How to write a hypothesis for marketing experimentation


Creating your strongest marketing hypothesis
The potential for your marketing improvement depends on the strength of your testing hypotheses.
But where are you getting your test ideas from? Have you been scouring competitor sites, or perhaps pulling from previous designs on your site? The web is full of ideas and you’re full of ideas – there is no shortage of inspiration, that’s for sure.
Coming up with something you want to test isn’t hard to do. Coming up with something you should test can be hard to do.
Hard – yes. Impossible? No. Which is good news, because if you can’t create hypotheses for things that should be tested, your test results won’t mean mean much, and you probably shouldn’t be spending your time testing.
Taking the time to write your hypotheses correctly will help you structure your ideas, get better results, and avoid wasting traffic on poor test designs.
With this post, we’re getting advanced with marketing hypotheses, showing you how to write and structure your hypotheses to gain both business results and marketing insights!
By the time you finish reading, you’ll be able to:
- Distinguish a solid hypothesis from a time-waster, and
- Structure your solid hypothesis to get results and insights
To make this whole experience a bit more tangible, let’s track a sample idea from…well…idea to hypothesis.
Let’s say you identified a call-to-action (CTA)* while browsing the web, and you were inspired to test something similar on your own lead generation landing page. You think it might work for your users! Your idea is:
“My page needs a new CTA.”
*A call-to-action is the point where you, as a marketer, ask your prospect to do something on your page. It often includes a button or link to an action like “Buy”, “Sign up”, or “Request a quote”.
The basics: The correct marketing hypothesis format
A well-structured hypothesis provides insights whether it is proved, disproved, or results are inconclusive.
You should never phrase a marketing hypothesis as a question. It should be written as a statement that can be rejected or confirmed.
Further, it should be a statement geared toward revealing insights – with this in mind, it helps to imagine each statement followed by a reason :
- Changing _______ into ______ will increase [conversion goal], because:
- Changing _______ into ______ will decrease [conversion goal], because:
- Changing _______ into ______ will not affect [conversion goal], because:
Each of the above sentences ends with ‘because’ to set the expectation that there will be an explanation behind the results of whatever you’re testing.
It’s important to remember to plan ahead when you create a test, and think about explaining why the test turned out the way it did when the results come in.
Level up: Moving from a good to great hypothesis
Understanding what makes an idea worth testing is necessary for your optimization team.
If your tests are based on random ideas you googled or were suggested by a consultant, your testing process still has its training wheels on. Great hypotheses aren’t random. They’re based on rationale and aim for learning.
Hypotheses should be based on themes and analysis that show potential conversion barriers.
At Conversion, we call this investigation phase the “Explore Phase” where we use frameworks like the LIFT Model to understand the prospect’s unique perspective. (You can read more on the the full optimization process here).
A well-founded marketing hypothesis should also provide you with new, testable clues about your users regardless of whether or not the test wins, loses or yields inconclusive results.
These new insights should inform future testing: a solid hypothesis can help you quickly separate worthwhile ideas from the rest when planning follow-up tests.
“Ultimately, what matters most is that you have a hypothesis going into each experiment and you design each experiment to address that hypothesis.” – Nick So, VP of Delivery
Here’s a quick tip :
If you’re about to run a test that isn’t going to tell you anything new about your users and their motivations, it’s probably not worth investing your time in.
Let’s take this opportunity to refer back to your original idea:
Ok, but what now ? To get actionable insights from ‘a new CTA’, you need to know why it behaved the way it did. You need to ask the right question.
To test the waters, maybe you changed the copy of the CTA button on your lead generation form from “Submit” to “Send demo request”. If this change leads to an increase in conversions, it could mean that your users require more clarity about what their information is being used for.
That’s a potential insight.
Based on this insight, you could follow up with another test that adds copy around the CTA about next steps: what the user should anticipate after they have submitted their information.
For example, will they be speaking to a specialist via email? Will something be waiting for them the next time they visit your site? You can test providing more information, and see if your users are interested in knowing it!
That’s the cool thing about a good hypothesis: the results of the test, while important (of course) aren’t the only component driving your future test ideas. The insights gleaned lead to further hypotheses and insights in a virtuous cycle.
It’s based on a science
The term “hypothesis” probably isn’t foreign to you. In fact, it may bring up memories of grade-school science class; it’s a critical part of the scientific method .
The scientific method in testing follows a systematic routine that sets ideation up to predict the results of experiments via:
- Collecting data and information through observation
- Creating tentative descriptions of what is being observed
- Forming hypotheses that predict different outcomes based on these observations
- Testing your hypotheses
- Analyzing the data, drawing conclusions and insights from the results
Don’t worry! Hypothesizing may seem ‘sciency’, but it doesn’t have to be complicated in practice.
Hypothesizing simply helps ensure the results from your tests are quantifiable, and is necessary if you want to understand how the results reflect the change made in your test.
A strong marketing hypothesis allows testers to use a structured approach in order to discover what works, why it works, how it works, where it works, and who it works on.
“My page needs a new CTA.” Is this idea in its current state clear enough to help you understand what works? Maybe. Why it works? No. Where it works? Maybe. Who it works on? No.
Your idea needs refining.
Let’s pull back and take a broader look at the lead generation landing page we want to test.
Imagine the situation: you’ve been diligent in your data collection and you notice several recurrences of Clarity pain points – meaning that there are many unclear instances throughout the page’s messaging.
Rather than focusing on the CTA right off the bat, it may be more beneficial to deal with the bigger clarity issue.
Now you’re starting to think about solving your prospects conversion barriers rather than just testing random ideas!
If you believe the overall page is unclear, your overarching theme of inquiry might be positioned as:
- “Improving the clarity of the page will reduce confusion and improve [conversion goal].”
By testing a hypothesis that supports this clarity theme, you can gain confidence in the validity of it as an actionable marketing insight over time.
If the test results are negative : It may not be worth investigating this motivational barrier any further on this page. In this case, you could return to the data and look at the other motivational barriers that might be affecting user behavior.
If the test results are positive : You might want to continue to refine the clarity of the page’s message with further testing.
Typically, a test will start with a broad idea — you identify the changes to make, predict how those changes will impact your conversion goal, and write it out as a broad theme as shown above. Then, repeated tests aimed at that theme will confirm or undermine the strength of the underlying insight.
Building marketing hypotheses to create insights
You believe you’ve identified an overall problem on your landing page (there’s a problem with clarity). Now you want to understand how individual elements contribute to the problem, and the effect these individual elements have on your users.
It’s game time – now you can start designing a hypothesis that will generate insights.
You believe your users need more clarity. You’re ready to dig deeper to find out if that’s true!
If a specific question needs answering, you should structure your test to make a single change. This isolation might ask: “What element are users most sensitive to when it comes to the lack of clarity?” and “What changes do I believe will support increasing clarity?”
At this point, you’ll want to boil down your overarching theme…
- Improving the clarity of the page will reduce confusion and improve [conversion goal].
…into a quantifiable hypothesis that isolates key sections:
- Changing the wording of this CTA to set expectations for users (from “submit” to “send demo request”) will reduce confusion about the next steps in the funnel and improve order completions.
Does this answer what works? Yes: changing the wording on your CTA.
Does this answer why it works? Yes: reducing confusion about the next steps in the funnel.
Does this answer where it works? Yes: on this page, before the user enters this theoretical funnel.
Does this answer who it works on? No, this question demands another isolation. You might structure your hypothesis more like this:
- Changing the wording of the CTA to set expectations for users (from “submit” to “send demo request”) will reduce confusion for visitors coming from my email campaign about the next steps in the funnel and improve order completions.
Now we’ve got a clear hypothesis. And one worth testing!
What makes a great hypothesis?
1. It’s testable.
2. It addresses conversion barriers.
3. It aims at gaining marketing insights.
Let’s compare:
The original idea : “My page needs a new CTA.”
Following the hypothesis structure : “A new CTA on my page will increase [conversion goal]”
The first test implied a problem with clarity, provides a potential theme : “Improving the clarity of the page will reduce confusion and improve [conversion goal].”
The potential clarity theme leads to a new hypothesis : “Changing the wording of the CTA to set expectations for users (from “submit” to “send demo request”) will reduce confusion about the next steps in the funnel and improve order completions.”
Final refined hypothesis : “Changing the wording of the CTA to set expectations for users (from “submit” to “send demo request”) will reduce confusion for visitors coming from my email campaign about the next steps in the funnel and improve order completions.”
Which test would you rather your team invest in?
Before you start your next test, take the time to do a proper analysis of the page you want to focus on. Do preliminary testing to define bigger issues, and use that information to refine and pinpoint your marketing hypothesis to give you forward-looking insights.
Doing this will help you avoid time-wasting tests, and enable you to start getting some insights for your team to keep testing!
Share this post
Other articles you might like

Exploration vs. Exploitation: how to balance short-term results with long-term impact

Spotlight: Kevin Turchyn on how Whirlpool Corporation relentlessly tests key assumptions for breakthrough results

Is Goodyear’s UX as effective as its tires?

Join 5,000 other people who get our newsletter updates
- Business Essentials
- Leadership & Management
- Credential of Leadership, Impact, and Management in Business (CLIMB)
- Entrepreneurship & Innovation
- *New* Digital Transformation
- Finance & Accounting
- Business in Society
- For Organizations
- Support Portal
- Media Coverage
- Founding Donors
- Leadership Team

- Harvard Business School →
- HBS Online →
- Business Insights →
Business Insights
Harvard Business School Online's Business Insights Blog provides the career insights you need to achieve your goals and gain confidence in your business skills.
- Career Development
- Communication
- Decision-Making
- Earning Your MBA
- Negotiation
- News & Events
- Productivity
- Staff Spotlight
- Student Profiles
- Work-Life Balance
- Alternative Investments
- Business Analytics
- Business Strategy
- Business and Climate Change
- Design Thinking and Innovation
- Digital Marketing Strategy
- Disruptive Strategy
- Economics for Managers
- Entrepreneurship Essentials
- Financial Accounting
- Global Business
- Launching Tech Ventures
- Leadership Principles
- Leadership, Ethics, and Corporate Accountability
- Leading with Finance
- Management Essentials
- Negotiation Mastery
- Organizational Leadership
- Power and Influence for Positive Impact
- Strategy Execution
- Sustainable Business Strategy
- Sustainable Investing
- Winning with Digital Platforms
A Beginner’s Guide to Hypothesis Testing in Business

- 30 Mar 2021
Becoming a more data-driven decision-maker can bring several benefits to your organization, enabling you to identify new opportunities to pursue and threats to abate. Rather than allowing subjective thinking to guide your business strategy, backing your decisions with data can empower your company to become more innovative and, ultimately, profitable.
If you’re new to data-driven decision-making, you might be wondering how data translates into business strategy. The answer lies in generating a hypothesis and verifying or rejecting it based on what various forms of data tell you.
Below is a look at hypothesis testing and the role it plays in helping businesses become more data-driven.
Access your free e-book today.
What Is Hypothesis Testing?
To understand what hypothesis testing is, it’s important first to understand what a hypothesis is.
A hypothesis or hypothesis statement seeks to explain why something has happened, or what might happen, under certain conditions. It can also be used to understand how different variables relate to each other. Hypotheses are often written as if-then statements; for example, “If this happens, then this will happen.”
Hypothesis testing , then, is a statistical means of testing an assumption stated in a hypothesis. While the specific methodology leveraged depends on the nature of the hypothesis and data available, hypothesis testing typically uses sample data to extrapolate insights about a larger population.
Hypothesis Testing in Business
When it comes to data-driven decision-making, there’s a certain amount of risk that can mislead a professional. This could be due to flawed thinking or observations, incomplete or inaccurate data , or the presence of unknown variables. The danger in this is that, if major strategic decisions are made based on flawed insights, it can lead to wasted resources, missed opportunities, and catastrophic outcomes.
The real value of hypothesis testing in business is that it allows professionals to test their theories and assumptions before putting them into action. This essentially allows an organization to verify its analysis is correct before committing resources to implement a broader strategy.
As one example, consider a company that wishes to launch a new marketing campaign to revitalize sales during a slow period. Doing so could be an incredibly expensive endeavor, depending on the campaign’s size and complexity. The company, therefore, may wish to test the campaign on a smaller scale to understand how it will perform.
In this example, the hypothesis that’s being tested would fall along the lines of: “If the company launches a new marketing campaign, then it will translate into an increase in sales.” It may even be possible to quantify how much of a lift in sales the company expects to see from the effort. Pending the results of the pilot campaign, the business would then know whether it makes sense to roll it out more broadly.
Related: 9 Fundamental Data Science Skills for Business Professionals
Key Considerations for Hypothesis Testing
1. alternative hypothesis and null hypothesis.
In hypothesis testing, the hypothesis that’s being tested is known as the alternative hypothesis . Often, it’s expressed as a correlation or statistical relationship between variables. The null hypothesis , on the other hand, is a statement that’s meant to show there’s no statistical relationship between the variables being tested. It’s typically the exact opposite of whatever is stated in the alternative hypothesis.
For example, consider a company’s leadership team that historically and reliably sees $12 million in monthly revenue. They want to understand if reducing the price of their services will attract more customers and, in turn, increase revenue.
In this case, the alternative hypothesis may take the form of a statement such as: “If we reduce the price of our flagship service by five percent, then we’ll see an increase in sales and realize revenues greater than $12 million in the next month.”
The null hypothesis, on the other hand, would indicate that revenues wouldn’t increase from the base of $12 million, or might even decrease.
Check out the video below about the difference between an alternative and a null hypothesis, and subscribe to our YouTube channel for more explainer content.
2. Significance Level and P-Value
Statistically speaking, if you were to run the same scenario 100 times, you’d likely receive somewhat different results each time. If you were to plot these results in a distribution plot, you’d see the most likely outcome is at the tallest point in the graph, with less likely outcomes falling to the right and left of that point.

With this in mind, imagine you’ve completed your hypothesis test and have your results, which indicate there may be a correlation between the variables you were testing. To understand your results' significance, you’ll need to identify a p-value for the test, which helps note how confident you are in the test results.
In statistics, the p-value depicts the probability that, assuming the null hypothesis is correct, you might still observe results that are at least as extreme as the results of your hypothesis test. The smaller the p-value, the more likely the alternative hypothesis is correct, and the greater the significance of your results.
3. One-Sided vs. Two-Sided Testing
When it’s time to test your hypothesis, it’s important to leverage the correct testing method. The two most common hypothesis testing methods are one-sided and two-sided tests , or one-tailed and two-tailed tests, respectively.
Typically, you’d leverage a one-sided test when you have a strong conviction about the direction of change you expect to see due to your hypothesis test. You’d leverage a two-sided test when you’re less confident in the direction of change.

4. Sampling
To perform hypothesis testing in the first place, you need to collect a sample of data to be analyzed. Depending on the question you’re seeking to answer or investigate, you might collect samples through surveys, observational studies, or experiments.
A survey involves asking a series of questions to a random population sample and recording self-reported responses.
Observational studies involve a researcher observing a sample population and collecting data as it occurs naturally, without intervention.
Finally, an experiment involves dividing a sample into multiple groups, one of which acts as the control group. For each non-control group, the variable being studied is manipulated to determine how the data collected differs from that of the control group.

Learn How to Perform Hypothesis Testing
Hypothesis testing is a complex process involving different moving pieces that can allow an organization to effectively leverage its data and inform strategic decisions.
If you’re interested in better understanding hypothesis testing and the role it can play within your organization, one option is to complete a course that focuses on the process. Doing so can lay the statistical and analytical foundation you need to succeed.
Do you want to learn more about hypothesis testing? Explore Business Analytics —one of our online business essentials courses —and download our Beginner’s Guide to Data & Analytics .

About the Author

- Free Resources
A/B Testing in Digital Marketing: Example of four-step hypothesis framework
by Daniel Burstein , Senior Director, Content & Marketing, MarketingSherpa and MECLABS Institute

This article was originally published in the MarketingSherpa email newsletter .
If you are a marketing expert — whether in a brand’s marketing department or at an advertising agency — you may feel the need to be absolutely sure in an unsure world.
What should the headline be? What images should we use? Is this strategy correct? Will customers value this promo?
This is the stuff you’re paid to know. So you may feel like you must boldly proclaim your confident opinion.
But you can’t predict the future with 100% accuracy. You can’t know with absolute certainty how humans will behave. And let’s face it, even as marketing experts we’re occasionally wrong.
It’s not bad, it’s healthy. And the most effective way to overcome that doubt is by testing our marketing creative to see what really works.
Developing a hypothesis
After we published Value Sequencing: A step-by-step examination of a landing page that generated 638% more conversions , a MarketingSherpa reader emailed us and asked …
Great stuff Daniel. Much appreciated. I can see you addressing all the issues there.
I thought I saw one more opportunity to expand on what you made. Would you consider adding the IF, BY, WILL, BECAUSE to the control/treatment sections so we can see what psychology you were addressing so we know how to create the hypothesis to learn from what the customer is currently doing and why and then form a test to address that? The video today on customer theory was great (Editor’s Note: Part of the MarketingExperiments YouTube Live series ) . I think there is a way to incorporate that customer theory thinking into this article to take it even further.
Developing a hypothesis is an essential part of marketing experimentation. Qualitative-based research should inform hypotheses that you test with real-world behavior.
The hypotheses help you discover how accurate those insights from qualitative research are. If you engage in hypothesis-driven testing, then you ensure your tests are strategic (not just based on a random idea) and built in a way that enables you to learn more and more about the customer with each test.
And that methodology will ultimately lead to greater and greater lifts over time, instead of a scattershot approach where sometimes you get a lift and sometimes you don’t, but you never really know why.
Here is a handy tool to help you in developing hypotheses — the MECLABS Four-Step Hypothesis Framework.
As the reader suggests, I will use the landing page test referenced in the previous article as an example. ( Please note: While the experiment in that article was created with a hypothesis-driven approach, this specific four-step framework is fairly new and was not in common use by the MECLABS team at that time, so I have created this specific example after the test was developed based on what I see in the test).
Here is what the hypothesis would look like for that test, and then we’ll break down each part individually:
If we emphasize the process-level value by adding headlines, images and body copy, we will generate more leads because the value of a longer landing page in reducing the anxiety of calling a TeleAgent outweighs the additional friction of a longer page.

IF: Summary description
The hypothesis begins with an overall statement about what you are trying to do in the experiment. In this case, the experiment is trying to emphasize the process-level value proposition (one of the four essential levels of value proposition ) of having a phone call with a TeleAgent.
The control landing page was emphasizing the primary value proposition of the brand itself.
The treatment landing page is essentially trying to answer this value proposition question: If I am your ideal customer, why should I call a TeleAgent rather than take any other action to learn more about my Medicare options?
The control landing page was asking a much bigger question that customers weren’t ready to say “yes” to yet, and it was overlooking the anxiety inherent in getting on a phone call with someone who might try to sell you something: If I am your ideal customer, why should I buy from your company instead of any other company.
This step answers WHAT you are trying to do.
BY: Remove, add, change
The next step answers HOW you are going to do it.
As Flint McGlaughlin, CEO and Managing Director of MECLABS Institute teaches, there are only three ways to improve performance: removing, adding or changing .
In this case, the team focused mostly on adding — adding headlines, images and body copy that highlighted the TeleAgents as trusted advisors.
“Adding” can be counterintuitive for many marketers. The team’s original landing page was short. Conventional wisdom says customers won’t read long landing pages. When I’m presenting to a group of marketers, I’ll put a short and long landing page on a slide and ask which page they think achieved better results.
Invariably I will hear, “Oh, the shorter page. I would never read something that long.”
That first-person statement is a mistake. Your marketing creative should not be based on “I” — the marketer. It should be based on “they” — the customer.
Most importantly, you need to focus on the customer at a specific point in time — when he or she is in the mindspace of considering to take an action like purchase a product or in need of more information before they decide to download a whitepaper. And sometimes in these situations, longer landing pages perform better.
In the case of this landing page, even the customer may not necessarily favor a long landing page all the time. But in the real-world situation when they are considering whether to call a TeleAgent or not, the added value helps more customers decide to take the action.
WILL: Improve performance
This is your KPI (key performance indicator). This step answers another HOW question: How do you know your hypothesis has been supported or refuted?
You can choose secondary metrics to monitor during your test as well. This might help you interpret the customer behavior observed in the test.
But ultimately, the hypothesis should rest on a single metric.
For this test, the goal was to generate more leads. And the treatment did — 638% more leads.
BECAUSE: Customer insight
This last step answers a WHY question — why did the customers act this way?
This helps you determine what you can learn about customers based on the actions observed in the experiment.
This is ultimately why you test. To learn about the customer and continually refine your company’s customer theory .
In this case, the team theorized that the value of a longer landing page in reducing the anxiety of calling a TeleAgent outweighs the additional friction of a longer landing page.
And the test results support that hypothesis.
Related Resources
The Hypothesis and the Modern-Day Marketer
Boost your Conversion Rate with a MECLABS Quick Win Intensive
Designing Hypotheses that Win: A four-step framework for gaining customer wisdom and generating marketing results
Improve Your Marketing

Join our thousands of weekly case study readers.
Enter your email below to receive MarketingSherpa news, updates, and promotions:
Note: Already a subscriber? Want to add a subscription? Click Here to Manage Subscriptions
Get Better Business Results With a Skillfully Applied Customer-first Marketing Strategy

The customer-first approach of MarketingSherpa’s agency services can help you build the most effective strategy to serve customers and improve results, and then implement it across every customer touchpoint.

