about real research.
Merriam-Webster defines an experiment as “an operation or procedure carried out under controlled conditions in order to discover an unknown effect or law, to test or establish a hypothesis, or to illustrate a known law.” Each of these three components of the definition will come in handy as we go through the different types of experimental design in this chapter. Most of us probably think of the physical sciences when we think of experiments, and for good reason—these experiments can be pretty flashy! But social science and psychological research follow the same scientific methods, as we’ve discussed in this book.
As the video discusses, experiments can be used in social sciences just like they can in physical sciences. It makes sense to use an experiment when you want to determine the cause of a phenomenon with as much accuracy as possible. Some types of experimental designs do this more precisely than others, as we’ll see throughout the chapter. If you’ll remember back to Chapter 11 and the discussion of validity, experiments are the best way to ensure internal validity, or the extent to which a change in your independent variable causes a change in your dependent variable.
Experimental designs for research projects are most appropriate when trying to uncover or test a hypothesis about the cause of a phenomenon, so they are best for explanatory research questions. As we’ll learn throughout this chapter, different circumstances are appropriate for different types of experimental designs. Each type of experimental design has advantages and disadvantages, and some are better at controlling the effect of extraneous variables —those variables and characteristics that have an effect on your dependent variable, but aren’t the primary variable whose influence you’re interested in testing. For example, in a study that tries to determine whether aspirin lowers a person’s risk of a fatal heart attack, a person’s race would likely be an extraneous variable because you primarily want to know the effect of aspirin.
In practice, many types of experimental designs can be logistically challenging and resource-intensive. As practitioners, the likelihood that we will be involved in some of the types of experimental designs discussed in this chapter is fairly low. However, it’s important to learn about these methods, even if we might not ever use them, so that we can be thoughtful consumers of research that uses experimental designs.
While we might not use all of these types of experimental designs, many of us will engage in evidence-based practice during our time as social workers. A lot of research developing evidence-based practice, which has a strong emphasis on generalizability, will use experimental designs. You’ve undoubtedly seen one or two in your literature search so far.
The logic of experimental design
How do we know that one phenomenon causes another? The complexity of the social world in which we practice and conduct research means that causes of social problems are rarely cut and dry. Uncovering explanations for social problems is key to helping clients address them, and experimental research designs are one road to finding answers.
As you read about in Chapter 8 (and as we’ll discuss again in Chapter 15 ), just because two phenomena are related in some way doesn’t mean that one causes the other. Ice cream sales increase in the summer, and so does the rate of violent crime; does that mean that eating ice cream is going to make me murder someone? Obviously not, because ice cream is great. The reality of that relationship is far more complex—it could be that hot weather makes people more irritable and, at times, violent, while also making people want ice cream. More likely, though, there are other social factors not accounted for in the way we just described this relationship.
Experimental designs can help clear up at least some of this fog by allowing researchers to isolate the effect of interventions on dependent variables by controlling extraneous variables . In true experimental design (discussed in the next section) and some quasi-experimental designs, researchers accomplish this w ith the control group and the experimental group . (The experimental group is sometimes called the “treatment group,” but we will call it the experimental group in this chapter.) The control group does not receive the intervention you are testing (they may receive no intervention or what is known as “treatment as usual”), while the experimental group does. (You will hopefully remember our earlier discussion of control variables in Chapter 8 —conceptually, the use of the word “control” here is the same.)

In a well-designed experiment, your control group should look almost identical to your experimental group in terms of demographics and other relevant factors. What if we want to know the effect of CBT on social anxiety, but we have learned in prior research that men tend to have a more difficult time overcoming social anxiety? We would want our control and experimental groups to have a similar gender mix because it would limit the effect of gender on our results, since ostensibly, both groups’ results would be affected by gender in the same way. If your control group has 5 women, 6 men, and 4 non-binary people, then your experimental group should be made up of roughly the same gender balance to help control for the influence of gender on the outcome of your intervention. (In reality, the groups should be similar along other dimensions, as well, and your group will likely be much larger.) The researcher will use the same outcome measures for both groups and compare them, and assuming the experiment was designed correctly, get a pretty good answer about whether the intervention had an effect on social anxiety.
You will also hear people talk about comparison groups , which are similar to control groups. The primary difference between the two is that a control group is populated using random assignment, but a comparison group is not. Random assignment entails using a random process to decide which participants are put into the control or experimental group (which participants receive an intervention and which do not). By randomly assigning participants to a group, you can reduce the effect of extraneous variables on your research because there won’t be a systematic difference between the groups.
Do not confuse random assignment with random sampling. Random sampling is a method for selecting a sample from a population, and is rarely used in psychological research. Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other related fields. Random sampling also helps a great deal with generalizability , whereas random assignment increases internal validity .
We have already learned about internal validity in Chapter 11 . The use of an experimental design will bolster internal validity since it works to isolate causal relationships. As we will see in the coming sections, some types of experimental design do this more effectively than others. It’s also worth considering that true experiments, which most effectively show causality , are often difficult and expensive to implement. Although other experimental designs aren’t perfect, they still produce useful, valid evidence and may be more feasible to carry out.
