

Trial and Error
Trial and Error is a fundamental method of problem-solving, which involves attempting different solutions until the correct one is found. As a strategy frequently used in multiple fields, including psychology, science, and computer programming, its significance is profound and multifaceted.
Understanding the term
To fully appreciate the trial and error method’s value, let’s delve into its characteristics, process, and theoretical underpinnings.
Characteristics of the Trial and Error Method
The trial and error method is defined by two key elements: making attempts (trials) and learning from failures (errors). The process continues until a solution is found.
The Trial and Error Process
The process of trial and error consists of generating possible solutions, applying them, assessing their effectiveness, and revising the approach based on the results.
Theoretical Background
Trial and error has roots in behavioral psychology, where it’s often associated with Edward Thorndike’s Law of Effect. This law suggests that responses followed by satisfaction will be repeated, while those followed by discomfort will be discontinued.
Trial and Error in Everyday Life
The application of the trial and error method is ubiquitous, extending from our daily activities to complex scientific research.
Learning New Skills
When we learn to ride a bicycle, cook a new dish, or play a musical instrument, we use trial and error to master the skills.
Technological Advancements
In the tech industry, trial and error play a crucial role in software development and debugging, hardware design, and algorithm optimization.
Advantages and Disadvantages
The trial and error method, despite its universal application, comes with its pros and cons.
H3: Advantages
Trial and error encourages creativity and fosters resilience. It allows for the discovery of all possible solutions and can lead to unexpected yet effective outcomes.
H3: Disadvantages
However, trial and error can be time-consuming and resource-intensive. It may not be feasible when there’s a need for immediate solutions or when the risks of failure are high.
To better illustrate the concept of trial and error, let’s consider a couple of examples.
Example 1: Learning to Code
When learning to code, students often write a program, run it to see if it works, and if it doesn’t, they debug and modify their code. This is an example of trial and error.
Example 2: Medicinal Drug Discovery
In medicinal chemistry, scientists often synthesize and test numerous compounds before finding one that effectively treats a disease. This process embodies the trial and error method.
Enhancing the Trial and Error Process
While trial and error inherently involve some degree of uncertainty, some strategies can enhance its efficiency.
Learn from Each Attempt
Each trial, whether successful or unsuccessful, provides valuable information. Reflecting on each attempt can improve future trials and hasten the problem-solving process.
Embrace Failure
Viewing errors as learning opportunities rather than failures can foster resilience and creativity, essential traits for effective problem-solving.
In essence, trial and error is an indispensable problem-solving strategy that encourages creativity, resilience, and comprehensive solution discovery. By understanding its characteristics, benefits, and limitations, we can harness its potential more effectively in various domains of life. Remember, each trial brings you one step closer to a solution, and each error is a stepping stone to success.
7.3 Problem-Solving
Learning objectives.
By the end of this section, you will be able to:
- Describe problem solving strategies
- Define algorithm and heuristic
- Explain some common roadblocks to effective problem solving
People face problems every day—usually, multiple problems throughout the day. Sometimes these problems are straightforward: To double a recipe for pizza dough, for example, all that is required is that each ingredient in the recipe be doubled. Sometimes, however, the problems we encounter are more complex. For example, say you have a work deadline, and you must mail a printed copy of a report to your supervisor by the end of the business day. The report is time-sensitive and must be sent overnight. You finished the report last night, but your printer will not work today. What should you do? First, you need to identify the problem and then apply a strategy for solving the problem.
The study of human and animal problem solving processes has provided much insight toward the understanding of our conscious experience and led to advancements in computer science and artificial intelligence. Essentially much of cognitive science today represents studies of how we consciously and unconsciously make decisions and solve problems. For instance, when encountered with a large amount of information, how do we go about making decisions about the most efficient way of sorting and analyzing all the information in order to find what you are looking for as in visual search paradigms in cognitive psychology. Or in a situation where a piece of machinery is not working properly, how do we go about organizing how to address the issue and understand what the cause of the problem might be. How do we sort the procedures that will be needed and focus attention on what is important in order to solve problems efficiently. Within this section we will discuss some of these issues and examine processes related to human, animal and computer problem solving.
PROBLEM-SOLVING STRATEGIES
When people are presented with a problem—whether it is a complex mathematical problem or a broken printer, how do you solve it? Before finding a solution to the problem, the problem must first be clearly identified. After that, one of many problem solving strategies can be applied, hopefully resulting in a solution.
Problems themselves can be classified into two different categories known as ill-defined and well-defined problems (Schacter, 2009). Ill-defined problems represent issues that do not have clear goals, solution paths, or expected solutions whereas well-defined problems have specific goals, clearly defined solutions, and clear expected solutions. Problem solving often incorporates pragmatics (logical reasoning) and semantics (interpretation of meanings behind the problem), and also in many cases require abstract thinking and creativity in order to find novel solutions. Within psychology, problem solving refers to a motivational drive for reading a definite “goal” from a present situation or condition that is either not moving toward that goal, is distant from it, or requires more complex logical analysis for finding a missing description of conditions or steps toward that goal. Processes relating to problem solving include problem finding also known as problem analysis, problem shaping where the organization of the problem occurs, generating alternative strategies, implementation of attempted solutions, and verification of the selected solution. Various methods of studying problem solving exist within the field of psychology including introspection, behavior analysis and behaviorism, simulation, computer modeling, and experimentation.
A problem-solving strategy is a plan of action used to find a solution. Different strategies have different action plans associated with them (table below). For example, a well-known strategy is trial and error. The old adage, “If at first you don’t succeed, try, try again” describes trial and error. In terms of your broken printer, you could try checking the ink levels, and if that doesn’t work, you could check to make sure the paper tray isn’t jammed. Or maybe the printer isn’t actually connected to your laptop. When using trial and error, you would continue to try different solutions until you solved your problem. Although trial and error is not typically one of the most time-efficient strategies, it is a commonly used one.
Another type of strategy is an algorithm. An algorithm is a problem-solving formula that provides you with step-by-step instructions used to achieve a desired outcome (Kahneman, 2011). You can think of an algorithm as a recipe with highly detailed instructions that produce the same result every time they are performed. Algorithms are used frequently in our everyday lives, especially in computer science. When you run a search on the Internet, search engines like Google use algorithms to decide which entries will appear first in your list of results. Facebook also uses algorithms to decide which posts to display on your newsfeed. Can you identify other situations in which algorithms are used?
A heuristic is another type of problem solving strategy. While an algorithm must be followed exactly to produce a correct result, a heuristic is a general problem-solving framework (Tversky & Kahneman, 1974). You can think of these as mental shortcuts that are used to solve problems. A “rule of thumb” is an example of a heuristic. Such a rule saves the person time and energy when making a decision, but despite its time-saving characteristics, it is not always the best method for making a rational decision. Different types of heuristics are used in different types of situations, but the impulse to use a heuristic occurs when one of five conditions is met (Pratkanis, 1989):
- When one is faced with too much information
- When the time to make a decision is limited
- When the decision to be made is unimportant
- When there is access to very little information to use in making the decision
- When an appropriate heuristic happens to come to mind in the same moment
Working backwards is a useful heuristic in which you begin solving the problem by focusing on the end result. Consider this example: You live in Washington, D.C. and have been invited to a wedding at 4 PM on Saturday in Philadelphia. Knowing that Interstate 95 tends to back up any day of the week, you need to plan your route and time your departure accordingly. If you want to be at the wedding service by 3:30 PM, and it takes 2.5 hours to get to Philadelphia without traffic, what time should you leave your house? You use the working backwards heuristic to plan the events of your day on a regular basis, probably without even thinking about it.
Another useful heuristic is the practice of accomplishing a large goal or task by breaking it into a series of smaller steps. Students often use this common method to complete a large research project or long essay for school. For example, students typically brainstorm, develop a thesis or main topic, research the chosen topic, organize their information into an outline, write a rough draft, revise and edit the rough draft, develop a final draft, organize the references list, and proofread their work before turning in the project. The large task becomes less overwhelming when it is broken down into a series of small steps.
Further problem solving strategies have been identified (listed below) that incorporate flexible and creative thinking in order to reach solutions efficiently.
Additional Problem Solving Strategies :
- Abstraction – refers to solving the problem within a model of the situation before applying it to reality.
- Analogy – is using a solution that solves a similar problem.
- Brainstorming – refers to collecting an analyzing a large amount of solutions, especially within a group of people, to combine the solutions and developing them until an optimal solution is reached.
- Divide and conquer – breaking down large complex problems into smaller more manageable problems.
- Hypothesis testing – method used in experimentation where an assumption about what would happen in response to manipulating an independent variable is made, and analysis of the affects of the manipulation are made and compared to the original hypothesis.
- Lateral thinking – approaching problems indirectly and creatively by viewing the problem in a new and unusual light.
- Means-ends analysis – choosing and analyzing an action at a series of smaller steps to move closer to the goal.
- Method of focal objects – putting seemingly non-matching characteristics of different procedures together to make something new that will get you closer to the goal.
- Morphological analysis – analyzing the outputs of and interactions of many pieces that together make up a whole system.
- Proof – trying to prove that a problem cannot be solved. Where the proof fails becomes the starting point or solving the problem.
- Reduction – adapting the problem to be as similar problems where a solution exists.
- Research – using existing knowledge or solutions to similar problems to solve the problem.
- Root cause analysis – trying to identify the cause of the problem.
The strategies listed above outline a short summary of methods we use in working toward solutions and also demonstrate how the mind works when being faced with barriers preventing goals to be reached.
One example of means-end analysis can be found by using the Tower of Hanoi paradigm . This paradigm can be modeled as a word problems as demonstrated by the Missionary-Cannibal Problem :
Missionary-Cannibal Problem
Three missionaries and three cannibals are on one side of a river and need to cross to the other side. The only means of crossing is a boat, and the boat can only hold two people at a time. Your goal is to devise a set of moves that will transport all six of the people across the river, being in mind the following constraint: The number of cannibals can never exceed the number of missionaries in any location. Remember that someone will have to also row that boat back across each time.
Hint : At one point in your solution, you will have to send more people back to the original side than you just sent to the destination.
The actual Tower of Hanoi problem consists of three rods sitting vertically on a base with a number of disks of different sizes that can slide onto any rod. The puzzle starts with the disks in a neat stack in ascending order of size on one rod, the smallest at the top making a conical shape. The objective of the puzzle is to move the entire stack to another rod obeying the following rules:
- 1. Only one disk can be moved at a time.
- 2. Each move consists of taking the upper disk from one of the stacks and placing it on top of another stack or on an empty rod.
- 3. No disc may be placed on top of a smaller disk.
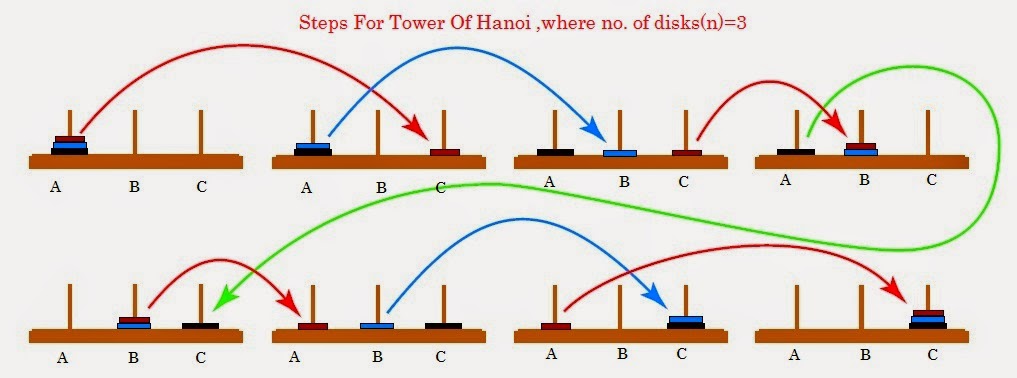
Figure 7.02. Steps for solving the Tower of Hanoi in the minimum number of moves when there are 3 disks.
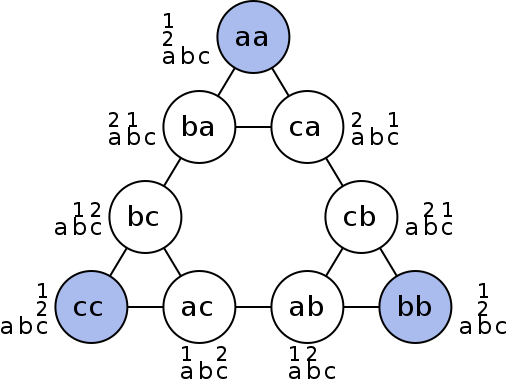
Figure 7.03. Graphical representation of nodes (circles) and moves (lines) of Tower of Hanoi.
The Tower of Hanoi is a frequently used psychological technique to study problem solving and procedure analysis. A variation of the Tower of Hanoi known as the Tower of London has been developed which has been an important tool in the neuropsychological diagnosis of executive function disorders and their treatment.
GESTALT PSYCHOLOGY AND PROBLEM SOLVING
As you may recall from the sensation and perception chapter, Gestalt psychology describes whole patterns, forms and configurations of perception and cognition such as closure, good continuation, and figure-ground. In addition to patterns of perception, Wolfgang Kohler, a German Gestalt psychologist traveled to the Spanish island of Tenerife in order to study animals behavior and problem solving in the anthropoid ape.
As an interesting side note to Kohler’s studies of chimp problem solving, Dr. Ronald Ley, professor of psychology at State University of New York provides evidence in his book A Whisper of Espionage (1990) suggesting that while collecting data for what would later be his book The Mentality of Apes (1925) on Tenerife in the Canary Islands between 1914 and 1920, Kohler was additionally an active spy for the German government alerting Germany to ships that were sailing around the Canary Islands. Ley suggests his investigations in England, Germany and elsewhere in Europe confirm that Kohler had served in the German military by building, maintaining and operating a concealed radio that contributed to Germany’s war effort acting as a strategic outpost in the Canary Islands that could monitor naval military activity approaching the north African coast.
While trapped on the island over the course of World War 1, Kohler applied Gestalt principles to animal perception in order to understand how they solve problems. He recognized that the apes on the islands also perceive relations between stimuli and the environment in Gestalt patterns and understand these patterns as wholes as opposed to pieces that make up a whole. Kohler based his theories of animal intelligence on the ability to understand relations between stimuli, and spent much of his time while trapped on the island investigation what he described as insight , the sudden perception of useful or proper relations. In order to study insight in animals, Kohler would present problems to chimpanzee’s by hanging some banana’s or some kind of food so it was suspended higher than the apes could reach. Within the room, Kohler would arrange a variety of boxes, sticks or other tools the chimpanzees could use by combining in patterns or organizing in a way that would allow them to obtain the food (Kohler & Winter, 1925).
While viewing the chimpanzee’s, Kohler noticed one chimp that was more efficient at solving problems than some of the others. The chimp, named Sultan, was able to use long poles to reach through bars and organize objects in specific patterns to obtain food or other desirables that were originally out of reach. In order to study insight within these chimps, Kohler would remove objects from the room to systematically make the food more difficult to obtain. As the story goes, after removing many of the objects Sultan was used to using to obtain the food, he sat down ad sulked for a while, and then suddenly got up going over to two poles lying on the ground. Without hesitation Sultan put one pole inside the end of the other creating a longer pole that he could use to obtain the food demonstrating an ideal example of what Kohler described as insight. In another situation, Sultan discovered how to stand on a box to reach a banana that was suspended from the rafters illustrating Sultan’s perception of relations and the importance of insight in problem solving.
Grande (another chimp in the group studied by Kohler) builds a three-box structure to reach the bananas, while Sultan watches from the ground. Insight , sometimes referred to as an “Ah-ha” experience, was the term Kohler used for the sudden perception of useful relations among objects during problem solving (Kohler, 1927; Radvansky & Ashcraft, 2013).
Solving puzzles.
Problem-solving abilities can improve with practice. Many people challenge themselves every day with puzzles and other mental exercises to sharpen their problem-solving skills. Sudoku puzzles appear daily in most newspapers. Typically, a sudoku puzzle is a 9×9 grid. The simple sudoku below (see figure) is a 4×4 grid. To solve the puzzle, fill in the empty boxes with a single digit: 1, 2, 3, or 4. Here are the rules: The numbers must total 10 in each bolded box, each row, and each column; however, each digit can only appear once in a bolded box, row, and column. Time yourself as you solve this puzzle and compare your time with a classmate.
How long did it take you to solve this sudoku puzzle? (You can see the answer at the end of this section.)
Here is another popular type of puzzle (figure below) that challenges your spatial reasoning skills. Connect all nine dots with four connecting straight lines without lifting your pencil from the paper:
Did you figure it out? (The answer is at the end of this section.) Once you understand how to crack this puzzle, you won’t forget.
Take a look at the “Puzzling Scales” logic puzzle below (figure below). Sam Loyd, a well-known puzzle master, created and refined countless puzzles throughout his lifetime (Cyclopedia of Puzzles, n.d.).

What steps did you take to solve this puzzle? You can read the solution at the end of this section.
Pitfalls to problem solving.
Not all problems are successfully solved, however. What challenges stop us from successfully solving a problem? Albert Einstein once said, “Insanity is doing the same thing over and over again and expecting a different result.” Imagine a person in a room that has four doorways. One doorway that has always been open in the past is now locked. The person, accustomed to exiting the room by that particular doorway, keeps trying to get out through the same doorway even though the other three doorways are open. The person is stuck—but she just needs to go to another doorway, instead of trying to get out through the locked doorway. A mental set is where you persist in approaching a problem in a way that has worked in the past but is clearly not working now.
Functional fixedness is a type of mental set where you cannot perceive an object being used for something other than what it was designed for. During the Apollo 13 mission to the moon, NASA engineers at Mission Control had to overcome functional fixedness to save the lives of the astronauts aboard the spacecraft. An explosion in a module of the spacecraft damaged multiple systems. The astronauts were in danger of being poisoned by rising levels of carbon dioxide because of problems with the carbon dioxide filters. The engineers found a way for the astronauts to use spare plastic bags, tape, and air hoses to create a makeshift air filter, which saved the lives of the astronauts.
Researchers have investigated whether functional fixedness is affected by culture. In one experiment, individuals from the Shuar group in Ecuador were asked to use an object for a purpose other than that for which the object was originally intended. For example, the participants were told a story about a bear and a rabbit that were separated by a river and asked to select among various objects, including a spoon, a cup, erasers, and so on, to help the animals. The spoon was the only object long enough to span the imaginary river, but if the spoon was presented in a way that reflected its normal usage, it took participants longer to choose the spoon to solve the problem. (German & Barrett, 2005). The researchers wanted to know if exposure to highly specialized tools, as occurs with individuals in industrialized nations, affects their ability to transcend functional fixedness. It was determined that functional fixedness is experienced in both industrialized and nonindustrialized cultures (German & Barrett, 2005).
In order to make good decisions, we use our knowledge and our reasoning. Often, this knowledge and reasoning is sound and solid. Sometimes, however, we are swayed by biases or by others manipulating a situation. For example, let’s say you and three friends wanted to rent a house and had a combined target budget of $1,600. The realtor shows you only very run-down houses for $1,600 and then shows you a very nice house for $2,000. Might you ask each person to pay more in rent to get the $2,000 home? Why would the realtor show you the run-down houses and the nice house? The realtor may be challenging your anchoring bias. An anchoring bias occurs when you focus on one piece of information when making a decision or solving a problem. In this case, you’re so focused on the amount of money you are willing to spend that you may not recognize what kinds of houses are available at that price point.
The confirmation bias is the tendency to focus on information that confirms your existing beliefs. For example, if you think that your professor is not very nice, you notice all of the instances of rude behavior exhibited by the professor while ignoring the countless pleasant interactions he is involved in on a daily basis. Hindsight bias leads you to believe that the event you just experienced was predictable, even though it really wasn’t. In other words, you knew all along that things would turn out the way they did. Representative bias describes a faulty way of thinking, in which you unintentionally stereotype someone or something; for example, you may assume that your professors spend their free time reading books and engaging in intellectual conversation, because the idea of them spending their time playing volleyball or visiting an amusement park does not fit in with your stereotypes of professors.
Finally, the availability heuristic is a heuristic in which you make a decision based on an example, information, or recent experience that is that readily available to you, even though it may not be the best example to inform your decision . Biases tend to “preserve that which is already established—to maintain our preexisting knowledge, beliefs, attitudes, and hypotheses” (Aronson, 1995; Kahneman, 2011). These biases are summarized in the table below.
Were you able to determine how many marbles are needed to balance the scales in the figure below? You need nine. Were you able to solve the problems in the figures above? Here are the answers.