Get headlines, value prop, competitive analysis, and more.
Marketer Vs Machine

Marketer Vs Machine: We need to train the marketer to train the machine.
Free Marketing Course

Become a Marketer-Philosopher: Create and optimize high-converting webpages (with this free online marketing course)
Project and Ideas Pitch Template

A free template to help you win approval for your proposed projects and campaigns
Six Quick CTA checklists

These CTA checklists are specifically designed for your team — something practical to hold up against your CTAs to help the time-pressed marketer quickly consider the customer psychology of your “asks” and how you can improve them.
Infographic: How to Create a Model of Your Customer’s Mind

You need a repeatable methodology focused on building your organization’s customer wisdom throughout your campaigns and websites. This infographic can get you started.
Infographic: 21 Psychological Elements that Power Effective Web Design

To build an effective page from scratch, you need to begin with the psychology of your customer. This infographic can get you started.
Receive the latest case studies and data on email, lead gen, and social media along with MarketingSherpa updates and promotions.
- Your Email Account
- Customer Service Q&A
- Search Library
- Content Directory:
Questions? Contact Customer Service at [email protected]
© 2000-2024 MarketingSherpa LLC, ISSN 1559-5137 Editorial HQ: MarketingSherpa LLC, PO Box 50032, Jacksonville Beach, FL 32240
The views and opinions expressed in the articles of this website are strictly those of the author and do not necessarily reflect in any way the views of MarketingSherpa, its affiliates, or its employees.
11 A/B Testing Examples From Real Businesses
Published: April 21, 2023
Whether you're looking to increase revenue, sign-ups, social shares, or engagement, A/B testing and optimization can help you get there.

But for many marketers out there, the tough part about A/B testing is often finding the right test to drive the biggest impact — especially when you're just getting started. So, what's the recipe for high-impact success?

Truthfully, there is no one-size-fits-all recipe. What works for one business won't work for another — and finding the right metrics and timing to test can be a tough problem to solve. That’s why you need inspiration from A/B testing examples.
In this post, let's review how a hypothesis will get you started with your testing, and check out excellent examples from real businesses using A/B testing. While the same tests may not get you the same results, they can help you run creative tests of your own. And before you check out these examples. be sure to review key concepts of A/B testing.
A/B Testing Hypothesis Examples
A hypothesis can make or break your experiment, especially when it comes to A/B testing. When creating your hypothesis, you want to make sure that it’s:
- Focused on one specific problem you want to solve or understand
- Able to be proven or disproven
- Focused on making an impact (bringing higher conversion rates, lower bounce rate, etc.)
When creating a hypothesis, following the "If, then" structure can be helpful, where if you changed a specific variable, then a particular result would happen.
Here are some examples of what that would look like in an A/B testing hypothesis:
- Shortening contact submission forms to only contain required fields would increase the number of sign-ups.
- Changing the call-to-action text from "Download now" to "Download this free guide" would increase the number of downloads.
- Reducing the frequency of mobile app notifications from five times per day to two times per day will increase mobile app retention rates.
- Using featured images that are more contextually related to our blog posts will contribute to a lower bounce rate.
- Greeting customers by name in emails will increase the total number of clicks.
Let’s go over some real-life examples of A/B testing to prepare you for your own.
A/B Testing Examples
Website a/b testing examples, 1. hubspot academy's homepage hero image.
Most websites have a homepage hero image that inspires users to engage and spend more time on the site. This A/B testing example shows how hero image changes can impact user behavior and conversions.
Based on previous data, HubSpot Academy found that out of more than 55,000 page views, only .9% of those users were watching the video on the homepage. Of those viewers, almost 50% watched the full video.
Chat transcripts also highlighted the need for clearer messaging for this useful and free resource.
That's why the HubSpot team decided to test how clear value propositions could improve user engagement and delight.
A/B Test Method
HubSpot used three variants for this test, using HubSpot Academy conversion rate (CVR) as the primary metric. Secondary metrics included CTA clicks and engagement.
Variant A was the control.

For variant B, the team added more vibrant images and colorful text and shapes. It also included an animated "typing" headline.

Variant C also added color and movement, as well as animated images on the right-hand side of the page.

As a result, HubSpot found that variant B outperformed the control by 6%. In contrast, variant C underperformed the control by 1%. From those numbers, HubSpot was able to project that using variant B would lead to about 375 more sign ups each month.
2. FSAstore.com’s Site Navigation
Every marketer will have to focus on conversion at some point. But building a website that converts is tough.
FSAstore.com is an ecommerce company supplying home goods for Americans with a flexible spending account.
This useful site could help the 35 million+ customers that have an FSA. But the website funnel was overwhelming. It had too many options, especially on category pages. The team felt that customers weren't making purchases because of that issue.
To figure out how to appeal to its customers, this company tested a simplified version of its website. The current site included an information-packed subheader in the site navigation.
To test the hypothesis, this A/B testing example compared the current site to an update without the subheader.

This update showed a clear boost in conversions and FSAstore.com saw a 53.8% increase in revenue per visitor.
3. Expoze’s Web Page Background
The visuals on your web page are important because they help users decide whether they want to spend more time on your site.
In this A/B testing example, Expoze.io decided to test the background on its homepage.
The website home page was difficult for some users to read because of low contrast. The team also needed to figure out how to improve page navigation while still representing the brand.
First, the team did some research and created several different designs. The goals of the redesign were to improve the visuals and increase attention to specific sections of the home page, like the video thumbnail.

They used AI-generated eye tracking as they designed to find the best designs before A/B testing. Then they ran an A/B heatmap test to see whether the new or current design got the most attention from visitors.

The new design showed a big increase in attention, with version B bringing over 40% more attention to the desired sections of the home page.
This design change also brought a 25% increase in CTA clicks. The team believes this is due to the added contrast on the page bringing more attention to the CTA button, which was not changed.
4. Thrive Themes’ Sales Page Optimization
Many landing pages showcase testimonials. That's valuable content and it can boost conversion.
That's why Thrive Themes decided to test a new feature on its landing pages — customer testimonials .
In the control, Thrive Themes had been using a banner that highlighted product features, but not how customers felt about the product.
The team decided to test whether adding testimonials to a sales landing page could improve conversion rates.
In this A/B test example, the team ran a 6-week test with the control against an updated landing page with testimonials.

This change netted a 13% increase in sales. The control page had a 2.2% conversion rate, but the new variant showed a 2.75% conversion rate.
Email A/B Testing Examples
5. hubspot's email subscriber experience.
Getting users to engage with email isn't an easy task. That's why HubSpot decided to A/B test how alignment impacts CTA clicks.
HubSpot decided to change text alignment in the weekly emails for subscribers to improve the user experience. Ideally, this improved experience would result in a higher click rate.
For the control, HubSpot sent centered email text to users.

For variant B, HubSpot sent emails with left-justified text.

HubSpot found that emails with left-aligned text got fewer clicks than the control. And of the total left-justified emails sent, less than 25% got more clicks than the control.
6. Neurogan’s Deal Promotion
Making the most of email promotion is important for any company, especially those in competitive industries.
This example uses the power of current customers for increasing email engagement.
Neurogan wasn't always offering the right content to its audience and it was having a hard time competing with a flood of other new brands.
An email agency audited this brand's email marketing, then focused efforts on segmentation. This A/B testing example starts with creating product-specific offers. Then, this team used testing to figure out which deals were best for each audience.
These changes brought higher revenue for promotions and higher click rates. It also led to a new workflow with a 37% average open rate and a click rate of 3.85%.
For more on how to run A/B testing for your campaigns, check out this free A/B testing kit .
Social Media A/B Testing Examples
7. vestiaire’s tiktok awareness campaign.
A/B testing examples like the one below can help you think creatively about what to test and when. This is extra helpful if your business is working with influencers and doesn't want to impact their process while working toward business goals.
Fashion brand Vestaire wanted help growing the brand on TikTok. It was also hoping to increase awareness with Gen Z audiences for its new direct shopping feature.
Vestaire's influencer marketing agency asked eight influencers to create content with specific CTAs to meet the brand's goals. Each influencer had extensive creative freedom and created a range of different social media posts.
Then, the agency used A/B testing to choose the best-performing content and promoted this content with paid advertising .

This testing example generated over 4,000 installs. It also decreased the cost per install by 50% compared to the brand's existing presence on Instagram and YouTube.
8. Underoutfit’s Promotion of User-Generated Content on Facebook
Paid advertising is getting more expensive, and clickthrough rates decreased through the end of 2022 .
To make the most of social ad spend, marketers are using A/B testing to improve ad performance. This approach helps them test creative content before launching paid ad campaigns, like in the examples below.
Underoutfit wanted to increase brand awareness on Facebook.
To meet this goal, it decided to try adding branded user-generated content. This brand worked with an agency and several creators to create branded content to drive conversion.
Then, Underoutfit ran split testing between product ads and the same ads combined with the new branded content ads. Both groups in the split test contained key marketing messages and clear CTA copy.
The brand and agency also worked with Meta Creative Shop to make sure the videos met best practice standards.

The test showed impressive results for the branded content variant, including a 47% higher clickthrough rate and 28% higher return on ad spend.
9. Databricks’ Ad Performance on LinkedIn
Pivoting to a new strategy quickly can be difficult for organizations. This A/B testing example shows how you can use split testing to figure out the best new approach to a problem.
Databricks , a cloud software tool, needed to raise awareness for an event that was shifting from in-person to online .
To connect with a large group of new people in a personalized way, the team decided to create a LinkedIn Message Ads campaign. To make sure the messages were effective, it used A/B testing to tweak the subject line and message copy.

The third variant of the copy featured a hyperlink in the first sentence of the invitation. Compared to the other two variants, this version got nearly twice as many clicks and conversions.
Mobile A/B Testing Example
7. hubspot's mobile calls-to-action.
On this blog, you'll notice anchor text in the introduction, a graphic CTA at the bottom, and a slide-in CTA when you scroll through the post. Once you click on one of these offers, you'll land on a content offer page.
While many users access these offers from a desktop or laptop computer, many others plan to download these offers to mobile devices.
But on mobile, users weren't finding the CTA buttons as quickly as they could on a computer. That's why HubSpot tested mobile design changes to improve the user experience.
Previous A/B tests revealed that HubSpot's mobile audience was 27% less likely to click through to download an offer. Also, less than 75% of mobile users were scrolling down far enough to see the CTA button.
So, HubSpot decided to test different versions of the offer page CTA, using conversion rate (CVR) as the primary metric. For secondary metrics, the team measured CTA clicks for each CTA, as well as engagement.
HubSpot used four variants for this test.
For variant A, the control, the traditional placement of CTAs remained unchanged.
For variant B, the team redesigned the hero image and added a sticky CTA bar.

For variant C, the redesigned hero was the only change.
For variant D, the team redesigned the hero image and repositioned the slider.

All variants outperformed the control for the primary metric, CVR. Variant C saw a 10% increase, variant B saw a 9% increase, and variant D saw an 8% increase.
From those numbers, HubSpot was able to project that using variant C on mobile would lead to about 1,400 more content leads and almost 5,700 more form submissions each month.
11. Hospitality.net’s Mobile Booking
Businesses need to keep up with quick shifts in mobile devices to create a consistently strong customer experience.
A/B testing examples like the one below can help your business streamline this process.
Hospitality.net offered both simplified and dynamic mobile booking experiences. The simplified experience showed a limited number of available dates and the design is for smaller screens. The dynamic experience is for the larger mobile device screens. It shows a wider range of dates and prices.
But the brand wasn’t sure which mobile optimization strategy would be better for conversion.
This brand believed that customers would prefer the dynamic experience and that it would get more conversions. But it chose to test these ideas with a simple A/B test. Over 34 days, it sent half of the mobile visitors to the simplified mobile experience, and half to the dynamic experience, with over 100,000 visitors total.

This A/B testing example showed a 33% improvement in conversion. It also helped confirm the brand's educated guesses about mobile booking preferences.
A/B Testing Takeaways for Marketers
A lot of different factors can go into A/B testing, depending on your business needs. But there are a few key things to keep in mind:
- Every A/B test should start with a hypothesis focused on one specific problem that you can test.
- Make sure you’re testing a control variable (your original version) and a treatment variable (a new version that you think will perform better).
- You can test various things, like landing pages, CTAs, emails, or mobile app designs.
- The best way to understand if your results mean something is to figure out the statistical significance of your test.
- There are a variety of goals to focus on for A/B testing (increased site traffic, lower bounce rates, etc.), but you should be able to test, support, prove, and disprove your hypothesis.
- When testing, make sure you’re splitting your sample groups equally and randomly, so your data is viable and not due to chance.
- Take action based on the results you observe.
Start Your Next A/B Test Today
You can see amazing results from the A/B testing examples above. These businesses were able to take action on goals because they started testing. If you want to get great results, you've got to get started, too.
Editor's note: This post was originally published in October 2014 and has been updated for comprehensiveness.

Don't forget to share this post!
Related articles.

How to Do A/B Testing: 15 Steps for the Perfect Split Test

Multivariate Testing: How It Differs From A/B Testing

How to A/B Test Your Pricing (And Why It Might Be a Bad Idea)

15 of the Best A/B Testing Tools for 2023

How to Determine Your A/B Testing Sample Size & Time Frame

These 20 A/B Testing Variables Measure Successful Marketing Campaigns
![How to Understand & Calculate Statistical Significance [Example]](https://blog.hubspot.com/hubfs/FEATURED%20IMAGE-Nov-22-2022-06-25-18-4060-PM.png "hypothesis examples marketing")
How to Understand & Calculate Statistical Significance [Example]

What is an A/A Test & Do You Really Need to Use It?

The Ultimate Guide to Social Testing
![How to Conduct the Perfect Marketing Experiment [+ Examples]](https://blog.hubspot.com/hubfs/marketing-experiment%20copy.jpg "hypothesis examples marketing")
How to Conduct the Perfect Marketing Experiment [+ Examples]
Learn more about A/B and how to run better tests.
Marketing software that helps you drive revenue, save time and resources, and measure and optimize your investments — all on one easy-to-use platform
Expert Advice on Developing a Hypothesis for Marketing Experimentation
- Conversion Rate Optimization

Simbar Dube
Every marketing experimentation process has to have a solid hypothesis.
That’s a must – unless you want to be roaming in the dark and heading towards a dead-end in your experimentation program.
Hypothesizing is the second phase of our SHIP optimization process here at Invesp.

It comes after we have completed the research phase.
This is an indication that we don’t just pull a hypothesis out of thin air. We always make sure that it is based on research data.
But having a research-backed hypothesis doesn’t mean that the hypothesis will always be correct. In fact, tons of hypotheses bear inconclusive results or get disproved.
The main idea of having a hypothesis in marketing experimentation is to help you gain insights – regardless of the testing outcome.
By the time you finish reading this article, you’ll know:
- The essential tips on what to do when crafting a hypothesis for marketing experiments
- How a marketing experiment hypothesis works
How experts develop a solid hypothesis
The basics: marketing experimentation hypothesis.
A hypothesis is a research-based statement that aims to explain an observed trend and create a solution that will improve the result. This statement is an educated, testable prediction about what will happen.
It has to be stated in declarative form and not as a question.
“ If we add magnification info, product video and making virtual mirror buttons, will that improve engagement? ” is not declarative, but “ Improving the experience of product pages by adding magnification info, product video and making virtual mirror buttons will increase engagement ” is.
Here’s a quick example of how a hypothesis should be phrased:
- Replacing ___ with __ will increase [conversion goal] by [%], because:
- Removing ___ and __ will decrease [conversion goal] by [%], because:
- Changing ___ into __ will not affect [conversion goal], because:
- Improving ___ by ___will increase [conversion goal], because:
As you can see from the above sentences, a good hypothesis is written in clear and simple language. Reading your hypothesis should tell your team members exactly what you thought was going to happen in an experiment.
Another important element of a good hypothesis is that it defines the variables in easy-to-measure terms, like who the participants are, what changes during the testing, and what the effect of the changes will be:
Example : Let’s say this is our hypothesis:
Displaying full look items on every “continue shopping & view your bag” pop-up and highlighting the value of having a full look will improve the visibility of a full look, encourage visitors to add multiple items from the same look and that will increase the average order value, quantity with cross-selling by 3% .
Who are the participants :
Visitors.
What changes during the testing :
Displaying full look items on every “continue shopping & view your bag” pop-up and highlighting the value of having a full look…
What the effect of the changes will be:
Will improve the visibility of a full look, encourage visitors to add multiple items from the same look and that will increase the average order value, quantity with cross-selling by 3% .
Don’t bite off more than you can chew! Answering some scientific questions can involve more than one experiment, each with its own hypothesis. so, you have to make sure your hypothesis is a specific statement relating to a single experiment.
How a Marketing Experimentation Hypothesis Works
Assuming that you have done conversion research and you have identified a list of issues ( UX or conversion-related problems) and potential revenue opportunities on the site. The next thing you’d want to do is to prioritize the issues and determine which issues will most impact the bottom line.
Having ranked the issues you need to test them to determine which solution works best. At this point, you don’t have a clear solution for the problems identified. So, to get better results and avoid wasting traffic on poor test designs, you need to make sure that your testing plan is guided.
This is where a hypothesis comes into play.
For each and every problem you’re aiming to address, you need to craft a hypothesis for it – unless the problem is a technical issue that can be solved right away without the need to hypothesize or test.
One important thing you should note about an experimentation hypothesis is that it can be implemented in different ways.