Key Takeaways
- Experimental designs are useful for establishing causality, but some types of experimental design do this better than others.
- Experiments help researchers isolate the effect of the independent variable on the dependent variable by controlling for the effect of extraneous variables .
- Experiments use a control/comparison group and an experimental group to test the effects of interventions. These groups should be as similar to each other as possible in terms of demographics and other relevant factors.
- True experiments have control groups with randomly assigned participants, while other types of experiments have comparison groups to which participants are not randomly assigned.
- Think about the research project you’ve been designing so far. How might you use a basic experiment to answer your question? If your question isn’t explanatory, try to formulate a new explanatory question and consider the usefulness of an experiment.
- Why is establishing a simple relationship between two variables not indicative of one causing the other?
13.2 True experimental design
- Describe a true experimental design in social work research
- Understand the different types of true experimental designs
- Determine what kinds of research questions true experimental designs are suited for
- Discuss advantages and disadvantages of true experimental designs
True experimental design , often considered to be the “gold standard” in research designs, is thought of as one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity and its ability to establish ( causality ) through treatment manipulation, while controlling for the effects of extraneous variable. Sometimes the treatment level is no treatment, while other times it is simply a different treatment than that which we are trying to evaluate. For example, we might have a control group that is made up of people who will not receive any treatment for a particular condition. Or, a control group could consist of people who consent to treatment with DBT when we are testing the effectiveness of CBT.
As we discussed in the previous section, a true experiment has a control group with participants randomly assigned , and an experimental group . This is the most basic element of a true experiment. The next decision a researcher must make is when they need to gather data during their experiment. Do they take a baseline measurement and then a measurement after treatment, or just a measurement after treatment, or do they handle measurement another way? Below, we’ll discuss the three main types of true experimental designs. There are sub-types of each of these designs, but here, we just want to get you started with some of the basics.
Using a true experiment in social work research is often pretty difficult, since as I mentioned earlier, true experiments can be quite resource intensive. True experiments work best with relatively large sample sizes, and random assignment, a key criterion for a true experimental design, is hard (and unethical) to execute in practice when you have people in dire need of an intervention. Nonetheless, some of the strongest evidence bases are built on true experiments.
For the purposes of this section, let’s bring back the example of CBT for the treatment of social anxiety. We have a group of 500 individuals who have agreed to participate in our study, and we have randomly assigned them to the control and experimental groups. The folks in the experimental group will receive CBT, while the folks in the control group will receive more unstructured, basic talk therapy. These designs, as we talked about above, are best suited for explanatory research questions.
Before we get started, take a look at the table below. When explaining experimental research designs, we often use diagrams with abbreviations to visually represent the experiment. Table 13.1 starts us off by laying out what each of the abbreviations mean.
| R | Randomly assigned group (control/comparison or experimental) |
| O | Observation/measurement taken of dependent variable |
| X | Intervention or treatment |
| X | Experimental or new intervention |
| X | Typical intervention/treatment as usual |
| A, B, C, etc. | Denotes different groups (control/comparison and experimental) |
Pretest and post-test control group design
In pretest and post-test control group design , participants are given a pretest of some kind to measure their baseline state before their participation in an intervention. In our social anxiety experiment, we would have participants in both the experimental and control groups complete some measure of social anxiety—most likely an established scale and/or a structured interview—before they start their treatment. As part of the experiment, we would have a defined time period during which the treatment would take place (let’s say 12 weeks, just for illustration). At the end of 12 weeks, we would give both groups the same measure as a post-test .

In the diagram, RA (random assignment group A) is the experimental group and RB is the control group. O 1 denotes the pre-test, X e denotes the experimental intervention, and O 2 denotes the post-test. Let’s look at this diagram another way, using the example of CBT for social anxiety that we’ve been talking about.

In a situation where the control group received treatment as usual instead of no intervention, the diagram would look this way, with X i denoting treatment as usual (Figure 13.3).
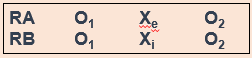
Hopefully, these diagrams provide you a visualization of how this type of experiment establishes time order , a key component of a causal relationship. Did the change occur after the intervention? Assuming there is a change in the scores between the pretest and post-test, we would be able to say that yes, the change did occur after the intervention. Causality can’t exist if the change happened before the intervention—this would mean that something else led to the change, not our intervention.
Post-test only control group design
Post-test only control group design involves only giving participants a post-test, just like it sounds (Figure 13.4).
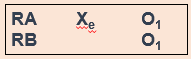
But why would you use this design instead of using a pretest/post-test design? One reason could be the testing effect that can happen when research participants take a pretest. In research, the testing effect refers to “measurement error related to how a test is given; the conditions of the testing, including environmental conditions; and acclimation to the test itself” (Engel & Schutt, 2017, p. 444) [1] (When we say “measurement error,” all we mean is the accuracy of the way we measure the dependent variable.) Figure 13.4 is a visualization of this type of experiment. The testing effect isn’t always bad in practice—our initial assessments might help clients identify or put into words feelings or experiences they are having when they haven’t been able to do that before. In research, however, we might want to control its effects to isolate a cleaner causal relationship between intervention and outcome.