Many different strategies exist for solving problems. Typical strategies include trial and error, applying algorithms, and using heuristics. To solve a large, complicated problem, it often helps to break the problem into smaller steps that can be accomplished individually, leading to an overall solution. Roadblocks to problem solving include a mental set, functional fixedness, and various biases that can cloud decision making skills.
References:
Openstax Psychology text by Kathryn Dumper, William Jenkins, Arlene Lacombe, Marilyn Lovett and Marion Perlmutter licensed under CC BY v4.0. https://openstax.org/details/books/psychology
Review Questions:
1. A specific formula for solving a problem is called ________.
a. an algorithm
b. a heuristic
c. a mental set
d. trial and error
2. Solving the Tower of Hanoi problem tends to utilize a ________ strategy of problem solving.
a. divide and conquer
b. means-end analysis
d. experiment
3. A mental shortcut in the form of a general problem-solving framework is called ________.
4. Which type of bias involves becoming fixated on a single trait of a problem?
a. anchoring bias
b. confirmation bias
c. representative bias
d. availability bias
5. Which type of bias involves relying on a false stereotype to make a decision?
6. Wolfgang Kohler analyzed behavior of chimpanzees by applying Gestalt principles to describe ________.
a. social adjustment
b. student load payment options
c. emotional learning
d. insight learning
7. ________ is a type of mental set where you cannot perceive an object being used for something other than what it was designed for.
a. functional fixedness
c. working memory
Critical Thinking Questions:
1. What is functional fixedness and how can overcoming it help you solve problems?
2. How does an algorithm save you time and energy when solving a problem?
Personal Application Question:
1. Which type of bias do you recognize in your own decision making processes? How has this bias affected how you’ve made decisions in the past and how can you use your awareness of it to improve your decisions making skills in the future?
anchoring bias
availability heuristic
confirmation bias
functional fixedness
hindsight bias
problem-solving strategy
representative bias
trial and error
working backwards
Answers to Exercises
algorithm: problem-solving strategy characterized by a specific set of instructions
anchoring bias: faulty heuristic in which you fixate on a single aspect of a problem to find a solution
availability heuristic: faulty heuristic in which you make a decision based on information readily available to you
confirmation bias: faulty heuristic in which you focus on information that confirms your beliefs
functional fixedness: inability to see an object as useful for any other use other than the one for which it was intended
heuristic: mental shortcut that saves time when solving a problem
hindsight bias: belief that the event just experienced was predictable, even though it really wasn’t
mental set: continually using an old solution to a problem without results
problem-solving strategy: method for solving problems
representative bias: faulty heuristic in which you stereotype someone or something without a valid basis for your judgment
trial and error: problem-solving strategy in which multiple solutions are attempted until the correct one is found
working backwards: heuristic in which you begin to solve a problem by focusing on the end result

Share This Book
- Increase Font Size
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Guided Meditations
- Verywell Mind Insights
- 2023 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
Problem-Solving Strategies and Obstacles
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "trial and error of problem solving")
Sean is a fact-checker and researcher with experience in sociology, field research, and data analytics.
:max_bytes(150000):strip_icc():format(webp)/Sean-Blackburn-1000-a8b2229366944421bc4b2f2ba26a1003.jpg "trial and error of problem solving")
JGI / Jamie Grill / Getty Images
- Application
- Improvement
From deciding what to eat for dinner to considering whether it's the right time to buy a house, problem-solving is a large part of our daily lives. Learn some of the problem-solving strategies that exist and how to use them in real life, along with ways to overcome obstacles that are making it harder to resolve the issues you face.
What Is Problem-Solving?
In cognitive psychology , the term 'problem-solving' refers to the mental process that people go through to discover, analyze, and solve problems.
A problem exists when there is a goal that we want to achieve but the process by which we will achieve it is not obvious to us. Put another way, there is something that we want to occur in our life, yet we are not immediately certain how to make it happen.
Maybe you want a better relationship with your spouse or another family member but you're not sure how to improve it. Or you want to start a business but are unsure what steps to take. Problem-solving helps you figure out how to achieve these desires.
The problem-solving process involves:
- Discovery of the problem
- Deciding to tackle the issue
- Seeking to understand the problem more fully
- Researching available options or solutions
- Taking action to resolve the issue
Before problem-solving can occur, it is important to first understand the exact nature of the problem itself. If your understanding of the issue is faulty, your attempts to resolve it will also be incorrect or flawed.
Problem-Solving Mental Processes
Several mental processes are at work during problem-solving. Among them are:
- Perceptually recognizing the problem
- Representing the problem in memory
- Considering relevant information that applies to the problem
- Identifying different aspects of the problem
- Labeling and describing the problem
Problem-Solving Strategies
There are many ways to go about solving a problem. Some of these strategies might be used on their own, or you may decide to employ multiple approaches when working to figure out and fix a problem.
An algorithm is a step-by-step procedure that, by following certain "rules" produces a solution. Algorithms are commonly used in mathematics to solve division or multiplication problems. But they can be used in other fields as well.
In psychology, algorithms can be used to help identify individuals with a greater risk of mental health issues. For instance, research suggests that certain algorithms might help us recognize children with an elevated risk of suicide or self-harm.
One benefit of algorithms is that they guarantee an accurate answer. However, they aren't always the best approach to problem-solving, in part because detecting patterns can be incredibly time-consuming.
There are also concerns when machine learning is involved—also known as artificial intelligence (AI)—such as whether they can accurately predict human behaviors.
Heuristics are shortcut strategies that people can use to solve a problem at hand. These "rule of thumb" approaches allow you to simplify complex problems, reducing the total number of possible solutions to a more manageable set.
If you find yourself sitting in a traffic jam, for example, you may quickly consider other routes, taking one to get moving once again. When shopping for a new car, you might think back to a prior experience when negotiating got you a lower price, then employ the same tactics.
While heuristics may be helpful when facing smaller issues, major decisions shouldn't necessarily be made using a shortcut approach. Heuristics also don't guarantee an effective solution, such as when trying to drive around a traffic jam only to find yourself on an equally crowded route.
Trial and Error
A trial-and-error approach to problem-solving involves trying a number of potential solutions to a particular issue, then ruling out those that do not work. If you're not sure whether to buy a shirt in blue or green, for instance, you may try on each before deciding which one to purchase.
This can be a good strategy to use if you have a limited number of solutions available. But if there are many different choices available, narrowing down the possible options using another problem-solving technique can be helpful before attempting trial and error.
In some cases, the solution to a problem can appear as a sudden insight. You are facing an issue in a relationship or your career when, out of nowhere, the solution appears in your mind and you know exactly what to do.
Insight can occur when the problem in front of you is similar to an issue that you've dealt with in the past. Although, you may not recognize what is occurring since the underlying mental processes that lead to insight often happen outside of conscious awareness .
Research indicates that insight is most likely to occur during times when you are alone—such as when going on a walk by yourself, when you're in the shower, or when lying in bed after waking up.
How to Apply Problem-Solving Strategies in Real Life
If you're facing a problem, you can implement one or more of these strategies to find a potential solution. Here's how to use them in real life:
- Create a flow chart . If you have time, you can take advantage of the algorithm approach to problem-solving by sitting down and making a flow chart of each potential solution, its consequences, and what happens next.
- Recall your past experiences . When a problem needs to be solved fairly quickly, heuristics may be a better approach. Think back to when you faced a similar issue, then use your knowledge and experience to choose the best option possible.
- Start trying potential solutions . If your options are limited, start trying them one by one to see which solution is best for achieving your desired goal. If a particular solution doesn't work, move on to the next.
- Take some time alone . Since insight is often achieved when you're alone, carve out time to be by yourself for a while. The answer to your problem may come to you, seemingly out of the blue, if you spend some time away from others.
Obstacles to Problem-Solving
Problem-solving is not a flawless process as there are a number of obstacles that can interfere with our ability to solve a problem quickly and efficiently. These obstacles include:
- Assumptions: When dealing with a problem, people can make assumptions about the constraints and obstacles that prevent certain solutions. Thus, they may not even try some potential options.
- Functional fixedness : This term refers to the tendency to view problems only in their customary manner. Functional fixedness prevents people from fully seeing all of the different options that might be available to find a solution.
- Irrelevant or misleading information: When trying to solve a problem, it's important to distinguish between information that is relevant to the issue and irrelevant data that can lead to faulty solutions. The more complex the problem, the easier it is to focus on misleading or irrelevant information.
- Mental set: A mental set is a tendency to only use solutions that have worked in the past rather than looking for alternative ideas. A mental set can work as a heuristic, making it a useful problem-solving tool. However, mental sets can also lead to inflexibility, making it more difficult to find effective solutions.
How to Improve Your Problem-Solving Skills
In the end, if your goal is to become a better problem-solver, it's helpful to remember that this is a process. Thus, if you want to improve your problem-solving skills, following these steps can help lead you to your solution:
- Recognize that a problem exists . If you are facing a problem, there are generally signs. For instance, if you have a mental illness , you may experience excessive fear or sadness, mood changes, and changes in sleeping or eating habits. Recognizing these signs can help you realize that an issue exists.
- Decide to solve the problem . Make a conscious decision to solve the issue at hand. Commit to yourself that you will go through the steps necessary to find a solution.
- Seek to fully understand the issue . Analyze the problem you face, looking at it from all sides. If your problem is relationship-related, for instance, ask yourself how the other person may be interpreting the issue. You might also consider how your actions might be contributing to the situation.
- Research potential options . Using the problem-solving strategies mentioned, research potential solutions. Make a list of options, then consider each one individually. What are some pros and cons of taking the available routes? What would you need to do to make them happen?
- Take action . Select the best solution possible and take action. Action is one of the steps required for change . So, go through the motions needed to resolve the issue.
- Try another option, if needed . If the solution you chose didn't work, don't give up. Either go through the problem-solving process again or simply try another option.
You can find a way to solve your problems as long as you keep working toward this goal—even if the best solution is simply to let go because no other good solution exists.
Sarathy V. Real world problem-solving . Front Hum Neurosci . 2018;12:261. doi:10.3389/fnhum.2018.00261
Dunbar K. Problem solving . A Companion to Cognitive Science . 2017. doi:10.1002/9781405164535.ch20
Stewart SL, Celebre A, Hirdes JP, Poss JW. Risk of suicide and self-harm in kids: The development of an algorithm to identify high-risk individuals within the children's mental health system . Child Psychiat Human Develop . 2020;51:913-924. doi:10.1007/s10578-020-00968-9
Rosenbusch H, Soldner F, Evans AM, Zeelenberg M. Supervised machine learning methods in psychology: A practical introduction with annotated R code . Soc Personal Psychol Compass . 2021;15(2):e12579. doi:10.1111/spc3.12579
Mishra S. Decision-making under risk: Integrating perspectives from biology, economics, and psychology . Personal Soc Psychol Rev . 2014;18(3):280-307. doi:10.1177/1088868314530517
Csikszentmihalyi M, Sawyer K. Creative insight: The social dimension of a solitary moment . In: The Systems Model of Creativity . 2015:73-98. doi:10.1007/978-94-017-9085-7_7
Chrysikou EG, Motyka K, Nigro C, Yang SI, Thompson-Schill SL. Functional fixedness in creative thinking tasks depends on stimulus modality . Psychol Aesthet Creat Arts . 2016;10(4):425‐435. doi:10.1037/aca0000050
Huang F, Tang S, Hu Z. Unconditional perseveration of the short-term mental set in chunk decomposition . Front Psychol . 2018;9:2568. doi:10.3389/fpsyg.2018.02568
National Alliance on Mental Illness. Warning signs and symptoms .
Mayer RE. Thinking, problem solving, cognition, 2nd ed .
Schooler JW, Ohlsson S, Brooks K. Thoughts beyond words: When language overshadows insight. J Experiment Psychol: General . 1993;122:166-183. doi:10.1037/0096-3445.2.166
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
4 Main problem-solving strategies

In Psychology, you get to read about a ton of therapies. It’s mind-boggling how different theorists have looked at human nature differently and have come up with different, often somewhat contradictory, theoretical approaches.
Yet, you can’t deny the kernel of truth that’s there in all of them. All therapies, despite being different, have one thing in common- they all aim to solve people’s problems. They all aim to equip people with problem-solving strategies to help them deal with their life problems.
Problem-solving is really at the core of everything we do. Throughout our lives, we’re constantly trying to solve one problem or another. When we can’t, all sorts of psychological problems take hold. Getting good at solving problems is a fundamental life skill.
Problem-solving stages
What problem-solving does is take you from an initial state (A) where a problem exists to a final or goal state (B), where the problem no longer exists.
To move from A to B, you need to perform some actions called operators. Engaging in the right operators moves you from A to B. So, the stages of problem-solving are:
- Initial state
The problem itself can either be well-defined or ill-defined. A well-defined problem is one where you can clearly see where you are (A), where you want to go (B), and what you need to do to get there (engaging the right operators).
For example, feeling hungry and wanting to eat can be seen as a problem, albeit a simple one for many. Your initial state is hunger (A) and your final state is satisfaction or no hunger (B). Going to the kitchen and finding something to eat is using the right operator.
In contrast, ill-defined or complex problems are those where one or more of the three problem solving stages aren’t clear. For example, if your goal is to bring about world peace, what is it exactly that you want to do?
It’s been rightly said that a problem well-defined is a problem half-solved. Whenever you face an ill-defined problem, the first thing you need to do is get clear about all the three stages.
Often, people will have a decent idea of where they are (A) and where they want to be (B). What they usually get stuck on is finding the right operators.
Initial theory in problem-solving
When people first attempt to solve a problem, i.e. when they first engage their operators, they often have an initial theory of solving the problem. As I mentioned in my article on overcoming challenges for complex problems, this initial theory is often wrong.
But, at the time, it’s usually the result of the best information the individual can gather about the problem. When this initial theory fails, the problem-solver gets more data, and he refines the theory. Eventually, he finds an actual theory i.e. a theory that works. This finally allows him to engage the right operators to move from A to B.
Problem-solving strategies
These are operators that a problem solver tries to move from A to B. There are several problem-solving strategies but the main ones are:
- Trial and error
1. Algorithms
When you follow a step-by-step procedure to solve a problem or reach a goal, you’re using an algorithm. If you follow the steps exactly, you’re guaranteed to find the solution. The drawback of this strategy is that it can get cumbersome and time-consuming for large problems.
Say I hand you a 200-page book and ask you to read out to me what’s written on page 100. If you start from page 1 and keep turning the pages, you’ll eventually reach page 100. There’s no question about it. But the process is time-consuming. So instead you use what’s called a heuristic.
2. Heuristics
Heuristics are rules of thumb that people use to simplify problems. They’re often based on memories from past experiences. They cut down the number of steps needed to solve a problem, but they don’t always guarantee a solution. Heuristics save us time and effort if they work.
You know that page 100 lies in the middle of the book. Instead of starting from page one, you try to open the book in the middle. Of course, you may not hit page 100, but you can get really close with just a couple of tries.
If you open page 90, for instance, you can then algorithmically move from 90 to 100. Thus, you can use a combination of heuristics and algorithms to solve the problem. In real life, we often solve problems like this.
When police are looking for suspects in an investigation, they try to narrow down the problem similarly. Knowing the suspect is 6 feet tall isn’t enough, as there could be thousands of people out there with that height.
Knowing the suspect is 6 feet tall, male, wears glasses, and has blond hair narrows down the problem significantly.
3. Trial and error
When you have an initial theory to solve a problem, you try it out. If you fail, you refine or change your theory and try again. This is the trial-and-error process of solving problems. Behavioral and cognitive trial and error often go hand in hand, but for many problems, we start with behavioural trial and error until we’re forced to think.
Say you’re in a maze, trying to find your way out. You try one route without giving it much thought and you find it leads to nowhere. Then you try another route and fail again. This is behavioural trial and error because you aren’t putting any thought into your trials. You’re just throwing things at the wall to see what sticks.
This isn’t an ideal strategy but can be useful in situations where it’s impossible to get any information about the problem without doing some trials.
Then, when you have enough information about the problem, you shuffle that information in your mind to find a solution. This is cognitive trial and error or analytical thinking. Behavioral trial and error can take a lot of time, so using cognitive trial and error as much as possible is advisable. You got to sharpen your axe before you cut the tree.
When solving complex problems, people get frustrated after having tried several operators that didn’t work. They abandon their problem and go on with their routine activities. Suddenly, they get a flash of insight that makes them confident they can now solve the problem.
I’ve done an entire article on the underlying mechanics of insight . Long story short, when you take a step back from your problem, it helps you see things in a new light. You make use of associations that were previously unavailable to you.
You get more puzzle pieces to work with and this increases the odds of you finding a path from A to B, i.e. finding operators that work.
Pilot problem-solving
No matter what problem-solving strategy you employ, it’s all about finding out what works. Your actual theory tells you what operators will take you from A to B. Complex problems don’t reveal their actual theories easily solely because they are complex.
Therefore, the first step to solving a complex problem is getting as clear as you can about what you’re trying to accomplish- collecting as much information as you can about the problem.
This gives you enough raw materials to formulate an initial theory. We want our initial theory to be as close to an actual theory as possible. This saves time and resources.
Solving a complex problem can mean investing a lot of resources. Therefore, it is recommended you verify your initial theory if you can. I call this pilot problem-solving.
Before businesses invest in making a product, they sometimes distribute free versions to a small sample of potential customers to ensure their target audience will be receptive to the product.
Before making a series of TV episodes, TV show producers often release pilot episodes to figure out whether the show can take off.
Before conducting a large study, researchers do a pilot study to survey a small sample of the population to determine if the study is worth carrying out.
The same ‘testing the waters’ approach needs to be applied to solving any complex problem you might be facing. Is your problem worth investing a lot of resources in? In management, we’re constantly taught about Return On Investment (ROI). The ROI should justify the investment.
If the answer is yes, go ahead and formulate your initial theory based on extensive research. Find a way to verify your initial theory. You need this reassurance that you’re going in the right direction, especially for complex problems that take a long time to solve.

Getting your causal thinking right
Problem solving boils down to getting your causal thinking right. Finding solutions is all about finding out what works, i.e. finding operators that take you from A to B. To succeed, you need to be confident in your initial theory (If I do X and Y, they’ll lead me to B). You need to be sure that doing X and Y will lead you to B- doing X and Y will cause B.
All obstacles to problem-solving or goal-accomplishing are rooted in faulty causal thinking leading to not engaging the right operators. When your causal thinking is on point, you’ll have no problem engaging the right operators.
As you can imagine, for complex problems, getting our causal thinking right isn’t easy. That’s why we need to formulate an initial theory and refine it over time.
I like to think of problem-solving as the ability to project the present into the past or into the future. When you’re solving problems, you’re basically looking at your present situation and asking yourself two questions:
“What caused this?” (Projecting present into the past)
“What will this cause?” (Projecting present into the future)
The first question is more relevant to problem-solving and the second to goal-accomplishing.
If you find yourself in a mess , you need to answer the “What caused this?” question correctly. For the operators you’re currently engaging to reach your goal, ask yourself, “What will this cause?” If you think they cannot cause B, it’s time to refine your initial theory.