This means that one hypothesis can have four or five different tests as illustrated in the image above. Khalid Saleh , the Invesp CEO, explains:
“There are several ways that can be used to support one single hypothesis. Each and every way is a possible test scenario. And that means you also have to prioritize the test design you want to start with. Ultimately the name of the game is you want to find the idea that has the biggest possible impact on the bottom line with the least amount of effort. We use almost 18 different metrics to score all of those.”
In one of the recent tests we launched after watching video recordings, viewing heatmaps, and conducting expert reviews, we noticed that:
- Visitors were scrolling to the bottom of the page to fill out a calculator so as to get a free diet plan.
- Brand is missing
- Too many free diet plans – and this made it hard for visitors to choose and understand.
- No value proposition on the page
- The copy didn’t mention the benefits of the paid program
- There was no clear CTA for the next action
To help you understand, let’s have a look at how the original page looked like before we worked on it:
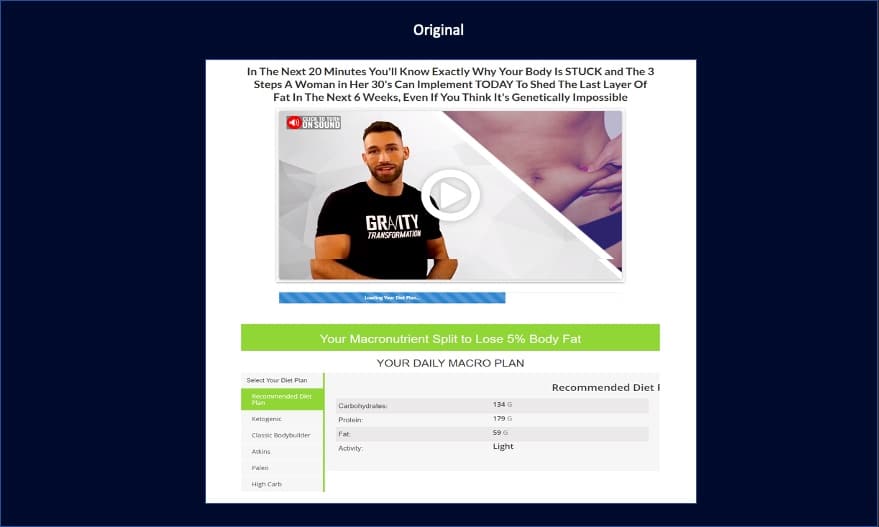
So our aim was to make the shopping experience seamless for visitors, make the page more appealing and not confusing. In order to do that, here is how we phrased the hypothesis for the page above:
Improving the experience of optin landing pages by making the free offer accessible above the fold and highlighting the next action with a clear CTA and will increase the engagement on the offer and increase the conversion rate by 1%.
For this particular hypothesis, we had two design variations aligned to it:
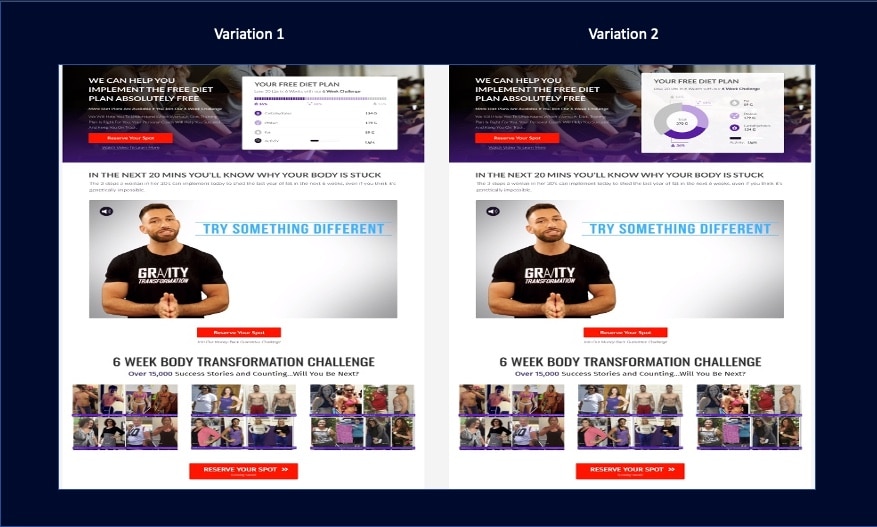
The two above designs are different, but they are aligned to one hypothesis. This goes on to show how one hypothesis can be implemented in different ways. Looking at the two variations above – which one do you think won?
Yes, you’re right, V2 was the winner.
Considering that there are many ways you can implement one hypothesis, so when you launch a test and it fails, it doesn’t necessarily mean that the hypothesis was wrong. Khalid adds:
“A single failure of a test doesn’t mean that the hypothesis is incorrect. Nine times out of ten it’s because of the way you’ve implemented the hypothesis. Look at the way you’ve coded and look at the copy you’ve used – you are more likely going to find something wrong with it. Always be open.”
So there are three things you should keep in mind when it comes to marketing experimentation hypotheses:
- It takes a while for this hypothesis to really fully test it.
- A single failure doesn’t necessarily mean that the hypothesis is incorrect.
- Whether a hypothesis is proved or disproved, you can still learn something about your users.
I know it’s never easy to develop a hypothesis that informs future testing – I mean it takes a lot of intense research behind the scenes, and tons of ideas to begin with. So, I reached out to six CRO experts for tips and advice to help you understand more about developing a solid hypothesis and what to include in it.
Maurice says that a solid hypothesis should have not more than one goal:
Maurice Beerthuyzen – CRO/CXO Lead at ClickValue “Creating a hypothesis doesn’t begin at the hypothesis itself. It starts with research. What do you notice in your data, customer surveys, and other sources? Do you understand what happens on your website? When you notice an opportunity it is tempting to base one single A/B test on one hypothesis. Create hypothesis A and run a single test, and then move forward to the next test. With another hypothesis. But it is very rare that you solve your problem with only one hypothesis. Often a test provides several other questions. Questions which you can solve with running other tests. But based on that same hypothesis! We should not come up with a new hypothesis for every test. Another mistake that often happens is that we fill the hypothesis with multiple goals. Then we expect that the hypothesis will work on conversion rate, average order value, and/or Click Through Ratio. Of course, this is possible, but when you run your test, your hypothesis can only have one goal at once. And what if you have two goals? Just split the hypothesis then create a secondary hypothesis for your second goal. Every test has one primary goal. What if you find a winner on your secondary hypothesis? Rerun the test with the second hypothesis as the primary one.”
Jon believes that a strong hypothesis is built upon three pillars:
Jon MacDonald – President and Founder of The Good Respond to an established challenge – The challenge must have a strong background based on data, and the background should state an established challenge that the test is looking to address. Example: “Sign up form lacks proof of value, incorrectly assuming if users are on the page, they already want the product.” Propose a specific solution – What is the one, the single thing that is believed will address the stated challenge? Example: “Adding an image of the dashboard as a background to the signup form…”. State the assumed impact – The assumed impact should reference one specific, measurable optimization goal that was established prior to forming a hypothesis. Example: “…will increase signups.” So, if your hypothesis doesn’t have a specific, measurable goal like “will increase signups,” you’re not really stating a test hypothesis!”
Matt uses his own hypothesis builder to collate important data points into a single hypothesis.
Matt Beischel – Founder of Corvus CRO Like Jon, Matt also breaks down his hypothesis writing process into three sections. Unlike Jon, Matt sections are: Comprehension Response Outcome I set it up so that the names neatly match the “CRO.” It’s a sort of “mad-libs” style fill-in-the-blank where each input is an important piece of information for building out a robust hypothesis. I consider these the minimum required data points for a good hypothesis; if you can’t completely fill out the form, then you don’t have a good hypothesis. Here’s a breakdown of each data point: Comprehension – Identifying something that can be improved upon Problem: “What is a problem we have?” Observation Method: “How did we identify the problem?” Response – Change that can cause improvement Variation: “What change do we think could solve the problem?” Location: “Where should the change occur?” Scope: “What are the conditions for the change?” Audience: “Who should the change affect?” Outcome – Measurable result of the change that determines the success Behavior Change : “What change in behavior are we trying to affect?” Primary KPI: “What is the important metric that determines business impact?” Secondary KPIs: “Other metrics that will help reinforce/refute the Primary KPI” Something else to consider is that I have a “user first” approach to formulating hypotheses. My process above is always considered within the context of how it would first benefit the user. Now, I do feel that a successful experiment should satisfy the needs of BOTH users and businesses, but always be in favor of the user. Notice that “Behavior Change” is the first thing listed in Outcome, not primary business KPI. Sure, at the end of the day you are working for the business’s best interests (both strategically and financially), but placing the user first will better inform your decision making and prioritization; there’s a reason that things like personas, user stories, surveys, session replays, reviews, etc. exist after all. A business-first ideology is how you end up with dark patterns and damaging brand credibility.”
One of the many mistakes that CROs make when writing a hypothesis is that they are focused on wins and not on insights. Shiva advises against this mindset:
Shiva Manjunath – Marketing Manager and CRO at Gartner “Test to learn, not test to win. It’s a very simple reframe of hypotheses but can have a magnitude of difference. Here’s an example: Test to Win Hypothesis: If I put a product video in the middle of the product page, I will improve add to cart rates and improve CVR. Test to Learn Hypothesis: If I put a product video on the product page, there will be high engagement with the video and it will positively influence traffic What you’re doing is framing your hypothesis, and test, in a particular way to learn as much as you can. That is where you gain marketing insights. The more you run ‘marketing insight’ tests, the more you will win. Why? The more you compound marketing insight learnings, your win velocity will start to increase as a proxy of the learnings you’ve achieved. Then, you’ll have a higher chance of winning in your tests – and the more you’ll be able to drive business results.”
Lorenzo says it’s okay to focus on achieving a certain result as long as you are also getting an answer to: “Why is this event happening or not happening?”
Lorenzo Carreri – CRO Consultant “When I come up with a hypothesis for a new or iterative experiment, I always try to find an answer to a question. It could be something related to a problem people have or an opportunity to achieve a result or a way to learn something. The main question I want to answer is “Why is this event happening or not happening?” The question is driven by data, both qualitative and quantitative. The structure I use for stating my hypothesis is: From [data source], I noticed [this problem/opportunity] among [this audience of users] on [this page or multiple pages]. So I believe that by [offering this experiment solution], [this KPI] will [increase/decrease/stay the same].
Jakub Linowski says that hypotheses are meant to hold researchers accountable:
Jakub Linowski – Chief Editor of GoodUI “They do this by making your change and prediction more explicit. A typical hypothesis may be expressed as: If we change (X), then it will have some measurable effect (A). Unfortunately, this oversimplified format can also become a heavy burden to your experiment design with its extreme reductionism. However you decide to format your hypotheses, here are three suggestions for more flexibility to avoid limiting yourself. One Or More Changes To break out of the first limitation, we have to admit that our experiments may contain a single or multiple changes. Whereas the classic hypothesis encourages a single change or isolated variable, it’s not the only way we can run experiments. In the real world, it’s quite normal to see multiple design changes inside a single variation. One valid reason for doing this is when wishing to optimize a section of a website while aiming for a greater effect. As more positive changes compound together, there are times when teams decide to run bigger experiments. An experiment design (along with your hypotheses) therefore should allow for both single or multiple changes. One Or More Metrics A second limitation of many hypotheses is that they often ask us to only make a single prediction at a time. There are times when we might like to make multiple guesses or predictions to a set of metrics. A simple example of this might be a trade-off experiment with a guess of increased sales but decreased trial signups. Being able to express single or multiple metrics in our experimental designs should therefore be possible. Estimates, Directional Predictions, Or Unknowns Finally, traditional hypotheses also tend to force very simple directional predictions by asking us to guess whether something will increase or decrease. In reality, however, the fidelity of predictions can be higher or lower. On one hand, I’ve seen and made experiment estimations that contain specific numbers from prior data (ex: increase sales by 14%). While at other times it should also be acceptable to admit the unknown and leave the prediction blank. One example of this is when we are testing a completely novel idea without any prior data in a highly exploratory type of experiment. In such cases, it might be dishonest to make any sort of predictions and we should allow ourselves to express the unknown comfortably.”
Conclusion
So there you have it! Before you jump on launching a test, start by making sure that your hypothesis is solid and backed by research. Ask yourself the questions below when crafting a hypothesis for marketing experimentation:
- Is the hypothesis backed by research?
- Can the hypothesis be tested?
- Does the hypothesis provide insights?
- Does the hypothesis set the expectation that there will be an explanation behind the results of whatever you’re testing?
Don’t worry! Hypothesizing may seem like a very complicated process, but it’s not complicated in practice especially when you have done proper research.
If you enjoyed reading this article and you’d love to get the best CRO content – delivered by the best experts in the industry – straight to your inbox, every week. Please subscribe here .
Share This Article
Join 25,000+ marketing professionals.
Subscribe to Invesp’s blog feed for future articles delivered to receive weekly updates by email.

Discover Similar Topics

Bayesian vs. Frequentist AB Testing: Which Testing Method Is Better
- Test Categories

Expert Insights: Exploring Multivariate Testing Strategies for Websites in 2024
- A/B Testing , Multivariate Testing
Our Services
- Conversion Optimization Training
- Conversion Rate Optimization Professional Services
- Landing Page Optimization
- Conversion Rate Audit
- Design for Growth
- Conversion Research & Discovery
- End to End Digital Optimization
By Industry
- E-commerce CRO Services
- Lead Generation CRO Services
- SaaS CRO Services
- Startup CRO Program
- Case Studies
- Privacy Policy
- © 2006-2020 All rights reserved. Invesp
Subscribe with us
- US office: Chicago, IL
- European office: Istanbul, Turkey
- +1.248.270.3325
- [email protected]
- Conversion Rate Optimization Services
- © 2006-2023 All rights reserved. Invesp
- Popular Topics
- A/B Testing
- Conversion Optimization
- Copy Writing
- Infographics
- Landing Pages
- Multivariate Testing
- Sales & Marketing
- Sales and Marketing
- Shopping Cart
- Social Media
- Subscribers
- MECLABS AI’s Problem Solver in Action
- MECLABS AI: Harness AI With the Power of Your Voice
- Harnessing MECLABS AI: Transform Your Copywriting and Landing Pages
- MECLABS AI: Overcome the ‘Almost Trap’ and Get Real Answers
- MECLABS AI: A brief glimpse into what is coming!
- Transforming Marketing with MECLABS AI: A New Paradigm
- Creative AI Marketing: Escaping the ‘Vending Machine Mentality’
- AI + Synoptic Layered Approach = Transformed Webpage Conversion
- AI Customer Simulations: A Marketing Revolution!
- The Implied Value Proposition: Three ways to transform your sales copy
Designing Hypotheses that Win: A four-step framework for gaining customer wisdom and generating marketing results
There are smart marketers everywhere testing many smart ideas — and bad ones. The problem with ideas is that they are unreliable and unpredictable . Knowing how to test is only half of the equation. As marketing tools and technology evolve rapidly offering new, more powerful ways to measure consumer behavior and conduct more sophisticated testing, it is becoming more important than ever to have a reliable system for deciding what to test .
Without a guiding framework, we are left to draw ideas almost arbitrarily from competitors, brainstorms, colleagues, books and any other sources without truly understanding what makes them good, bad or successful. Ideas are unpredictable because until you can articulate a forceful “because” statement to why your ideas will work, regardless of how good, they are nothing more than a guess , albeit educated, but most often not by the customer.
20+ years of in-depth research, testing, optimization and over 20,000+ sales path experiments have taught us that there is an answer to this problem, and that answer involves rethinking how we view testing and optimization. This short article touches on the keynote message MECLABS Institute’s founder Flint McGlaughlin will give at the upcoming 2018 A/B Testing Summit virtual conference on December 12-13 th . You can register for free at the link above.
Marketers don’t need better ideas; they need a better understanding of their customer.
So if understanding your customer is the key to efficient and effective optimization and ideas aren’t reliable or predictable, what then? We begin with the process of intensively analyzing existing data, metrics, reports and research to construct our best Customer Theory , which is the articulation of our understanding of our customer and their behavior toward our offer.
Then, as we identify problems/focus areas for higher performance in our funnel, we transform our ideas for solving them into a hypothesis containing four key parts :
- If [we achieve this in the mind of the consumer]
- By [adding, subtracting or changing these elements]
- Then [this result will occur]
- Because [that will confirm or deny this belief/hypothesis about the customer]
By transforming ideas into hypotheses, we orient our test to learn about our customer rather than merely trying out an idea. The hypothesis grounds our thinking in the psychology of the customer by providing a framework that forces the right questions into the equation of what to test . “The goal of a test is not to get a lift, but to get a learning,” says Flint McGlaughlin, “and learning compounds over time.”
Let’s look at some examples of what to avoid in your testing, along with good examples of hypotheses.
“Let’s advertise our top products in our rotating banner — that’s what Competitor X is doing.”
“We need more attractive imagery … Let’s place a big, powerful hero image as our banner. Everyone is doing it.”
“We should go minimalist … It’s modern, sleek and sexy, and customers love it. It’ll be good for our brand. Less is more.”
“If we emphasize and sample the diversity of our product line by grouping our top products from various categories in a slowly rotating banner, we will increase clickthrough and engagement from the homepage because customers want to understand the range of what we have to offer (versus some other value, e.g., quality, style, efficacy, affordability, etc.).”
“If we reinforce the clarity of the value proposition by using more relevant imagery to draw attention to the most important information, we will increase clickthrough and ultimately conversion because the customer wants to quickly understand why we’re different in such a competitive space.”
“If we better emphasize the primary message be reducing unnecessary, less-relevant page elements and changing to a simpler, clearer more readable design, we will increase clickthrough and engagement on the homepage because customers are currently overwhelmed by too much friction on this page.”
The golden rule of optimization is “Specificity converts . ” The more specific/relevant you can be to the individual wants and needs of your ideal customer, the more likely the probability of conversion. To be as specific and relevant as possible to a consumer, we use testing not as merely an idea-trial hoping for positive results, but as a mechanism to fill in the gaps of our understanding that existing data can’t answer. Our understanding of the customer is what powers the efficiency and efficacy of our testing .
In Summary …
Smart ideas only work sometimes, but a framework based on understanding your customer will yield more consistent, more rewarding results that only improve over time. The first key to rethinking your approach to optimization is to construct a robust customer theory articulating your best understanding of your customer. From this, you can transform your ideas into hypotheses that will begin producing invaluable insights to lay the groundwork for how you communicate with your customer.
Looking for ideas to inform your hypotheses? We have created and compiled a 60-page guide that contains 21 crafted tools and concepts, and outlines the unique methodology we have used and tested with our partners for 20+ years. You can download the guide for free here: A Model of Your Customer’s Mind
You might also like …
A/B Testing Summit free online conference – Research your seat to see Flint McGlaughlin’s keynote Design Hypotheses that Win: A 4-step framework for gaining customer wisdom and generating significant results
The Hypothesis and the Modern-Day Marketer
Customer Theory: How we learned from a previous test to drive a 40% increase in CTR

Quin McGlaughlin is currently a Senior Optimization Analyst at MECLABS Institute and full-time distance student at Harvard University, studying psychology and business. He has worked on projects for some of MECLABS’ largest clients ranging from Fortune 50 companies to defense contractors, not-for-profits, major ecommerce organizations and others. He has also served as Vice Chair of Digital Strategy for the Harvard Extension Student Association and provided marketing consulting for small and mid-size businesses.
Low-Hanging Fruit for the Holiday Season: Four simple marketing changes with significant impact
Most Popular MarketingExperiments Articles of 2018
How to Discover Exactly What the Customer Wants to See on the Next Click: 3 critical…
The 21 Psychological Elements that Power Effective Web Design (Part 3)
The 21 Psychological Elements that Power Effective Web Design (Part 2)
The 21 Psychological Elements that Power Effective Web Design (Part 1)

Awesome work.Just wanted to drop a comment and say I am new to your blog and really like what I am reading.Thanks for the share
Leave A Reply Cancel Reply
Your email address will not be published.
Save my name, email, and website in this browser for the next time I comment.
- Quick Win Clinics
- Research Briefs
- A/B Testing
- Conversion Marketing
- Copywriting
- Digital Advertising
- Digital Analytics
- Digital Subscriptions
- E-commerce Marketing
- Email Marketing
- Lead Generation
- Social Marketing
- Value Proposition
- Research Services
- Video – Transparent Marketing
- Video – 15 years of marketing research in 11 minutes
- Lecture – The Web as a Living Laboratory
- Featured Research
Welcome, Login to your account.
Recover your password.
A password will be e-mailed to you.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- How to Write a Strong Hypothesis | Steps & Examples
How to Write a Strong Hypothesis | Steps & Examples
Published on May 6, 2022 by Shona McCombes . Revised on November 20, 2023.
A hypothesis is a statement that can be tested by scientific research. If you want to test a relationship between two or more variables, you need to write hypotheses before you start your experiment or data collection .
Example: Hypothesis
Daily apple consumption leads to fewer doctor’s visits.
Table of contents
What is a hypothesis, developing a hypothesis (with example), hypothesis examples, other interesting articles, frequently asked questions about writing hypotheses.
A hypothesis states your predictions about what your research will find. It is a tentative answer to your research question that has not yet been tested. For some research projects, you might have to write several hypotheses that address different aspects of your research question.
A hypothesis is not just a guess – it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Variables in hypotheses
Hypotheses propose a relationship between two or more types of variables .
- An independent variable is something the researcher changes or controls.
- A dependent variable is something the researcher observes and measures.
If there are any control variables , extraneous variables , or confounding variables , be sure to jot those down as you go to minimize the chances that research bias will affect your results.
In this example, the independent variable is exposure to the sun – the assumed cause . The dependent variable is the level of happiness – the assumed effect .
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
Step 1. Ask a question
Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project.
Step 2. Do some preliminary research
Your initial answer to the question should be based on what is already known about the topic. Look for theories and previous studies to help you form educated assumptions about what your research will find.
At this stage, you might construct a conceptual framework to ensure that you’re embarking on a relevant topic . This can also help you identify which variables you will study and what you think the relationships are between them. Sometimes, you’ll have to operationalize more complex constructs.
Step 3. Formulate your hypothesis
Now you should have some idea of what you expect to find. Write your initial answer to the question in a clear, concise sentence.
4. Refine your hypothesis
You need to make sure your hypothesis is specific and testable. There are various ways of phrasing a hypothesis, but all the terms you use should have clear definitions, and the hypothesis should contain:
- The relevant variables
- The specific group being studied
- The predicted outcome of the experiment or analysis
5. Phrase your hypothesis in three ways
To identify the variables, you can write a simple prediction in if…then form. The first part of the sentence states the independent variable and the second part states the dependent variable.
In academic research, hypotheses are more commonly phrased in terms of correlations or effects, where you directly state the predicted relationship between variables.
If you are comparing two groups, the hypothesis can state what difference you expect to find between them.
6. Write a null hypothesis
If your research involves statistical hypothesis testing , you will also have to write a null hypothesis . The null hypothesis is the default position that there is no association between the variables. The null hypothesis is written as H 0 , while the alternative hypothesis is H 1 or H a .
- H 0 : The number of lectures attended by first-year students has no effect on their final exam scores.
- H 1 : The number of lectures attended by first-year students has a positive effect on their final exam scores.
If you want to know more about the research process , methodology , research bias , or statistics , make sure to check out some of our other articles with explanations and examples.
- Sampling methods
- Simple random sampling
- Stratified sampling
- Cluster sampling
- Likert scales
- Reproducibility
Statistics
- Null hypothesis
- Statistical power
- Probability distribution
- Effect size
- Poisson distribution
Research bias
- Optimism bias
- Cognitive bias
- Implicit bias
- Hawthorne effect
- Anchoring bias
- Explicit bias
Receive feedback on language, structure, and formatting
Professional editors proofread and edit your paper by focusing on:
- Academic style
- Vague sentences
- Style consistency
See an example

A hypothesis is not just a guess — it should be based on existing theories and knowledge. It also has to be testable, which means you can support or refute it through scientific research methods (such as experiments, observations and statistical analysis of data).
Null and alternative hypotheses are used in statistical hypothesis testing . The null hypothesis of a test always predicts no effect or no relationship between variables, while the alternative hypothesis states your research prediction of an effect or relationship.
Hypothesis testing is a formal procedure for investigating our ideas about the world using statistics. It is used by scientists to test specific predictions, called hypotheses , by calculating how likely it is that a pattern or relationship between variables could have arisen by chance.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
McCombes, S. (2023, November 20). How to Write a Strong Hypothesis | Steps & Examples. Scribbr. Retrieved March 29, 2024, from https://www.scribbr.com/methodology/hypothesis/
Is this article helpful?