Going back to our CBT for social anxiety example, we might be concerned that participants would learn about social anxiety symptoms by virtue of taking a pretest. They might then identify that they have those symptoms on the post-test, even though they are not new symptoms for them. That could make our intervention look less effective than it actually is.
However, without a baseline measurement establishing causality can be more difficult. If we don’t know someone’s state of mind before our intervention, how do we know our intervention did anything at all? Establishing time order is thus a little more difficult. You must balance this consideration with the benefits of this type of design.
Solomon four group design
One way we can possibly measure how much the testing effect might change the results of the experiment is with the Solomon four group design. Basically, as part of this experiment, you have two control groups and two experimental groups. The first pair of groups receives both a pretest and a post-test. The other pair of groups receives only a post-test (Figure 13.5). This design helps address the problem of establishing time order in post-test only control group designs.
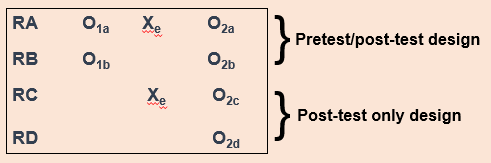
For our CBT project, we would randomly assign people to four different groups instead of just two. Groups A and B would take our pretest measures and our post-test measures, and groups C and D would take only our post-test measures. We could then compare the results among these groups and see if they’re significantly different between the folks in A and B, and C and D. If they are, we may have identified some kind of testing effect, which enables us to put our results into full context. We don’t want to draw a strong causal conclusion about our intervention when we have major concerns about testing effects without trying to determine the extent of those effects.
Solomon four group designs are less common in social work research, primarily because of the logistics and resource needs involved. Nonetheless, this is an important experimental design to consider when we want to address major concerns about testing effects.
- True experimental design is best suited for explanatory research questions.
- True experiments require random assignment of participants to control and experimental groups.
- Pretest/post-test research design involves two points of measurement—one pre-intervention and one post-intervention.
- Post-test only research design involves only one point of measurement—post-intervention. It is a useful design to minimize the effect of testing effects on our results.
- Solomon four group research design involves both of the above types of designs, using 2 pairs of control and experimental groups. One group receives both a pretest and a post-test, while the other receives only a post-test. This can help uncover the influence of testing effects.
- Think about a true experiment you might conduct for your research project. Which design would be best for your research, and why?
- What challenges or limitations might make it unrealistic (or at least very complicated!) for you to carry your true experimental design in the real-world as a student researcher?
- What hypothesis(es) would you test using this true experiment?
13.4 Quasi-experimental designs
- Describe a quasi-experimental design in social work research
- Understand the different types of quasi-experimental designs
- Determine what kinds of research questions quasi-experimental designs are suited for
- Discuss advantages and disadvantages of quasi-experimental designs
Quasi-experimental designs are a lot more common in social work research than true experimental designs. Although quasi-experiments don’t do as good a job of giving us robust proof of causality , they still allow us to establish time order , which is a key element of causality. The prefix quasi means “resembling,” so quasi-experimental research is research that resembles experimental research, but is not true experimental research. Nonetheless, given proper research design, quasi-experiments can still provide extremely rigorous and useful results.
There are a few key differences between true experimental and quasi-experimental research. The primary difference between quasi-experimental research and true experimental research is that quasi-experimental research does not involve random assignment to control and experimental groups. Instead, we talk about comparison groups in quasi-experimental research instead. As a result, these types of experiments don’t control the effect of extraneous variables as well as a true experiment.
Quasi-experiments are most likely to be conducted in field settings in which random assignment is difficult or impossible. They are often conducted to evaluate the effectiveness of a treatment—perhaps a type of psychotherapy or an educational intervention. We’re able to eliminate some threats to internal validity, but we can’t do this as effectively as we can with a true experiment. Realistically, our CBT-social anxiety project is likely to be a quasi experiment, based on the resources and participant pool we’re likely to have available.
It’s important to note that not all quasi-experimental designs have a comparison group. There are many different kinds of quasi-experiments, but we will discuss the three main types below: nonequivalent comparison group designs, time series designs, and ex post facto comparison group designs.
Nonequivalent comparison group design
You will notice that this type of design looks extremely similar to the pretest/post-test design that we discussed in section 13.3. But instead of random assignment to control and experimental groups, researchers use other methods to construct their comparison and experimental groups. A diagram of this design will also look very similar to pretest/post-test design, but you’ll notice we’ve removed the “R” from our groups, since they are not randomly assigned (Figure 13.6).