Hi, I’m Hanan Parvez (MA Psychology). I’ve been writing about Psychology for 9+ years. My work has been featured in Forbes , Business Insider , Reader’s Digest , and Entrepreneur . If you have any queries, use the contact form or reach out to me on my socials.
Forgot password? New user? Sign up
Existing user? Log in
Trial and Error
Already have an account? Log in here.
- Andrew Hayes
Trial and error refers to the process of verifying that a certain choice is right (or wrong). We simply substitute that choice into the problem and check. Some questions can only be solved by trial and error; for others we must first decide if there isn't a faster way to arrive at the answer. In the examples to follow, we test all choices for your benefit. Once you have the right answer, there is no need to check the rest of the choices.
\[(2, 3), (3, 5), (4, 4), (6, 3), (10, 0)\] How many of the above pairs of integers are solutions to \( 2x + 3y = 20 ?\) (A) \(\ \ 1\) (B) \(\ \ 2\) (C) \(\ \ 3\) (D) \(\ \ 4\) (E) \(\ \ 5\) Show Answer Correct Answer: B Solution: We try each of the pairs of integers: For \((2, 3)\), we have \( 2 \times 2 + 3 \times 3 = 4 + 9 = 13 \neq 20 \). For \((3, 5)\), we have \( 2 \times 3 + 3 \times 5 = 6 + 15 = 21 \neq 20 \). For \((4, 4)\), we have \( 2 \times 4 + 3 \times 4 = 8 + 12 = 20 \). This is a solution. For \((6, 3)\), we have \( 2 \times 6 + 3 \times 3 = 12 + 9 = 21 \neq 20 \). For \((10, 0)\), we have \( 2 \times 10 + 3 \times 0 = 20 + 0 = 20 \). This is a solution. Thus, 2 of the pairs are solutions. Incorrect Choices: (A) , (C) , (D) , and (E) See the solution for why these choices are wrong.
\[ ab - 2a - 2b - 2 = 0 \]
Which of the following pairs of numbers \( (a, b) \) is a solution to the equation above?
- \( (3, 8) \)
- \( (4, 5 ) \)
- \( (4.5, 4.5) \)
(A)\(\ \ \) I only (B)\(\ \ \) II only (C)\(\ \ \) I and II only (D)\(\ \ \) I and III only (E)\(\ \ \) I, II and III
When the wind blows, half of the leaves on a tree fall, and then 5 more. When the wind blows a second time, again half of the leaves fall and then 5 more. If there are no leaves remaining on the tree, how many leaves are there at the start? (A) \(\ \ 5\) (B) \(\ \ 10\) (C) \(\ \ 15\) (D) \(\ \ 30\) (E) \(\ \ 50\) Show Answer Correct Answer: D Solution 1: Let's analyze each answer using the trial and error approach. (A) If there are 5 leaves at the start, when the wind blows the first time, half of the leaves fall, which is 2.5, and then 5 more, so there are \( 5 - 2.5 - 5 = - 2.5 \) leaves left. This does not make sense, so we eliminate this choice. (B) If there are 10 leaves at the start, when the wind blows the first time, half of the leaves fall, which is 5, and then 5 more, so there are \( 10 - 5 - 5 = 0 \) leaves left. When the wind blows the second time, half of the remaining leaves fall, which is 0, and then 5 more. Thus there are \( 0 - 0 - 5 = - 5 \) leaves left. This does not make sense, so we eliminate this choice. (C) If there are 15 leaves at the start, when the wind blows the first time, half of the leaves fall, which is 7.5, and then 5 more. Thus there are \( 15 - 7.5 - 5 = 2.5 \) leaves left. When the wind blows the second time, it blows down half of the remaining leaves, which is 1.25, and then 5 more. Thus there are \( 2.5 - 1.25 - 5 = -3.75 \) leaves left. Wrong choice. (D) If there are 30 leaves at the start, when the wind blows the first time, half of the leaves fall, which is 5, and then 5 more. Thus there are \( 30 - 15 - 5 = 10 \) leaves left. When the wind blows the second time, half of the remaining leaves fall, which is 5, and then 5 more. Thus there are \( 10 - 5 - 5 = 0 \) leaves left. This is the correct answer. (E) If there are 50 leaves at the start, when the wind blows the first time, half of the leaves fall, which is 25, and then 5 more. Thus there are \( 50- 25 - 5 = 20 \) leaves left. When the wind blows the second time, it blows down half of the remaining leaves, which is 10, and then 5 more. Thus there are \( 20 - 10 - 5 = 5 \) leaves left. But we are told that no leaves remain on the tree. Wrong choice. Thus, the answer is (D). Solution 2: We can solve this problem by working backwards. At the end, we are left with 0 leaves. Just before that, 5 leaves fall, so there were 5 leaves on the tree. Just before that, half of the leaves fall, so there are \(2\cdot 5=10\) leaves on the tree. Just before that, 5 leaves fall, so there are \(10+5=15\) leaves on the tree. And just before that, half of the leaves fall, so there are \(2\cdot 15=30\) leaves on the tree. Incorrect Choices: (A) This is the number of leaves that are blown down right at the end. (B) This is the number of leaves that are on the tree before the second wind. (C) This is the number of leaves that are on the tree just after the first wind blows half of the leaves down. (E) This choice is offered to confused you.
There are several people in a meeting, and each pair of them shake hands. If there are a total of 210 handshakes, how many people are in the meeting? (A)\(\ \ \) 14 (B)\(\ \ \) 15 (C)\(\ \ \) 18 (D)\(\ \ \) 20 (E)\(\ \ \) 21 Show Answer Correct Answer: E Solution: If there are \(n\) people at the meeting, each person will shake hands with \(n-1\) other people (a person cannot shake hands with himself). So, there are \(n\cdot (n-1)\) ways we can pair the people at the meeting. But, the number of handshakes isn't equal to the number of ways we can pair the people. Since the handshake between person A and person B is the same as the handshake between person B and person A, we must divide \(n\cdot (n-1)\) by 2 so as to not count each handshake twice. Let's analyze each answer choice. (A) If there are 14 people, there will be \( \frac{14 \times 13 } { 2} = 91 \) handshakes. Wrong choice. (B) If there are 15 people, there will be \( \frac{15 \times 14 } { 2} = 105 \) handshakes. Wrong choice. (C) If there are 18 people, there will be \( \frac{18 \times 17 } { 2} = 153 \) handshakes. Wrong choice. (D) If there are 20 people, there will be \( \frac{20 \times 19 } { 2} = 190 \) handshakes. Wrong choice. (E) If there are 21 people, there will be \( \frac{21 \times 20 } { 2} = 210 \) handshakes. Correct answer. Incorrect Choices: (A) , (B) , (C) , and (D) The solution explains how to eliminate these choices.
Problem Loading...
Note Loading...
Set Loading...
Leadership & Flow
Global Research Program and Network
What is ‘trial and error’?
Trial and error is not a method of finding the best solution, nor a method of finding all solutions. It is a problem-solving technique that is used simply to find a solution.
‘ So, you screwed up? ’ – How many times have you heard this criticism when you failed? What this question often implies is that you are a loser , someone who lost its reputation or having difficulty managing a situation or a relationship. Hidden, this question sends the message: ‘You are not good enough’ .
No wonder, that it is inherently coded in us to fear failure and be ashamed when we fail. Even though every one fails sometimes in life, as failure is part of a learning process we cannot avoid. If we look deep inside, everybody would agree, that the failures that make us stronger and unique.
Studies show that the most successful people failed a lot. When testing concepts, ideas, solving new problems in the real world one cannot avoid making mistakes, or fall flat sometimes. Successful managers, leaders, and entrepreneurs all understand the importance of failure, indeed they are mastered in failing but:
- they have learned to move on; and
- learned from their mistakes, in other words, they truly understand the meaning of trial and error.
To me, failure and self-development come hand in hand. It is not a question if: ‘ Will you fail or not?’ , but rather ‘ What level of risk you take?’ when you fail . Successful managers and leaders suggest testing concepts, ideas in a low-risk environment to minimize risk associated with failure.
So, why not to use this ‘formula’ in teaching management and leadership?
Computer games and online simulations, such as FLIGBY offer to test and master leadership and management skills in a safe, low-risk environment and allows to experiment.
By playing FLIGBY the players can face with some of their lacking abilities, management or leadership skills. It is almost certain that they will fail someway or another as leaders/managers while playing the Game. Odd it might be, but true that failing in the Game motivates the player to play more in order to test and try out other alternative management and leadership styles and skills in order to succeed.
This is how FLIGBY unconsciously teaches new management and leadership skills and styles, teaches to accept failure as part of a learning process, and master in people management skills.
After all our whole life is based on ‘ trail and error’ , but no one can take away the experience we collect through truly experiencing life, including the mistakes we make!
(The author of this entry is Esztella Fazekas , member of the Leadership & Flow Research Team)
Chapter 7: Thinking and Intelligence
Problem solving, learning objectives.
By the end of this section, you will be able to:
- Describe problem solving strategies
- Define algorithm and heuristic
- Explain some common roadblocks to effective problem solving
People face problems every day—usually, multiple problems throughout the day. Sometimes these problems are straightforward: To double a recipe for pizza dough, for example, all that is required is that each ingredient in the recipe be doubled. Sometimes, however, the problems we encounter are more complex. For example, say you have a work deadline, and you must mail a printed copy of a report to your supervisor by the end of the business day. The report is time-sensitive and must be sent overnight. You finished the report last night, but your printer will not work today. What should you do? First, you need to identify the problem and then apply a strategy for solving the problem.
PROBLEM-SOLVING STRATEGIES
When you are presented with a problem—whether it is a complex mathematical problem or a broken printer, how do you solve it? Before finding a solution to the problem, the problem must first be clearly identified. After that, one of many problem solving strategies can be applied, hopefully resulting in a solution.
A problem-solving strategy is a plan of action used to find a solution. Different strategies have different action plans associated with them ( [link] ). For example, a well-known strategy is trial and error . The old adage, “If at first you don’t succeed, try, try again” describes trial and error. In terms of your broken printer, you could try checking the ink levels, and if that doesn’t work, you could check to make sure the paper tray isn’t jammed. Or maybe the printer isn’t actually connected to your laptop. When using trial and error, you would continue to try different solutions until you solved your problem. Although trial and error is not typically one of the most time-efficient strategies, it is a commonly used one.
Another type of strategy is an algorithm. An algorithm is a problem-solving formula that provides you with step-by-step instructions used to achieve a desired outcome (Kahneman, 2011). You can think of an algorithm as a recipe with highly detailed instructions that produce the same result every time they are performed. Algorithms are used frequently in our everyday lives, especially in computer science. When you run a search on the Internet, search engines like Google use algorithms to decide which entries will appear first in your list of results. Facebook also uses algorithms to decide which posts to display on your newsfeed. Can you identify other situations in which algorithms are used?
A heuristic is another type of problem solving strategy. While an algorithm must be followed exactly to produce a correct result, a heuristic is a general problem-solving framework (Tversky & Kahneman, 1974). You can think of these as mental shortcuts that are used to solve problems. A “rule of thumb” is an example of a heuristic. Such a rule saves the person time and energy when making a decision, but despite its time-saving characteristics, it is not always the best method for making a rational decision. Different types of heuristics are used in different types of situations, but the impulse to use a heuristic occurs when one of five conditions is met (Pratkanis, 1989):
- When one is faced with too much information
- When the time to make a decision is limited
- When the decision to be made is unimportant
- When there is access to very little information to use in making the decision
- When an appropriate heuristic happens to come to mind in the same moment
Working backwards is a useful heuristic in which you begin solving the problem by focusing on the end result. Consider this example: You live in Washington, D.C. and have been invited to a wedding at 4 PM on Saturday in Philadelphia. Knowing that Interstate 95 tends to back up any day of the week, you need to plan your route and time your departure accordingly. If you want to be at the wedding service by 3:30 PM, and it takes 2.5 hours to get to Philadelphia without traffic, what time should you leave your house? You use the working backwards heuristic to plan the events of your day on a regular basis, probably without even thinking about it.
Another useful heuristic is the practice of accomplishing a large goal or task by breaking it into a series of smaller steps. Students often use this common method to complete a large research project or long essay for school. For example, students typically brainstorm, develop a thesis or main topic, research the chosen topic, organize their information into an outline, write a rough draft, revise and edit the rough draft, develop a final draft, organize the references list, and proofread their work before turning in the project. The large task becomes less overwhelming when it is broken down into a series of small steps.
Problem-solving abilities can improve with practice. Many people challenge themselves every day with puzzles and other mental exercises to sharpen their problem-solving skills. Sudoku puzzles appear daily in most newspapers. Typically, a sudoku puzzle is a 9×9 grid. The simple sudoku below ( [link] ) is a 4×4 grid. To solve the puzzle, fill in the empty boxes with a single digit: 1, 2, 3, or 4. Here are the rules: The numbers must total 10 in each bolded box, each row, and each column; however, each digit can only appear once in a bolded box, row, and column. Time yourself as you solve this puzzle and compare your time with a classmate.

How long did it take you to solve this sudoku puzzle? (You can see the answer at the end of this section.)
Here is another popular type of puzzle ( [link] ) that challenges your spatial reasoning skills. Connect all nine dots with four connecting straight lines without lifting your pencil from the paper:

Did you figure it out? (The answer is at the end of this section.) Once you understand how to crack this puzzle, you won’t forget.
Take a look at the “Puzzling Scales” logic puzzle below ( [link] ). Sam Loyd, a well-known puzzle master, created and refined countless puzzles throughout his lifetime (Cyclopedia of Puzzles, n.d.).

PITFALLS TO PROBLEM SOLVING
Not all problems are successfully solved, however. What challenges stop us from successfully solving a problem? Albert Einstein once said, “Insanity is doing the same thing over and over again and expecting a different result.” Imagine a person in a room that has four doorways. One doorway that has always been open in the past is now locked. The person, accustomed to exiting the room by that particular doorway, keeps trying to get out through the same doorway even though the other three doorways are open. The person is stuck—but she just needs to go to another doorway, instead of trying to get out through the locked doorway. A mental set is where you persist in approaching a problem in a way that has worked in the past but is clearly not working now.
Functional fixedness is a type of mental set where you cannot perceive an object being used for something other than what it was designed for. During the Apollo 13 mission to the moon, NASA engineers at Mission Control had to overcome functional fixedness to save the lives of the astronauts aboard the spacecraft. An explosion in a module of the spacecraft damaged multiple systems. The astronauts were in danger of being poisoned by rising levels of carbon dioxide because of problems with the carbon dioxide filters. The engineers found a way for the astronauts to use spare plastic bags, tape, and air hoses to create a makeshift air filter, which saved the lives of the astronauts.
Link to Learning
Check out this Apollo 13 scene where the group of NASA engineers are given the task of overcoming functional fixedness.
Researchers have investigated whether functional fixedness is affected by culture. In one experiment, individuals from the Shuar group in Ecuador were asked to use an object for a purpose other than that for which the object was originally intended. For example, the participants were told a story about a bear and a rabbit that were separated by a river and asked to select among various objects, including a spoon, a cup, erasers, and so on, to help the animals. The spoon was the only object long enough to span the imaginary river, but if the spoon was presented in a way that reflected its normal usage, it took participants longer to choose the spoon to solve the problem. (German & Barrett, 2005). The researchers wanted to know if exposure to highly specialized tools, as occurs with individuals in industrialized nations, affects their ability to transcend functional fixedness. It was determined that functional fixedness is experienced in both industrialized and nonindustrialized cultures (German & Barrett, 2005).
In order to make good decisions, we use our knowledge and our reasoning. Often, this knowledge and reasoning is sound and solid. Sometimes, however, we are swayed by biases or by others manipulating a situation. For example, let’s say you and three friends wanted to rent a house and had a combined target budget of $1,600. The realtor shows you only very run-down houses for $1,600 and then shows you a very nice house for $2,000. Might you ask each person to pay more in rent to get the $2,000 home? Why would the realtor show you the run-down houses and the nice house? The realtor may be challenging your anchoring bias. An anchoring bias occurs when you focus on one piece of information when making a decision or solving a problem. In this case, you’re so focused on the amount of money you are willing to spend that you may not recognize what kinds of houses are available at that price point.
The confirmation bias is the tendency to focus on information that confirms your existing beliefs. For example, if you think that your professor is not very nice, you notice all of the instances of rude behavior exhibited by the professor while ignoring the countless pleasant interactions he is involved in on a daily basis. Hindsight bias leads you to believe that the event you just experienced was predictable, even though it really wasn’t. In other words, you knew all along that things would turn out the way they did. Representative bias describes a faulty way of thinking, in which you unintentionally stereotype someone or something; for example, you may assume that your professors spend their free time reading books and engaging in intellectual conversation, because the idea of them spending their time playing volleyball or visiting an amusement park does not fit in with your stereotypes of professors.
Finally, the availability heuristic is a heuristic in which you make a decision based on an example, information, or recent experience that is that readily available to you, even though it may not be the best example to inform your decision . Biases tend to “preserve that which is already established—to maintain our preexisting knowledge, beliefs, attitudes, and hypotheses” (Aronson, 1995; Kahneman, 2011). These biases are summarized in [link] .
Please visit this site to see a clever music video that a high school teacher made to explain these and other cognitive biases to his AP psychology students.
Were you able to determine how many marbles are needed to balance the scales in [link] ? You need nine. Were you able to solve the problems in [link] and [link] ? Here are the answers ( [link] ).

Many different strategies exist for solving problems. Typical strategies include trial and error, applying algorithms, and using heuristics. To solve a large, complicated problem, it often helps to break the problem into smaller steps that can be accomplished individually, leading to an overall solution. Roadblocks to problem solving include a mental set, functional fixedness, and various biases that can cloud decision making skills.
Self Check Questions
Critical thinking questions.
1. What is functional fixedness and how can overcoming it help you solve problems?
2. How does an algorithm save you time and energy when solving a problem?
Personal Application Question
3. Which type of bias do you recognize in your own decision making processes? How has this bias affected how you’ve made decisions in the past and how can you use your awareness of it to improve your decisions making skills in the future?
1. Functional fixedness occurs when you cannot see a use for an object other than the use for which it was intended. For example, if you need something to hold up a tarp in the rain, but only have a pitchfork, you must overcome your expectation that a pitchfork can only be used for garden chores before you realize that you could stick it in the ground and drape the tarp on top of it to hold it up.
2. An algorithm is a proven formula for achieving a desired outcome. It saves time because if you follow it exactly, you will solve the problem without having to figure out how to solve the problem. It is a bit like not reinventing the wheel.
- Psychology. Authored by : OpenStax College. Located at : http://cnx.org/contents/[email protected]:1/Psychology . License : CC BY: Attribution . License Terms : Download for free at http://cnx.org/content/col11629/latest/.