Shona McCombes
Other students also liked, construct validity | definition, types, & examples, what is a conceptual framework | tips & examples, operationalization | a guide with examples, pros & cons, what is your plagiarism score.
- Product Management
How to Generate and Validate Product Hypotheses
What is a product hypothesis.
A hypothesis is a testable statement that predicts the relationship between two or more variables. In product development, we generate hypotheses to validate assumptions about customer behavior, market needs, or the potential impact of product changes. These experimental efforts help us refine the user experience and get closer to finding a product-market fit.
Product hypotheses are a key element of data-driven product development and decision-making. Testing them enables us to solve problems more efficiently and remove our own biases from the solutions we put forward.
Here’s an example: ‘If we improve the page load speed on our website (variable 1), then we will increase the number of signups by 15% (variable 2).’ So if we improve the page load speed, and the number of signups increases, then our hypothesis has been proven. If the number did not increase significantly (or not at all), then our hypothesis has been disproven.
In general, product managers are constantly creating and testing hypotheses. But in the context of new product development , hypothesis generation/testing occurs during the validation stage, right after idea screening .
Now before we go any further, let’s get one thing straight: What’s the difference between an idea and a hypothesis?
Idea vs hypothesis
Innovation expert Michael Schrage makes this distinction between hypotheses and ideas – unlike an idea, a hypothesis comes with built-in accountability. “But what’s the accountability for a good idea?” Schrage asks. “The fact that a lot of people think it’s a good idea? That’s a popularity contest.” So, not only should a hypothesis be tested, but by its very nature, it can be tested.
At Railsware, we’ve built our product development services on the careful selection, prioritization, and validation of ideas. Here’s how we distinguish between ideas and hypotheses:
Idea: A creative suggestion about how we might exploit a gap in the market, add value to an existing product, or bring attention to our product. Crucially, an idea is just a thought. It can form the basis of a hypothesis but it is not necessarily expected to be proven or disproven.
- We should get an interview with the CEO of our company published on TechCrunch.
- Why don’t we redesign our website?
- The Coupler.io team should create video tutorials on how to export data from different apps, and publish them on YouTube.
- Why not add a new ‘email templates’ feature to our Mailtrap product?
Hypothesis: A way of framing an idea or assumption so that it is testable, specific, and aligns with our wider product/team/organizational goals.
Examples:
- If we add a new ‘email templates’ feature to Mailtrap, we’ll see an increase in active usage of our email-sending API.
- Creating relevant video tutorials and uploading them to YouTube will lead to an increase in Coupler.io signups.
- If we publish an interview with our CEO on TechCrunch, 500 people will visit our website and 10 of them will install our product.
Now, it’s worth mentioning that not all hypotheses require testing . Sometimes, the process of creating hypotheses is just an exercise in critical thinking. And the simple act of analyzing your statement tells whether you should run an experiment or not. Remember: testing isn’t mandatory, but your hypotheses should always be inherently testable.
Let’s consider the TechCrunch article example again. In that hypothesis, we expect 500 readers to visit our product website, and a 2% conversion rate of those unique visitors to product users i.e. 10 people. But is that marginal increase worth all the effort? Conducting an interview with our CEO, creating the content, and collaborating with the TechCrunch content team – all of these tasks take time (and money) to execute. And by formulating that hypothesis, we can clearly see that in this case, the drawbacks (efforts) outweigh the benefits. So, no need to test it.
In a similar vein, a hypothesis statement can be a tool to prioritize your activities based on impact. We typically use the following criteria:
- The quality of impact
- The size of the impact
- The probability of impact
This lets us organize our efforts according to their potential outcomes – not the coolness of the idea, its popularity among the team, etc.
Now that we’ve established what a product hypothesis is, let’s discuss how to create one.
Start with a problem statement
Before you jump into product hypothesis generation, we highly recommend formulating a problem statement. This is a short, concise description of the issue you are trying to solve. It helps teams stay on track as they formalize the hypothesis and design the product experiments. It can also be shared with stakeholders to ensure that everyone is on the same page.
The statement can be worded however you like, as long as it’s actionable, specific, and based on data-driven insights or research. It should clearly outline the problem or opportunity you want to address.
Here’s an example: Our bounce rate is high (more than 90%) and we are struggling to convert website visitors into actual users. How might we improve site performance to boost our conversion rate?
How to generate product hypotheses
Now let’s explore some common, everyday scenarios that lead to product hypothesis generation. For our teams here at Railsware, it’s when:
- There’s a problem with an unclear root cause e.g. a sudden drop in one part of the onboarding funnel. We identify these issues by checking our product metrics or reviewing customer complaints.
- We are running ideation sessions on how to reach our goals (increase MRR, increase the number of users invited to an account, etc.)
- We are exploring growth opportunities e.g. changing a pricing plan, making product improvements , breaking into a new market.
- We receive customer feedback. For example, some users have complained about difficulties setting up a workspace within the product. So, we build a hypothesis on how to help them with the setup.
BRIDGES framework for ideation
When we are tackling a complex problem or looking for ways to grow the product, our teams use BRIDGeS – a robust decision-making and ideation framework. BRIDGeS makes our product discovery sessions more efficient. It lets us dive deep into the context of our problem so that we can develop targeted solutions worthy of testing.
Between 2-8 stakeholders take part in a BRIDGeS session. The ideation sessions are usually led by a product manager and can include other subject matter experts such as developers, designers, data analysts, or marketing specialists. You can use a virtual whiteboard such as Figjam or Miro (see our Figma template ) to record each colored note.
In the first half of a BRIDGeS session, participants examine the Benefits, Risks, Issues, and Goals of their subject in the ‘Problem Space.’ A subject is anything that is being described or dealt with; for instance, Coupler.io’s growth opportunities. Benefits are the value that a future solution can bring, Risks are potential issues they might face, Issues are their existing problems, and Goals are what the subject hopes to gain from the future solution. Each descriptor should have a designated color.
After we have broken down the problem using each of these descriptors, we move into the Solution Space. This is where we develop solution variations based on all of the benefits/risks/issues identified in the Problem Space (see the Uber case study for an in-depth example).
In the Solution Space, we start prioritizing those solutions and deciding which ones are worthy of further exploration outside of the framework – via product hypothesis formulation and testing, for example. At the very least, after the session, we will have a list of epics and nested tasks ready to add to our product roadmap.
How to write a product hypothesis statement
Across organizations, product hypothesis statements might vary in their subject, tone, and precise wording. But some elements never change. As we mentioned earlier, a hypothesis statement must always have two or more variables and a connecting factor.
1. Identify variables
Since these components form the bulk of a hypothesis statement, let’s start with a brief definition.
First of all, variables in a hypothesis statement can be split into two camps: dependent and independent. Without getting too theoretical, we can describe the independent variable as the cause, and the dependent variable as the effect . So in the Mailtrap example we mentioned earlier, the ‘add email templates feature’ is the cause i.e. the element we want to manipulate. Meanwhile, ‘increased usage of email sending API’ is the effect i.e the element we will observe.
Independent variables can be any change you plan to make to your product. For example, tweaking some landing page copy, adding a chatbot to the homepage, or enhancing the search bar filter functionality.
Dependent variables are usually metrics. Here are a few that we often test in product development:
- Number of sign-ups
- Number of purchases
- Activation rate (activation signals differ from product to product)
- Number of specific plans purchased
- Feature usage (API activation, for example)
- Number of active users
Bear in mind that your concept or desired change can be measured with different metrics. Make sure that your variables are well-defined, and be deliberate in how you measure your concepts so that there’s no room for misinterpretation or ambiguity.
For example, in the hypothesis ‘Users drop off because they find it hard to set up a project’ variables are poorly defined. Phrases like ‘drop off’ and ‘hard to set up’ are too vague. A much better way of saying it would be: If project automation rules are pre-defined (email sequence to responsible, scheduled tickets creation), we’ll see a decrease in churn. In this example, it’s clear which dependent variable has been chosen and why.
And remember, when product managers focus on delighting users and building something of value, it’s easier to market and monetize it. That’s why at Railsware, our product hypotheses often focus on how to increase the usage of a feature or product. If users love our product(s) and know how to leverage its benefits, we can spend less time worrying about how to improve conversion rates or actively grow our revenue, and more time enhancing the user experience and nurturing our audience.
2. Make the connection
The relationship between variables should be clear and logical. If it’s not, then it doesn’t matter how well-chosen your variables are – your test results won’t be reliable.
To demonstrate this point, let’s explore a previous example again: page load speed and signups.
Through prior research, you might already know that conversion rates are 3x higher for sites that load in 1 second compared to sites that take 5 seconds to load. Since there appears to be a strong connection between load speed and signups in general, you might want to see if this is also true for your product.
Here are some common pitfalls to avoid when defining the relationship between two or more variables:
Relationship is weak. Let’s say you hypothesize that an increase in website traffic will lead to an increase in sign-ups. This is a weak connection since website visitors aren’t necessarily motivated to use your product; there are more steps involved. A better example is ‘If we change the CTA on the pricing page, then the number of signups will increase.’ This connection is much stronger and more direct.
Relationship is far-fetched. This often happens when one of the variables is founded on a vanity metric. For example, increasing the number of social media subscribers will lead to an increase in sign-ups. However, there’s no particular reason why a social media follower would be interested in using your product. Oftentimes, it’s simply your social media content that appeals to them (and your audience isn’t interested in a product).
Variables are co-dependent. Variables should always be isolated from one another. Let’s say we removed the option “Register with Google” from our app. In this case, we can expect fewer users with Google workspace accounts to register. Obviously, it’s because there’s a direct dependency between variables (no registration with Google→no users with Google workspace accounts).
3. Set validation criteria
First, build some confirmation criteria into your statement . Think in terms of percentages (e.g. increase/decrease by 5%) and choose a relevant product metric to track e.g. activation rate if your hypothesis relates to onboarding. Consider that you don’t always have to hit the bullseye for your hypothesis to be considered valid. Perhaps a 3% increase is just as acceptable as a 5% one. And it still proves that a connection between your variables exists.
Secondly, you should also make sure that your hypothesis statement is realistic . Let’s say you have a hypothesis that ‘If we show users a banner with our new feature, then feature usage will increase by 10%.’ A few questions to ask yourself are: Is 10% a reasonable increase, based on your current feature usage data? Do you have the resources to create the tests (experimenting with multiple variations, distributing on different channels: in-app, emails, blog posts)?
Null hypothesis and alternative hypothesis
In statistical research, there are two ways of stating a hypothesis: null or alternative. But this scientific method has its place in hypothesis-driven development too…
Alternative hypothesis: A statement that you intend to prove as being true by running an experiment and analyzing the results. Hint: it’s the same as the other hypothesis examples we’ve described so far.
Example: If we change the landing page copy, then the number of signups will increase.
Null hypothesis: A statement you want to disprove by running an experiment and analyzing the results. It predicts that your new feature or change to the user experience will not have the desired effect.
Example: The number of signups will not increase if we make a change to the landing page copy.
What’s the point? Well, let’s consider the phrase ‘innocent until proven guilty’ as a version of a null hypothesis. We don’t assume that there is any relationship between the ‘defendant’ and the ‘crime’ until we have proof. So, we run a test, gather data, and analyze our findings — which gives us enough proof to reject the null hypothesis and validate the alternative. All of this helps us to have more confidence in our results.
Now that you have generated your hypotheses, and created statements, it’s time to prepare your list for testing.
Prioritizing hypotheses for testing
Not all hypotheses are created equal. Some will be essential to your immediate goal of growing the product e.g. adding a new data destination for Coupler.io. Others will be based on nice-to-haves or small fixes e.g. updating graphics on the website homepage.
Prioritization helps us focus on the most impactful solutions as we are building a product roadmap or narrowing down the backlog . To determine which hypotheses are the most critical, we use the MoSCoW framework. It allows us to assign a level of urgency and importance to each product hypothesis so we can filter the best 3-5 for testing.
MoSCoW is an acronym for Must-have, Should-have, Could-have, and Won’t-have. Here’s a breakdown:
- Must-have – hypotheses that must be tested, because they are strongly linked to our immediate project goals.
- Should-have – hypotheses that are closely related to our immediate project goals, but aren’t the top priority.
- Could-have – hypotheses of nice-to-haves that can wait until later for testing.
- Won’t-have – low-priority hypotheses that we may or may not test later on when we have more time.
How to test product hypotheses
Once you have selected a hypothesis, it’s time to test it. This will involve running one or more product experiments in order to check the validity of your claim.
The tricky part is deciding what type of experiment to run, and how many. Ultimately, this all depends on the subject of your hypothesis – whether it’s a simple copy change or a whole new feature. For instance, it’s not necessary to create a clickable prototype for a landing page redesign. In that case, a user-wide update would do.
On that note, here are some of the approaches we take to hypothesis testing at Railsware:
A/B testing
A/B or split testing involves creating two or more different versions of a webpage/feature/functionality and collecting information about how users respond to them.
Let’s say you wanted to validate a hypothesis about the placement of a search bar on your application homepage. You could design an A/B test that shows two different versions of that search bar’s placement to your users (who have been split equally into two camps: a control group and a variant group). Then, you would choose the best option based on user data. A/B tests are suitable for testing responses to user experience changes, especially if you have more than one solution to test.
Prototyping
When it comes to testing a new product design, prototyping is the method of choice for many Lean startups and organizations. It’s a cost-effective way of collecting feedback from users, fast, and it’s possible to create prototypes of individual features too. You may take this approach to hypothesis testing if you are working on rolling out a significant new change e.g adding a brand-new feature, redesigning some aspect of the user flow, etc. To control costs at this point in the new product development process , choose the right tools — think Figma for clickable walkthroughs or no-code platforms like Bubble.
Deliveroo feature prototype example
Let’s look at how feature prototyping worked for the food delivery app, Deliveroo, when their product team wanted to ‘explore personalized recommendations, better filtering and improved search’ in 2018. To begin, they created a prototype of the customer discovery feature using web design application, Framer.
One of the most important aspects of this feature prototype was that it contained live data — real restaurants, real locations. For test users, this made the hypothetical feature feel more authentic. They were seeing listings and recommendations for real restaurants in their area, which helped immerse them in the user experience, and generate more honest and specific feedback. Deliveroo was then able to implement this feedback in subsequent iterations.
Asking your users
Interviewing customers is an excellent way to validate product hypotheses. It’s a form of qualitative testing that, in our experience, produces better insights than user surveys or general user research. Sessions are typically run by product managers and involve asking in-depth interview questions to one customer at a time. They can be conducted in person or online (through a virtual call center , for instance) and last anywhere between 30 minutes to 1 hour.
Although CustDev interviews may require more effort to execute than other tests (the process of finding participants, devising questions, organizing interviews, and honing interview skills can be time-consuming), it’s still a highly rewarding approach. You can quickly validate assumptions by asking customers about their pain points, concerns, habits, processes they follow, and analyzing how your solution fits into all of that.
Wizard of Oz
The Wizard of Oz approach is suitable for gauging user interest in new features or functionalities. It’s done by creating a prototype of a fake or future feature and monitoring how your customers or test users interact with it.
For example, you might have a hypothesis that your number of active users will increase by 15% if you introduce a new feature. So, you design a new bare-bones page or simple button that invites users to access it. But when they click on the button, a pop-up appears with a message such as ‘coming soon.’
By measuring the frequency of those clicks, you could learn a lot about the demand for this new feature/functionality. However, while these tests can deliver fast results, they carry the risk of backfiring. Some customers may find fake features misleading, making them less likely to engage with your product in the future.
User-wide updates
One of the speediest ways to test your hypothesis is by rolling out an update for all users. It can take less time and effort to set up than other tests (depending on how big of an update it is). But due to the risk involved, you should stick to only performing these kinds of tests on small-scale hypotheses. Our teams only take this approach when we are almost certain that our hypothesis is valid.
For example, we once had an assumption that the name of one of Mailtrap ’s entities was the root cause of a low activation rate. Being an active Mailtrap customer meant that you were regularly sending test emails to a place called ‘Demo Inbox.’ We hypothesized that the name was confusing (the word ‘demo’ implied it was not the main inbox) and this was preventing new users from engaging with their accounts. So, we updated the page, changed the name to ‘My Inbox’ and added some ‘to-do’ steps for new users. We saw an increase in our activation rate almost immediately, validating our hypothesis.
Feature flags
Creating feature flags involves only releasing a new feature to a particular subset or small percentage of users. These features come with a built-in kill switch; a piece of code that can be executed or skipped, depending on who’s interacting with your product.
Since you are only showing this new feature to a selected group, feature flags are an especially low-risk method of testing your product hypothesis (compared to Wizard of Oz, for example, where you have much less control). However, they are also a little bit more complex to execute than the others — you will need to have an actual coded product for starters, as well as some technical knowledge, in order to add the modifiers ( only when… ) to your new coded feature.
Let’s revisit the landing page copy example again, this time in the context of testing.
So, for the hypothesis ‘If we change the landing page copy, then the number of signups will increase,’ there are several options for experimentation. We could share the copy with a small sample of our users, or even release a user-wide update. But A/B testing is probably the best fit for this task. Depending on our budget and goal, we could test several different pieces of copy, such as:
- The current landing page copy
- Copy that we paid a marketing agency 10 grand for
- Generic copy we wrote ourselves, or removing most of the original copy – just to see how making even a small change might affect our numbers.
Remember, every hypothesis test must have a reasonable endpoint. The exact length of the test will depend on the type of feature/functionality you are testing, the size of your user base, and how much data you need to gather. Just make sure that the experiment running time matches the hypothesis scope. For instance, there is no need to spend 8 weeks experimenting with a piece of landing page copy. That timeline is more appropriate for say, a Wizard of Oz feature.
Recording hypotheses statements and test results
Finally, it’s time to talk about where you will write down and keep track of your hypotheses. Creating a single source of truth will enable you to track all aspects of hypothesis generation and testing with ease.
At Railsware, our product managers create a document for each individual hypothesis, using tools such as Coda or Google Sheets. In that document, we record the hypothesis statement, as well as our plans, process, results, screenshots, product metrics, and assumptions.
We share this document with our team and stakeholders, to ensure transparency and invite feedback. It’s also a resource we can refer back to when we are discussing a new hypothesis — a place where we can quickly access information relating to a previous test.
Understanding test results and taking action
The other half of validating product hypotheses involves evaluating data and drawing reasonable conclusions based on what you find. We do so by analyzing our chosen product metric(s) and deciding whether there is enough data available to make a solid decision. If not, we may extend the test’s duration or run another one. Otherwise, we move forward. An experimental feature becomes a real feature, a chatbot gets implemented on the customer support page, and so on.
Something to keep in mind: the integrity of your data is tied to how well the test was executed, so here are a few points to consider when you are testing and analyzing results:
Gather and analyze data carefully. Ensure that your data is clean and up-to-date when running quantitative tests and tracking responses via analytics dashboards. If you are doing customer interviews, make sure to record the meetings (with consent) so that your notes will be as accurate as possible.
Conduct the right amount of product experiments. It can take more than one test to determine whether your hypothesis is valid or invalid. However, don’t waste too much time experimenting in the hopes of getting the result you want. Know when to accept the evidence and move on.
Choose the right audience segment. Don’t cast your net too wide. Be specific about who you want to collect data from prior to running the test. Otherwise, your test results will be misleading and you won’t learn anything new.
Watch out for bias. Avoid confirmation bias at all costs. Don’t make the mistake of including irrelevant data just because it bolsters your results. For example, if you are gathering data about how users are interacting with your product Monday-Friday, don’t include weekend data just because doing so would alter the data and ‘validate’ your hypothesis.
- Not all failed hypotheses should be treated as losses. Even if you didn’t get the outcome you were hoping for, you may still have improved your product. Let’s say you implemented SSO authentication for premium users, but unfortunately, your free users didn’t end up switching to premium plans. In this case, you still added value to the product by streamlining the login process for paying users.
- Yes, taking a hypothesis-driven approach to product development is important. But remember, you don’t have to test everything . Use common sense first. For example, if your website copy is confusing and doesn’t portray the value of the product, then you should still strive to replace it with better copy – regardless of how this affects your numbers in the short term.
Wrapping Up
The process of generating and validating product hypotheses is actually pretty straightforward once you’ve got the hang of it. All you need is a valid question or problem, a testable statement, and a method of validation. Sure, hypothesis-driven development requires more of a time commitment than just ‘giving it a go.’ But ultimately, it will help you tune the product to the wants and needs of your customers.
If you share our data-driven approach to product development and engineering, check out our services page to learn more about how we work with our clients!
What Is Experiment Marketing? (With Tips and Examples)