Researchers using this design select a comparison group that’s as close as possible based on relevant factors to their experimental group. Engel and Schutt (2017) [2] identify two different selection methods:
- Individual matching : Researchers take the time to match individual cases in the experimental group to similar cases in the comparison group. It can be difficult, however, to match participants on all the variables you want to control for.
- Aggregate matching : Instead of trying to match individual participants to each other, researchers try to match the population profile of the comparison and experimental groups. For example, researchers would try to match the groups on average age, gender balance, or median income. This is a less resource-intensive matching method, but researchers have to ensure that participants aren’t choosing which group (comparison or experimental) they are a part of.
As we’ve already talked about, this kind of design provides weaker evidence that the intervention itself leads to a change in outcome. Nonetheless, we are still able to establish time order using this method, and can thereby show an association between the intervention and the outcome. Like true experimental designs, this type of quasi-experimental design is useful for explanatory research questions.
What might this look like in a practice setting? Let’s say you’re working at an agency that provides CBT and other types of interventions, and you have identified a group of clients who are seeking help for social anxiety, as in our earlier example. Once you’ve obtained consent from your clients, you can create a comparison group using one of the matching methods we just discussed. If the group is small, you might match using individual matching, but if it’s larger, you’ll probably sort people by demographics to try to get similar population profiles. (You can do aggregate matching more easily when your agency has some kind of electronic records or database, but it’s still possible to do manually.)
Time series design
Another type of quasi-experimental design is a time series design. Unlike other types of experimental design, time series designs do not have a comparison group. A time series is a set of measurements taken at intervals over a period of time (Figure 13.7). Proper time series design should include at least three pre- and post-intervention measurement points. While there are a few types of time series designs, we’re going to focus on the most common: interrupted time series design.

But why use this method? Here’s an example. Let’s think about elementary student behavior throughout the school year. As anyone with children or who is a teacher knows, kids get very excited and animated around holidays, days off, or even just on a Friday afternoon. This fact might mean that around those times of year, there are more reports of disruptive behavior in classrooms. What if we took our one and only measurement in mid-December? It’s possible we’d see a higher-than-average rate of disruptive behavior reports, which could bias our results if our next measurement is around a time of year students are in a different, less excitable frame of mind. When we take multiple measurements throughout the first half of the school year, we can establish a more accurate baseline for the rate of these reports by looking at the trend over time.
We may want to test the effect of extended recess times in elementary school on reports of disruptive behavior in classrooms. When students come back after the winter break, the school extends recess by 10 minutes each day (the intervention), and the researchers start tracking the monthly reports of disruptive behavior again. These reports could be subject to the same fluctuations as the pre-intervention reports, and so we once again take multiple measurements over time to try to control for those fluctuations.
This method improves the extent to which we can establish causality because we are accounting for a major extraneous variable in the equation—the passage of time. On its own, it does not allow us to account for other extraneous variables, but it does establish time order and association between the intervention and the trend in reports of disruptive behavior. Finding a stable condition before the treatment that changes after the treatment is evidence for causality between treatment and outcome.
Ex post facto comparison group design
Ex post facto (Latin for “after the fact”) designs are extremely similar to nonequivalent comparison group designs. There are still comparison and experimental groups, pretest and post-test measurements, and an intervention. But in ex post facto designs, participants are assigned to the comparison and experimental groups once the intervention has already happened. This type of design often occurs when interventions are already up and running at an agency and the agency wants to assess effectiveness based on people who have already completed treatment.
In most clinical agency environments, social workers conduct both initial and exit assessments, so there are usually some kind of pretest and post-test measures available. We also typically collect demographic information about our clients, which could allow us to try to use some kind of matching to construct comparison and experimental groups.
In terms of internal validity and establishing causality, ex post facto designs are a bit of a mixed bag. The ability to establish causality depends partially on the ability to construct comparison and experimental groups that are demographically similar so we can control for these extraneous variables .
Quasi-experimental designs are common in social work intervention research because, when designed correctly, they balance the intense resource needs of true experiments with the realities of research in practice. They still offer researchers tools to gather robust evidence about whether interventions are having positive effects for clients.
- Quasi-experimental designs are similar to true experiments, but do not require random assignment to experimental and control groups.
- In quasi-experimental projects, the group not receiving the treatment is called the comparison group, not the control group.
- Nonequivalent comparison group design is nearly identical to pretest/post-test experimental design, but participants are not randomly assigned to the experimental and control groups. As a result, this design provides slightly less robust evidence for causality.
- Nonequivalent groups can be constructed by individual matching or aggregate matching .
- Time series design does not have a control or experimental group, and instead compares the condition of participants before and after the intervention by measuring relevant factors at multiple points in time. This allows researchers to mitigate the error introduced by the passage of time.
- Ex post facto comparison group designs are also similar to true experiments, but experimental and comparison groups are constructed after the intervention is over. This makes it more difficult to control for the effect of extraneous variables, but still provides useful evidence for causality because it maintains the time order of the experiment.
- Think back to the experiment you considered for your research project in Section 13.3. Now that you know more about quasi-experimental designs, do you still think it’s a true experiment? Why or why not?