Privacy Policy
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
8.2 Problem-Solving: Heuristics and Algorithms
Learning objectives.
- Describe the differences between heuristics and algorithms in information processing.
When faced with a problem to solve, should you go with intuition or with more measured, logical reasoning? Obviously, we use both of these approaches. Some of the decisions we make are rapid, emotional, and automatic. Daniel Kahneman (2011) calls this “fast” thinking. By definition, fast thinking saves time. For example, you may quickly decide to buy something because it is on sale; your fast brain has perceived a bargain, and you go for it quickly. On the other hand, “slow” thinking requires more effort; applying this in the same scenario might cause us not to buy the item because we have reasoned that we don’t really need it, that it is still too expensive, and so on. Using slow and fast thinking does not guarantee good decision-making if they are employed at the wrong time. Sometimes it is not clear which is called for, because many decisions have a level of uncertainty built into them. In this section, we will explore some of the applications of these tendencies to think fast or slow.
We will look further into our thought processes, more specifically, into some of the problem-solving strategies that we use. Heuristics are information-processing strategies that are useful in many cases but may lead to errors when misapplied. A heuristic is a principle with broad application, essentially an educated guess about something. We use heuristics all the time, for example, when deciding what groceries to buy from the supermarket, when looking for a library book, when choosing the best route to drive through town to avoid traffic congestion, and so on. Heuristics can be thought of as aids to decision making; they allow us to reach a solution without a lot of cognitive effort or time.
The benefit of heuristics in helping us reach decisions fairly easily is also the potential downfall: the solution provided by the use of heuristics is not necessarily the best one. Let’s consider some of the most frequently applied, and misapplied, heuristics in the table below.
In many cases, we base our judgments on information that seems to represent, or match, what we expect will happen, while ignoring other potentially more relevant statistical information. When we do so, we are using the representativeness heuristic . Consider, for instance, the data presented in the table below. Let’s say that you went to a hospital, and you checked the records of the babies that were born on that given day. Which pattern of births do you think you are most likely to find?
Most people think that list B is more likely, probably because list B looks more random, and matches — or is “representative of” — our ideas about randomness, but statisticians know that any pattern of four girls and four boys is mathematically equally likely. Whether a boy or girl is born first has no bearing on what sex will be born second; these are independent events, each with a 50:50 chance of being a boy or a girl. The problem is that we have a schema of what randomness should be like, which does not always match what is mathematically the case. Similarly, people who see a flipped coin come up “heads” five times in a row will frequently predict, and perhaps even wager money, that “tails” will be next. This behaviour is known as the gambler’s fallacy . Mathematically, the gambler’s fallacy is an error: the likelihood of any single coin flip being “tails” is always 50%, regardless of how many times it has come up “heads” in the past.
The representativeness heuristic may explain why we judge people on the basis of appearance. Suppose you meet your new next-door neighbour, who drives a loud motorcycle, has many tattoos, wears leather, and has long hair. Later, you try to guess their occupation. What comes to mind most readily? Are they a teacher? Insurance salesman? IT specialist? Librarian? Drug dealer? The representativeness heuristic will lead you to compare your neighbour to the prototypes you have for these occupations and choose the one that they seem to represent the best. Thus, your judgment is affected by how much your neibour seems to resemble each of these groups. Sometimes these judgments are accurate, but they often fail because they do not account for base rates , which is the actual frequency with which these groups exist. In this case, the group with the lowest base rate is probably drug dealer.
Our judgments can also be influenced by how easy it is to retrieve a memory. The tendency to make judgments of the frequency or likelihood that an event occurs on the basis of the ease with which it can be retrieved from memory is known as the availability heuristic (MacLeod & Campbell, 1992; Tversky & Kahneman, 1973). Imagine, for instance, that I asked you to indicate whether there are more words in the English language that begin with the letter “R” or that have the letter “R” as the third letter. You would probably answer this question by trying to think of words that have each of the characteristics, thinking of all the words you know that begin with “R” and all that have “R” in the third position. Because it is much easier to retrieve words by their first letter than by their third, we may incorrectly guess that there are more words that begin with “R,” even though there are in fact more words that have “R” as the third letter.
The availability heuristic may explain why we tend to overestimate the likelihood of crimes or disasters; those that are reported widely in the news are more readily imaginable, and therefore, we tend to overestimate how often they occur. Things that we find easy to imagine, or to remember from watching the news, are estimated to occur frequently. Anything that gets a lot of news coverage is easy to imagine. Availability bias does not just affect our thinking. It can change behaviour. For example, homicides are usually widely reported in the news, leading people to make inaccurate assumptions about the frequency of murder. In Canada, the murder rate has dropped steadily since the 1970s (Statistics Canada, 2018), but this information tends not to be reported, leading people to overestimate the probability of being affected by violent crime. In another example, doctors who recently treated patients suffering from a particular condition were more likely to diagnose the condition in subsequent patients because they overestimated the prevalence of the condition (Poses & Anthony, 1991).
The anchoring and adjustment heuristic is another example of how fast thinking can lead to a decision that might not be optimal. Anchoring and adjustment is easily seen when we are faced with buying something that does not have a fixed price. For example, if you are interested in a used car, and the asking price is $10,000, what price do you think you might offer? Using $10,000 as an anchor, you are likely to adjust your offer from there, and perhaps offer $9000 or $9500. Never mind that $10,000 may not be a reasonable anchoring price. Anchoring and adjustment does not just happen when we’re buying something. It can also be used in any situation that calls for judgment under uncertainty, such as sentencing decisions in criminal cases (Bennett, 2014), and it applies to groups as well as individuals (Rutledge, 1993).
In contrast to heuristics, which can be thought of as problem-solving strategies based on educated guesses, algorithms are problem-solving strategies that use rules. Algorithms are generally a logical set of steps that, if applied correctly, should be accurate. For example, you could make a cake using heuristics — relying on your previous baking experience and guessing at the number and amount of ingredients, baking time, and so on — or using an algorithm. The latter would require a recipe which would provide step-by-step instructions; the recipe is the algorithm. Unless you are an extremely accomplished baker, the algorithm should provide you with a better cake than using heuristics would. While heuristics offer a solution that might be correct, a correctly applied algorithm is guaranteed to provide a correct solution. Of course, not all problems can be solved by algorithms.
As with heuristics, the use of algorithmic processing interacts with behaviour and emotion. Understanding what strategy might provide the best solution requires knowledge and experience. As we will see in the next section, we are prone to a number of cognitive biases that persist despite knowledge and experience.
Key Takeaways
- We use a variety of shortcuts in our information processing, such as the representativeness, availability, and anchoring and adjustment heuristics. These help us to make fast judgments but may lead to errors.
- Algorithms are problem-solving strategies that are based on rules rather than guesses. Algorithms, if applied correctly, are far less likely to result in errors or incorrect solutions than heuristics. Algorithms are based on logic.
Bennett, M. W. (2014). Confronting cognitive ‘anchoring effect’ and ‘blind spot’ biases in federal sentencing: A modest solution for reforming and fundamental flaw. Journal of Criminal Law and Criminology , 104 (3), 489-534.
Kahneman, D. (2011). Thinking, fast and slow. New York, NY: Farrar, Straus and Giroux.
MacLeod, C., & Campbell, L. (1992). Memory accessibility and probability judgments: An experimental evaluation of the availability heuristic. Journal of Personality and Social Psychology, 63 (6), 890–902.
Poses, R. M., & Anthony, M. (1991). Availability, wishful thinking, and physicians’ diagnostic judgments for patients with suspected bacteremia. Medical Decision Making, 11 , 159-68.
Rutledge, R. W. (1993). The effects of group decisions and group-shifts on use of the anchoring and adjustment heuristic. Social Behavior and Personality, 21 (3), 215-226.
Statistics Canada. (2018). Ho micide in Canada, 2017 . Retrieved from https://www150.statcan.gc.ca/n1/en/daily-quotidien/181121/dq181121a-eng.pdf
Tversky, A., & Kahneman, D. (1973). Availability: A heuristic for judging frequency and probability. Cognitive Psychology, 5 , 207–232.
Psychology - 1st Canadian Edition Copyright © 2020 by Sally Walters is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book

Advantages and Disadvantages of Solving a Problem Through Trial and Error
Back to: Learning and Teaching – Unit 2
Introduction
E.L. Thorndike propounded the theory of trial and error. He believes that behavior is the result of a response to a stimulus. According to him, learning is associated with responses, impressions, and a sense of action. Thorndike’s views are often referred to as connectionism as it believes in the connection of stimulus and response. Thorndike referred to it as connecting and selecting or trial and error theory since learning results from repetition. Thorndike proposed three laws of learning namely, the law of readiness, the law of effect, and the law of exercise.
The disadvantages of solving a problem through the trial and error method are as follows:
Creative Approach
Trial and error is considered to be a creative approach for solving tasks because it makes individuals use both the right and left hemispheres of their brain.
Less Time Consuming
The trial and method consume less time to solve tasks that do not have a great depth of difficulty.
Division of Tasks
The trial and error method involves the division of tasks which makes it possible for individuals to search for a quick solution.
Allows one to Learn
It is not possible to get everything right on the first try due to trial and error is a good method to encourage learning.
Mistakes are Allowed
In the trial and error theory, mistakes are a part of learning. When people make errors, they can reflect on them and make changes to get better.
Disadvantages
Consumes a lot of energy.
The trial and error method can be a bit energy-consuming since it uses a lot of energy due to which it can limit the quantity of learning.
Emphasizes Rote Learning
The theory includes the use of repetition and therefore, encourages rote learning.
Ineffective for Bright Learners
Learners who do not focus on rote memorization and learn things quickly may find this method ineffective.
Ineffective for Higher Classes
The theory fails to provide adequate guidance for learners belonging to higher classes.
Losing Popularity
The trial and error method has been losing popularity in the modern age due to which its use might not be relevant in the future.
The trial and error method has various benefits for solving tasks but there are certain limitations that impact its prevalence.


- Spanish – español
Approaches to Learning: Problem Solving

Birth to 9 months
7 months to 18 months, 16 months to 24 months, 21 months to 36 months.
Children attempt a variety of strategies to accomplish tasks, overcome obstacles, and find solutions to tasks, questions, and challenges.
Children build the foundation for problem-solving skills through nurturing relationships, active exploration, and social interactions. In infancy, children learn that their actions and behaviors have an effect on others. For example, children cry to signal hunger to their caregivers; in turn, their caregivers feed them. Caregivers’ consistent responses to children’s communication attempts teach children the earliest forms of problem solving. Children learn that they have the ability to solve a problem by completing certain actions. Children build this knowledge and translate it into how they interact and problem-solve in future situations.
Children discover that their actions and behaviors also have an impact on objects. They learn that certain actions produce certain results. For example, children may bang a toy over and over as they notice the sound that it makes. This behavior is intentional and purposeful; children learn that they have the ability to make something happen. As they get older, children will experiment with different ways to solve problems, such as moving puzzle pieces in different ways to place them correctly. They will use trial and error to find solutions to the tasks they are working on, and use communication skills to ask or gesture for help from caregivers.
By 36 months, children are able to decrease the amount of trial and error they use when solving problems. Their cognitive skills are maturing and they are able to use logic and reasoning when working through challenges. Increased attention allows children to focus for longer periods of time when working through challenges. Children still depend on their caregivers for help, but are likely to attempt problem solving on their own before asking someone for help.
Children are building the foundation for problem solving through active exploration and social interaction.
Indicators for children include:
- Focuses on getting a caregiver’s attention through the use of sounds, cries, gestures, and facial expressions
- Enjoys repeating actions, e.g., continues to drop toy from highchair after it is picked up by a caregiver or sibling
- Communicates the need for assistance through verbal and/or nonverbal cues, e.g., pointing, reaching, vocalizing
Strategies for interaction
- Respond thoughtfully and promptly to the child’s attempts for attention
- Provide interesting and age-appropriate toys and objects for exploration
- Engage and interact with the child frequently during the day
Children begin to discover that certain actions and behaviors can be solutions to challenges and obstacles they encounter. Children also recognize how to engage their caregiver(s) to assist in managing these challenges.
- Repeats actions over and over again to figure out how an object works
- Begins to recognize that certain actions will draw out certain responses, e.g., laughing and smiling will often result in an adult responding in the same manner
- Attempts a variety of physical strategies to reach simple goals, e.g., pulls the string of a toy train to move it closer or crawls to get a ball that has rolled away
- Demonstrate how to try things in different ways and encourage the child to do the same, e.g., using a plastic bucket as a drum
- Gently guide the child in discovering and exploring, while allowing him or her enough independence to try new things
- Respond thoughtfully and promptly to the child’s communication attempts
Children have an enhanced capacity to solve challenges they encounter through the use of objects and imitation. Children may take on a more autonomous role during this stage, yet, reach out to caregiver(s) in most instances.
- Imitates a caregiver’s behavior to accomplish a task, e.g., attempts to turn a doorknob
- Increases ability to recognize and solve problems through active exploration, play, and trial and error, e.g., tries inserting a shape at different angles to make it fit in a sorter
- Uses objects in the environment to solve problems, e.g., uses a pail to move numerous books to the other side of the room
- Uses communication to solve problems, e.g., runs out of glue during an art project and gestures to a caregiver for more
- Validate and praise the child’s attempts to find solutions to challenges
- Narrate while assisting the child in figuring out a solution, e.g., “Let’s try to turn the puzzle piece this way”
- Provide the child with opportunities to solve problems with and without your help; minimize the possibility for the child to become frustrated
- Respond to the child’s communication efforts
Children begin to discriminate which solutions work, with fewer trials. Children increasingly become more autonomous and will attempt to first overcome obstacles on their own or with limited support from caregiver(s).
- Asks for help from a caregiver when needed
- Begins to solve problems with less trial and error
- Refuses assistance, e.g., calls for help but then pushes a hand away
- Shows pride when accomplishing a task
- Uses increasingly refined skills while solving problems, e.g., uses own napkin to clean up a spill without asking an adult for help
- Follow the child’s lead and pay attention to his or her cues when assisting in a task
- Share in the child’s joy and accomplishments
- Model and narrate problem-solving skills through play
- Provide the child with blocks of uninterrupted time to work on activities
- Be available for the child and recognize when he or she needs guidance
Real World Story
Sebastian, who is 25 months old, is engaged in a fine-motor activity provided by his caregiver. He is holding large, plastic tweezers and is attempting to use them to pick up big, fuzzy balls off a plastic plate and move them into a plastic cup. He is holding the plastic tweezers in one hand, and holds the plate steady on the table. He repeatedly tries to use one hand, but cannot pinch the tweezers tightly enough to pick up one of the balls. Sebastian pauses, looks around, and picks up the balls with his thumb and forefinger.
Holding the plastic tweezers in one hand and the ball in the other, Sebastian places the ball in the tweezers and then pinches it closed. He moves it over to the plastic cup and drops it inside. He then grabs another fuzzy ball and places it in the tweezers. Again, he pinches it tightly and transfers it to the cup. Sebastian engages in the same method until all the fuzzy balls on his plate are now inside his cup. Once he is done, he empties out the cup onto the plate and starts all over. After successfully completing the process again, he holds out his full cup toward his caregiver, Maria. She sees him, smiles, and gives two thumbs up. Sebastian grabs his cup and walks over to her. He hands Maria the cup and walks away from the table.
Discover how this Real World Story is related to:
- Self-Regulation: Foundation of Development Attention Regulation
- Developmental Domain 1: Social & Emotional Development Self-Concept
- Developmental Domain 2: Physical Development & Health Fine Motor
- Developmental Domain 2: Physical Development & Health Perceptual
- Developmental Domain 4: Cognitive Development Logic & Reasoning
THIS EXAMPLE HIGHLIGHTS how children use physical trial and error to solve problems. Sebastian is not successful in his initial attempts to pick up the small objects with his tweezers. However, he pauses to think about possible ways to work on this problem, and then changes his process. Instead of pinching the tweezers to grab the ball, he places the ball in between the tweezers and then pinches it closed. This is easier for him, as he is still developing the fine motor skills necessary to be able to complete this task. Once he realizes he is successful in accomplishing his goal, he engages in this task until he has finished placing every ball on his plate into the cup. He then repeats the activity all over again. Sebastian’s ability to successfully problem solve builds his self-confidence. Maria’s positive acknowledgment of his accomplishment further supports his social and emotional development. A positive self-concept and increasing self-confidence is very important for Sebastian’s future learning and overall healthy development.
Discover how Problem Solving is related to:
- Self-Regulation: Foundation of Development Emotional Regulation
- Developmental Domain 1: Social & Emotional Development Relationship with Adults
- Developmental Domain 4: Cognitive Development Memory
Related Resources
7.3 Problem Solving
Learning objectives.
By the end of this section, you will be able to:
- Describe problem solving strategies
- Define algorithm and heuristic
- Explain some common roadblocks to effective problem solving and decision making
People face problems every day—usually, multiple problems throughout the day. Sometimes these problems are straightforward: To double a recipe for pizza dough, for example, all that is required is that each ingredient in the recipe be doubled. Sometimes, however, the problems we encounter are more complex. For example, say you have a work deadline, and you must mail a printed copy of a report to your supervisor by the end of the business day. The report is time-sensitive and must be sent overnight. You finished the report last night, but your printer will not work today. What should you do? First, you need to identify the problem and then apply a strategy for solving the problem.
Problem-Solving Strategies
When you are presented with a problem—whether it is a complex mathematical problem or a broken printer, how do you solve it? Before finding a solution to the problem, the problem must first be clearly identified. After that, one of many problem solving strategies can be applied, hopefully resulting in a solution.
A problem-solving strategy is a plan of action used to find a solution. Different strategies have different action plans associated with them ( Table 7.2 ). For example, a well-known strategy is trial and error . The old adage, “If at first you don’t succeed, try, try again” describes trial and error. In terms of your broken printer, you could try checking the ink levels, and if that doesn’t work, you could check to make sure the paper tray isn’t jammed. Or maybe the printer isn’t actually connected to your laptop. When using trial and error, you would continue to try different solutions until you solved your problem. Although trial and error is not typically one of the most time-efficient strategies, it is a commonly used one.
Another type of strategy is an algorithm. An algorithm is a problem-solving formula that provides you with step-by-step instructions used to achieve a desired outcome (Kahneman, 2011). You can think of an algorithm as a recipe with highly detailed instructions that produce the same result every time they are performed. Algorithms are used frequently in our everyday lives, especially in computer science. When you run a search on the Internet, search engines like Google use algorithms to decide which entries will appear first in your list of results. Facebook also uses algorithms to decide which posts to display on your newsfeed. Can you identify other situations in which algorithms are used?
A heuristic is another type of problem solving strategy. While an algorithm must be followed exactly to produce a correct result, a heuristic is a general problem-solving framework (Tversky & Kahneman, 1974). You can think of these as mental shortcuts that are used to solve problems. A “rule of thumb” is an example of a heuristic. Such a rule saves the person time and energy when making a decision, but despite its time-saving characteristics, it is not always the best method for making a rational decision. Different types of heuristics are used in different types of situations, but the impulse to use a heuristic occurs when one of five conditions is met (Pratkanis, 1989):
- When one is faced with too much information
- When the time to make a decision is limited
- When the decision to be made is unimportant
- When there is access to very little information to use in making the decision
- When an appropriate heuristic happens to come to mind in the same moment
Working backwards is a useful heuristic in which you begin solving the problem by focusing on the end result. Consider this example: You live in Washington, D.C. and have been invited to a wedding at 4 PM on Saturday in Philadelphia. Knowing that Interstate 95 tends to back up any day of the week, you need to plan your route and time your departure accordingly. If you want to be at the wedding service by 3:30 PM, and it takes 2.5 hours to get to Philadelphia without traffic, what time should you leave your house? You use the working backwards heuristic to plan the events of your day on a regular basis, probably without even thinking about it.
Another useful heuristic is the practice of accomplishing a large goal or task by breaking it into a series of smaller steps. Students often use this common method to complete a large research project or long essay for school. For example, students typically brainstorm, develop a thesis or main topic, research the chosen topic, organize their information into an outline, write a rough draft, revise and edit the rough draft, develop a final draft, organize the references list, and proofread their work before turning in the project. The large task becomes less overwhelming when it is broken down into a series of small steps.
Everyday Connection
Solving puzzles.
Problem-solving abilities can improve with practice. Many people challenge themselves every day with puzzles and other mental exercises to sharpen their problem-solving skills. Sudoku puzzles appear daily in most newspapers. Typically, a sudoku puzzle is a 9×9 grid. The simple sudoku below ( Figure 7.7 ) is a 4×4 grid. To solve the puzzle, fill in the empty boxes with a single digit: 1, 2, 3, or 4. Here are the rules: The numbers must total 10 in each bolded box, each row, and each column; however, each digit can only appear once in a bolded box, row, and column. Time yourself as you solve this puzzle and compare your time with a classmate.
Here is another popular type of puzzle ( Figure 7.8 ) that challenges your spatial reasoning skills. Connect all nine dots with four connecting straight lines without lifting your pencil from the paper:
Take a look at the “Puzzling Scales” logic puzzle below ( Figure 7.9 ). Sam Loyd, a well-known puzzle master, created and refined countless puzzles throughout his lifetime (Cyclopedia of Puzzles, n.d.).
Pitfalls to Problem Solving
Not all problems are successfully solved, however. What challenges stop us from successfully solving a problem? Imagine a person in a room that has four doorways. One doorway that has always been open in the past is now locked. The person, accustomed to exiting the room by that particular doorway, keeps trying to get out through the same doorway even though the other three doorways are open. The person is stuck—but they just need to go to another doorway, instead of trying to get out through the locked doorway. A mental set is where you persist in approaching a problem in a way that has worked in the past but is clearly not working now.
Functional fixedness is a type of mental set where you cannot perceive an object being used for something other than what it was designed for. Duncker (1945) conducted foundational research on functional fixedness. He created an experiment in which participants were given a candle, a book of matches, and a box of thumbtacks. They were instructed to use those items to attach the candle to the wall so that it did not drip wax onto the table below. Participants had to use functional fixedness to overcome the problem ( Figure 7.10 ). During the Apollo 13 mission to the moon, NASA engineers at Mission Control had to overcome functional fixedness to save the lives of the astronauts aboard the spacecraft. An explosion in a module of the spacecraft damaged multiple systems. The astronauts were in danger of being poisoned by rising levels of carbon dioxide because of problems with the carbon dioxide filters. The engineers found a way for the astronauts to use spare plastic bags, tape, and air hoses to create a makeshift air filter, which saved the lives of the astronauts.
Link to Learning
Check out this Apollo 13 scene about NASA engineers overcoming functional fixedness to learn more.
Researchers have investigated whether functional fixedness is affected by culture. In one experiment, individuals from the Shuar group in Ecuador were asked to use an object for a purpose other than that for which the object was originally intended. For example, the participants were told a story about a bear and a rabbit that were separated by a river and asked to select among various objects, including a spoon, a cup, erasers, and so on, to help the animals. The spoon was the only object long enough to span the imaginary river, but if the spoon was presented in a way that reflected its normal usage, it took participants longer to choose the spoon to solve the problem. (German & Barrett, 2005). The researchers wanted to know if exposure to highly specialized tools, as occurs with individuals in industrialized nations, affects their ability to transcend functional fixedness. It was determined that functional fixedness is experienced in both industrialized and nonindustrialized cultures (German & Barrett, 2005).
In order to make good decisions, we use our knowledge and our reasoning. Often, this knowledge and reasoning is sound and solid. Sometimes, however, we are swayed by biases or by others manipulating a situation. For example, let’s say you and three friends wanted to rent a house and had a combined target budget of $1,600. The realtor shows you only very run-down houses for $1,600 and then shows you a very nice house for $2,000. Might you ask each person to pay more in rent to get the $2,000 home? Why would the realtor show you the run-down houses and the nice house? The realtor may be challenging your anchoring bias. An anchoring bias occurs when you focus on one piece of information when making a decision or solving a problem. In this case, you’re so focused on the amount of money you are willing to spend that you may not recognize what kinds of houses are available at that price point.
The confirmation bias is the tendency to focus on information that confirms your existing beliefs. For example, if you think that your professor is not very nice, you notice all of the instances of rude behavior exhibited by the professor while ignoring the countless pleasant interactions he is involved in on a daily basis. Hindsight bias leads you to believe that the event you just experienced was predictable, even though it really wasn’t. In other words, you knew all along that things would turn out the way they did. Representative bias describes a faulty way of thinking, in which you unintentionally stereotype someone or something; for example, you may assume that your professors spend their free time reading books and engaging in intellectual conversation, because the idea of them spending their time playing volleyball or visiting an amusement park does not fit in with your stereotypes of professors.
Finally, the availability heuristic is a heuristic in which you make a decision based on an example, information, or recent experience that is that readily available to you, even though it may not be the best example to inform your decision . Biases tend to “preserve that which is already established—to maintain our preexisting knowledge, beliefs, attitudes, and hypotheses” (Aronson, 1995; Kahneman, 2011). These biases are summarized in Table 7.3 .
Watch this teacher-made music video about cognitive biases to learn more.
Were you able to determine how many marbles are needed to balance the scales in Figure 7.9 ? You need nine. Were you able to solve the problems in Figure 7.7 and Figure 7.8 ? Here are the answers ( Figure 7.11 ).
As an Amazon Associate we earn from qualifying purchases.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute OpenStax.
Access for free at https://openstax.org/books/psychology-2e/pages/1-introduction
- Authors: Rose M. Spielman, William J. Jenkins, Marilyn D. Lovett
- Publisher/website: OpenStax
- Book title: Psychology 2e
- Publication date: Apr 22, 2020
- Location: Houston, Texas
- Book URL: https://openstax.org/books/psychology-2e/pages/1-introduction
- Section URL: https://openstax.org/books/psychology-2e/pages/7-3-problem-solving
© Jan 6, 2024 OpenStax. Textbook content produced by OpenStax is licensed under a Creative Commons Attribution License . The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
Boosting of Thoughts: Trial-and-Error Problem Solving with Large Language Models
The reasoning performance of Large Language Models (LLMs) on a wide range of problems critically relies on chain-of-thought prompting, which involves providing a few chain of thought demonstrations as exemplars in prompts. Recent work, e.g., Tree of Thoughts, has pointed out the importance of exploration and self-evaluation in reasoning step selection for complex problem solving. In this paper, we present Boosting of Thoughts (BoT), an automated prompting framework for problem solving with LLMs by iteratively exploring and self-evaluating many trees of thoughts in order to acquire an ensemble of trial-and-error reasoning experiences, which will serve as a new form of prompting to solve the complex problem. Starting from a simple prompt without requiring examples, BoT iteratively explores and evaluates a large collection of reasoning steps, and more importantly, uses error analysis obtained from the LLM on them to explicitly revise prompting, which in turn enhances reasoning step generation, until a final answer is attained. Our experiments with GPT-4 and Llama2 across extensive complex mathematical problems demonstrate that BoT consistently achieves higher or comparable problem-solving rates than other advanced prompting approaches.
1 Introduction
Large language models (LLMs) with the autoregressive paradigm have gained remarkable performance across various tasks due to their potential reasoning ability Brown et al. ( 2020 ); Lewkowycz et al. ( 2022 ) . The guarantee of such ability in complex tasks heavily relies on chain-of-thought (CoT) Wei et al. ( 2022 ) prompting, which provides step-by-step reasoning examples. This approach suggests that the reasoning ability can be elicited through a chain of thoughts, where a thought serves as an intermediate step toward problem solving.
Thus, subsequent studies Fu et al. ( 2022 ); Wang et al. ( 2022 ); Yao et al. ( 2023 ); Besta et al. ( 2023 ) , especially Tree-of-Thought (ToT) Yao et al. ( 2023 ) , have been proposed to improve CoT. To guarantee effectiveness, the prompt of these approaches generally includes human annotations on one specific task. Such a reliance limits their scalability. Recent work that either employs a double-check with LLMs to improve answers Paul et al. ( 2023 ); Weng et al. ( 2023 ); Madaan et al. ( 2023 ) or boosts prompts based on feedback Zheng et al. ( 2023 ); Zhang et al. ( 2023a ); Hou et al. ( 2023 ); Pitis et al. ( 2023 ) has demonstrated significant promise. The existing literature generally tends to discard ineffective thoughts from the prompt. However, humans typically can continuously learn from errors by carefully analyzing them to gain experience, thereby gradually improving performance. We therefore ask: whether the thought generation of LLMs can dispense with human annotation and mimic such a problem-solving way of humans to achieve effective reasoning across various tasks?