Do you feel like your marketing efforts aren’t quite hitting the mark? There’s an approach that could open up a whole new world of growth for your business: marketing experimentation.
This isn’t your typical marketing spiel. It’s about trying new things, seeing what sticks, and learning as you go. Think of it as the marketing world’s lab, where creativity meets strategy in a quest to wow audiences and break the internet.
In this article, we’ll talk about what are marketing experiments, offer some killer tips to implement and analyze marketing experiments, and showcase examples that turned heads.
Ready to dive in?
Shortcuts ✂️
What is a marketing experiment, why should you run marketing experiments, how to design marketing experiments, how to implement marketing experimentation, how to analyze your experiment marketing campaign, 3 real-life examples of experiment marketing.
Marketing experimentation is like a scientific journey into how customers respond to your marketing campaigns.
Imagine you’ve got this wild idea for your PPC ads. Instead of just hoping it’ll work, you test it. That’s your experiment. You’re not just throwing stuff at the wall to see what sticks. You’re carefully choosing your shot, aiming, and then checking the impact.
Marketing experiments involve testing lots of things, like new products and how your marketing messages affect people’s actions on your website.
Running a marketing experiment before implementing new strategies is essential because it serves as a form of insurance for future marketing endeavors.
By conducting marketing experiments, you can assess potential risks and ensure that your efforts align with the desired outcomes you seek.
One of the main advantages of marketing experiments is that they provide insight into your target audience, helping you better understand your customers and optimize your marketing strategies for better results.
By ensuring that your new marketing strategies are the most impactful, you’ll achieve better campaign performance and a better return on investment.
Now that we’ve unpacked what are marketing experiments, let’s dive deeper. To design a successful marketing experiment, follow the steps below.
1. Identify campaign objectives
Establishing clear campaign objectives is essential. What do you want to accomplish? What are your most important goals?
To identify campaign objectives, you can:
- Review your organizational goals
- Brainstorm with your team
- Use the SMART framework (Specific, Measurable, Achievable, Relevant, Time-bound) to define your objectives
Setting specific objectives ensures that your marketing experiment is geared towards addressing critical business challenges and promoting growth. This focus will also help you:
- Select the most relevant marketing channels
- Define success metrics
- Create more successful campaigns
- Make better business decisions
2. Make a good hypothesis
Making a hypothesis before conducting marketing experiments is crucial because it provides a clear direction for the experiment and helps in setting specific goals to be achieved.
A hypothesis allows marketers to articulate their assumptions about the expected outcomes of various changes or strategies they plan to implement.
By formulating a hypothesis, marketers can create measurable and testable statements that guide the experiment and provide a basis for making informed decisions based on results.
It helps in understanding what impact certain changes may have on your customers or desired outcomes, thus enabling marketers to design effective experiments that yield valuable insights.
3. Select the right marketing channels
Choosing the right marketing channels is crucial for ensuring that your campaign reaches your customers effectively.
To select the most appropriate channels, you should consider factors such as the demographics, interests, and behaviors of your customers, as well as the characteristics of your product or service.
Additionally, it’s essential to analyze your competitors and broader industry trends to understand which marketing channels are most effective in your niche.
4. Define success metrics
Establishing success metrics is a crucial step in evaluating the effectiveness of your marketing experiments.
Defining success metrics begins with identifying your experiment’s objectives and then choosing relevant metrics that can help you measure your success. You’ll also want to set targets for each metric.
Common success metrics include:
- conversion rate,
- cost per acquisition,
- and customer lifetime value.
When selecting appropriate metrics for measuring the success of your marketing experiments, you should consider the nature of the experiment itself – whether it involves email campaigns, landing pages, blogs, or other platforms.
For example, if the experiment involves testing email subject lines, tracking the open rate would be crucial to understanding how engaging the subject lines are for the audience.
When testing a landing page, metrics such as the submission rate during the testing period can reveal how effective the page is in converting visitors.
On the other hand, if the experiment focuses on blogs, metrics like average time on page can indicate the level of reader engagement.
Once you’ve finished designing your marketing experiments, it’s time to put them into action.
This involves setting up test groups, running tests, and then monitoring and adjusting the marketing campaigns as needed.
Let’s see the implementation process in more detail!
1. Setting up test groups
Establishing test groups is essential for accurately comparing different marketing strategies. To set up test groups, you need to define your target audience, split them into groups, create various versions of your content, and configure the test environment.
Setting up test groups ensures your marketing experiment takes place under controlled conditions, enabling you to compare results more accurately.
This, in turn, will help you identify the most effective tactics for your audience.
2. Running multiple tests simultaneously
By conducting multiple tests at the same time, you’ll be able to:
- Collect more data and insights
- Foster informed decision-making
- Improve campaign performance
A/B testing tools that allow for simultaneous experiments can be a valuable asset for your marketing team. By leveraging these tools, you can streamline your experiment marketing process and ensure that you’re getting the best results from your efforts.
3. Monitoring and adjusting the campaign
Monitoring and adjusting your marketing experiment campaign is essential to ensure that the experiment stays on track and achieves its objectives.
To do so, you should regularly:
- Review the data from your experiment to identify any issues.
- Make necessary adjustments to keep the experiment on track.
- Evaluate the results of those adjustments.
Proactive monitoring and adjustment of your campaign helps identify potential problems early, enabling you to make decisions based on data and optimize your experiments.
As discussed above, after implementing your marketing experiment you’ll want to analyze the results and learn from the insights gained.
Remember that the insights gained from your marketing experiments are not only valuable for the current campaign you’re running but also for informing your future marketing initiatives.
By continuously iterating and improving your marketing efforts based on what you learn from your experiments, you can unlock sustained growth and success for your business.
1. Evaluating the success of your campaign
Assessing the success of your marketing experiment is vital, and essentially it involves determining if the campaign met its objectives and whether the marketing strategies were effective.
To evaluate the success of your marketing campaigns, you can:
- Compare website visits during the campaign period with traffic from a previous period
- Utilize control groups to measure the effect of the campaign
- Analyze data such as conversion rates and engagement levels
2. Identifying patterns and trends
Recognizing patterns and trends in the data from your marketing experiments can provide valuable insights that can be leveraged to optimize future marketing efforts.
Patterns indicate that many different potential customers are experiencing the same reaction to your campaigns, for better or for worse.
To identify these patterns and trends, you can:
- Visualize customer data
- Combine experiments and data sources
- Conduct market research
- Analyze marketing analytics
By identifying patterns and trends in your marketing experiment data, you can uncover insights that will help you refine your marketing strategies and make data-driven decisions for your future marketing endeavors.
3. Applying learnings to future campaigns
Leveraging the insights gained from your marketing experiment in future campaigns ensures that you can continuously improve and grow the effectiveness of your marketing efforts.
Applying learnings from your marketing experiments, quite simply, involves:
- analyzing the data,
- identifying the successful strategies,
- documenting key learnings, and
- applying these insights to future campaigns
By consistently applying the learnings from your marketing experiments to your future digital marketing efforts, you can ensure that your marketing strategies are data-driven, optimized for success, and always improving.
Now that we’ve talked about the advantages of experiment marketing and the steps involved, let’s dive into real-life cases that showcase the impact of this approach.
By exploring these experiment ideas, you’ll get a clear picture of how you can harness experiment marketing to get superior results.
You can take these insights and apply them to your own marketing experiments, boosting your campaign’s performance and your ROI.
Example 1: Homepage headline experiment
Bukvybag , a Swedish fashion brand selling premium bags, was on a mission to find the perfect homepage headline that would resonate with its website visitors.
They tested multiple headlines with OptiMonk’s Dynamic Content feature to discover which headline option would be most successful with their customers and boost conversion rates.
Take a look at the headlines they experimented with, which all focused on different value propositions.
Original: “ Versatile bags & accessories”

Variant A: “Stand out from the crowd with our fashion-forward and unique bags”

Variant B: “Discover the ultimate travel companion that combines style and functionality”

Variant C: “ Premium quality bags designed for exploration and adventure”

The results? Bukvybag’s conversions shot up by a whopping 45% as a result of this A/B testing!
Example 2: Product page experiment
Varnish & Vine , an ecommerce store selling premium plants, discovered that there was a lot they could do to optimize their product pages.
They turned to OptiMonk’s Smart Product Page Optimizer and used the AI-powered tool to achieve a stunning transformation.
First, the tool analyzed their current product pages. Then, it crafted captivating headlines, subheadlines, and lists of benefits for each product page automatically, which were tailored to their audience.

After the changes, the tool ran A/B tests automatically, so the team was able to compare their previous results with their AI-tailored product pages.
The outcome? A 12% boost in orders and a jaw-dropping 43% surge in revenue, all thanks to A/B testing the AI-optimized product pages.
Example 3: Email popup experiment
Crown & Paw , an ecommerce brand selling artistic pet portraits, had been using a simple Klaviyo popup that was underperforming, so they decided to kick it up a notch with a multi-step popup instead.
On the first page, they offered an irresistible discount, and as a plus they promised personalized product recommendations.

In the second step, once visitors had demonstrated that they wanted to grab that 10% off, they asked simple questions to learn about their interests. Here are the questions they asked:

For the 95% who answered their questions, Crown & Paw revealed personalized product recommendations alongside the discount code in the final step.

The result? A 4.03% conversion rate, and a massive 2.5X increase from their previous email popup strategy.
This is tangible proof that creatively engaging your audience can work wonders.
What is an example of a market experiment?
An example of a marketing experiment could involve an e-commerce company testing the impact of offering free shipping on orders over $50 for a month. If they find that the promotion significantly increases total sales revenue and average order value, they may decide to implement the free shipping offer as a permanent strategy.
What is experimental data in marketing?
Experimental data in marketing refers to information collected through tests or experiments designed to investigate specific hypotheses. This data is obtained by running experiments and measuring outcomes to draw conclusions about marketing strategies.
How do you run a marketing experiment?
To run a marketing experiment, start by defining your objective and hypothesis. Then, create control and experimental groups, collect relevant data, analyze the results, and make decisions based on the findings. This iterative process helps refine marketing strategies for better performance.
What are some real-life examples of experiment marketing?
Real-life examples of marketing experiments include A/B testing email subject lines to determine which leads to higher open rates, testing different ad creatives to measure click-through rates, and experimenting with pricing strategies to see how they affect sales and customer behavior.
How to brainstorm and prioritize ideas for marketing experiments?
Start by considering your current objectives and priorities for the upcoming quarter or year. Reflect on your past marketing strategies to identify successful approaches and areas where performance was lacking. Analyze your historical data to gain insights into what has worked previously and what has not. This examination may reveal lingering uncertainties or gaps in your understanding of which strategies are most effective. Use this information to generate new ideas for future experiments aimed at improving performance. After generating a list of potential strategies, prioritize them based on factors such as relevance to your goals, timeliness of implementation, and expected return on investment.
Wrapping up
Experiment marketing is a powerful tool for businesses and marketers looking to optimize their marketing strategies and drive better results.
By designing, implementing, analyzing, and learning from marketing experiments, you can ensure that your marketing efforts are data-driven, focused on the most impactful tactics, and continuously improving.
Want to level up your marketing strategy with a bit of experimenting? Then give OptiMonk a try today by signing up for a free account!

Nikolett Lorincz
You may also like.

8 Website Contact Form Examples & How to Create One

How to Get Customer Reviews Easily from Customer Feedback

How to Leverage Customer Pain Points to Increase Sales
- Összes funkció
- Grow Your Email List
- Grow Your Messenger List
- Reduce Cart Abandonment
- Increase Avg. Cart Value
- Promote Special Offers
- Collect Customer Feedback
- Facilitate Social Sharing
- For Mid-Market/Enterprise users
- Partners program
- Terms & Conditions
- Security & Privacy
- We’re Hiring! ????
- eCommerce Guides
- Case Studies
- All features
- Book a demo
Partner with us
- Partner program
- Become an affiliate
- Agency program
- Success Stories
- We're hiring
- Tactic Library
- Help center / Support
- Optimonk vs. Optinmonster
- OptiMonk vs. Klaviyo
- OptiMonk vs. Privy
- OptiMonk vs. Dynamic Yield
- OptiMonk vs. Justuno
- OptiMonk vs. Nosto
- OptiMonk vs. VWo
- © OptiMonk. All rights reserved!
- Terms of Use
- Privacy Policy
- Cookie Policy
Product updates: Introducing OptiMonk AI

Marketing Research Design & Analysis 2019
5 hypothesis testing.
This chapter is primarily based on Field, A., Miles J., & Field, Z. (2012): Discovering Statistics Using R. Sage Publications, chapters 5, 9, 15, 18 .
You can download the corresponding R-Code here
5.1 Introduction
We test hypotheses because we are confined to taking samples – we rarely work with the entire population. In the previous chapter, we introduced the standard error (i.e., the standard deviation of a large number of hypothetical samples) as an estimate of how well a particular sample represents the population. We also saw how we can construct confidence intervals around the sample mean \(\bar x\) by computing \(SE_{\bar x}\) as an estimate of \(\sigma_{\bar x}\) using \(s\) as an estimate of \(\sigma\) and calculating the 95% CI as \(\bar x \pm 1.96 * SE_{\bar x}\) . Although we do not know the true population mean ( \(\mu\) ), we might have an hypothesis about it and this would tell us how the corresponding sampling distribution looks like. Based on the sampling distribution of the hypothesized population mean, we could then determine the probability of a given sample assuming that the hypothesis is true .
Let us again begin by assuming we know the entire population using the example of music listening times among students from the previous example. As a reminder, the following plot shows the distribution of music listening times in the population of WU students.

In this example, the population mean ( \(\mu\) ) is equal to 19.98, and the population standard deviation \(\sigma\) is equal to 14.15.
5.1.1 The null hypothesis
Let us assume that we were planning to take a random sample of 50 students from this population and our hypothesis was that the mean listening time is equal to some specific value \(\mu_0\) , say \(10\) . This would be our null hypothesis . The null hypothesis refers to the statement that is being tested and is usually a statement of the status quo, one of no difference or no effect. In our example, the null hypothesis would state that there is no difference between the true population mean \(\mu\) and the hypothesized value \(\mu_0\) (in our example \(10\) ), which can be expressed as follows:
\[ H_0: \mu = \mu_0 \] When conducting research, we are usually interested in providing evidence against the null hypothesis. If we then observe sufficient evidence against it and our estimate is said to be significant. If the null hypothesis is rejected, this is taken as support for the alternative hypothesis . The alternative hypothesis assumes that some difference exists, which can be expressed as follows:
\[ H_1: \mu \neq \mu_0 \] Accepting the alternative hypothesis in turn will often lead to changes in opinions or actions. Note that while the null hypothesis may be rejected, it can never be accepted based on a single test. If we fail to reject the null hypothesis, it means that we simply haven’t collected enough evidence against the null hypothesis to disprove it. In classical hypothesis testing, there is no way to determine whether the null hypothesis is true. Hypothesis testing provides a means to quantify to what extent the data from our sample is in line with the null hypothesis.
In order to quantify the concept of “sufficient evidence” we look at the theoretical distribution of the sample means given our null hypothesis and the sample standard error. Using the available information we can infer the sampling distribution for our null hypothesis. Recall that the standard deviation of the sampling distribution (i.e., the standard error of the mean) is given by \(\sigma_{\bar x}={\sigma \over \sqrt{n}}\) , and thus can be computed as follows:
Since we know from the central limit theorem that the sampling distribution is normal for large enough samples, we can now visualize the expected sampling distribution if our null hypothesis was in fact true (i.e., if the was no difference between the true population mean and the hypothesized mean of 10).

We also know that 95% of the probability is within 1.96 standard deviations from the mean. Values higher than that are rather unlikely, if our hypothesis about the population mean was indeed true. This is shown by the shaded area, also known as the “rejection region”. To test our hypothesis that the population mean is equal to \(10\) , let us take a random sample from the population.

The mean listening time in the sample (black line) \(\bar x\) is 18.59. We can already see from the graphic above that such a value is rather unlikely under the hypothesis that the population mean is \(10\) . Intuitively, such a result would therefore provide evidence against our null hypothesis. But how could we quantify specifically how unlikely it is to obtain such a value and decide whether or not to reject the null hypothesis? Significance tests can be used to provide answers to these questions.
5.1.2 Statistical inference on a sample
5.1.2.1 test statistic, 5.1.2.1.1 z-scores.
Let’s go back to the sampling distribution above. We know that 95% of all values will fall within 1.96 standard deviations from the mean. So if we could express the distance between our sample mean and the null hypothesis in terms of standard deviations, we could make statements about the probability of getting a sample mean of the observed magnitude (or more extreme values). Essentially, we would like to know how many standard deviations ( \(\sigma_{\bar x}\) ) our sample mean ( \(\bar x\) ) is away from the population mean if the null hypothesis was true ( \(\mu_0\) ). This can be formally expressed as follows:
\[ \bar x- \mu_0 = z \sigma_{\bar x} \]
In this equation, z will tell us how many standard deviations the sample mean \(\bar x\) is away from the null hypothesis \(\mu_0\) . Solving for z gives us:
\[ z = {\bar x- \mu_0 \over \sigma_{\bar x}}={\bar x- \mu_0 \over \sigma / \sqrt{n}} \]
This standardized value (or “z-score”) is also referred to as a test statistic . Let’s compute the test statistic for our example above:
To make a decision on whether the difference can be deemed statistically significant, we now need to compare this calculated test statistic to a meaningful threshold. In order to do so, we need to decide on a significance level \(\alpha\) , which expresses the probability of finding an effect that does not actually exist (i.e., Type I Error). You can find a detailed discussion of this point at the end of this chapter. For now, we will adopt the widely accepted significance level of 5% and set \(\alpha\) to 0.05. The critical value for the normal distribution and \(\alpha\) = 0.05 can be computed using the qnorm() function as follows:
We use 0.975 and not 0.95 since we are running a two-sided test and need to account for the rejection region at the other end of the distribution. Recall that for the normal distribution, 95% of the total probability falls within 1.96 standard deviations of the mean, so that higher (absolute) values provide evidence against the null hypothesis. Generally, we speak of a statistically significant effect if the (absolute) calculated test statistic is larger than the (absolute) critical value. We can easily check if this is the case in our example:
Since the absolute value of the calculated test statistic is larger than the critical value, we would reject \(H_0\) and conclude that the true population mean \(\mu\) is significantly different from the hypothesized value \(\mu_0 = 10\) .
5.1.2.1.2 t-statistic
You may have noticed that the formula for the z-score above assumes that we know the true population standard deviation ( \(\sigma\) ) when computing the standard deviation of the sampling distribution ( \(\sigma_{\bar x}\) ) in the denominator. However, the population standard deviation is usually not known in the real world and therefore represents another unknown population parameter which we have to estimate from the sample. We saw in the previous chapter that we usually use \(s\) as an estimate of \(\sigma\) and \(SE_{\bar x}\) as and estimate of \(\sigma_{\bar x}\) . Intuitively, we should be more conservative regarding the critical value that we used above to assess whether we have a significant effect to reflect this uncertainty about the true population standard deviation. That is, the threshold for a “significant” effect should be higher to safeguard against falsely claiming a significant effect when there is none. If we replace \(\sigma_{\bar x}\) by it’s estimate \(SE_{\bar x}\) in the formula for the z-score, we get a new test statistic (i.e, the t-statistic ) with its own distribution (the t-distribution ):
\[ t = {\bar x- \mu_0 \over SE_{\bar x}}={\bar x- \mu_0 \over s / \sqrt{n}} \]
Here, \(\bar X\) denotes the sample mean and \(s\) the sample standard deviation. The t-distribution has more probability in its “tails”, i.e. farther away from the mean. This reflects the higher uncertainty introduced by replacing the population standard deviation by its sample estimate. Intuitively, this is particularly relevant for small samples, since the uncertainty about the true population parameters decreases with increasing sample size. This is reflected by the fact that the exact shape of the t-distribution depends on the degrees of freedom , which is the sample size minus one (i.e., \(n-1\) ). To see this, the following graph shows the t-distribution with different degrees of freedom for a two-tailed test and \(\alpha = 0.05\) . The grey curve shows the normal distribution.

Notice that as \(n\) gets larger, the t-distribution gets closer and closer to the normal distribution, reflecting the fact that the uncertainty introduced by \(s\) is reduced. To summarize, we now have an estimate for the standard deviation of the distribution of the sample mean (i.e., \(SE_{\bar x}\) ) and an appropriate distribution that takes into account the necessary uncertainty (i.e., the t-distribution). Let us now compute the t-statistic according to the formula above:
Notice that the value of the t-statistic is higher compared to the z-score (4.29). This can be attributed to the fact that by using the \(s\) as and estimate of \(\sigma\) , we underestimate the true population standard deviation. Hence, the critical value would need to be larger to adjust for this. This is what the t-distribution does. Let us compute the critical value from the t-distribution with n - 1 degrees of freedom.
Again, we use 0.975 and not 0.95 since we are running a two-sided test and need to account for the rejection region at the other end of the distribution. Notice that the new critical value based on the t-distributionis larger, to reflect the uncertainty when estimating \(\sigma\) from \(s\) . Now we can see that the calculated test statistic is still larger than the critical value.
The following graphics shows that the calculated test statistic (red line) falls into the rejection region so that in our example, we would reject the null hypothesis that the true population mean is equal to \(10\) .