- What should you consider when deciding whether an experimental or quasi-experimental design would be more feasible or fit your research question better?
13.5 Non-experimental designs
- Describe non-experimental designs in social work research
- Discuss how non-experimental research differs from true and quasi-experimental research
- Demonstrate an understanding the different types of non-experimental designs
- Determine what kinds of research questions non-experimental designs are suited for
- Discuss advantages and disadvantages of non-experimental designs
The previous sections have laid out the basics of some rigorous approaches to establish that an intervention is responsible for changes we observe in research participants. This type of evidence is extremely important to build an evidence base for social work interventions, but it’s not the only type of evidence to consider. We will discuss qualitative methods, which provide us with rich, contextual information, in Part 4 of this text. The designs we’ll talk about in this section are sometimes used in qualitative research but in keeping with our discussion of experimental design so far, we’re going to stay in the quantitative research realm for now. Non-experimental is also often a stepping stone for more rigorous experimental design in the future, as it can help test the feasibility of your research.
In general, non-experimental designs do not strongly support causality and don’t address threats to internal validity. However, that’s not really what they’re intended for. Non-experimental designs are useful for a few different types of research, including explanatory questions in program evaluation. Certain types of non-experimental design are also helpful for researchers when they are trying to develop a new assessment or scale. Other times, researchers or agency staff did not get a chance to gather any assessment information before an intervention began, so a pretest/post-test design is not possible.

A significant benefit of these types of designs is that they’re pretty easy to execute in a practice or agency setting. They don’t require a comparison or control group, and as Engel and Schutt (2017) [3] point out, they “flow from a typical practice model of assessment, intervention, and evaluating the impact of the intervention” (p. 177). Thus, these designs are fairly intuitive for social workers, even when they aren’t expert researchers. Below, we will go into some detail about the different types of non-experimental design.
One group pretest/post-test design
Also known as a before-after one-group design, this type of research design does not have a comparison group and everyone who participates in the research receives the intervention (Figure 13.8). This is a common type of design in program evaluation in the practice world. Controlling for extraneous variables is difficult or impossible in this design, but given that it is still possible to establish some measure of time order, it does provide weak support for causality.

Imagine, for example, a researcher who is interested in the effectiveness of an anti-drug education program on elementary school students’ attitudes toward illegal drugs. The researcher could assess students’ attitudes about illegal drugs (O 1 ), implement the anti-drug program (X), and then immediately after the program ends, the researcher could once again measure students’ attitudes toward illegal drugs (O 2 ). You can see how this would be relatively simple to do in practice, and have probably been involved in this type of research design yourself, even if informally. But hopefully, you can also see that this design would not provide us with much evidence for causality because we have no way of controlling for the effect of extraneous variables. A lot of things could have affected any change in students’ attitudes—maybe girls already had different attitudes about illegal drugs than children of other genders, and when we look at the class’s results as a whole, we couldn’t account for that influence using this design.
All of that doesn’t mean these results aren’t useful, however. If we find that children’s attitudes didn’t change at all after the drug education program, then we need to think seriously about how to make it more effective or whether we should be using it at all. (This immediate, practical application of our results highlights a key difference between program evaluation and research, which we will discuss in Chapter 23 .)
After-only design
As the name suggests, this type of non-experimental design involves measurement only after an intervention. There is no comparison or control group, and everyone receives the intervention. I have seen this design repeatedly in my time as a program evaluation consultant for nonprofit organizations, because often these organizations realize too late that they would like to or need to have some sort of measure of what effect their programs are having.
Because there is no pretest and no comparison group, this design is not useful for supporting causality since we can’t establish the time order and we can’t control for extraneous variables. However, that doesn’t mean it’s not useful at all! Sometimes, agencies need to gather information about how their programs are functioning. A classic example of this design is satisfaction surveys—realistically, these can only be administered after a program or intervention. Questions regarding satisfaction, ease of use or engagement, or other questions that don’t involve comparisons are best suited for this type of design.
Static-group design
A final type of non-experimental research is the static-group design. In this type of research, there are both comparison and experimental groups, which are not randomly assigned. There is no pretest, only a post-test, and the comparison group has to be constructed by the researcher. Sometimes, researchers will use matching techniques to construct the groups, but often, the groups are constructed by convenience of who is being served at the agency.
Non-experimental research designs are easy to execute in practice, but we must be cautious about drawing causal conclusions from the results. A positive result may still suggest that we should continue using a particular intervention (and no result or a negative result should make us reconsider whether we should use that intervention at all). You have likely seen non-experimental research in your daily life or at your agency, and knowing the basics of how to structure such a project will help you ensure you are providing clients with the best care possible.
- Non-experimental designs are useful for describing phenomena, but cannot demonstrate causality.
- After-only designs are often used in agency and practice settings because practitioners are often not able to set up pre-test/post-test designs.
- Non-experimental designs are useful for explanatory questions in program evaluation and are helpful for researchers when they are trying to develop a new assessment or scale.