This paper proposes a novel framework, shown in Fig. 1 , referred to as the Boosting of Thoughts (BoT), which achieves the boosting mechanism that embraces aggregation and experience , thereby enabling the progressive refinement of unreliable reasoning steps (weak thoughts) by learning from errors to eventually solve various problems. Starting with a simple prompt without human annotations for LLMs, BoT may get weak thoughts. With aggregation , BoT is capable of deriving a more logical and effective thought chain from them, thereby guiding the subsequent refinement. This guidance in our framework is achieved by tuning the prompt with experience , which is the detailed error reports, advice, and instructions of each reasoning step obtained by exploiting LLMs to analyze the aggregated chain. When such experience accumulates in the prompt, it gradually leads to stronger thoughts.
Specifically, BoT implements such a Boosting mechanism as an experience -driven iteration process, as shown in Fig. 1 . In each iteration, for a given prompt, BoT builds massive simplistic thought structures in parallel with the LLM. We select the tree structure as in ToT Yao et al. ( 2023 ) but significantly modify it to weighted binary trees with various growth strategies for our boosting purposes. After extracting the root-to-leaf branch with the highest score per tree, the aggregation component of BoT is performed to aggregate them into one single thought chain. Subsequently, this chain is evaluated by the same LLM to gain the experience , which is added to the prompt as guidance for the thought generation in the next iteration.
Our contributions can be summarized in three folds. First, instead of generating more complicated structures for thoughts with well-designed prompts, this paper shows that it is possible to rely solely on a simple initial prompt, as weak thoughts can be refined progressively based on previous experience toward solving problems. Second, to achieve such a boosting mechanism, we propose Boosting of Thoughts (BoT), a novel framework that performs an experience -driven iterative process. Due to starting from a simple prompt, BoT is scalable across various tasks. While guaranteeing effectiveness, BoT is fast as it builds simplistic thought structures in parallel and converges to a solution after a few iterations. Finally, with GPT-4 and LlamaV2, we evaluate the performance of BoT on complex mathematical problems. Finally, relying on GPT-4 OpenAI ( 2023 ) and LlamaV2 Touvron et al. ( 2023 ) , we evaluate the performance of BoT on complex mathematical problems. The problem-solving rates indicate that BoT, employing binary tree thought structures, significantly surpasses the current state-of-the-art on the GSM8K and AQuA while achieving the second-best results on other datasets. Especially on the new challenging task, Game of 24 Yao et al. ( 2023 ) , BoT is 9.7 % percent 9.7 9.7\% 9.7 % higher than the leading approach ToT. Our BoT thus demonstrates that, through enhancing the prompt by accumulating error analysis of ineffective thought chains and the corresponding advice, even without human annotation, LLMs are scalable across various tasks while sustaining high performance.
2 Related Work
Multi-Step Reasoning . The prominent work Chain-of-thought (CoT) prompting Wei et al. ( 2022 ) shows that step-by-step reasoning behaviors from LLMs can be elicited by providing intermediate reasoning steps, termed thoughts, within the prompt for each question, as also supported by Self-Consistency Wang et al. ( 2022 ) and a series of CoT-based work Zhou et al. ( 2022 ); Fu et al. ( 2022 ) . The recent work, Tree of Thoughts (ToT) Yao et al. ( 2023 ) , converts the sequential reasoning process into a tree structure, in which each thought (node) may consider previous reasoning paths to produce multiple next-step thoughts. With such backtracking and expanded exploration during reasoning, ToT performs well on problems that even challenge GPT-4 OpenAI ( 2023 ) . Considering its high ability, the base thought structure of BoT largely utilizes this tree thought structure ToT. And, thanks to the boosting framework, the tree structure generated in each iteration of BoT is binary and shallow instead of the ToT’s complex tree, in which each node corresponds to massive child nodes. However, the base structure is not restricted to ToT. In contrast, BoT is flexible as the base thought structure can be either ToT, GoT Besta et al. ( 2023 ) , or CR Zhang et al. ( 2023b ) , where Graph of Thoughts (GoT) Besta et al. ( 2023 ) is the most recent work that expands the thought structure into a graph format. This paper will only focus on the ToT as the base thought structure and leave the usage of GoT for future work.
Automatic Prompting . Releasing humans from task-specific prompts attracts much attention Shin et al. ( 2020 ) . To guarantee the reasoning ability of LLMs, conventional CoT Wei et al. ( 2022 ) relies on human priors to manually generate task-specific demonstrations as the prompt. However, the zero-shot CoT Kojima et al. ( 2022 ) shows that even without hand-crafted examples, by simply adding “Let’s think step by step” to the prompt, LLMs are able to perform step-by-step reasoning toward accurate answers. These insights have spurred a series of subsequent studies. Auto-CoT Zhang et al. ( 2022 ) eliminates manual efforts by retrieving usable reasoning chains generated by zero-shot CoT. Active-Prompt Diao et al. ( 2023 ) first measures the uncertainty of a set of questions and thus selects only the uncertain ones to be annotated by humans. ToT Yao et al. ( 2023 ) can also reduce manual efforts, but for each task, it still requires experts to provide possible next-step thoughts in the prompt. Our paper introduces a novel boosting approach for manual-free prompting. Starting with a simple prompt, BoT iteratively enhances it based on the analysis of LLMs on thoughts.
Prompt Engineering via Feedback . Utilizing responses from LLMs to the input prompt as feedback for further prompt revisions has garnered much attention. Those who continuously revise the given prompt based on evaluation descriptions from LLMs aim to gain an accurate answer Weng et al. ( 2023 ) . Using a similar higher-level idea of our paper, SELF-REFINE Madaan et al. ( 2023 ) proposes an iterative self-refinement algorithm to let the LLM produce feedback for its output for further refinement. PHP Zheng et al. ( 2023 ) simplifies this process by directly adding a solution from the previous answer as a hint to the subsequent prompt. REFINER Paul et al. ( 2023 ) is also related to our paper as it evaluates each reasoning step as feedback to produce a more reasonable one. Another line of research explores ensembles, particularly leveraging the boosting mechanism Freund et al. ( 1996 ) to refine the prompt using feedback from a set of examples. They adjust the prompt to focus on the unsolved problems in the previous iteration by either adding a few shot examples uncertain in the previous Pitis et al. ( 2023 ) or relying on a feedback-reflect-refine process Zhang et al. ( 2023a ) . APO Pryzant et al. ( 2023 ) iteratively refines a prompt, using the performance of the prior prompt to form a natural language for optimization. These works prove the effectiveness of the boosting mechanism in prompt engineering. However, our work is the first to highlight the importance of error analysis in enhancing the prompt toward generating effective reasoning chains. The proposed BoT extends this insight to implement an automated prompting framework by iteratively accumulating an ensemble of trial-and-error reasoning experiences in the prompt.
3 Boosting of Thoughts
3.1 background.
The objective of prompt engineering is to design a prompt 𝕀 𝕀 {\mathbb{I}} blackboard_I containing multiple language sequences, such that with this prompt as input, a pre-trained large language model (LLM) denoted as p θ subscript 𝑝 𝜃 p_{\theta} italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT parameterized by θ 𝜃 \theta italic_θ , can obtain the desired language sequence y 𝑦 y italic_y . Thus, the standard Input-Output (IO) can be formulated as y ∼ p θ ( y | 𝕀 ( X , Q ) ) similar-to 𝑦 subscript 𝑝 𝜃 conditional 𝑦 𝕀 𝑋 𝑄 y\sim p_{\theta}\left(y|{\mathbb{I}}\left(X,Q\right)\right) italic_y ∼ italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( italic_y | blackboard_I ( italic_X , italic_Q ) ) in which 𝕀 ( ⋅ ) 𝕀 ⋅ {\mathbb{I}}\left(\cdot\right) blackboard_I ( ⋅ ) means that the prompt wraps task instructions X 𝑋 X italic_X and the corresponding question Q 𝑄 Q italic_Q .
The prompt can be designed in a more delicate way to guide the LLM toward solving a problem in a step-by-step manner. Each intermediate reasoning step is denoted as z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT (a.k.a thought ). CoT Wei et al. ( 2022 ) provides few-shot examples with the answer of each example containing a chain of thought z 1 … n subscript 𝑧 1 … 𝑛 z_{1...n} italic_z start_POSTSUBSCRIPT 1 … italic_n end_POSTSUBSCRIPT . This leads to y ∼ p θ ( y | 𝕀 ( [ z 1 … n ] N , X , Q ) ) similar-to 𝑦 subscript 𝑝 𝜃 conditional 𝑦 𝕀 superscript delimited-[] subscript 𝑧 1 … 𝑛 𝑁 𝑋 𝑄 y\sim p_{\theta}\left(y|{\mathbb{I}}\left(\left[z_{1...n}\right]^{N},X,Q\right% )\right) italic_y ∼ italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( italic_y | blackboard_I ( [ italic_z start_POSTSUBSCRIPT 1 … italic_n end_POSTSUBSCRIPT ] start_POSTSUPERSCRIPT italic_N end_POSTSUPERSCRIPT , italic_X , italic_Q ) ) where N 𝑁 N italic_N is the number of examples included in the prompt.
Instead of pre-preparing examples in the prompt, a more adaptive way is to design prompts to guide the LLMs to gradually generate the thought z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT during the reasoning process. This can be formalized as z i ∼ p θ ( z i | 𝕀 ( z 1 … i − 1 , X , Q ) ) similar-to subscript 𝑧 𝑖 subscript 𝑝 𝜃 conditional subscript 𝑧 𝑖 𝕀 subscript 𝑧 1 … 𝑖 1 𝑋 𝑄 z_{i}\sim p_{\theta}\left(z_{i}|{\mathbb{I}}\left(z_{1...{i-1}},X,Q\right)\right) italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT ∼ italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT | blackboard_I ( italic_z start_POSTSUBSCRIPT 1 … italic_i - 1 end_POSTSUBSCRIPT , italic_X , italic_Q ) ) . Finally, the solution is formalized as y ∼ p θ ( y | 𝕀 ( z 1 … n , X , Q ) ) similar-to 𝑦 subscript 𝑝 𝜃 conditional 𝑦 𝕀 subscript 𝑧 1 … 𝑛 𝑋 𝑄 y\sim p_{\theta}\left(y|{\mathbb{I}}\left(z_{1...n},X,Q\right)\right) italic_y ∼ italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( italic_y | blackboard_I ( italic_z start_POSTSUBSCRIPT 1 … italic_n end_POSTSUBSCRIPT , italic_X , italic_Q ) ) . The representative approach, ToT Yao et al. ( 2023 ) , further extends this sequential reasoning steps into a tree structure in which C 𝐶 C italic_C next-step thoughts can be generated. Thus, the thought strcuture can be chain or tree.
3.2 Framework