Decision: Reject \(H_0\) , given that the calculated test statistic is larger than critical value.
Something to keep in mind here is the fact the test statistic is a function of the sample size. This, as \(n\) gets large, the test statistic gets larger as well and we are more likely to find a significant effect. This reflects the decrease in uncertainty about the true population mean as our sample size increases.
5.1.2.2 P-values
In the previous section, we computed the test statistic, which tells us how close our sample is to the null hypothesis. The p-value corresponds to the probability that the test statistic would take a value as extreme or more extreme than the one that we actually observed, assuming that the null hypothesis is true . It is important to note that this is a conditional probability : we compute the probability of observing a sample mean (or a more extreme value) conditional on the assumption that the null hypothesis is true. The pnorm() function can be used to compute this probability. It is the cumulative probability distribution function of the `normal distribution. Cumulative probability means that the function returns the probability that the test statistic will take a value less than or equal to the calculated test statistic given the degrees of freedom. However, we are interested in obtaining the probability of observing a test statistic larger than or equal to the calculated test statistic under the null hypothesis (i.e., the p-value). Thus, we need to subtract the cumulative probability from 1. In addition, since we are running a two-sided test, we need to multiply the probability by 2 to account for the rejection region at the other side of the distribution.
This value corresponds to the probability of observing a mean equal to or larger than the one we obtained from our sample, if the null hypothesis was true. As you can see, this probability is very low. A small p-value signals that it is unlikely to observe the calculated test statistic under the null hypothesis. To decide whether or not to reject the null hypothesis, we would now compare this value to the level of significance ( \(\alpha\) ) that we chose for our test. For this example, we adopt the widely accepted significance level of 5%, so any test results with a p-value < 0.05 would be deemed statistically significant. Note that the p-value is directly related to the value of the test statistic. The relationship is such that the higher (lower) the value of the test statistic, the lower (higher) the p-value.
Decision: Reject \(H_0\) , given that the p-value is smaller than 0.05.
5.1.2.3 Confidence interval
For a given statistic calculated for a sample of observations (e.g., listening times), a 95% confidence interval can be constructed such that in 95% of samples, the true value of the true population mean will fall within its limits. If the parameter value specified in the null hypothesis (here \(10\) ) does not lie within the bounds, we reject \(H_0\) . Building on what we learned about confidence intervals in the previous chapter, the 95% confidence interval based on the t-distribution can be computed as follows:
\[ CI_{lower} = {\bar x} - t_{1-{\alpha \over 2}} * SE_{\bar x} \\ CI_{upper} = {\bar x} + t_{1-{\alpha \over 2}} * SE_{\bar x} \]
It is easy to compute this interval manually:
The interpretation of this interval is as follows: if we would (hypothetically) take 100 samples and calculated the mean and confidence interval for each of them, then the true population mean would be included in 95% of these intervals. The CI is informative when reporting the result of your test, since it provides an estimate of the uncertainty associated with the test result. From the test statistic or the p-value alone, it is not easy to judge in which range the true population parameter is located. The CI provides an estimate of this range.
Decision: Reject \(H_0\) , given that the parameter value from the null hypothesis ( \(10\) ) is not included in the interval.
To summarize, you can see that we arrive at the same conclusion (i.e., reject \(H_0\) ), irrespective if we use the test statistic, the p-value, or the confidence interval. However, keep in mind that rejecting the null hypothesis does not prove the alternative hypothesis (we can merely provide support for it). Rather, think of the p-value as the chance of obtaining the data we’ve collected assuming that the null hypothesis is true. You should report the confidence interval to provide an estimate of the uncertainty associated with your test results.
5.1.3 Choosing the right test
The test statistic, as we have seen, measures how close the sample is to the null hypothesis and often follows a well-known distribution (e.g., normal, t, or chi-square). To select the correct test, various factors need to be taken into consideration. Some examples are:
- On what scale are your variables measured (categorical vs. continuous)?
- Do you want to test for relationships or differences?
- If you test for differences, how many groups would you like to test?
- For parametric tests, are the assumptions fulfilled?
The previous discussion used a one sample t-test as an example, which requires that variable is measured on an interval or ratio scale. If you are confronted with other settings, the following flow chart provides a rough guideline on selecting the correct test:

Flowchart for selecting an appropriate test (source: McElreath, R. (2016): Statistical Rethinking, p. 2)
For a detailed overview over the different type of tests, please also refer to this overview by the UCLA.
5.1.3.1 Parametric vs. non-parametric tests
A basic distinction can be made between parametric and non-parametric tests. Parametric tests require that variables are measured on an interval or ratio scale and that the sampling distribution follows a known distribution. Non-Parametric tests on the other hand do not require the sampling distribution to be normally distributed (a.k.a. “assumption free tests”). These tests may be used when the variable of interest is measured on an ordinal scale or when the parametric assumptions do not hold. They often rely on ranking the data instead of analyzing the actual scores. By ranking the data, information on the magnitude of differences is lost. Thus, parametric tests are more powerful if the sampling distribution is normally distributed. In this chapter, we will first focus on parametric tests and cover non-parametric tests later.
5.1.3.2 One-tailed vs. two-tailed test
For some tests you may choose between a one-tailed test versus a two-tailed test . The choice depends on the hypothesis you specified, i.e., whether you specified a directional or a non-directional hypotheses. In the example above, we used a non-directional hypothesis . That is, we stated that the mean is different from the comparison value \(\mu_0\) , but we did not state the direction of the effect. A directional hypothesis states the direction of the effect. For example, we might test whether the population mean is smaller than a comparison value:
\[ H_0: \mu \ge \mu_0 \\ H_1: \mu < \mu_0 \]
Similarly, we could test whether the population mean is larger than a comparison value:
\[ H_0: \mu \le \mu_0 \\ H_1: \mu > \mu_0 \]
Connected to the decision of how to phrase the hypotheses (directional vs. non-directional) is the choice of a one-tailed test versus a two-tailed test . Let’s first think about the meaning of a one-tailed test. Using a significance level of 0.05, a one-tailed test means that 5% of the total area under the probability distribution of our test statistic is located in one tail. Thus, under a one-tailed test, we test for the possibility of the relationship in one direction only, disregarding the possibility of a relationship in the other direction. In our example, a one-tailed test could test either if the mean listening time is significantly larger or smaller compared to the control condition, but not both. Depending on the direction, the mean listening time is significantly larger (smaller) if the test statistic is located in the top (bottom) 5% of its probability distribution.
The following graph shows the critical values that our test statistic would need to surpass so that the difference between the population mean and the comparison value would be deemed statistically significant.

It can be seen that under a one-sided test, the rejection region is at one end of the distribution or the other. In a two-sided test, the rejection region is split between the two tails. As a consequence, the critical value of the test statistic is smaller using a one-tailed test, meaning that it has more power to detect an effect. Having said that, in most applications, we would like to be able catch effects in both directions, simply because we can often not rule out that an effect might exist that is not in the hypothesized direction. For example, if we would conduct a one-tailed test for a mean larger than some specified value but the mean turns out to be substantially smaller, then testing a one-directional hypothesis ($H_0: _0 $) would not allow us to conclude that there is a significant effect because there is not rejection at this end of the distribution.
5.1.4 Summary
As we have seen, the process of hypothesis testing consists of various steps:
- Formulate null and alternative hypotheses
- Select an appropriate test
- Choose the level of significance ( \(\alpha\) )
- Descriptive statistics and data visualization
- Conduct significance test
- Report results and draw a marketing conclusion
In the following, we will go through the individual steps using examples for different tests.
5.2 One sample t-test
The example we used in the introduction was an example of the one sample t-test and we computed all statistics by hand to explain the underlying intuition. When you conduct hypothesis tests using R, you do not need to calculate these statistics by hand, since there are build-in routines to conduct the steps for you. Let us use the same example again to see how you would conduct hypothesis tests in R.
1. Formulate null and alternative hypotheses
The null hypothesis states that there is no difference between the true population mean \(\mu\) and the hypothesized value (i.e., \(10\) ), while the alternative hypothesis states the opposite:
\[ H_0: \mu = 10 \\ H_1: \mu \neq 10 \]
2. Select an appropriate test
Because we would like to test if the mean of a variable is different from a specified threshold, the one-sample t-test is appropriate. The assumptions of the test are 1) that the variable is measured using an interval or ratio scale, and 2) that the sampling distribution is normal. Both assumptions are met since 1) listening time is a ratio scale, and 2) we deem the sample size (n = 50) large enough to assume a normal sampling distribution according to the central limit theorem.
3. Choose the level of significance
We choose the conventional 5% significance level.
4. Descriptive statistics and data visualization
Provide descriptive statistics using the stat.desc() function:
From this, we can already see that the mean is different from the hypothesized value. The question however remains, whether this difference is significantly different, given the sample size and the variability in the data. Since we only have one continuous variable, we can visualize the distribution in a histogram.

5. Conduct significance test
In the beginning of the chapter, we saw, how you could conduct significance test by hand. However, R has built-in routines that you can use to conduct the analyses. The t.test() function can be used to conduct the test. To test if the listening time among WU students was 10, you can use the following code:
Note that if you would have stated a directional hypothesis (i.e., the mean is either greater or smaller than 10 hours), you could easily amend the code to conduct a one sided test by changing the argument alternative from 'two.sided' to either 'less' or 'greater' .
6. Report results and draw a marketing conclusion
Note that the results are the same as above, when we computed the test by hand. You could summarize the results as follows:
On average, the listening times in our sample were different form 10 hours per month (Mean = 18.99 hours, SE = 1.78). This difference was significant t(49) = 5.058, p < .05 (95% CI = [15.42; 22.56]). Based on this evidence, we can conclude that the mean in our sample is significantly lower compared to the hypothesized population mean of \(10\) hours, providing evidence against the null hypothesis.
Note that in the reporting above, the number 49 in parenthesis refers to the degrees of freedom that are available from the output.
5.3 Comparing two means
In the one-sample test above, we tested the hypothesis that the population mean has some specific value \(\mu_0\) using data from only one sample. In marketing (as in many other disciplines), you will often be confronted with a situation where you wish to compare the means of two groups. For example, you may conduct an experiment and randomly split your sample into two groups, one of which receives a treatment (experimental group) while the other doesn’t (control group). In this case, the units (e.g., participants, products) in each group are different (‘between-subjects design’) and the samples are said to be independent. Hence, we would use a independent-means t-test . If you run an experiment with two experimental conditions and the same units (e.g., participants, products) were observed in both experimental conditions, the sample is said to be dependent in the sense that you have the same units in each group (‘within-subjects design’). In this case, we would need to conduct an dependent-means t-test . Both tests are described in the following sections, beginning with the independent-means t-test.
5.3.1 Independent-means t-test
Using an independent-means t-test, we can compare the means of two possibly different populations. It is, for example, quite common for online companies to test new service features by running an experiment and randomly splitting their website visitors into two groups: one is exposed to the website with the new feature (experimental group) and the other group is not exposed to the new feature (control group). This is a typical A/B-Test scenario.
As an example, imagine that a music streaming service would like to introduce a new playlist feature that let’s their users access playlists created by other users. The goal is to analyse how the new service feature impacts the listening time of users. The service randomly splits a representative subset of their users into two groups and collects data about their listening times over one month. Let’s create a data set to simulate such a scenario.
This data set contains two variables: the variable hours indicates the music listening times (in hours) and the variable group indicates from which group the observation comes, where ‘A’ refers to the control group (with the standard service) and ‘B’ refers to the experimental group (with the new playlist feature). Let’s first look at the descriptive statistics by group using the describeBy function:
From this, we can already see that there is a difference in means between groups A and B. We can also see that the number of observations is different, as is the standard deviation. The question that we would like to answer is whether there is a significant difference in mean listening times between the groups. Remember that different users are contained in each group (‘between-subjects design’) and that the observations in one group are independent of the observations in the other group. Before we will see how you can easily conduct an independent-means t-test, let’s go over some theory first.
5.3.1.1 Theory
As a starting point, let us label the unknown population mean of group A (control group) in our experiment \(\mu_1\) , and that of group B (experimental group) \(\mu_2\) . In this setting, the null hypothesis would state that the mean in group A is equal to the mean in group B:
\[ H_0: \mu_1=\mu_2 \]
This is equivalent to stating that the difference between the two groups ( \(\delta\) ) is zero:
\[ H_0: \mu_1 - \mu_2=0=\delta \]
That is, \(\delta\) is the new unknown population parameter, so that the null and alternative hypothesis become:
\[ H_0: \delta = 0 \\ H_1: \delta \ne 0 \]
Remember that we usually don’t have access to the entire population so that we can not observe \(\delta\) and have to estimate is from a sample statistic, which we define as \(d = \bar x_1-\bar x_2\) , i.e., the difference between the sample means from group a ( \(\bar x_1\) ) and group b ( \(\bar x_2\) ). But can we really estimate \(d\) from \(\delta\) ? Remember from the previous chapter, that we could estimate \(\mu\) from \(\bar x\) , because if we (hypothetically) take a larger number of samples, the distribution of the means of these samples (the sampling distribution) will be normally distributed and its mean will be (in the limit) equal to the population mean. It turns out that we can use the same underlying logic here. The above samples were drawn from two different populations with \(\mu_1\) and \(\mu_2\) . Let us compute the difference in means between these two populations:
This means that the true difference between the mean listening times of groups a and b is -7.42. Let us now repeat the exercise from the previous chapter: let us repeatedly draw a large number of \(20,000\) random samples of 100 users from each of these populations, compute the difference (i.e., \(d\) , our estimate of \(\delta\) ), store the difference for each draw and create a histogram of \(d\) .

This gives us the sampling distribution of the mean differences between the samples. You will notice that this distribution follows a normal distribution and is centered around the true difference between the populations. This means that, on average, the difference between two sample means \(d\) is a good estimate of \(\delta\) . In our example, the difference between \(\bar x_1\) and \(\bar x_2\) is:
Now that we have \(d\) as an estimate of \(\delta\) , how can we find out if the observed difference is significantly different from the null hypothesis (i.e., \(\delta = 0\) )?
Recall from the previous section, that the standard deviation of the sampling distribution \(\sigma_{\bar x}\) (i.e., the standard error) gives us indication about the precision of our estimate. Further recall that the standard error can be calculated as \(\sigma_{\bar x}={\sigma \over \sqrt{n}}\) . So how can we calculate the standard error of the difference between two population means? According to the variance sum law , to find the variance of the sampling distribution of differences, we merely need to add together the variances of the sampling distributions of the two populations that we are comparing. To find the standard error, we only need to take the square root of the variance (because the standard error is the standard deviation of the sampling distribution and the standard deviation is the square root of the variance), so that we get:
\[ \sigma_{\bar x_1-\bar x_2} = \sqrt{{\sigma_1^2 \over n_1}+{\sigma_2^2 \over n_2}} \]
But recall that we don’t actually know the true population standard deviation, so we use \(SE_{\bar x_1-\bar x_2}\) as an estimate of \(\sigma_{\bar x_1-\bar x_2}\) :
\[ SE_{\bar x_1-\bar x_2} = \sqrt{{s_1^2 \over n_1}+{s_2^2 \over n_2}} \]
Hence, for our example, we can calculate the standard error as follows:
Recall from above that we can calculate the t-statistic as:
\[ t= {\bar x - \mu_0 \over {s \over \sqrt{n}}} \]
Exchanging \(\bar x\) for \(d\) , we get
\[ t= {(\bar{x}_1 - \bar{x}_2) - (\mu_1 - \mu_2) \over {\sqrt{{s_1^2 \over n_1}+{s_2^2 \over n_2}}}} \]
Note that according to our hypothesis \(\mu_1-\mu_2=0\) , so that we can calculate the t-statistic as:
Following the example of our one sample t-test above, we would now need to compare this calculated test statistic to a critical value in order to assess if \(d\) is sufficiently far away from the null hypothesis to be statistically significant. To do this, we would need to know the exact t-distribution, which depends on the degrees of freedom. The problem is that deriving the degrees of freedom in this case is not that obvious. If we were willing to assume that \(\sigma_1=\sigma_2\) , the correct t-distribution has \(n_1 -1 + n_2-1\) degrees of freedom (i.e., the sum of the degrees of freedom of the two samples). However, because in real life we don not know if \(\sigma_1=\sigma_2\) , we need to account for this additional uncertainty. We will not go into detail here, but R automatically uses a sophisticated approach to correct the degrees of freedom called the Welch’s correction, as we will see in the subsequent application.
5.3.1.2 Application
The section above explained the theory behind the independent-means t-test and showed how to compute the statistics manually. Obviously you don’t have to compute these statistics by hand in this section shows you how to conduct an independent-means t-test in R using the example from above.
We wish to analyze whether there is a significant difference in music listening times between groups A and B. So our null hypothesis is that the means from the two populations are the same (i.e., there is no difference), while the alternative hypothesis states the opposite:
\[ H_0: \mu_1=\mu_2\\ H_1: \mu_1 \ne \mu_2 \]
Since we have a ratio scaled variable (i.e., listening times) and two independent groups, where the mean of one sample is independent of the group of the second sample (i.e., the groups contain different units), the independent-means t-test is appropriate.
We can compute the descriptive statistics for each group separately, using the describeBy() function:
This already shows us that the mean between groups A and B are different. We can visualize the data using a plot of means, boxplot, and a histogram.

To conduct the independent means t-test, we can use the t.test() function:
The results showed that listening times were higher in the experimental group B (Mean = 28.50, SE = 1.7) compared to the control group (Mean = 18.11, SE = 1.22). This means that the listening times were 10.39 hours higher on average in the experimental group (B), compared to the control group (A). An independent-means t-test showed that this difference is significant t(195.73) = -4.9646, p < .05 (95% CI = [-14.514246,-6.261264]).
5.3.2 Dependent-means t-test
While the independent-means t-test is used when different units (e.g., participants, products) were assigned to the different condition, the dependent-means t-test is used when there are two experimental conditions and the same units (e.g., participants, products) were observed in both experimental conditions.
Imagine, for example, a slightly different experimental setup for the above experiment. Imagine that we do not assign different users to the groups, but that a sample of 100 users gets to use the music streaming service with the new feature for one month and we compare the music listening times of these users during the month of the experiment with the listening time in the previous month. Let us generate data for this example:
Note that the data set has almost the same structure as before only that we know have two variables representing the listening times of each user in the month before the experiment and during the month of the experiment when the new feature was tested.
5.3.2.1 Theory
In this case, we want to test the hypothesis that there is no difference in mean the mean listening times between the two months. This can be expressed as follows:
\[ H_0: \mu_D = 0 \\ \] Note that the hypothesis only refers to one population, since both observations come from the same units (i.e., users). To use consistent notation, we replace \(\mu_D\) with \(\delta\) and get:
\[ H_0: \delta = 0 \\ H_1: \delta \neq 0 \]
where \(\delta\) denotes the difference between the observed listening times from the two consecutive months of the same users . As is the previous example, since we do not observe the entire population, we estimate \(\delta\) based on the sample using \(d\) , which is the difference in mean listening time between the two months for our sample. Note that we assume that everything else (e.g., number of new releases) remained constant over the two month to keep it simple. We can show as above that the sampling distribution follows a normal distribution with a mean that is (in the limit) the same as the population mean. This means, again, that the difference in sample means is a good estimate for the difference in population means. Let’s compute a new variable \(d\) , which is the difference between two month.
Note that we now have a new variable, which is the difference in listening times (in hours) between the two months. The mean of this difference is:
Again, we use \(SE_{\bar x}\) as an estimate of \(\sigma_{\bar x}\) :
\[ SE_{\bar d}={s \over \sqrt{n}} \] Hence, we can compute the standard error as:
The test statistic is therefore:
\[ t = {\bar d- \mu_0 \over SE_{\bar d}} \] on 99 (i.e., n-1) degrees of freedom. Now we can compute the t-statistic as follows:
Note that in the case of the dependent-means t-test, we only base our hypothesis on one population and hence there is only one population variance. This is because in the dependent sample test, the observations come from the same observational units (i.e., users). Hence, there is no unsystematic variation due to potential differences between users that were assigned to the experimental groups. This means that the influence of unobserved factors (unsystematic variation) relative to the variation due to the experimental manipulation (systematic variation) is not as strong in the dependent-means test compared to the independent-means test and we don’t need to correct for differences in the population variances.
5.3.2.2 Application
Again, we don’t have to compute all this by hand since the t.test(...) function can be used to do it for us. Now we have to use the argument paired=TRUE to let R know that we are working with dependent observations.
We would like to the test if there is a difference in music listening times between the two consecutive months, so our null hypothesis is that there is no difference, while the alternative hypothesis states the opposite:
\[ H_0: \mu_D = 0 \\ H_0: \mu_D \ne 0 \]
Since we have a ratio scaled variable (i.e., listening times) and two observations of the same group of users (i.e., the groups contain the same units), the dependent-means t-test is appropriate.
We can compute the descriptive statistics for each month separately, using the describe() function:
This already shows us that the mean between the two months are different. We can visiualize the data using a plot of means, boxplot, and a histogram.
To plot the data, we need to do some restructuring first, since the variables are now stored in two different columns (“hours_a” and “hours_b”). This is also known as the “wide” format. To plot the data we need all observations to be stored in one variable. This is also known as the “long” format. We can use the melt(...) function from the reshape2 package to “melt” the two variable into one column to plot the data.
Now we are ready to plot the data:

To conduct the independent means t-test, we can use the t.test() function with the argument paired = TRUE :
On average, the same users used the service more when it included the new feature (M = 25.96, SE = 1.68) compared to the service without the feature (M = 20.99, SE = 1.34). This difference was significant t(99) = 2.3781, p < .05 (95% CI = [0.82, 9.12]).
5.3.3 Further considerations
5.3.3.1 type i and type ii errors.
When choosing the level of significance ( \(\alpha\) ). It is important to note that the choice of the significance level affects the type 1 and type 2 error:
- Type I error: When we believe there is a genuine effect in our population, when in fact there isn’t. Probability of type I error ( \(\alpha\) ) = level of significance.
- Type II error: When we believe that there is no effect in the population, when in fact there is.
This following table shows the possible outcomes of a test (retain vs. reject \(H_0\) ), depending on whether \(H_0\) is true or false in reality.
5.3.3.2 Significance level, sample size, power, and effect size
When you plan to conduct an experiment, there are some factors that are under direct control of the researcher:
- Significance level ( \(\alpha\) ) : The probability of finding an effect that does not genuinely exist.
- Sample size (n) : The number of observations in each group of the experimental design.
Unlike α and n, which are specified by the researcher, the magnitude of β depends on the actual value of the population parameter. In addition, β is influenced by the effect size (e.g., Cohen’s d), which can be used to determine a standardized measure of the magnitude of an observed effect. The following parameters are affected more indirectly:
- Power (1-β) : The probability of finding an effect that does genuinely exists.
- Effect size (d) : Standardized measure of the effect size under the alternate hypothesis.
Although β is unknown, it is related to α. For example, if we would like to be absolutely sure that we do not falsely identify an effect which does not exist (i.e., make a type I error), this means that the probability of identifying an effect that does exist (i.e., 1-β) decreases and vice versa. Thus, an extremely low value of α (e.g., α = 0.0001) will result in intolerably high β errors. A common approach is to set α=0.05 and 1-β=0.80.
Unlike the t-value of our test, the effect size (d) is unaffected by the sample size and can be categorized as follows (see Cohen, J. 1988):
- 0.2 (small effect)
- 0.5 (medium effect)
- 0.8 (large effect)
In order to test more subtle effects (smaller effect sizes), you need a larger sample size compared to the test of more obvious effects. In this paper , you can find a list of examples for different effect sizes and the number of observations you need to reliably find an effect of that magnitude. Although the exact effect size is unknown before the experiment, you might be able to make a guess about the effect size (e.g., based on previous studies).
If you wish to obtain a standardized measure of the effect, you may compute the effect size (Cohen’s d) using the cohensD() function from the lsr package. Using the examples from the independent-means t-test above, we would use:
According to the thresholds defined above, this effect would be judged to be a small-medium effect.
For the dependent-means t-test, we would use:
According to the thresholds defined above, this effect would also be judged to be a small-medium effect.
When constructing an experimental design, your goal should be to maximize the power of the test while maintaining an acceptable significance level and keeping the sample as small as possible. To achieve this goal, you may use the pwr package, which let’s you compute n , d , alpha , and power . You only need to specify three of the four input variables to get the fourth.
For example, what sample size do we need (per group) to identify an effect with d = 0.6, α = 0.05, and power = 0.8:
Or we could ask, what is the power of our test with 51 observations in each group, d = 0.6, and α = 0.05:
5.3.3.3 P-values, stopping rules and p-hacking
From my experience, students tend to place a lot of weight on p-values when interpreting their research findings. It is therefore important to note some points that hopefully help to put the meaning of a “significant” vs. “insignificant” test result into perspective.
Significant result
- Even if the probability of the effect being a chance result is small (e.g., less than .05) it doesn’t necessarily mean that the effect is important.
- Very small and unimportant effects can turn out to be statistically significant if the sample size is large enough.
Insignificant result
- If the probability of the effect occurring by chance is large (greater than .05), the alternative hypothesis is rejected. However, this does not mean that the null hypothesis is true.
- Although an effect might not be large enough to be anything other than a chance finding, it doesn’t mean that the effect is zero.
- In fact, two random samples will always have slightly different means that would deemed to be statistically significant if the samples were large enough.
Thus, you should not base your research conclusion on p-values alone!
It is also crucial to determine the sample size before you run the experiment or before you start your analysis. Why? Consider the following example:
- You run an experiment
- After each respondent you analyze the data and look at the mean difference between the two groups with a t-test
- You stop when you have a significant effect
This is called p-hacking and should be avoided at all costs. Assuming that both groups come from the same population (i.e., there is no difference in the means): What is the likelihood that the result will be significant at some point? In other words, what is the likelihood that you will draw the wrong conclusion from your data that there is an effect, while there is none? This is shown in the following graph using simulated data - the color red indicates significant test results that arise although there is no effect (i.e., false positives).