- Non-experimental designs are well-suited to qualitative methods.
- If you were to use a non-experimental design for your research project, which would you choose? Why?
- Have you conducted non-experimental research in your practice or professional life? Which type of non-experimental design was it?
13.6 Critical, ethical, and cultural considerations
- Describe critiques of experimental design
- Identify ethical issues in the design and execution of experiments
- Identify cultural considerations in experimental design
As I said at the outset, experiments, and especially true experiments, have long been seen as the gold standard to gather scientific evidence. When it comes to research in the biomedical field and other physical sciences, true experiments are subject to far less nuance than experiments in the social world. This doesn’t mean they are easier—just subject to different forces. However, as a society, we have placed the most value on quantitative evidence obtained through empirical observation and especially experimentation.
Major critiques of experimental designs tend to focus on true experiments, especially randomized controlled trials (RCTs), but many of these critiques can be applied to quasi-experimental designs, too. Some researchers, even in the biomedical sciences, question the view that RCTs are inherently superior to other types of quantitative research designs. RCTs are far less flexible and have much more stringent requirements than other types of research. One seemingly small issue, like incorrect information about a research participant, can derail an entire RCT. RCTs also cost a great deal of money to implement and don’t reflect “real world” conditions. The cost of true experimental research or RCTs also means that some communities are unlikely to ever have access to these research methods. It is then easy for people to dismiss their research findings because their methods are seen as “not rigorous.”
Obviously, controlling outside influences is important for researchers to draw strong conclusions, but what if those outside influences are actually important for how an intervention works? Are we missing really important information by focusing solely on control in our research? Is a treatment going to work the same for white women as it does for indigenous women? With the myriad effects of our societal structures, you should be very careful ever assuming this will be the case. This doesn’t mean that cultural differences will negate the effect of an intervention; instead, it means that you should remember to practice cultural humility implementing all interventions, even when we “know” they work.
How we build evidence through experimental research reveals a lot about our values and biases, and historically, much experimental research has been conducted on white people, and especially white men. [4] This makes sense when we consider the extent to which the sciences and academia have historically been dominated by white patriarchy. This is especially important for marginalized groups that have long been ignored in research literature, meaning they have also been ignored in the development of interventions and treatments that are accepted as “effective.” There are examples of marginalized groups being experimented on without their consent, like the Tuskegee Experiment or Nazi experiments on Jewish people during World War II. We cannot ignore the collective consciousness situations like this can create about experimental research for marginalized groups.
None of this is to say that experimental research is inherently bad or that you shouldn’t use it. Quite the opposite—use it when you can, because there are a lot of benefits, as we learned throughout this chapter. As a social work researcher, you are uniquely positioned to conduct experimental research while applying social work values and ethics to the process and be a leader for others to conduct research in the same framework. It can conflict with our professional ethics, especially respect for persons and beneficence, if we do not engage in experimental research with our eyes wide open. We also have the benefit of a great deal of practice knowledge that researchers in other fields have not had the opportunity to get. As with all your research, always be sure you are fully exploring the limitations of the research.
- While true experimental research gathers strong evidence, it can also be inflexible, expensive, and overly simplistic in terms of important social forces that affect the resources.
- Marginalized communities’ past experiences with experimental research can affect how they respond to research participation.
- Social work researchers should use both their values and ethics, and their practice experiences, to inform research and push other researchers to do the same.
- Think back to the true experiment you sketched out in the exercises for Section 13.3. Are there cultural or historical considerations you hadn’t thought of with your participant group? What are they? Does this change the type of experiment you would want to do?
- How can you as a social work researcher encourage researchers in other fields to consider social work ethics and values in their experimental research?
Media Attributions
- Being kinder to yourself © Evgenia Makarova is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- Original by author is licensed under a CC BY-NC-SA (Attribution NonCommercial ShareAlike) license
- Original by author. is licensed under a CC BY-NC-SA (Attribution NonCommercial ShareAlike) license
- Orginal by author. is licensed under a CC BY-NC-SA (Attribution NonCommercial ShareAlike) license
- therapist © Zackary Drucker is licensed under a CC BY-NC-ND (Attribution NonCommercial NoDerivatives) license
- nonexper-pretest-posttest is licensed under a CC BY-NC-SA (Attribution NonCommercial ShareAlike) license
- Engel, R. & Schutt, R. (2016). The practice of research in social work. Thousand Oaks, CA: SAGE Publications, Inc. ↵
- Sullivan, G. M. (2011). Getting off the “gold standard”: Randomized controlled trials and education research. Journal of Graduate Medical Education , 3 (3), 285-289. ↵
an operation or procedure carried out under controlled conditions in order to discover an unknown effect or law, to test or establish a hypothesis, or to illustrate a known law.
explains why particular phenomena work in the way that they do; answers “why” questions
variables and characteristics that have an effect on your outcome, but aren't the primary variable whose influence you're interested in testing.
the group of participants in our study who do not receive the intervention we are researching in experiments with random assignment
in experimental design, the group of participants in our study who do receive the intervention we are researching
the group of participants in our study who do not receive the intervention we are researching in experiments without random assignment
using a random process to decide which participants are tested in which conditions
The ability to apply research findings beyond the study sample to some broader population,
Ability to say that one variable "causes" something to happen to another variable. Very important to assess when thinking about studies that examine causation such as experimental or quasi-experimental designs.
the idea that one event, behavior, or belief will result in the occurrence of another, subsequent event, behavior, or belief
An experimental design in which one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed
a type of experimental design in which participants are randomly assigned to control and experimental groups, one group receives an intervention, and both groups receive pre- and post-test assessments
A measure of a participant's condition before they receive an intervention or treatment.