In this paper, we argue that the prompt can be enhanced by continuously collecting the analysis of LLMs on those ineffective thoughts – wrong reasoning steps in a chain of thought. Therefore, even a simple prompt, such as 𝕀 ( X , Q ) 𝕀 𝑋 𝑄 {\mathbb{I}}\left(X,Q\right) blackboard_I ( italic_X , italic_Q ) , potentially leading to ineffective thoughts, can be progressively refined by relying on such analysis to gain powerful thoughts toward the solution.
We propose Boosting of Thoughts (BoT), an automated prompting framework incorporating, which achieves prompt boosting with an experience -driven iteration process commencing with a simple prompt . As summarized in Fig. 2 , each iteration t 𝑡 t italic_t of BoT includes three stages. TThe Thought Structures Generation stage is able to fully explore reasoning chains generated by LLMs with the input prompt 𝕀 t superscript 𝕀 𝑡 {\mathbb{I}}^{t} blackboard_I start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT . In the second stage, these thought structures are aggregated to form a reasoning chain, which is to be analyzed by LLMs in the third stage to produce feedback containing error reports and detailed revision advice. Combining the aggregated reasoning chain with the feedback results in a new experience , denoted as 𝐅 t superscript 𝐅 𝑡 \mathbf{F}^{t} bold_F start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT . Thus, the prompt is enhanced by accumulating these experiences 𝐅 1 … t superscript 𝐅 1 … 𝑡 \mathbf{F}^{1...t} bold_F start_POSTSUPERSCRIPT 1 … italic_t end_POSTSUPERSCRIPT over iterations.
Simple Prompt . For any task, in iteration t = 0 𝑡 0 t=0 italic_t = 0 , we create a simple initial prompt 𝕀 0 ( S , X , Q , 𝐅 0 , { G i } ) superscript 𝕀 0 𝑆 𝑋 𝑄 superscript 𝐅 0 subscript 𝐺 𝑖 {\mathbb{I}}^{0}\left(S,X,Q,\mathbf{F}^{0},\left\{G_{i}\right\}\right) blackboard_I start_POSTSUPERSCRIPT 0 end_POSTSUPERSCRIPT ( italic_S , italic_X , italic_Q , bold_F start_POSTSUPERSCRIPT 0 end_POSTSUPERSCRIPT , { italic_G start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } ) , where S 𝑆 S italic_S represents task-agnostic descriptions while the terms X 𝑋 X italic_X and Q 𝑄 Q italic_Q respectively denote the task information and the question. The experience part of the prompt is denoted as 𝐅 0 superscript 𝐅 0 \mathbf{F}^{0} bold_F start_POSTSUPERSCRIPT 0 end_POSTSUPERSCRIPT , which should be empty at the beginning. { G i } subscript 𝐺 𝑖 \left\{G_{i}\right\} { italic_G start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } is a placeholder that is waiting to be filled during building thought structures. In other words, when generating the next thought z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , { G i } subscript 𝐺 𝑖 \left\{G_{i}\right\} { italic_G start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } will be substituted with the preceding chain of thoughts z 1 . . , i − 1 z_{1..,i-1} italic_z start_POSTSUBSCRIPT 1 . . , italic_i - 1 end_POSTSUBSCRIPT .
- 𝑖 1 𝑖 subscript 𝑉 𝑖 superscript 𝕀 𝑡 𝑋 𝑄 p_{\theta}\left(z_{i}|\left(V_{i-1,i},V_{i},{\mathbb{I}}^{t},X,Q\right)\right) italic_p start_POSTSUBSCRIPT italic_θ end_POSTSUBSCRIPT ( italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT | ( italic_V start_POSTSUBSCRIPT italic_i - 1 , italic_i end_POSTSUBSCRIPT , italic_V start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , blackboard_I start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT , italic_X , italic_Q ) ) .
- 𝑖 1 𝑖 V_{i-1,i} italic_V start_POSTSUBSCRIPT italic_i - 1 , italic_i end_POSTSUBSCRIPT and V i subscript 𝑉 𝑖 V_{i} italic_V start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT values are outside the specified range [ 0.3 , 0.8 ] 0.3 0.8 \left[0.3,0.8\right] [ 0.3 , 0.8 ] .
- 𝑖 1 𝑖 \operatorname*{arg\,max}_{z_{1...n}\in\left\{{\textnormal{Z}}^{m}\right\}_{m=1% }^{M}}\sum_{i=1}^{n}V_{i}+V_{i-1,i} start_OPERATOR roman_arg roman_max end_OPERATOR start_POSTSUBSCRIPT italic_z start_POSTSUBSCRIPT 1 … italic_n end_POSTSUBSCRIPT ∈ { Z start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT } start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_M end_POSTSUPERSCRIPT end_POSTSUBSCRIPT ∑ start_POSTSUBSCRIPT italic_i = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_n end_POSTSUPERSCRIPT italic_V start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT + italic_V start_POSTSUBSCRIPT italic_i - 1 , italic_i end_POSTSUBSCRIPT to choose the best one as z ¯ 1 … n subscript ¯ 𝑧 1 … 𝑛 \overline{z}_{1...n} over¯ start_ARG italic_z end_ARG start_POSTSUBSCRIPT 1 … italic_n end_POSTSUBSCRIPT from M 𝑀 M italic_M thought structures. This algorithm is fast but may lead to an unreasonable chain that is hard to guide the following refinement.
- 𝑗 1 𝑗 \overline{z}_{1}=\operatorname*{arg\,max}_{z_{j}\in\left\{z^{m}_{1}\right\}_{m% =1}^{M}}V_{j}+V_{j-1,j} over¯ start_ARG italic_z end_ARG start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT = start_OPERATOR roman_arg roman_max end_OPERATOR start_POSTSUBSCRIPT italic_z start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT ∈ { italic_z start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 end_POSTSUBSCRIPT } start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_M end_POSTSUPERSCRIPT end_POSTSUBSCRIPT italic_V start_POSTSUBSCRIPT italic_j end_POSTSUBSCRIPT + italic_V start_POSTSUBSCRIPT italic_j - 1 , italic_j end_POSTSUBSCRIPT . Subsequently, to obtain z ¯ i subscript ¯ 𝑧 𝑖 \overline{z}_{i} over¯ start_ARG italic_z end_ARG start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT for z ¯ i − 1 subscript ¯ 𝑧 𝑖 1 \overline{z}_{i-1} over¯ start_ARG italic_z end_ARG start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT , BoT searches all thoughts where the previous step is z ¯ i − 1 subscript ¯ 𝑧 𝑖 1 \overline{z}_{i-1} over¯ start_ARG italic_z end_ARG start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT in { Z m } m = 1 M superscript subscript superscript Z 𝑚 𝑚 1 𝑀 \left\{{\textnormal{Z}}^{m}\right\}_{m=1}^{M} { Z start_POSTSUPERSCRIPT italic_m end_POSTSUPERSCRIPT } start_POSTSUBSCRIPT italic_m = 1 end_POSTSUBSCRIPT start_POSTSUPERSCRIPT italic_M end_POSTSUPERSCRIPT .
𝑡 1 {\mathbb{I}}^{t+1} blackboard_I start_POSTSUPERSCRIPT italic_t + 1 end_POSTSUPERSCRIPT as input prompt for the LLM to gain the final answer.
4 Experiments
Datasets . Experiments are performed on benchmark datasets with diverse mathematical problems, including MMLU Hendrycks et al. ( 2021a ) , SVAMP Patel et al. ( 2021 ) , GSM8K Cobbe et al. ( 2021 ) , AQuA Ling et al. ( 2017 ) and MATH Hendrycks et al. ( 2021b ) . Besides, we include a challenging mathematical reasoning task, Game of 24 Yao et al. ( 2023 ) , where the goal is to use four numbers and basic arithmetic operations (addition, subtraction, multiplication, and division) to obtain 24 in 1 1 1 1 equation. Thus, the solution includes 3 3 3 3 intermediate steps.
Competitors . Apart from the benchmark approach, standard Input-output (IO), the comparison approaches include Chain-of-thought (CoT) Wei et al. ( 2022 ) , CoT-SC Wang et al. ( 2022 ) and Complex CoT Fu et al. ( 2022 ) , in which the input prompt contains a few-shot examples ( 8 8 8 8 ) with human annotations. Also, BoT is also compared with related works, such as Tree of thoughts (ToT) Yao et al. ( 2023 ) with the breadth limit 5 5 5 5 , Progressive-Hint Prompting (PHP) Zheng et al. ( 2023 ) , and the state-of-the-art CSV Zhou et al. ( 2023 ) .
Settings . If not explicitly stated, BoT, in all experiments, performs T = 10 𝑇 10 T=10 italic_T = 10 iterations of running and builds M = 15 𝑀 15 M=15 italic_M = 15 thought structures, each being a weighted binary tree because this tends to achieve optimal results. Besides, for those benchmark datasets, we set the depth of the tree to be 5 5 5 5 while the corresponding depth in Game of 24 is 3 3 3 3 . BoT+CoT means our simple prompt includes 5 5 5 5 examples from CoT Wei et al. ( 2022 ) . In the ablation study, when no experience is accumulated in BoT, 8 8 8 8 examples of CoT will be provided in the prompt.
Metrics . All experiments report the Solve Rate (%) of the task as the evaluation results. To extract target answers from the output z ¯ 1 … n T subscript superscript ¯ 𝑧 𝑇 1 … 𝑛 \overline{z}^{T}_{1...n} over¯ start_ARG italic_z end_ARG start_POSTSUPERSCRIPT italic_T end_POSTSUPERSCRIPT start_POSTSUBSCRIPT 1 … italic_n end_POSTSUBSCRIPT of BoT, we specifically set the formatted description of the answer for LLMs. For commonly used datasets, the desired answer format is “The answer is: .” For the Game of 24, we utilize “Step idx, Current set: , Selected two numbers: , Operation: , Computed new number: , Remaining numbers: , New set: ”. Thus, we directly compare the ground truth with the number presented in the new set. Following ToT Yao et al. ( 2023 ) , we report the Solving Rate across 100 100 100 100 hard games as the metric.
Methods No need Human Annotation Datasets Average SVAMP GSM8K AQuA MATH SOTA ✗ 93.7 97 79.9 84.3 88.7 Standard ✓ 68.7 87.1 40.6 42.5 59.7 CoT ✗ 77.6 92 74.0 48.93 73.1 Zero-shot CoT ✓ 74.3 89.6 73.2 47.7 71.2 Complex-CoT ✗ 90.5 94.9 77.5 50.4 78.3 PHP Complex-CoT ✗ 91.9 95.5 79.9 53.9 80.3 BoT ✓ 92.7 ( ↓ ↓ \downarrow ↓ 1) 97.1 ( ↑ ↑ \uparrow ↑ 0.1) 81.4 ( ↑ ↑ \uparrow ↑ 2.5) 62.5 ( ↓ ↓ \downarrow ↓ 21.8) 83.7 ( ↓ ↓ \downarrow ↓ 7.6) BoT + CoT ✗ 94.9 ( ↑ ↑ \uparrow ↑ 1.2) 98.7 ( ↑ ↑ \uparrow ↑ 1.7) 84.9 ( ↑ ↑ \uparrow ↑ 5) 66.3 ( ↓ ↓ \downarrow ↓ 18) 86.2 ( ↓ ↓ \downarrow ↓ 2.5)