Figure 5.1: p-hacking (red indicates false positives)
5.4 Comparing several means
This chapter is primarily based on Field, A., Miles J., & Field, Z. (2012): Discovering Statistics Using R. Sage Publications, chapters 10 & 12 .
5.4.1 Introduction
In the previous section we learned how to compare means using a t-test. The t-test has some limitations since it only lets you compare 2 means and you can only use it with one independent variable. However, often we would like to compare means from 3 or more groups. In addition, there may be instances in which you manipulate more than one independent variable. For these applications, ANOVA (ANalysis Of VAriance) can be used. Hence, to conduct ANOVA you need:
- A metric dependent variable (i.e., measured using an interval or ratio scale)
- One or more non-metric (categorical) independent variables (also called factors)
A treatment is a particular combination of factor levels, or categories. One-way ANOVA is used when there is only one categorical variable (factor). In this case, a treatment is the same as a factor level. N-way ANOVA is used with two or more factors. Note that we are only going to talk about a single independent variable in the context of ANOVA. If you have multiple independent variables please refere to the chapter on Regression .
Let’s use an example to see how ANOVA works. Similar to the previous example it is also imaginable that the music streaming service experiments with a recommendation system for user created playlists. We now have three groups, the control group “A” with the current system, treatment group “B” who have access to playlists created by other users but are not shown recommendations and treatment group “C” who are shown recommendations for user created playlists. As always, we load and inspect the data first:
The null hypothesis, typically, is that all means are equal (non-directional hypothesis). Hence, in our case:
\[H_0: \mu_1 = \mu_2 = \mu_3\]
The alternative hypothesis is simply that the means are not all equal, i.e.,
\[H_1: \textrm{Means are not all equal}\]
If you wanted to put this in mathematical notation, you could also write:
\[H_1: \exists {i,j}: {\mu_i \ne \mu_j} \]
To get a first impression if there are any differences in listening times across the experimental groups, we use the describeBy(...) function from the psych package:
In addition, you should visualize the data using appropriate plots:

Figure 5.2: Plot of means
Note that ANOVA is an omnibus test, which means that we test for an overall difference between groups. Hence, the test will only tell you if the group means are different, but it won’t tell you exactly which groups are different from another.
So why don’t we then just conduct a series of t-tests for all combinations of groups (i.e., A vs. B, A vs. C, B vs. C)? The reason is that if we assume each test to be independent, then there is a 5% probability of falsely rejecting the null hypothesis (Type I error) for each test. In our case:
- A vs. B (α = 0.05)
- A vs. C (α = 0.05)
- B vs. C (α = 0.05)
This means that the overall probability of making a Type I error is 1-(0.95 3 ) = 0.143, since the probability of no Type I error is 0.95 for each of the three tests. Consequently, the Type I error probability would be 14.3%, which is above the conventional standard of 5%. This is also known as the family-wise or experiment-wise error.
5.4.2 Decomposing variance
The basic concept underlying ANOVA is the decomposition of the variance in the data. There are three variance components which we need to consider:
- We calculate how much variability there is between scores: Total sum of squares (SS T )
- We then calculate how much of this variability can be explained by the model we fit to the data (i.e., how much variability is due to the experimental manipulation): Model sum of squares (SS M )
- … and how much cannot be explained (i.e., how much variability is due to individual differences in performance): Residual sum of squares (SS R )
The following figure shows the different variance components using a generalized data matrix:

Decomposing variance
The total variation is determined by the variation between the categories (due to our experimental manipulation) and the within-category variation that is due to extraneous factors (e.g., promotion of artists on a social network):
\[SS_T= SS_M+SS_R\]
To get a better feeling how this relates to our data set, we can look at the data in a slightly different way. Specifically, we can use the dcast(...) function from the reshape2 package to convert the data to wide format:
In this example, X 1 from the generalized data matrix above would refer to the factor level “A”, X 2 to the level “B”, and X 3 to the level “C”. Y 11 refers to the first data point in the first row (i.e., “13”), Y 12 to the second data point in the first row (i.e., “21”), etc.. The grand mean ( \(\overline{Y}\) ) and the category means ( \(\overline{Y}_c\) ) can be easily computed:
To see how each variance component can be derived, let’s look at the data again. The following graph shows the individual observations by experimental group:

Figure 5.3: Sum of Squares
5.4.2.1 Total sum of squares
To compute the total variation in the data, we consider the difference between each observation and the grand mean. The grand mean is the mean over all observations in the data set. The vertical lines in the following plot measure how far each observation is away from the grand mean:

Figure 5.4: Total Sum of Squares
The formal representation of the total sum of squares (SS T ) is:
\[ SS_T= \sum_{i=1}^{N} (Y_i-\bar{Y})^2 \]
This means that we need to subtract the grand mean from each individual data point, square the difference, and sum up over all the squared differences. Thus, in our example, the total sum of squares can be calculated as:
\[ \begin{align} SS_T =&(13−24.67)^2 + (14−24.67)^2 + … + (2−24.67)^2\\ &+(21−24.67)^2 + (18-24.67)^2 + … + (17−24.67)^2\\ &+(30−24.67)^2 + (37−24.67)^2 + … + (28−24.67)^2\\ &=30855.64 \end{align} \]
You could also compute this in R using:
For the subsequent analyses, it is important to understand the concept behind the degrees of freedom . Remember that in order to estimate a population value from a sample, we need to hold something in the population constant. In ANOVA, the df are generally one less than the number of values used to calculate the SS. For example, when we estimate the population mean from a sample, we assume that the sample mean is equal to the population mean. Then, in order to estimate the population mean from the sample, all but one scores are free to vary and the remaining score needs to be the value that keeps the population mean constant. In our example, we used all 300 observations to calculate the sum of square, so the total degrees of freedom (df T ) are:
\[\begin{equation} \begin{split} df_T = N-1=300-1=299 \end{split} \tag{5.1} \end{equation}\]
5.4.2.2 Model sum of squares
Now we know that there are 26646.33 units of total variation in our data. Next, we compute how much of the total variation can be explained by the differences between groups (i.e., our experimental manipulation). To compute the explained variation in the data, we consider the difference between the values predicted by our model for each observation (i.e., the group mean) and the grand mean. The group mean refers to the mean value within the experimental group. The vertical lines in the following plot measure how far the predicted value for each observation (i.e., the group mean) is away from the grand mean:

Figure 5.5: Model Sum of Squares
The formal representation of the model sum of squares (SS M ) is:
\[ SS_M= \sum_{j=1}^{c} n_j(\bar{Y}_j-\bar{Y})^2 \]
where c denotes the number of categories (experimental groups). This means that we need to subtract the grand mean from each group mean, square the difference, and sum up over all the squared differences. Thus, in our example, the model sum of squares can be calculated as:
\[ \begin{align} SS_M &= 100*(15.47−24.67)^2 + 100*(24.88−24.67)^2 + 100*(33.66−24.67)^2 \\ &= 21321.21 \end{align} \]
You could also compute this manually in R using:
In this case, we used the three group means to calculate the sum of squares, so the model degrees of freedom (df M ) are:
\[ df_M= c-1=3-1=2 \]
5.4.2.3 Residual sum of squares
Lastly, we calculate the amount of variation that cannot be explained by our model. In ANOVA, this is the sum of squared distances between what the model predicts for each data point (i.e., the group means) and the observed values. In other words, this refers to the amount of variation that is caused by extraneous factors, such as differences between product characteristics of the products in the different experimental groups. The vertical lines in the following plot measure how far each observation is away from the group mean:

Figure 5.6: Residual Sum of Squares
The formal representation of the residual sum of squares (SS R ) is:
\[ SS_R= \sum_{j=1}^{c} \sum_{i=1}^{n} ({Y}_{ij}-\bar{Y}_{j})^2 \]
This means that we need to subtract the group mean from each individual observation, square the difference, and sum up over all the squared differences. Thus, in our example, the model sum of squares can be calculated as:
\[ \begin{align} SS_R =& (13−14.34)^2 + (14−14.34)^2 + … + (2−14.34)^2 \\ +&(21−24.7)^2 + (18−24.7)^2 + … + (17−24.7)^2 \\ +& (30−34.99)^2 + (37−34.99)^2 + … + (28−34.99)^2 \\ =& 9534.43 \end{align} \]
In this case, we used the 10 values for each of the SS for each group, so the residual degrees of freedom (df R ) are:
\[ \begin{align} df_R=& (n_1-1)+(n_2-1)+(n_3-1) \\ =&(100-1)+(100-1)+(100-1)=297 \end{align} \]
5.4.2.4 Effect strength
Once you have computed the different sum of squares, you can investigate the effect strength. \(\eta^2\) is a measure of the variation in Y that is explained by X:
\[ \eta^2= \frac{SS_M}{SS_T}=\frac{21321.21}{30855.64}=0.69 \]
To compute this in R:
The statistic can only take values between 0 and 1. It is equal to 0 when all the category means are equal, indicating that X has no effect on Y. In contrast, it has a value of 1 when there is no variability within each category of X but there is some variability between categories.
5.4.2.5 Test of significance
How can we determine whether the effect of X on Y is significant?
- First, we calculate the fit of the most basic model (i.e., the grand mean)
- Then, we calculate the fit of the “best” model (i.e., the group means)
- A good model should fit the data significantly better than the basic model
- The F-statistic or F-ratio compares the amount of systematic variance in the data to the amount of unsystematic variance
The F-statistic uses the ratio of mean square related to X (explained variation) and the mean square related to the error (unexplained variation):
\(\frac{SS_M}{SS_R}\)
However, since these are summed values, their magnitude is influenced by the number of scores that were summed. For example, to calculate SS M we only used the sum of 3 values (the group means), while we used 30 and 27 values to calculate SS T and SS R , respectively. Thus, we calculate the average sum of squares (“mean square”) to compare the average amount of systematic vs. unsystematic variation by dividing the SS values by the degrees of freedom associated with the respective statistic.
Mean square due to X:
\[ MS_M= \frac{SS_M}{df_M}=\frac{SS_M}{c-1}=\frac{21321.21}{(3-1)} \]
Mean square due to error:
\[ MS_R= \frac{SS_R}{df_R}=\frac{SS_R}{N-c}=\frac{9534.43}{(300-3)} \]
Now, we compare the amount of variability explained by the model (experiment), to the error in the model (variation due to extraneous variables). If the model explains more variability than it can’t explain, then the experimental manipulation has had a significant effect on the outcome (DV). The F-radio can be derived as follows:
\[ F= \frac{MS_M}{MS_R}=\frac{\frac{SS_M}{c-1}}{\frac{SS_R}{N-c}}=\frac{\frac{21321.21}{(3-1)}}{\frac{9534.43}{(300-3)}}=332.08 \]
You can easily compute this in R:
This statistic follows the F distribution with (m = c – 1) and (n = N – c) degrees of freedom. This means that, like the \(\chi^2\) distribution, the shape of the F-distribution depends on the degrees of freedom. In this case, the shape depends on the degrees of freedom associated with the numerator and denominator used to compute the F-ratio. The following figure shows the shape of the F-distribution for different degrees of freedom:

The F distribution
The outcome of the test is one of the following:
- If the null hypothesis of equal category means is not rejected, then the independent variable does not have a significant effect on the dependent variable
- If the null hypothesis is rejected, then the effect of the independent variable is significant
For 2 and 297 degrees of freedom, the critical value of F is 3.026 for α=0.05. As usual, you can either look up these values in a table or use the appropriate function in R:
The output tells us that the calculated test statistic exceeds the critical value. We can also show the test result visually:

Visual depiction of the test result
Thus, we conclude that because F CAL = 332.08 > F CR = 3.03, H 0 is rejected!
Interpretation: one or more of the differences between means are statistically significant.
Reporting: There was a significant effect of promotion on sales levels, F(2,297) = 332.08, p < 0.05, \(\eta^2\) = 0.69.
Remember: This doesn’t tell us where the differences between groups lie. To find out which group means exactly differ, we need to use post-hoc procedures (see below).
You don’t have to compute these statistics manually! Luckily, there is a function for ANOVA in R, which does the above calculations for you as we will see in the next section.
5.4.3 One-way ANOVA
5.4.3.1 basic anova.
As already indicated, one-way ANOVA is used when there is only one categorical variable (factor). Before conducting ANOVA, you need to check if the assumptions of the test are fulfilled. The assumptions of ANOVA are discussed in the following sections.
Independence of observations
The observations in the groups should be independent. Because we randomly assigned the listeners to the experimental conditions, this assumption can be assumed to be met.
Distributional assumptions
ANOVA is relatively immune to violations to the normality assumption when sample sizes are large due to the Central Limit Theorem. However, if your sample is small (i.e., n < 30 per group) you may nevertheless want to check the normality of your data, e.g., by using the Shapiro-Wilk test or QQ-Plot. In our example, we have 100 observations in each group which is plenty but let’s create another example with only 10 observations in each group. In the latter case we cannot rely on the Central Limit Theorem and we should test the normality of our data. This can be done using the Shapiro-Wilk Test, which has the Null Hypothesis that the data is normally distributed. Hence, an insignificant test results means that the data can be assumed to be approximately normally distributed:
Since the test result is insignificant for all groups, we can conclude that the data approximately follow a normal distribution.
We could also test the distributional assumptions visually using a Q-Q plot (i.e., quantile-quantile plot). This plot can be used to assess if a set of data plausibly came from some theoretical distribution such as the Normal distribution. Since this is just a visual check, it is somewhat subjective. But it may help us to judge if our assumption is plausible, and if not, which data points contribute to the violation. A Q-Q plot is a scatterplot created by plotting two sets of quantiles against one another. If both sets of quantiles came from the same distribution, we should see the points forming a line that’s roughly straight. In other words, Q-Q plots take your sample data, sort it in ascending order, and then plot them versus quantiles calculated from a theoretical distribution. Quantiles are often referred to as “percentiles” and refer to the points in your data below which a certain proportion of your data fall. Recall, for example, the standard Normal distribution with a mean of 0 and a standard deviation of 1. Since the 50th percentile (or 0.5 quantile) is 0, half the data lie below 0. The 95th percentile (or 0.95 quantile), is about 1.64, which means that 95 percent of the data lie below 1.64. The 97.5th quantile is about 1.96, which means that 97.5% of the data lie below 1.96. In the Q-Q plot, the number of quantiles is selected to match the size of your sample data.
To create the Q-Q plot for the normal distribution, you may use the qqnorm() function, which takes the data to be tested as an argument. Using the qqline() function subsequently on the data creates the line on which the data points should fall based on the theoretical quantiles. If the individual data points deviate a lot from this line, it means that the data is not likely to follow a normal distribution.

Figure 5.7: Q-Q plot 1

Figure 5.8: Q-Q plot 2

Figure 5.9: Q-Q plot 3
The Q-Q plots suggest an approximately Normal distribution. If the assumption had been violated, you might consider transforming your data or resort to a non-parametric test.
Homogeneity of variance
Let’s return to our original dataset with 100 observations in each group for the rest of the analysis.
You can test the homogeneity of variances in R using Levene’s test:
The null hypothesis of the test is that the group variances are equal. Thus, if the test result is significant it means that the variances are not equal. If we cannot reject the null hypothesis (i.e., the group variances are not significantly different), we can proceed with the ANOVA as follows:
You can see that the p-value is smaller than 0.05. This means that, if there really was no difference between the population means (i.e., the Null hypothesis was true), the probability of the observed differences (or larger differences) is less than 5%.
To compute η 2 from the output, we can extract the relevant sum of squares as follows
You can see that the results match the results from our manual computation above ( \(\eta^2 =\) 0.69).
The aov() function also automatically generates some plots that you can use to judge if the model assumptions are met. We will inspect two of the plots here.
We will use the first plot to inspect if the residual variances are equal across the experimental groups:

Generally, the residual variance (i.e., the range of values on the y-axis) should be the same for different levels of our independent variable. The plot shows, that there are some slight differences. Notably, the range of residuals is higher in group “B” than in group “C”. However, the differences are not that large and since the Levene’s test could not reject the Null of equal variances, we conclude that the variances are similar enough in this case.
The second plot can be used to test the assumption that the residuals are approximately normally distributed. We use a Q-Q plot to test this assumption:

The plot suggests that, the residuals are approximately normally distributed. We could also test this by extracting the residuals from the anova output using the resid() function and using the Shapiro-Wilk test:
Confirming the impression from the Q-Q plot, we cannot reject the Null that the residuals are approximately normally distributed.
Note that if Levene’s test would have been significant (i.e., variances are not equal), we would have needed to either resort to non-parametric tests (see below), or compute the Welch’s F-ratio instead:
You can see that the results are fairly similar, since the variances turned out to be fairly equal across groups.
5.4.3.2 Post-hoc tests
Provided that significant differences were detected by the overall ANOVA you can find out which group means are different using post hoc procedures. Post hoc procedures are designed to conduct pairwise comparisons of all different combinations of the treatment groups by correcting the level of significance for each test such that the overall Type I error rate (α) across all comparisons remains at 0.05.
In other words, we rejected H 0 : μ 1 = μ 2 = μ 3 , and now we would like to test:
\[H_0: \mu_1 = \mu_2\]
\[H_0: \mu_1 = \mu_3\]
\[H_0: \mu_2 = \mu_3\]
There are several post hoc procedures available to choose from. In this tutorial, we will cover Bonferroni and Tukey’s HSD (“honest significant differences”). Both tests control for family-wise error. Bonferroni tends to have more power when the number of comparisons is small, whereas Tukey’ HSDs is better when testing large numbers of means.
5.4.3.2.1 Bonferroni
One of the most popular (and easiest) methods to correct for the family-wise error rate is to conduct the individual t-tests and divide α by the number of comparisons („k“):
\[ p_{CR}= \frac{\alpha}{k} \]
In our example with three groups:
\[p_{CR}= \frac{0.05}{3}=0.017\]
Thus, the “corrected” critical p-value is now 0.017 instead of 0.05 (i.e., the critical t value is higher). You can implement the Bonferroni procedure in R using:
In the output, you will get the corrected p-values for the individual tests. In our example, we can reject H 0 of equal means for all three tests, since p < 0.05 for all combinations of groups.
Note the difference between the results from the post-hoc test compared to individual t-tests. For example, when we test the “B” vs. “C” groups, the result from a t-test would be:
Usually the p-value is lower in the t-test, reflecting the fact that the family-wise error is not corrected (i.e., the test is less conservative). In this case the p-value is extremely small in both cases and thus indistinguishable.
5.4.3.2.2 Tukey’s HSD
Tukey’s HSD also compares all possible pairs of means (two-by-two combinations; i.e., like a t-test, except that it corrects for family-wise error rate).
Test statistic:
\[\begin{equation} \begin{split} HSD= q\sqrt{\frac{MS_R}{n_c}} \end{split} \tag{5.2} \end{equation}\]
- q = value from studentized range table (see e.g., here )
- MS R = Mean Square Error from ANOVA
- n c = number of observations per group
- Decision: Reject H 0 if
\[|\bar{Y}_i-\bar{Y}_j | > HSD\]
The value from the studentized range table can be obtained using the qtukey() function.
\[HSD= 3.33\sqrt{\frac{33.99}{100}}=1.94\]
Since all mean differences between groups are larger than 1.906, we can reject the null hypothesis for all individual tests, confirming the results from the Bonferroni test. To compute Tukey’s HSD, we can use the appropriate function from the multcomp package.
We may also plot the result for the mean differences incl. their confidence intervals:

Figure 5.10: Tukey’s HSD
You can see that the CIs do not cross zero, which means that the true difference between group means is unlikely zero.
Reporting of post hoc results:
The post hoc tests based on Bonferroni and Tukey’s HSD revealed that people listened to music significantly more when:
- they had access to user created playlists vs. those who did not,
- they got recommendations vs. those who did not. This is true for both the control group “A” as well as treatment “B”.
The following video summarizes how to conduct a one-way ANOVA in R
5.5 Non-parametric tests
Non-Parametric tests do not require the sampling distribution to be normally distributed (a.k.a. “assumption free tests”). These tests may be used when the variable of interest is measured on an ordinal scale or when the parametric assumptions do not hold. They often rely on ranking the data instead of analyzing the actual scores. By ranking the data, information on the magnitude of differences is lost. Thus, parametric tests are more powerful if the sampling distribution is normally distributed.
When should you use non-parametric tests?
- When your DV is measured on an ordinal scale
- When your data is better represented by the median (e.g., there are outliers that you can’t remove)
- When the assumptions of parametric tests are not met (e.g., normally distributed sampling distribution)
- You have a very small sample size (i.e., the central limit theorem does not apply)
5.5.1 Mann-Whitney U Test (a.k.a. Wilcoxon rank-sum test)
The Mann-Whitney U test is a non-parametric test of differences between groups, similar to the two sample t-test. In contrast to the two sample t-test it only requires ordinally scaled data and relies on weaker assumptions. Thus it is often useful if the assumptions of the t-test are violated, especially if the data is not on a ratio scale. The following assumptions must be fulfilled for the test to be applicable:
- The dependent variable is at least ordinally scaled (i.e. a ranking between values can be established)
- The independent variable has only two levels
- A between-subjects design is used (i.e., the subjects are not matched across conditions)
Intuitively, the test compares the frequency of low and high ranks between groups. Under the null hypothesis, the amount of high and low ranks should be roughly equal in the two groups. This is achieved through comparing the expected sum of ranks to the actual sum of ranks.
As an example, we will be using data obtained from a field experiment with random assignment. In a music download store, new releases were randomly assigned to an experimental group and sold at a reduced price (i.e., 7.95€), or a control group and sold at the standard price (9.95€). A representative sample of 102 new releases were sampled and these albums were randomly assigned to the experimental groups (i.e., 51 albums per group). The sales were tracked over one day.
Let’s load and investigate the data first:
Inspect descriptives (overall and by group).
Create boxplot and plot of means.