A measure of a participant's condition after an intervention or, if they are part of the control/comparison group, at the end of an experiment.
A demonstration that a change occurred after an intervention. An important criterion for establishing causality.
an experimental design in which participants are randomly assigned to control and treatment groups, one group receives an intervention, and both groups receive only a post-test assessment
The measurement error related to how a test is given; the conditions of the testing, including environmental conditions; and acclimation to the test itself
a subtype of experimental design that is similar to a true experiment, but does not have randomly assigned control and treatment groups
In nonequivalent comparison group designs, the process by which researchers match individual cases in the experimental group to similar cases in the comparison group.
In nonequivalent comparison group designs, the process in which researchers match the population profile of the comparison and experimental groups.
a set of measurements taken at intervals over a period of time
Research that involves the use of data that represents human expression through words, pictures, movies, performance and other artifacts.
Graduate research methods in social work Copyright © 2021 by Matthew DeCarlo, Cory Cummings, Kate Agnelli is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
| --> Return to Home Page + – + – + – + – + – + – Return to Home Page 1200 Murchison Road Fayetteville, NC 28301 All Rights Reserved. The University of North Carolina. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Fayetteville State University | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||









IMAGES
COMMENTS
Social work researchers will send out a survey, receive responses, aggregate the results, analyze the data, and form conclusions based on trends. Surveys are one of the most common research methods social workers use — and for good reason. They tend to be relatively simple and are usually affordable.
Social work research means conducting an investigation in accordance with the scientific method. The aim of social work research is to build the social work knowledge base in order to solve practical problems in social work practice or social policy. Investigating phenomena in accordance with the scientific method requires maximal adherence to ...
Graduate Research Methods in Social Work by DeCarlo, et al., is a comprehensive and well-structured guide that serves as an invaluable resource for graduate students delving into the intricate world of social work research. The book is divided into five distinct parts, each carefully curated to provide a step-by-step approach to mastering ...
This textbook was created to provide an introduction to research methods for BSW and MSW students, with particular emphasis on research and practice relevant to students at the University of Texas at Arlington. It provides an introduction to social work students to help evaluate research for evidence-based practice and design social work research projects. It can be used with its companion, A ...
Practice research in social work is evolving and has been iteratively defined through a series of statements over the last 15 years (Epstein et al., 2015; Fook & Evans, 2011; Joubert et al., 2023; Julkunen et al., 2014; Sim et al., 2019).Most recently, the Melbourne Statement on Practice Research (Joubert et al., 2023) focused on practice meeting research, with an emphasis on 'the ...
In addition, Bruce Thyer is the editor of the journal Research in Social Work Practice and expressed interest in updating the book along with the other two candidates. In the field of social work, qualitative research is starting to gain more prominence as are mixed methods and various issues regarding race, ethnicity and gender.
Abstract. Mixed methods are a useful approach chosen by many social work researchers. This article showcases a quality framework using social work examples as practical guidance for social work researchers. Combining methodological literature with practical social work examples, elements of a high-quality approach to mixed methods are showcased ...
A three-part structure introduces the fundamentals of research methods, the different types of social work research, and the use of data analysis for evaluation of social work practice. Chapter-opening vignettes illustrate the value of chapter content to the practicing social worker.
"`Not so much a handbook, but an excellent source of reference' - British Journal of Social Work This volume is the definitive resource for anyone doing research in social work. It details both quantitative and qualitative methods and data collection, as well as suggesting the methods appropriate to particular types of studies.
Table of Contents. Chapter 1: Introduction to research. Chapter 2: Beginning a research project. Chapter 3: Reading and evaluating literature. Chapter 4: Conducting a literature review. Chapter 5: Ethics in social work research. Chapter 6: Linking methods with theory. Chapter 7: Design and causality. Chapter 8: Creating and refining a research ...
Title = Practice Research Methods in Social Work: Processes, Applications, and Implications for Social Service Organisations . 1* Bowen McBeath, 2 Michael J. Austin, 2 Sarah Carnochan, and 2 Emmeline Chuang. 1 School of Social Work, Portland State University, Portland, OR, U.S.A.