4.1 Main Results
The primary experimental results are summarized in Table. 1 and Fig. 3 , where we present insights into the overall performance of BoT. Our findings indicate that the proposed BoT with Boosting mechanism 1). obtains competitive problem-solving rates in most datasets without human annotations; 2). is capable of reaching a new state-of-the-art on GSM8K and AQuA when provided with CoT examples. However, experimental results also demonstrate that BoT heavily relies on experience , thus is sensitive to the ability of LLMs.
Specifically, in Table. 1 , BoT, starting from a simple initial prompt and performing basic chatting, eventually obtains a GSM8K solve rate 0.1 % percent 0.1 0.1\% 0.1 % higher than the current state-of-the-art (SOTA) CSV Zhou et al. ( 2023 ) , which heavily relies on code interpreter of GPT-4. Considering AQuA , BoT is 2.5 % percent 2.5 2.5\% 2.5 % higher than SOTA. This demonstrates that by adding error analysis and advice to the prompt without human annotations, LLMs are able to perform well on complex reasoning. The main reason is that a simple prompt can be iteratively refined by accumulating prior experience towards accurate problem-solving. After including CoT examples in the prompt, BoT+CoT outperforms SOTA by 1.3 % percent 1.3 1.3\% 1.3 % on average in GSM8K and AQuA datasets. We argue that the CoT examples can be regarded as the success cases in the experience , directly guiding the subsequent thought structures generation of BoT. Thus, cooperating with the iteration refinement, BoT+CoT reaches a new SOTA. It also deserves to show that because BoT can gradually collect analysis of various reasoning chains (bad or good) as experience , it is consistently close to the BoT+CoT. However, BoT and BoT+CoT, especially BoT, are at least 18 % percent 18 18\% 18 % lower than SOTA in MATH . This observation means weak LLMs may not perform well with BoT due to their lower ability to analyze reasoning chains for an effective experience , as supported by Fig. 3 .
Fig. 3 presents that with BoT, GPT-4 and Llama2 are respectively improved by 11.6 % percent 11.6 11.6\% 11.6 % and 4.4 % percent 4.4 4.4\% 4.4 % on average in three datasets. The two numbers show a clear trend that when the LLM is weaker, BoT’s performance drops significantly. With powerful GPT-4, as presented in Fig. 3 , BoT and BoT-CoT behave similarly to those shown in Table. 1 . Additionally, their performance escalates along a similar trend as the number of trees varies from 1 1 1 1 to 20 20 20 20 . As Llama2 is weaker, BoT is unable to benefit from its analysis to perform the experience -driven iteration process, which is particularly shown by Fig. 3 (a). When provided with valid success cases, i.e., 5-shots, BoT, through progressive refinement, can still help Llama2 to solve more problems than the baseline even though the improvement is limited.
4.2 Game of 24
![[Uncaptioned image]](https://arxiv.org/x9.png "trial and error of problem solving")
t 𝑡 t italic_t -th iteration Two numbers Arithmetic operation New number set Experience Judgement 2, 8 multiplication 16, 7, 9 The new set does not bring us closer to the target of 24. Try other numbers and operations. 𝐅 1 superscript 𝐅 1 \mathbf{F}^{1} bold_F start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT 9, 7 addition 7, 16, 16 This step does not follow the rules of combining the remaining numbers and the obtained new number into a new set. Adjust the new set. Possible but more subsequent steps are required 16, 7 multiplication 16, 112 Too many numbers in the new set. More steps are required to reach the target of 24. 9, 7 addition 16, 2, 8 The “Evaluation Score: 0.5” is low. Increase the score. 𝐅 5 superscript 𝐅 5 \mathbf{F}^{5} bold_F start_POSTSUPERSCRIPT 5 end_POSTSUPERSCRIPT 16, 8 addition 2, 24 It is not possible to further manipulate the numbers to reach 24. Choose different numbers. Possible but should revise some steps 2, 24 subtraction 22 The new set is not correct. Can choose other two numbers. 𝐅 8 superscript 𝐅 8 \mathbf{F}^{8} bold_F start_POSTSUPERSCRIPT 8 end_POSTSUPERSCRIPT 9, 7 addition 16, 2, 8 - Possible 16, 2 multiplication 32, 8 - 32, 8 subtraction 24 -
Due to the hardness of the Game of 24 problem, GPT-4 and Llama2 both perform badly on this task, even incorporating the CoT, and CoT-SC approaches. The llama2 model even fails to follow the correct rules of addressing the problem, making the solve rate even lower. Especially when applying BoT, which relies on the experience , to Llama2, all results are lower than 5 % percent 5 5\% 5 % without significant improvement. Thus, we only report the performance of BoT with GPT-4. To maintain a fair comparison, we follow the settings proposed by ToT Yao et al. ( 2023 ) .
As shown in Table 2, BoT without human annotations is 9.7 % percent 9.7 9.7\% 9.7 % higher than ToT, which relies on one example showing all possible next steps. Besides, BoT+CoT, which contains 5 CoT shots in the initial prompt, is 1.2 % percent 1.2 1.2\% 1.2 % higher than BoT. Such a close performance between BoT and BoT+CoT is attributed to the boosting mechanism, which progressively revises weak thoughts, as discussed in subsection 4.1 . Adopting an experience -driven iterative process, BoT exhibits enhanced performance as the number of trees M 𝑀 M italic_M and the number of iterations T 𝑇 T italic_T increment. Also shown by Fig. 4 , compared to BoT+CoT, BoT relies more on M 𝑀 M italic_M and T 𝑇 T italic_T as it requires to collect experience from a better thought chain or longer iterations. Another observation is that when enabling ToT to operate iteratively with the prompt enriched by experience , the problem-solving rate escalates from 72.5 % percent 72.5 72.5\% 72.5 % in the initial iteration to 80.2 % percent 80.2 80.2\% 80.2 % by the 10 10 10 10 -th iteration. This demonstrates that experience – the analysis of previous reasoning chains can be used by LLMs to significantly improve the solve rate. However, the score obtained by ToT is still 3.5 % percent 3.5 3.5\% 3.5 % lower than BoT. This is attributed to the fact that the aggregation stage of BoT will produce the most representative reasoning chain in the current iteration, thus leading to more meaningful experience to enhance the prompt. We verify this in the ablation study section.
To better present how BoT learns from errors and previous advice, we show in Table 3 that GPT-4 is able to avoid previous errors and produce more specific advice with the increase of iteration and eventually obtain the correct solution. In the first iteration, with the simple prompt, LLMs even make a mistake in following the task rules as the new set is wrong in step 3. After analyzing, it presents correct advice on this mistake. However, the analysis at the initial iteration is vague, such as “try other numbers and operations”. After five iterations, BoT aggregates multiple such analyses, deriving a more potent prompt, making the LLMs select the right numbers 9 9 9 9 and 7 7 7 7 . Also, the advice is more concrete and useful. The advice for this right selection is to increase the corresponding evaluation score. Through the continuous accumulation such experiences , BoT progressively refines the prompt, culminating in the direct generation of a correct solution in the 8 8 8 8 -th iteration.
4.3 Ablation Study
Experience 𝐅 1 … t superscript 𝐅 1 … 𝑡 \mathbf{F}^{1…t} bold_F start_POSTSUPERSCRIPT 1 … italic_t end_POSTSUPERSCRIPT Accumulation Type Game of 24 AQuA Issues Advice Replace Add BoT (Best first) BoT (Greedy) BoT (No) BoT (Best first) BoT (Greedy) BoT (No) ✓ ✓ ✓ 81.2 83.7 67.1 78 81.4 56.2 74.7 78.2 70 47.3 56.8 44.9 ✓ ✓ 72.8 74.1 70.2 52.4 62.7 46.3 ✓ ✓ 69.2 70.7 67.6 54.1 60 40.3 ✓ ✓ 74.9 76.9 72.7 68.3 74.2 71.9 ✓ ✓ 77.9 80 72.4 73.6 77 64.1
Experience consistently leads to thought revision, but too much can have the opposite effect. When the prompt accumulates issues and advice by the “adding” type, both aggregation strategies can lead to high solve rates. Maintaining a complete experience is important for revising thoughts, especially for the AQuA dataset, which includes wider mathematical reasoning problems. However, BoT (No), which does not perform aggregation but directly uses all reasoning chains from generated trees, suffers the worst performance in all cases, especially when the experience accumulation type is “adding”. As BoT builds 15 15 15 15 trees each iteration, putting them all together into a prompt may cover core information, not to mention that most such experiences are invalid or harmful.
Advice is more important to generate thoughts than others. In all cases of Table 4 , BoT variations that embrace advice as experience achieve the top solve rate. For example, with the same “adding” type, when the experience does not contain advice, the performance drops by more than 10 % percent 10 10\% 10 % and 20 % percent 20 20\% 20 % in Game of 24 and AQuA , respectively. On the contrary, including issues in the experience serves as an auxiliary mechanism for performance improvement. Only by cooperating issues can the BoT with advice gain the best solve rate; for example, the number grows by 4.4 % percent 4.4 4.4\% 4.4 % for BoT (Greedy) in AQuA .
Greedy aggregation can be the only required choice for performance purposes. As compared to the Best-first that selects one from existing thought chains and no aggregation that maintains all thought chains, greedy aggregation adaptively merges tree structures into one better thought chain that may not exist in the current iteration. By doing so, LLM is able to perform a more meaningful analysis on a stronger thought chain, thus producing important experiences to enhance the prompt. As shown in Table 4 , once the Greedy aggregation is used, BoT improves by more than 2 % percent 2 2\% 2 % in all cases. In AQuA , containing more math problems, this number is even 10 % percent 10 10\% 10 % . Besides, as our discussion in Fig. 4 , ToT with a similar experience-driven boosting mechanism reaches 80 % percent 80 80\% 80 % but still lags behind the BoT. This may be attributed to the inability to execute the greedy aggregation within its singular tree structure.
5 Conclusion
This paper verified that a simple prompt can be enhanced by gradually accumulating error analysis on its generated thoughts to address complex tasks. We have proposed a novel framework, the Boosting of Thoughts (BoT), to implement such progressive prompt enhancement for effective thought generation with an experience -driven iteration process. Iteratively exploring and self-evaluating the generated simplistic trees of thoughts enables a simple initial prompt to be gradually enhanced by an ensemble of trial-and-error reasoning experiences, resulting in accurate solutions. Our extensive experiments demonstrated that BoT is capable of achieving state-of-the-art on multiple benchmark datasets while outperforming the alternative leading approach in Game of 24, which is a challenging mathematical reasoning task.
- Besta et al. (2023) Maciej Besta, Nils Blach, Ales Kubicek, Robert Gerstenberger, Lukas Gianinazzi, Joanna Gajda, Tomasz Lehmann, Michal Podstawski, Hubert Niewiadomski, Piotr Nyczyk, et al. Graph of thoughts: Solving elaborate problems with large language models. arXiv preprint arXiv:2308.09687 , 2023.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems , 33:1877–1901, 2020.
- Chen & Guestrin (2016) Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd acm sigkdd international conference on knowledge discovery and data mining , pp. 785–794, 2016.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 , 2021.
- Diao et al. (2023) Shizhe Diao, Pengcheng Wang, Yong Lin, and Tong Zhang. Active prompting with chain-of-thought for large language models. arXiv preprint arXiv:2302.12246 , 2023.
- Freund et al. (1996) Yoav Freund, Robert E Schapire, et al. Experiments with a new boosting algorithm. In icml , volume 96, pp. 148–156. Citeseer, 1996.
- Fu et al. (2022) Yao Fu, Hao Peng, Ashish Sabharwal, Peter Clark, and Tushar Khot. Complexity-based prompting for multi-step reasoning. arXiv preprint arXiv:2210.00720 , 2022.
- Hendrycks et al. (2021a) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR) , 2021a.
- Hendrycks et al. (2021b) Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874 , 2021b.
- Hou et al. (2023) Bairu Hou, Joe O’connor, Jacob Andreas, Shiyu Chang, and Yang Zhang. Promptboosting: Black-box text classification with ten forward passes. In International Conference on Machine Learning , pp. 13309–13324. PMLR, 2023.
- Ke et al. (2017) Guolin Ke, Qi Meng, Thomas Finley, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, and Tie-Yan Liu. Lightgbm: A highly efficient gradient boosting decision tree. Advances in neural information processing systems , 30, 2017.
- Kojima et al. (2022) Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. arXiv preprint arXiv:2205.11916 , 2022.
- Lewkowycz et al. (2022) Aitor Lewkowycz, Anders Andreassen, David Dohan, Ethan Dyer, Henryk Michalewski, Vinay Ramasesh, Ambrose Slone, Cem Anil, Imanol Schlag, Theo Gutman-Solo, et al. Solving quantitative reasoning problems with language models. arXiv preprint arXiv:2206.14858 , 2022.
- Ling et al. (2017) Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. Program induction by rationale generation: Learning to solve and explain algebraic word problems. arXiv preprint arXiv:1705.04146 , 2017.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-refine: Iterative refinement with self-feedback. arXiv preprint arXiv:2303.17651 , 2023.
- OpenAI (2023) OpenAI. Gpt-4 technical report. arXiv preprint arXiv:2303.08774 , 2023.
- Patel et al. (2021) Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are nlp models really able to solve simple math word problems? arXiv preprint arXiv:2103.07191 , 2021.
- Paul et al. (2023) Debjit Paul, Mete Ismayilzada, Maxime Peyrard, Beatriz Borges, Antoine Bosselut, Robert West, and Boi Faltings. Refiner: Reasoning feedback on intermediate representations. arXiv preprint arXiv:2304.01904 , 2023.
- Pitis et al. (2023) Silviu Pitis, Michael R Zhang, Andrew Wang, and Jimmy Ba. Boosted prompt ensembles for large language models. arXiv preprint arXiv:2304.05970 , 2023.
- Pryzant et al. (2023) Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimization with ”gradient descent” and beam search. arXiv preprint arXiv:2305.03495 , 2023.
- Shin et al. (2020) Taylor Shin, Yasaman Razeghi, Robert L Logan IV, Eric Wallace, and Sameer Singh. Autoprompt: Eliciting knowledge from language models with automatically generated prompts. arXiv preprint arXiv:2010.15980 , 2020.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 , 2023.
- Wang et al. (2022) Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. Self-consistency improves chain of thought reasoning in language models. arXiv preprint arXiv:2203.11171 , 2022.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems , 35:24824–24837, 2022.
- Weng et al. (2023) Yixuan Weng, Minjun Zhu, Fei Xia, Bin Li, Shizhu He, Kang Liu, and Jun Zhao. Large language models are better reasoners with self-verification. arXiv preprint arXiv:2212.09561 , 2023.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L Griffiths, Yuan Cao, and Karthik Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. arXiv preprint arXiv:2305.10601 , 2023.
- Zhang et al. (2023a) Chenrui Zhang, Lin Liu, Jinpeng Wang, Chuyuan Wang, Xiao Sun, Hongyu Wang, and Mingchen Cai. Prefer: Prompt ensemble learning via feedback-reflect-refine. arXiv preprint arXiv:2308.12033 , 2023a.
- Zhang et al. (2023b) Yifan Zhang, Jingqin Yang, Yang Yuan, and Andrew Chi-Chih Yao. Cumulative reasoning with large language models. arXiv preprint arXiv:2308.04371 , 2023b.
- Zhang et al. (2022) Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic chain of thought prompting in large language models. arXiv preprint arXiv:2210.03493 , 2022.
- Zhao et al. (2023) Xu Zhao, Yuxi Xie, Kenji Kawaguchi, Junxian He, and Qizhe Xie. Automatic model selection with large language models for reasoning. arXiv preprint arXiv:2305.14333 , 2023.
- Zheng et al. (2023) Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, and Yu Li. Progressive-hint prompting improves reasoning in large language models. arXiv preprint arXiv:2304.09797 , 2023.
- Zhou et al. (2023) Aojun Zhou, Ke Wang, Zimu Lu, Weikang Shi, Sichun Luo, Zipeng Qin, Shaoqing Lu, Anya Jia, Linqi Song, Mingjie Zhan, et al. Solving challenging math word problems using gpt-4 code interpreter with code-based self-verification. arXiv preprint arXiv:2308.07921 , 2023.
- Zhou et al. (2022) Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625 , 2022.
Appendix A Basic Prompts and Reasoning Pipeline of BoT
A.1 thought generation part of bot.
This subsection presents the basic prompts used by the reasoning generation of the proposed Boosting of Thoughts (BoT). For details, one can also access the source code examples/BoostingOfThought/BoT_reasoner.py .
System prompt S 𝑆 S italic_S : You are an expert on mathematical problems. Perform step-by-step reasoning toward problem solving by first learning from an ensemble of trial-and-error reasoning experiences. Such trial-and-error reasoning experience specifically contains error reports and detailed advice on how to revise historical reasoning steps. Always recall these listed experiences before generating a new reasoning step, thereby avoiding making the same mistakes and reusing correct steps to generate better reasoning steps to solve the task.
Prompt for the next thought generation :
where the task_prompt contaings the X 𝑋 X italic_X and Q 𝑄 Q italic_Q for the task, experiences is the historical reasoning experience 𝐅 1 … t superscript 𝐅 1 … 𝑡 \mathbf{F}^{1...t} bold_F start_POSTSUPERSCRIPT 1 … italic_t end_POSTSUPERSCRIPT , and chain_prompt is the { G i } subscript 𝐺 𝑖 \left\{G_{i}\right\} { italic_G start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } , which is a placeholder to be replaced by the preceding chain of thoughts z 1 . . , i − 1 z_{1..,i-1} italic_z start_POSTSUBSCRIPT 1 . . , italic_i - 1 end_POSTSUBSCRIPT of the current thought z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT .
Prompt for the thought evaluation :
where the thought is the current thought z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT .
A.2 Experience generation part of BoT
To generate feedback for the aggregated chain, LLMs use the following basic prompts.For details, one can also access the source code examples/BoostingOfThought/BoT_commenter.py
System prompt S 𝑆 S italic_S : You are an expert AI checker for math answers, dedicated to evaluating the reasoning chain generated towards addressing the mathematical problem. Judge each reasoning step of this reasoning chain by providing detailed analyses on whether the current step is a logical inference of the previous step and whether the reasoning step is beneficial to the correct solution. Provide advice and suggestions for each reasoning step with errors. Provide recommendation or rejection descriptions for each correct reasoning step.
Prompt for the feedback :
where the chain_prompt is the aggregated thought chain z ¯ 1 … n subscript ¯ 𝑧 1 … 𝑛 \overline{z}_{1...n} over¯ start_ARG italic_z end_ARG start_POSTSUBSCRIPT 1 … italic_n end_POSTSUBSCRIPT .
chain feedback format : Can this reasoning chain complete the task and reach the target correctly by executing its reasoning steps? why? Write a analysis report with conclusion under ’Anlysis Report:’.
step feedback format : For each reasoning step, please provide a detailed analysis of whether the current step is a logical inference of the previous step and whether the reasoning step is beneficial to the correct solution. For each reasoning step with errors, please provide an error report and the corresponding advice on revision. For each reasoning step, please provide recommendation or rejection descriptions. Comments should be brief and follow the format: Reasoning step ¡idx¿. Analysis report: . Advice: . Recommendation or Reject description: . .
confidence feedback format : What is your confidence score on these your evaluations and comments? Please select one value from [0.1, 0.3, 0.5, 0.7, 0.9, 1.0]. The score should be placed after ’Confidence score:’ for users to read.”
With the feedback prompt, LLMs generate reasoning experience 𝐅 t superscript 𝐅 𝑡 \mathbf{F}^{t} bold_F start_POSTSUPERSCRIPT italic_t end_POSTSUPERSCRIPT containing conclusion and analysis on the reasoning chain and each reasoning step.
A.3 Reasoning Pipeline
To facilitate the understanding of the proposed Boosting of Thoughts, we summarize the reasoning pipeline in Algorithm Table 1 . The source code for this pipeline can be found in the file examples/BoostingOfThought/BoT_core.py .
Appendix B Insights for Boosting of Thoughts
Boosting of Thoughts is not an algorithmic method but derives from our insights that the reasoning ability Fu et al. ( 2022 ) of large language models (LLMs) for addressing mathematical problems comes directly from experience, which contains the accumulation of the analysis and advice on previous mistakes. Once the prompt embraces valid historical reasoning experience to be recalled by LLMs before performing reasoning, the produced reasoning steps are generally more logical and reasonable, as shown in the comparison between Table 5 and 6 . Such insights also made us consider that LLMs do not need to rely heavily on a well-prepared prompt with human annotations (a few chain of thought demonstrations as exemplars in prompts) for each task. Yet, as LLMs are able to learn from experience, we can start from a simple prompt without examples or manually designed content to gradually collect experience during the reasoning process. Eventually, by accumulating experiences in the prompt, LLMs achieve strong reasoning toward addressing complex problems. With these insights, the Boosting of Thoughts is designed as an automated prompting framework, which iteratively collects an ensemble of trial-and-error reasoning experience for problem-solving with LLMs. We argue that the proposed BoT is not an application of LLMs to specific tasks but rather builds upon the insights that LLMs’ reasoning ability can be derived directly from the experience gained by analyzing incorrect reasoning chains, without relying on human priors.
To emphasize our insights, we share three key observations derived from applying gpt-3.5-turbo with a temperature of 0.7 and a top_p value of 0.7 on the Game of 24 dataset below.
The prompt with experience encourage LLMs to explore more logics in the responses . As shown in Table 5 , when no experience is included in the prompt, the model generates the same reasoning step five times. This observation shows one of the common problems of LLMs, which is the lack of self-motivation to explore different reasoning logic. Thus, despite their strong potential for reasoning, LLMs may become trapped in a cycle of beginning with the simplest reasoning step, which may never culminate in finding the final solution. The ’Obtained reasoning chain’ part of Table 5 presents the wrong reasoning chain. We believe that as Tree of Thoughts Yao et al. ( 2023 ) generates multiple responses as thoughts to build the nodes of the Tree, such a duplicated reasoning step may lead to the failure of this algorithm in some cases. However, in the second iteration of BoT, the introduction of experience into the prompt leads to the generation of distinct initial reasoning steps, as illustrated in Table 6 . The final reasoning chain can ultimately arrive at the correct solution by commencing with a wider range of potential logics. Weng et al. ( 2023 )
LLMs avoid making similar mistakes emphasized by the experience of the prompt . Without including experience, which contains the error analysis, in the prompt, LLMs will make many mistakes, such as deviations from the task’s rules and regressing to the initial reasoning step in the final process, as shown by Table 5 ’s ’Obtained reasoning chain’ part. After analyzing this reasoning chain and incorporating the feedback as the experience into the prompt for the second iteration of BoT, it becomes evident from Table 6 that LLMs will fully learn from the experience before engaging in reasoning. First, none of the responses replicate the same erroneous reasoning step, as illustrated by the diverse initial reasoning steps in the ’Five responses from the gpt-3.5-turbo’. Second, LLMs successfully circumvent all previously identified mistakes by rigorously adhering to task rules, eliminating incorrect reasoning, and executing logical reasoning steps. Third, it eventually leads to the correct solution for the ’1 1 4 6’ Game of 24 task. Other work, such as Weng et al. ( 2023 ); Madaan et al. ( 2023 ); Zheng et al. ( 2023 ) , also highlighted the importance of enhancing the prompt with the feedback, which is self-evaluation of previous answers. Nevertheless, BoT is the pioneering work founded on the insight that embracing error analysis for learning empowers LLMs to attain formidable reasoning capabilities.
Without human annotations, LLMs automatically organize an effective reasoning chain toward solving complex problems based on experience containing error analysis. . BoT is the pioneering initiative that proposes an automated prompting framework, leveraging the insight that LLMs can acquire effective reasoning skills for problem-solving solely through error analysis and guidance, all without the need for human annotations. As shown in Table 5 , which shows the first iteration of BoT, the initial prompt only contains the basic task guidance and the question without any in-context learning examples like what in CoT. Even though the reasoning chain obtained by LLMs with such a prompt contains numerous errors and invalid reasoning steps, its error analysis and advice can be included as the experience in the input prompt to benefit the reasoning for the second iteration, as shown in Table 6 . It can be observed that with no prior human guidance on correct reasoning procedures, LLMs can acquire knowledge from experience that includes error analysis and guidance from previously generated reasoning chains, leading to a progressive improvement in reasoning for problem-solving.
Therefore, our BoT provides long-term guidance for research as it exposes the importance of recalling error analysis and advice when enabling LLMs to generate effective reasoning processes for complex tasks. With these insights, the research of prompt engineering on inducing the reasoning ability of LLMs can focus on how to generate experience instead of introducing more human priors.
Appendix C Thought Structures Generation
BoT is an automated prompting framework that iteratively accumulates the experience derived from the analysis of reasoning chains. Consequently, BoT is generalized to various thought generation methods and LLMs capable of generating and evaluating reasoning steps. And the performance of BoT depends on the effectiveness of its thought generation structure. Thus, BoT utilizes the tree of thoughts (ToT) Yao et al. ( 2023 ) , the most recent structure, as its base model to generate reasoning chains in each iteration. As mentioned in the main paper, the base thought generation model can also be the Graph of Thoughts (GoT) Besta et al. ( 2023 ) , i.e., BoT with GoT. However, due to time constraints and the fact that the current GoT has not been applied to mathematical problems, BoT design exclusively embraces ToT. Furthermore, when employed as the base model within a boosting mechanism, thought structures in each iteration can remain lightweight. Ultimately, the proposed BoT generates heterogeneous tree structures, with each tree being a shallow-weighted binary tree.
C.1 Next thought generation and edge weights computation
Utilizing the Prompt for the next thought generation discussed in Section A , LLMs can generate the next possible thought for the reasoning step z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT by incorporating the experience 𝐅 1 … t superscript 𝐅 1 … 𝑡 \mathbf{F}^{1}...t bold_F start_POSTSUPERSCRIPT 1 end_POSTSUPERSCRIPT … italic_t and replacing { G i } subscript 𝐺 𝑖 \left\{G_{i}\right\} { italic_G start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT } with z 1 . . , i − 1 z_{1..,i-1} italic_z start_POSTSUBSCRIPT 1 . . , italic_i - 1 end_POSTSUBSCRIPT . For a reasoning step z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT , LLMs utilize Prompt for the thought evaluation to generate the evaluation score as the edge weight between z i subscript 𝑧 𝑖 z_{i} italic_z start_POSTSUBSCRIPT italic_i end_POSTSUBSCRIPT and z i − 1 subscript 𝑧 𝑖 1 z_{i-1} italic_z start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT . For a detailed procedure, the source code is available in examples/BoostingOfThought/BoT_reasoner.py . In a direct example of BoT applied to the ’3 5 6 8’ in the Game of 24 , using gpt-3.5-turbo, Table 7 and Table 8 present the thought generation while the Table 9 show how to compute the computation.
C.2 The Necessity of Heterogeneous Tree Structures
Heterogeneity extends the reasoning search space, thus increasing the convergence speed . When different trees are constructed for distinct purposes, such as exploration with a level-wise strategy or exploitation with a leaf-wise strategy, and are based on LLMs with varying configurations for being random or deterministic, the generation of reasoning steps and the resulting reasoning chains can exhibit significant differences, effectively covering a wider range of reasoning possibilities. For example, in one iteration, when LLMs generate the next thought with more confidence, similar thoughts will be explored continuously; otherwise, LLMs with more randomness tend to generate diverse thoughts. It is generally challenging to predict whether deterministic reasoning or randomness can contribute to the solution. Therefore, incorporating heterogeneity by mixing different types and logical reasoning steps allows us to comprehensively explore the reasoning space within a single iteration, ultimately facilitating subsequent iterations. In the ablation study, we compare the performance of BoT between Heterogeneous and homogeneous tree structures.
Heterogeneity reduces the possibility of producing invalid or wrong reasoning chains, thus enhancing the robustness . Unlike heterogeneity, in trees with homogeneous settings, individual trees tend to generate thoughts following consistent logic and build reasoning chains with the same tree structures. Then, when the logic is wrong or the underlying structure is invalid for the current question, reasoning chains obtained by all trees of BoT in each iteration can only contain noisy and incorrect reasoning steps. Even after aggregating them to obtain a more refined reasoning chain for evaluation in BoT, the experience may still diverge significantly from providing suitable problem-solving suggestions. Therefore, designing tree thought structures to be heterogeneous can be a way to reduce the possibility that there are no effective reasoning chains to be evaluated for subsequent BoT’s iteration. Therefore, designing tree thought structures to be heterogeneous can help mitigate the possibility of having no effective reasoning chains available for evaluation in subsequent BoT iterations. This enhancement of robustness allows BoT to tackle questions of varying difficulty levels.
Appendix D Thought Structures Aggregation
After completing the reasoning in Heterogeneous Tree Structures, the aggregation process of BoT first extracts the best reasoning chain from each tree and then combines them using either the Best-First or Greedy aggregation method into a single reasoning chain. More details of these two aggregation methods can be accessed in the source code examples/BoostingOfThought/BoT_aggregator.py .
As shown in the first block of the algorithm 2 , the Best-first aggregation is a straightforward approach for aggregation as it directly extracts the chain with the highest sum of edge weights. This method is fast and stable. It typically guarantees competitive performance as the subsequent experience is able to be generated by analyzing the best chain among obtained reasoning chains. However, it can only select existing chains without making effective adjustments. Greedy aggregation is more advanced as it combines reasoning steps from different chains to produce a new, better reasoning chain with the highest edge weights. The greedy aggregation procedure in algorithm 2 contains two steps. It first collects reasoning steps that are similar to the aggregated reasoning step z i − 1 subscript 𝑧 𝑖 1 z_{i-1} italic_z start_POSTSUBSCRIPT italic_i - 1 end_POSTSUBSCRIPT . Thus, the next aggregated reasoning step is selected from the next reasoning steps of this collected set by maximizing the edge weights. And, s i m 𝑠 𝑖 𝑚 sim italic_s italic_i italic_m is the similarity function that uses LLMs to assess the percentage of identical words and mathematical numbers shared between two paragraphs. 0.7 0.7 0.7 0.7 is an empirical threshold obtained from experiments.
Appendix E Influence of the bad feedback
The feedback obtained by evaluating the aggregated reasoning chain with LLMs may include analysis of limited usefulness and completely incorrect conclusions and error reports. This issue typically arises due to the nature of LLMs, which are language models and do not inherently verify the accuracy of the generated text. Additionally, the capabilities of LLMs, such as gpt-3.5-turbo, are constrained when used as validators for mathematical problems.
A direct example is presented in Table 7 . The analysis report concludes that ”The final result obtained in Step 3 is 80, which is mathematically equal to 24.” Even worse, the experience further contains that ”the reasoning chain is correct” and ”No errors were found in the reasoning steps.”. Using the prompt with this experience as the input in the first iteration, BoT is misled to generate wrong reasoning steps, and the corresponding aggregated chain can be seen at the beginning of Table 8 . It is evident that the aggregated chain is logically incorrect and does not adhere to any of the rules of the Game of 24 .
However, we argue that spurious feedback will not be amplified over iterations; instead, thanks to the iterative mechanism of BoT, its negative impact on the generated reasoning steps can be mitigated or even entirely rectified in subsequent iterations. The main reason is that the generated wrong reasoning steps will be further analyzed to produce new experiences to be added to the prompt. Specifically, as these reasoning steps contain obvious mistakes that are easy to identify, LLMs are prone to generating correct error analysis and providing effective advice for revisions. With this new experience included in the prompt, BoT is capable of generating correct reasoning steps. As demonstrated by the experience in Table 8 , BoT produces detailed error reports and revision suggestions, resulting in a rational thought generation process illustrated in Table 7 .
The advantage of BoT, which leverages iterations to mitigate the detrimental effects of erroneous feedback, is evident in Figure 4 . Notably, the performance of BoT exhibits consistent enhancement with an increasing number of iterations. This underscores both the significance of accumulating experience iteratively and the capacity of subsequent experiences to rectify prior errors.
Appendix F More results on MATH