Widely considered the best text for the course, RESEARCH METHODS FOR SOCIAL WORK, Seventh Edition strikes an optimal balance of quantitative and qualitative research techniques--illustrating how the two methods complement one another. Allen Rubin and Earl R. Babbie's classic bestseller is acclaimed for its depth and breadth of coverage as well as the authors' clear and often humorous ...
Research on Social Work Practice (RSWP), peer-reviewed and published eight times per year, is a disciplinary journal devoted to the publication of empirical research concerning the assessment methods and outcomes of social work practice. Intervention programs covered include behavior analysis and therapy; psychotherapy or counseling with individuals; case management; and education.
Research for Social Workers has built a strong reputation as an accessible guide to the key research methods and approaches used in the discipline. Ideal for beginners, the book outlines the importance of social work research, its guiding principles and explains how to choose a topic area, develop research questions together with describing the key steps in the research process.
Welcome to the SAGE Edge site for Research Methods for Social Work, 1e!. Research Methods for Social Work: A Problem-Based Approach is a comprehensive introduction to methods instruction that engages students innovatively and interactively.Using a case study and problem-based learning (PBL) approach, authors Antoinette Y. Farmer and G. Lawrence Farmer utilize case examples to achieve a level ...
Another critical factor that distinguishes PR from other participatory research methods is the connection between social work practice and social service managers. Compared to action research and empowerment evaluation methodologies, PR is more explicitly organisational in understanding how managers, front line staff and service users make ...
Handbook of Social Work Research Methods Encyclopedia of Survey Research Methods Paul Lavrakas covers all major facets of survey research methodology, from selecting the sample design and the sampling frame, designing and pretesting the questionnaire, data collection, and data coding, to the thorny issues surrounding diminishing response rates ...
Type of Publication: Empirical research articles are published in scholarly or academic journals . These publications are sometimes referred to as "peer-reviewed," "academic" or "refereed" publications. Examples of such publications include: Social Work Research, Mental Health Practice, and Journal of Substance Abuse. <<
PDF | On Jan 1, 2009, A. Rubin and others published Research Methods for Social Work | Find, read and cite all the research you need on ResearchGate
Methods of Social Work Research I 19:910:505 Spring 2022 Catalog Course Description. k Research I19:910:505Spring 2022Instructor:Email:Catalog Course Description Introduction to scientific, analytic, approach to building knowledge and skills, including the role of concepts and theory, hypothesis formulation, operationalization, research design ...
Mixed methods research adds three important elements to social work research: voices of participants, comprehensive analyses of phenomena, and enhanced validity of findings. For these reasons, the teaching and use of mixed methods research remain integral to social work. Keywords: Mixed methods research, social work.
Using a true experiment in social work research is often pretty difficult, since as I mentioned earlier, true experiments can be quite resource intensive. True experiments work best with relatively large sample sizes, and random assignment, a key criterion for a true experimental design, is hard (and unethical) to execute in practice when you ...
Within this process, the following will be covered: the scientific method for building knowledge for social work practice, ethical standards for scientific inquiry, qualitative and quantitative research methodology, research designs for developing knowledge and systematically evaluating social work practice and human service programs, and the ...
Based on: Campbell AnneTaylor BrianMcGlade Anne, Research design in social work: Qualitative and quantitative methods. London: Sage Publications - Learning Matters, 2017; 160 pp. ISBN 9781446271247, £20.99 (pbk) ... Qualitative Methods in Social Work Research, 2nd edn. Thousand Oaks, CA: SAGE, 2008. 281 pp. ISBN 978 1412951920 (hbk ...
The complexity of social problems addressed by the social work profession makes mixed methods research an essential tool. This literature review examined common quantitative and qualitative techniques used by social work researchers and what mixed methods research may add to social work research. Surveys and in-depth interviews were the most common quantitative and qualitative data collection ...
Social support was a significant component of an individual's external resources in COR. Citation 11 Perceived social support refers to the subjective feeling and evaluation of the degree of external support from individuals. Citation 17 Many studies have confirmed the positive correlation between social support and LS in adult cancer patients.
Methods. The present study examines how the relationship between area level indicators of deprivation and child welfare interventions across NI has changed over time. Specifically, it extends the current evidence base to look at four stages of children's contact with child and family social work in NI during each of the years from 2010 to ...
Mixed-methods research can facilitate research that cannot be answered using a single method. Though there is controversy concerning what constitutes mixed-methods research, integrating quantitative and qualitative approaches is considered increasingly important, and extant literature has observed and demonstrated that the definition of mixed ...
Background Triage and clinical consultations increasingly occur remotely. We aimed to learn why safety incidents occur in remote encounters and how to prevent them. Setting and sample UK primary care. 95 safety incidents (complaints, settled indemnity claims and reports) involving remote interactions. Separately, 12 general practices followed 2021-2023. Methods Multimethod qualitative study ...
Higher education institutions, as organizations that transform society, have a responsibility to contribute to the construction of a sustainable and resilient world that is aware of the collateral effects of technological advances. This is the initial phase of a research that aims to determine whether subjects in the complementary training area have a significant effect on ethical, social ...