In Figure 5 , we provide the solving rate of different methods in each category of the MATH dataset. The diverse range of mathematical problems in these categories poses a significantly more challenging benchmark for mathematical reasoning. Thus, the complexity and diversity of the problems in MATH require a wide spectrum of reasoning capabilities for solutions. Consequently, a detailed examination of our approach and its comparison with other methods in this context yields valuable insights.
LLMs . The experiments conducted on the MATH dataset employed prominent large language models (LLMs), namely, GPT-3.5-Turbo, hereafter abbreviated as GPT3.5, and GPT-4, denoted as GPT4 for brevity. We directly utilized the release APIs of OPENAI.
Competitors .
GPT4 ComplexCoT. This is the GPT4 model employing greedy decoding (i.e. temperature = 0) with the ComplexCoT Fu et al. ( 2022 ) prompting method. The reasoning examples utilized in the prompt for reasoning are derived from the corresponding Complex CoT publication Fu et al. ( 2022 ) . As greedy decoding is used, we do not follow the self-consistency method Wang et al. ( 2022 ) to sample reasoning paths.
GPT3.5. With the standard prompt, the GPT3.5 model is used to generate the answer.
GPT3.5 ComplexCoT. Similar to the GPT4 ComplexCoT but change the model to GPT3.5.
GPT4 PHP+ComplexCoT. This is the GPT4 model employing greedy decoding (i.e. temperature = 0) with the PHP Zheng et al. ( 2023 ) +Complex CoT Fu et al. ( 2022 ) . Specifically, in the PHP Zheng et al. ( 2023 ) framework, the Complex CoT prompt is used to generate initial base answers, from which the PHP+Complex CoT can then develop the subsequent answer generation prompts. Thus, at the beginning of the interaction, by passing a concatenation of the base prompt of Complex CoT and the current question to the LLM, the base answer can be generated. Then, relying on the Complex CoT prompts revised into the PHP version with additional hint sentences, the progressive-hint prompting framework is performed on this base answer to update the hint over interactions to generate the right answer. We refer to this as the PHP+Complex CoT corresponding to the Progressive-Hint Prompting Complex CoT (PHP-Complex CoT) in the original work Zheng et al. ( 2023 ) . The number of shots from Complex CoT is 8 8 8 8 .
GPT4 BoT wo/ experience. The GPT4 model is used to perform reasoning with the proposed BoT framework without the experience accumulation. The basic settings of BoT follow those presented in the main paper. Therefore, after one iteration, the aggregated chain will be used as the solution.
GPT4 BoT. The GPT4 is used to perform reasoning with the full version of BoT as shown in the main paper.
GPT4 BoT + CoT. Apart from the BoT framework, 5 5 5 5 reasoning examples from the CoT Wei et al. ( 2022 ) publication are included in the prompt. Therefore, in each iteration, the prompt contains not only experience but also additional 5 5 5 5 CoT reasoning examples.
GPT3.5 BoT. Similar to the GPT4 BoT but change the model to GPT3.5.
GPT3.5 BoT (GPT4). In this experiment, we utilize the GPT3.5 to perform reasoning, thus generating thought chains in the Thought Structure Generation. However, when performing the thought evaluation and the experience generation in the aggregated Thought Chain Analysis, the GPT4 model is used to get the evaluation and the analysis feedback.
We obtain the following additional observations from the results in Figure 5 .
The top performance of BoT on challenging problems derives from the accumulation of experience . BoT-related methods, such as GPT4 BoT and GPT4 BoT + CoT, consistently achieve the highest problem-solving rate on different sub-categories of MATH . Specifically, GPT4 BoT outperforms the current best GPT4 PHP+ComplexCoT by 8.6 % percent 8.6 8.6\% 8.6 % , while GPT4 BOT + CoT is even 12.4 % percent 12.4 12.4\% 12.4 % higher. In all seven categories, GPT4 BoT is at least 0.8 % percent 0.8 0.8\% 0.8 % higher than GPT4 PHP+ComplexCoT, and the corresponding number on the Algebra problems is even 12.5 % percent 12.5 12.5\% 12.5 % . Similar for GPT3.5 BoT and GPT3.5 BoT + CoT. However, when no experience is accumulated in the BoT framework, the performance drops significantly on all mathematical problems, as shown by the GPT4 BoT wo/ experience.
In addition to experience with error analysis, including correct examples, such as simple CoT instances, is essential for improving the problem-solving efficiency of the BoT in challenging mathematical problems. . GPT4 BoT outperforms the GPT4 PHP+ComplexCoT by a large margin on the first five sub-categories of MATH problems. Nevertheless, in the domains of Precalculus and Intermediate Algebra, which demand more intricate reasoning and complex logical steps for solutions, BoT exhibits only a marginal improvement of 0.8 % percent 0.8 0.8\% 0.8 % and 2.4 % percent 2.4 2.4\% 2.4 % , respectively. These gains are limited compared to the more substantial enhancements observed in simpler problem categories. After directly adding 5 5 5 5 correct CoT examples into the prompt, GPT-4 BoT + CoT demonstrates a significant performance boost, surpassing GPT-4 BoT by 7.7 % percent 7.7 7.7\% 7.7 % and 11.5 % percent 11.5 11.5\% 11.5 % in Precalculus and Intermediate Algebra domains, respectively. This basic conclusion from these observations is that to guarantee the top performance of BoT in complex mathematical problems, relying on trial-and-error analysis to learn how to reason is not sufficient; instead, the correct answers should also be provided in the prompt for LLMs.
While GPT3.5 with BoT may initially fall behind GPT-4 CoT, leveraging GPT-4 as the evaluator and analyzer to generate experience allows GPT-3.5 BoT (GPT-4) to outperform GPT-4 Complex CoT . With the GPT3.5, which has less capacity than GPT4, as the LLM, the solving rate obtained by BoT is at least 7.7 % percent 7.7 7.7\% 7.7 % (on Algebra) lower than GPT4 ComplexCoT. It is evident that when less powerful LLMs produce lower-quality trial-and-error analyses, the BoT is unable to outperform GPT4 ComplexCoT. Thus, after using the GPT4 in the experience generation part while GPT3.5 is only used to generate reasoning steps, GPT3.5 BoT (GPT4) shows a significant improvement in all categories, leading to a solving rate of 55.8 % percent 55.8 55.8\% 55.8 % , which outperforms GPT4 ComplexCoT by 5.5 % percent 5.5 5.5\% 5.5 % and is even 1.9 % percent 1.9 1.9\% 1.9 % higher than the current state-of-the-art GPT4 PHP+ComplexCoT. These observations further demonstrate that the accumulation of experience over iterations in the prompt constitutes the primary factor contributing to the success of the BoT framework.
Appendix G Reasoning results of “Game of 24”
First, in Table 5 - Table 9 , we present the detailed prompts that BoT used during the reasoning process, thus providing a comprehensive understanding of what BoT does within each iteration. Then, starting from Table 10 , we show some exact examples containing the whole reasoning process of BoT. Following the basic settings shown in the experiment section, these experiments are obtained using BoT with the GPT-3.5-turbo model.
Appendix H Reasoning results of “GSM8K”
BoT uses similar basic prompts and the specific format as shown in Table 5 - Table 9 . Only the task prompt will be changed, as shown in Table 15 . Then, starting from Table 16 , we show some exact examples containing the whole reasoning process of BoT. Following the basic settings shown in the experiment section, these experiments are obtained using BoT with the GPT-3.5-turbo model.
To many Black Americans, the O.J. Simpson verdict was bigger than O.J. Simpson

On Oct. 3, 1995, Black residents in parts of Los Angeles spilled out onto the street, cheering and passing celebratory drinks. The world had just learned that O.J. Simpson had been acquitted of double murder.
“Everybody was running out of their house, screaming and happy,” recalled journalist and cultural critic Jasmyne Cannick, who was a teenager living near Compton when the verdict came down. “I remember that. People had been glued to their television sets” for months on end, wondering where the jury would land.
The celebratory scene in Cannick’s neighborhood that day was duplicated in Black communities across the country, as the nearly yearlong so-called Trial of the Century came to an end. Simpson, then a movie star and a beloved former football player, was acquitted of murder charges in the death of his ex-wife Nicole Brown Simpson and her friend Ron Goldman.
The reaction to the verdict was far different among white Americans, revealing the trench-like racial divisions that were roiling the nation at the time. In 1994, 22% of Black respondents to a Washington Post-ABC News poll said they thought Simpson was guilty of the charges, versus 63% of white people. As time went on, particularly after Simpson was found liable in 1997 in a civil case brought by the Brown and Goldman families, 57% of Black people in 2015 said they thought he was guilty. Eighty-three percent of white people agreed.
“White people were like ‘guilty guilty guilty’ — there were families that broke up, and family members who would not speak to each other over the O.J. Simpson case,” Cannick said. “It was as vicious as the Trump situation. People just felt so strongly one way or the other.”

With the trial’s every detail broadcast in wall-to-wall coverage on cable news — a pure anomaly at the time — Simpson’s downfall symbolized something deeper to many Black people, particularly with the 1992 L.A. riots still fresh in their minds.
“The African American community has accepted him not as an athlete or a hero, but as someone in the criminal justice system who, like them, would have been railroaded, they would say, if he had not had a Johnnie Cochran there to rescue him,” said Charles Ogletree Jr., a Harvard Law School professor who told PBS’s “Frontline” in 2005 that as Simpson became more successful, he seemed to become increasingly disjointed from Blackness. (Cochran was a key member of Simpson’s legal defense team.)
“O.J. Simpson was raceless,” said Ogletree who founded Harvard’s Charles Hamilton Houston Institute for Race and Justice and died last year. “He was not a person who spent time in African American communities. He was not a person who was deeply committed to African American values.”
Simpson, who died Wednesday at 76 from cancer, came from humble beginnings, raised in housing projects in San Francisco. He played football for the City College of San Francisco before transferring to the University of Southern California, where he was part of the 1967 national championship team. The next year he won the Heisman Trophy and was the No. 1 overall pick for the Buffalo Bills in 1969. He played in the NFL for 11 seasons and, over those years, his charm and good looks threw him further into the spotlight.

His rise on the field came as American culture was shifting, following the intense peak of the civil rights era.
“He wasn’t just a household name to sports fans, but he became a household name to all of America,” said Shemar Woods, a professor at Arizona State University, who teaches sports journalism. “He was a real celebrity. We talk about influencers in this day and age, but you might say he was one of the original influencers.”
Soon enough, he became the face of major brands like Hertz, Chevrolet and TreeSweet Orange Juice in a steady stream of commercials, ensuring his wealth and fame. Eventually, that charm led him to television and movies.
“Add in the fact that he was Black, in the late 1960s — seeing a Black face in these prominent positions,” Woods said. “Certainly the Black community looked up to him and revered him as a figure that people wanted to watch. You just didn’t see that many Black people in these positions.”
To many Black people, Simpson embodied the American dream. Conversely, however, it was becoming clear that O.J. was not exactly keeping his roots in mind during his ascent.
It emerged that he would tell close friends , “I’m not Black, I’m O.J.” — an apparent recognition that he understood how his fame seemed to transcend his race in the eyes of white fans.
“Especially as a Black athlete at that time, it’s hard not to get caught up in this lifestyle and forget where he came from and forget his roots, and forget about the people who truly cared for him as a person, and not about his ability to carry a football or act in a movie,” Woods said. “Different people viewed him differently.”
By the time Simpson was pursued by LAPD in a slow-speed chase on a Southern California freeway in 1994, Los Angeles was already on a low boil of deep-seated racial tensions and Black animosity toward police.

Cecil Rhambo, now the chief of police for Los Angeles International Airport, was a sergeant with the L.A. County Sheriff’s Department at the time and had begun overseeing its internal affairs office between the Rodney King beating and the Simpson trial.
“On the heels of Rodney King, there was always some hostility” from the community, Rhambo said.
In 1991, four white police officers were captured on camera beating King. The next year, Los Angeles erupted in violence after the officers were acquitted of nearly all charges , including assault with a deadly weapon and use of excessive force, and deadlocked on one assault charge.
Rhambo said that after the King verdict, some Black Angelenos would chide him and fellow sheriffs, saying they were only there to cover things up, while others would quietly thank them for their work. He said that distrust and unrest paved the way for “differences in the way we police,” including higher expectations of accountability and the use of tools like body cameras.
Cannick, who as an advocate has taken Los Angeles’ police force to task in several high-profile cases of alleged police brutality and misconduct, says that she has seen an observable difference in the way the media covers crime in 2024, versus 1995, or even 1992. The contrasting outcomes for the trials of King and Simpson were both factors in that change.

Rhambo, who is Black and Korean, said that he remembers that while on duty during that era, he often had to remind the sheriffs who worked for him to remain neutral.
“Everybody was asking us if we thought he did it,” he recalled.
Off duty, in casual settings around other Black people, Rhambo said most people believed it was more likely than not that Simpson was guilty.
For many Black people, even if the evidence pointed to guilt, there was more on trial than the crimes themselves. The revelation that Detective Mark Furhman had used the N-word prolifically, and other injustices by local police, which were highlighted by star attorney Cochran, combined with the dust still settling from the L.A. riots, meant the case was open-and-shut to them: Simpson was not guilty.
“He symbolized the Black man and the criminal justice system at the time,” Cannick said. “Him beating the case, at the time, was everybody beating the case. We finally won one.”
CORRECTION (April 12, 2024, 11:38 a.m. ET): A previous version of this article misstated where Shemar Woods is a professor. It is Arizona State University, not the University of Arizona.
Michelle Garcia is the editorial director of NBCBLK
IMAGES
VIDEO
COMMENTS
Main page; Contents; Current events; Random article; About Wikipedia; Contact us; Donate; Help; Learn to edit; Community portal; Recent changes; Upload file
In insight problem-solving, the cognitive processes that help you solve a problem happen outside your conscious awareness. 4. Working backward. Working backward is a problem-solving approach often ...
Understanding the Concept of Trial and Error: An Accessible Guide in Everyday Language, Crafted by Expert Psychologists, Professors, and Advanced Students. Join us in enhancing clarity.
means-ends analysis, heuristic, or trial-and-error, problem-solving strategy in which an end goal is identified and then fulfilled via the generation of subgoals and action plans that help overcome obstacles encountered along the way. Solving a problem with means-ends analysis typically begins by examining the end goal and breaking it down into ...
Problem-solving skills are essential in our daily lives. The video explains different problem-solving methods, including trial and error, algorithm strategy, and heuristics. It also discusses concepts like means-end analysis, working backwards, fixation, and insight. These techniques help us tackle both well-defined and ill-defined problems ...
Additional Problem Solving Strategies:. Abstraction - refers to solving the problem within a model of the situation before applying it to reality.; Analogy - is using a solution that solves a similar problem.; Brainstorming - refers to collecting an analyzing a large amount of solutions, especially within a group of people, to combine the solutions and developing them until an optimal ...
Problem-solving is a vital skill for coping with various challenges in life. This webpage explains the different strategies and obstacles that can affect how you solve problems, and offers tips on how to improve your problem-solving skills. Learn how to identify, analyze, and overcome problems with Verywell Mind.
Solving Puzzles. Problem-solving abilities can improve with practice. Many people challenge themselves every day with puzzles and other mental exercises to sharpen their problem-solving skills. Sudoku puzzles appear daily in most newspapers. Typically, a sudoku puzzle is a 9×9 grid. The simple sudoku below ( [link]) is a 4×4 grid.
Typically, a sudoku puzzle is a 9×9 grid. The simple sudoku below is a 4×4 grid. To solve the puzzle, fill in the empty boxes with a single digit: 1, 2, 3, or 4. Here are the rules: The numbers must total 10 in each bolded box, each row, and each column; however, each digit can only appear once in a bolded box, row, and column.
Problem-solving strategies. These are operators that a problem solver tries to move from A to B. There are several problem-solving strategies but the main ones are: Algorithms; Heuristics; Trial and error; Insight; 1. Algorithms. When you follow a step-by-step procedure to solve a problem or reach a goal, you're using an algorithm.
We simply substitute that choice into the problem and check. Some questions can only be solved by trial and error; for others we must first decide if there isn't a faster way to arrive at the answer. In the examples to follow, we test all choices for your benefit. Once you have the right answer, there is no …
How do you solve problems in different situations? Do you rely on insight, trial-and-error, or algorithms? This webpage explains the advantages and disadvantages of these three problem solving strategies, and provides examples and exercises to help you improve your skills. Whether you are a student, a professional, or a curious learner, you will find this webpage useful and engaging.
Trial and error is really a primitive experience-based technique for problem-solving, learning, and discovery. With trial and error any "so-called" solution is ...
Studies show that the most successful people failed a lot. When testing concepts, ideas, solving new problems in the real world one cannot avoid making mistakes, or fall flat sometimes. Successful managers, leaders, and entrepreneurs all understand the importance of failure, indeed they are mastered in failing but: they have learned to move on; and
Problem-solving is an integral part of human cognition and innovation. From the simplest tasks to complex challenges, our ability to navigate problems effectively is a key factor in our personal ...
Many people challenge themselves every day with puzzles and other mental exercises to sharpen their problem-solving skills. Sudoku puzzles appear daily in most newspapers. Typically, a sudoku puzzle is a 9×9 grid. The simple sudoku below ( [link]) is a 4×4 grid. To solve the puzzle, fill in the empty boxes with a single digit: 1, 2, 3, or 4.
Algorithms. In contrast to heuristics, which can be thought of as problem-solving strategies based on educated guesses, algorithms are problem-solving strategies that use rules. Algorithms are generally a logical set of steps that, if applied correctly, should be accurate. For example, you could make a cake using heuristics — relying on your ...
The trial and error method is a problem-solving technique that involves trying different approaches or solutions until you find the one that works best. This method ...
The reasoning performance of Large Language Models (LLMs) on a wide range of problems critically relies on chain-of-thought prompting, which involves providing a few chain of thought demonstrations as exemplars in prompts. Recent work, e.g., Tree of Thoughts, has pointed out the importance of exploration and self-evaluation in reasoning step selection for complex problem solving. In this paper ...
Advantages and Disadvantages of Solving a Problem Through Trial and Error » E.L. Thorndike propounded the theory of trial and error. He believes that
Begins to solve problems with less trial and error; Refuses assistance, e.g., calls for help but then pushes a hand away; Shows pride when accomplishing a task; Uses increasingly refined skills while solving problems, e.g., uses own napkin to clean up a spill without asking an adult for help; Strategies for interaction
Problem-solving abilities can improve with practice. Many people challenge themselves every day with puzzles and other mental exercises to sharpen their problem-solving skills. Sudoku puzzles appear daily in most newspapers. Typically, a sudoku puzzle is a 9×9 grid. The simple sudoku below ( Figure 7.7) is a 4×4 grid.
Report issue for preceding element. Step 1: First, we need to calculate the amount of yarn Mariah and her grandma used separately. To do this, we can multiply the fraction of the skein they used by the total yards in a skein. So, Mariah used 1/4 * 364 yards of yarn and her grandma used 1/2 * 364 yards of yarn..
Physics-Informed Neural Network (PINN) is a data-driven solver for partial and ordinary differential equations (ODEs/PDEs). It provides a unified framework to address both forward and inverse problems. However, the complexity of the objective function often leads to training failures. This issue is particularly prominent when solving high-frequency and multi-scale problems. We proposed using ...
For many Black people, even if the evidence pointed to guilt, there was more on trial than the crimes themselves. The revelation that Detective Mark Furhman had used the N-word prolifically, and ...