Figure 5.11: Boxplot
Let’s assume that one of the parametric assumptions has been violated and we needed to conduct a non-parametric test. Then, the Mann-Whitney U test is implemented in R using the function wilcox.test() . Using the ranking data as an independent variable and the listening time as a dependent variable, the test could be executed as follows:
The p-value is smaller than 0.05, which leads us to reject the null hypothesis, i.e. the test yields evidence that the new service feature leads to higher music listening times.
5.5.2 Wilcoxon signed-rank test
The Wilcoxon signed-rank test is a non-parametric test used to analyze the difference between paired observations, analogously to the paired t-test. It can be used when measurements come from the same observational units but the distributional assumptions of the paired t-test do not hold, because it does not require any assumptions about the distribution of the measurements. Since we subtract two values, however, the test requires that the dependent variable is at least interval scaled, meaning that intervals have the same meaning for different points on our measurement scale.
Under the null hypothesis \(H_0\) , the differences of the measurements should follow a symmetric distribution around 0, meaning that, on average, there is no difference between the two matched samples. \(H_1\) states that the distributions mean is non-zero.
As an example, let’s consider a slightly different experimental setup for the music download store. Imagine that new releases were either sold at a reduced price (i.e., 7.95€), or at the standard price (9.95€). Every time a customer came to the store, the prices were randomly determined for every new release. This means that the same 51 albums were either sold at the standard price or at the reduced price and this price was determined randomly. The sales were then recorded over one day. Note the difference to the previous case, where we randomly split the sample and assigned 50% of products to each condition. Now, we randomly vary prices for all albums between high and low prices.
Again, let’s assume that one of the prarametric assumptions has been violated and we needed to conduct a non-parametric test. Then the Wilcoxon signed-rank test can be performed with the same command as the Mann-Whitney U test, provided that the argument paired is set to TRUE .
Using the 95% confidence level, the result would suggest a significant effect of price on sales (i.e., p < 0.05).
5.5.3 Kruskal-Wallis test
- When the dependent variable is measured at an ordinal scale and we want to compare more than 2 means
- When the assumptions of independent ANOVA are not met (e.g., assumptions regarding the sampling distribution in small samples)
The Kruskal–Wallis test is the non-parametric counterpart of the one-way independent ANOVA. It is designed to test for significant differences in population medians when you have more than two samples (otherwise you would use the Mann-Whitney U-test). The theory is very similar to that of the Mann–Whitney U-test since it is also based on ranked data. The Kruskal-Wallis test is carried out using the kruskal.test() function. Using the same data as before, we type:
The test-statistic follows a chi-square distribution and since the test is significant (p < 0.05), we can conclude that there are significant differences in population medians. Provided that the overall effect is significant, you may perform a post hoc test to find out which groups are different. To get a first impression, we can plot the data using a boxplot:

Figure 5.12: Boxplot
To test for differences between groups, we can, for example, apply post hoc tests according to Nemenyi for pairwise multiple comparisons of the ranked data using the appropriate function from the PMCMR package.
The results reveal that there is a significant difference between the “low” and “high” promotion groups. Note that the results are different compared to the results from the parametric test above. This difference occurs because non-parametric tests have more power to detect differences between groups since we lose information by ranking the data. Thus, you should rely on parametric tests if the assumptions are met.
5.6 Categorical data
In some instances, you will be confronted with differences between proportions, rather than differences between means. For example, you may conduct an A/B-Test and wish to compare the conversion rates between two advertising campaigns. In this case, your data is binary (0 = no conversion, 1 = conversion) and the sampling distribution for such data is binomial. While binomial probabilities are difficult to calculate, we can use a Normal approximation to the binomial when n is large (>100) and the true likelihood of a 1 is not too close to 0 or 1.
Let’s use an example: assume a call center where service agents call potential customers to sell a product. We consider two call center agents:
- Service agent 1 talks to 300 customers and gets 200 of them to buy (conversion rate=2/3)
- Service agent 2 talks to 300 customers and gets 100 of them to buy (conversion rate=1/3)
As always, we load the data first:
Next, we create a table to check the relative frequencies:
We could also plot the data to visualize the frequencies using ggplot:

Figure 5.13: proportion of conversions per agent (stacked bar chart)
… or using the mosaicplot() function:

Figure 5.14: proportion of conversions per agent (mosaic plot)
5.6.1 Confidence intervals for proportions
Recall that we can use confidence intervals to determine the range of values that the true population parameter will take with a certain level of confidence based on the sample. Similar to the confidence interval for means, we can compute a confidence interval for proportions. The (1- \(\alpha\) )% confidence interval for proportions is approximately
\[ CI = p\pm z_{1-\frac{\alpha}{2}}*\sqrt{\frac{p*(1-p)}{N}} \]
where \(\sqrt{p(1-p)}\) is the equivalent to the standard deviation in the formula for the confidence interval for means. Based on the equation, it is easy to compute the confidence intervals for the conversion rates of the call center agents:
Similar to testing for differences in means, we could also ask: Is agent 1 twice as likely as agent 2 to convert a customer? Or, to state it formally:
\[H_0: \pi_1=\pi_2 \\ H_1: \pi_1\ne \pi_2\]
where \(\pi\) denotes the population parameter associated with the proportion in the respective population. One approach to test this is based on confidence intervals to estimate the difference between two populations. We can compute an approximate confidence interval for the difference between the proportion of successes in group 1 and group 2, as:
\[ CI = p_1-p_2\pm z_{1-\frac{\alpha}{2}}*\sqrt{\frac{p_1*(1-p_1)}{n_1}+\frac{p_2*(1-p_2)}{n_2}} \]
If the confidence interval includes zero, then the data does not suggest a difference between the groups. Let’s compute the confidence interval for differences in the proportions by hand first:
Now we can see that the 95% confidence interval estimate of the difference between the proportion of conversions for agent 1 and the proportion of conversions for agent 2 is between 26% and 41%. This interval tells us the range of plausible values for the difference between the two population proportions. According to this interval, zero is not a plausible value for the difference (i.e., interval does not cross zero), so we reject the null hypothesis that the population proportions are the same.
Instead of computing the intervals by hand, we could also use the prop.test() function:
Note that the prop.test() function uses a slightly different (more accurate) way to compute the confidence interval (Wilson’s score method is used). It is particularly a better approximation for smaller N. That’s why the confidence interval in the output slightly deviates from the manual computation above, which uses the Wald interval.
You can also see that the output from the prop.test() includes the results from a χ 2 test for the equality of proportions (which will be discussed below) and the associated p-value. Since the p-value is less than 0.05, we reject the null hypothesis of equal probability. Thus, the reporting would be:
The test showed that the conversion rate for agent 1 was higher by 33%. This difference is significant χ (1) = 70, p < .05 (95% CI = [0.25,0.41]).
5.6.2 Chi-square test
In the previous section, we saw how we can compute the confidence interval for the difference between proportions to decide on whether or not to reject the null hypothesis. Whenever you would like to investigate the relationship between two categorical variables, the \(\chi^2\) test may be used to test whether the variables are independent of each other. It achieves this by comparing the expected number of observations in a group to the actual values. Let’s continue with the example from the previous section. Under the null hypothesis, the two variables agent and conversion in our contingency table are independent (i.e., there is no relationship). This means that the frequency in each field will be roughly proportional to the probability of an observation being in that category, calculated under the assumption that they are independent. The difference between that expected quantity and the actual quantity can be used to construct the test statistic. The test statistic is computed as follows:
\[ \chi^2=\sum_{i=1}^{J}\frac{(f_o-f_e)^2}{f_e} \]
where \(J\) is the number of cells in the contingency table, \(f_o\) are the observed cell frequencies and \(f_e\) are the expected cell frequencies. The larger the differences, the larger the test statistic and the smaller the p-value.
The observed cell frequencies can easily be seen from the contingency table:
The expected cell frequencies can be calculated as follows:
\[ f_e=\frac{(n_r*n_c)}{n} \]
where \(n_r\) are the total observed frequencies per row, \(n_c\) are the total observed frequencies per column, and \(n\) is the total number of observations. Thus, the expected cell frequencies under the assumption of independence can be calculated as:
To sum up, these are the expected cell frequencies
… and these are the observed cell frequencies
To obtain the test statistic, we simply plug the values into the formula:
The test statistic is \(\chi^2\) distributed. The chi-square distribution is a non-symmetric distribution. Actually, there are many different chi-square distributions, one for each degree of freedom as show in the following figure.

Figure 5.15: The chi-square distribution
You can see that as the degrees of freedom increase, the chi-square curve approaches a normal distribution. To find the critical value, we need to specify the corresponding degrees of freedom, given by:
\[ df=(r-1)*(c-1) \]
where \(r\) is the number of rows and \(c\) is the number of columns in the contingency table. Recall that degrees of freedom are generally the number of values that can vary freely when calculating a statistic. In a 2 by 2 table as in our case, we have 2 variables (or two samples) with 2 levels and in each one we have 1 that vary freely. Hence, in our example the degrees of freedom can be calculated as:
Now, we can derive the critical value given the degrees of freedom and the level of confidence using the qchisq() function and test if the calculated test statistic is larger than the critical value:

Figure 5.16: Visual depiction of the test result
We could also compute the p-value using the pchisq() function, which tells us the probability of the observed cell frequencies if the null hypothesis was true (i.e., there was no association):
The test statistic can also be calculated in R directly on the contingency table with the function chisq.test() .
Since the p-value is smaller than 0.05 (i.e., the calculated test statistic is larger than the critical value), we reject H 0 that the two variables are independent.
Note that the test statistic is sensitive to the sample size. To see this, let’s assume that we have a sample of 100 observations instead of 1000 observations:
You can see that even though the proportions haven’t changed, the test is insignificant now. The following equation lets you compute a measure of the effect size, which is insensitive to sample size:
\[ \phi=\sqrt{\frac{\chi^2}{n}} \]
The following guidelines are used to determine the magnitude of the effect size (Cohen, 1988):
- 0.1 (small effect)
- 0.3 (medium effect)
- 0.5 (large effect)
In our example, we can compute the effect sizes for the large and small samples as follows:
You can see that the statistic is insensitive to the sample size.
Note that the Φ coefficient is appropriate for two dichotomous variables (resulting from a 2 x 2 table as above). If any your nominal variables has more than two categories, Cramér’s V should be used instead:
\[ V=\sqrt{\frac{\chi^2}{n*df_{min}}} \]
where \(df_{min}\) refers to the degrees of freedom associated with the variable that has fewer categories (e.g., if we have two nominal variables with 3 and 4 categories, \(df_{min}\) would be 3 - 1 = 2). The degrees of freedom need to be taken into account when judging the magnitude of the effect sizes (see e.g., here ).
Note that the correct = FALSE argument above ensures that the test statistic is computed in the same way as we have done by hand above. By default, chisq.test() applies a correction to prevent overestimation of statistical significance for small data (called the Yates’ correction). The correction is implemented by subtracting the value 0.5 from the computed difference between the observed and expected cell counts in the numerator of the test statistic. This means that the calculated test statistic will be smaller (i.e., more conservative). Although the adjustment may go too far in some instances, you should generally rely on the adjusted results, which can be computed as follows:
As you can see, the results don’t change much in our example, since the differences between the observed and expected cell frequencies are fairly large relative to the correction.
Caution is warranted when the cell counts in the contingency table are small. The usual rule of thumb is that all cell counts should be at least 5 (this may be a little too stringent though). When some cell counts are too small, you can use Fisher’s exact test using the fisher.test() function.
The Fisher test, while more conservative, also shows a significant difference between the proportions (p < 0.05). This is not surprising since the cell counts in our example are fairly large.
5.6.3 Sample size
To calculate the required sample size when comparing proportions, the power.prop.test() function can be used. For example, we could ask how large our sample needs to be if we would like to compare two groups with conversion rates of 2% and 2.5%, respectively using the conventional settings for \(\alpha\) and \(\beta\) :
The output tells us that we need 13809 observations per group to detect a difference of the desired size.
- Privacy Policy
Buy Me a Coffee
Home » What is a Hypothesis – Types, Examples and Writing Guide
What is a Hypothesis – Types, Examples and Writing Guide
Table of Contents

Definition:
Hypothesis is an educated guess or proposed explanation for a phenomenon, based on some initial observations or data. It is a tentative statement that can be tested and potentially proven or disproven through further investigation and experimentation.
Hypothesis is often used in scientific research to guide the design of experiments and the collection and analysis of data. It is an essential element of the scientific method, as it allows researchers to make predictions about the outcome of their experiments and to test those predictions to determine their accuracy.
Types of Hypothesis
Types of Hypothesis are as follows:
Research Hypothesis
A research hypothesis is a statement that predicts a relationship between variables. It is usually formulated as a specific statement that can be tested through research, and it is often used in scientific research to guide the design of experiments.
Null Hypothesis
The null hypothesis is a statement that assumes there is no significant difference or relationship between variables. It is often used as a starting point for testing the research hypothesis, and if the results of the study reject the null hypothesis, it suggests that there is a significant difference or relationship between variables.
Alternative Hypothesis
An alternative hypothesis is a statement that assumes there is a significant difference or relationship between variables. It is often used as an alternative to the null hypothesis and is tested against the null hypothesis to determine which statement is more accurate.
Directional Hypothesis
A directional hypothesis is a statement that predicts the direction of the relationship between variables. For example, a researcher might predict that increasing the amount of exercise will result in a decrease in body weight.
Non-directional Hypothesis
A non-directional hypothesis is a statement that predicts the relationship between variables but does not specify the direction. For example, a researcher might predict that there is a relationship between the amount of exercise and body weight, but they do not specify whether increasing or decreasing exercise will affect body weight.
Statistical Hypothesis
A statistical hypothesis is a statement that assumes a particular statistical model or distribution for the data. It is often used in statistical analysis to test the significance of a particular result.
Composite Hypothesis
A composite hypothesis is a statement that assumes more than one condition or outcome. It can be divided into several sub-hypotheses, each of which represents a different possible outcome.
Empirical Hypothesis
An empirical hypothesis is a statement that is based on observed phenomena or data. It is often used in scientific research to develop theories or models that explain the observed phenomena.
Simple Hypothesis
A simple hypothesis is a statement that assumes only one outcome or condition. It is often used in scientific research to test a single variable or factor.
Complex Hypothesis
A complex hypothesis is a statement that assumes multiple outcomes or conditions. It is often used in scientific research to test the effects of multiple variables or factors on a particular outcome.
Applications of Hypothesis
Hypotheses are used in various fields to guide research and make predictions about the outcomes of experiments or observations. Here are some examples of how hypotheses are applied in different fields:
- Science : In scientific research, hypotheses are used to test the validity of theories and models that explain natural phenomena. For example, a hypothesis might be formulated to test the effects of a particular variable on a natural system, such as the effects of climate change on an ecosystem.
- Medicine : In medical research, hypotheses are used to test the effectiveness of treatments and therapies for specific conditions. For example, a hypothesis might be formulated to test the effects of a new drug on a particular disease.
- Psychology : In psychology, hypotheses are used to test theories and models of human behavior and cognition. For example, a hypothesis might be formulated to test the effects of a particular stimulus on the brain or behavior.
- Sociology : In sociology, hypotheses are used to test theories and models of social phenomena, such as the effects of social structures or institutions on human behavior. For example, a hypothesis might be formulated to test the effects of income inequality on crime rates.
- Business : In business research, hypotheses are used to test the validity of theories and models that explain business phenomena, such as consumer behavior or market trends. For example, a hypothesis might be formulated to test the effects of a new marketing campaign on consumer buying behavior.
- Engineering : In engineering, hypotheses are used to test the effectiveness of new technologies or designs. For example, a hypothesis might be formulated to test the efficiency of a new solar panel design.
How to write a Hypothesis
Here are the steps to follow when writing a hypothesis:
Identify the Research Question
The first step is to identify the research question that you want to answer through your study. This question should be clear, specific, and focused. It should be something that can be investigated empirically and that has some relevance or significance in the field.
Conduct a Literature Review
Before writing your hypothesis, it’s essential to conduct a thorough literature review to understand what is already known about the topic. This will help you to identify the research gap and formulate a hypothesis that builds on existing knowledge.
Determine the Variables
The next step is to identify the variables involved in the research question. A variable is any characteristic or factor that can vary or change. There are two types of variables: independent and dependent. The independent variable is the one that is manipulated or changed by the researcher, while the dependent variable is the one that is measured or observed as a result of the independent variable.
Formulate the Hypothesis
Based on the research question and the variables involved, you can now formulate your hypothesis. A hypothesis should be a clear and concise statement that predicts the relationship between the variables. It should be testable through empirical research and based on existing theory or evidence.
Write the Null Hypothesis
The null hypothesis is the opposite of the alternative hypothesis, which is the hypothesis that you are testing. The null hypothesis states that there is no significant difference or relationship between the variables. It is important to write the null hypothesis because it allows you to compare your results with what would be expected by chance.
Refine the Hypothesis
After formulating the hypothesis, it’s important to refine it and make it more precise. This may involve clarifying the variables, specifying the direction of the relationship, or making the hypothesis more testable.
Examples of Hypothesis
Here are a few examples of hypotheses in different fields:
- Psychology : “Increased exposure to violent video games leads to increased aggressive behavior in adolescents.”
- Biology : “Higher levels of carbon dioxide in the atmosphere will lead to increased plant growth.”
- Sociology : “Individuals who grow up in households with higher socioeconomic status will have higher levels of education and income as adults.”
- Education : “Implementing a new teaching method will result in higher student achievement scores.”
- Marketing : “Customers who receive a personalized email will be more likely to make a purchase than those who receive a generic email.”
- Physics : “An increase in temperature will cause an increase in the volume of a gas, assuming all other variables remain constant.”
- Medicine : “Consuming a diet high in saturated fats will increase the risk of developing heart disease.”
Purpose of Hypothesis
The purpose of a hypothesis is to provide a testable explanation for an observed phenomenon or a prediction of a future outcome based on existing knowledge or theories. A hypothesis is an essential part of the scientific method and helps to guide the research process by providing a clear focus for investigation. It enables scientists to design experiments or studies to gather evidence and data that can support or refute the proposed explanation or prediction.
The formulation of a hypothesis is based on existing knowledge, observations, and theories, and it should be specific, testable, and falsifiable. A specific hypothesis helps to define the research question, which is important in the research process as it guides the selection of an appropriate research design and methodology. Testability of the hypothesis means that it can be proven or disproven through empirical data collection and analysis. Falsifiability means that the hypothesis should be formulated in such a way that it can be proven wrong if it is incorrect.
In addition to guiding the research process, the testing of hypotheses can lead to new discoveries and advancements in scientific knowledge. When a hypothesis is supported by the data, it can be used to develop new theories or models to explain the observed phenomenon. When a hypothesis is not supported by the data, it can help to refine existing theories or prompt the development of new hypotheses to explain the phenomenon.
When to use Hypothesis
Here are some common situations in which hypotheses are used:
- In scientific research , hypotheses are used to guide the design of experiments and to help researchers make predictions about the outcomes of those experiments.
- In social science research , hypotheses are used to test theories about human behavior, social relationships, and other phenomena.
- I n business , hypotheses can be used to guide decisions about marketing, product development, and other areas. For example, a hypothesis might be that a new product will sell well in a particular market, and this hypothesis can be tested through market research.
Characteristics of Hypothesis
Here are some common characteristics of a hypothesis:
- Testable : A hypothesis must be able to be tested through observation or experimentation. This means that it must be possible to collect data that will either support or refute the hypothesis.
- Falsifiable : A hypothesis must be able to be proven false if it is not supported by the data. If a hypothesis cannot be falsified, then it is not a scientific hypothesis.
- Clear and concise : A hypothesis should be stated in a clear and concise manner so that it can be easily understood and tested.
- Based on existing knowledge : A hypothesis should be based on existing knowledge and research in the field. It should not be based on personal beliefs or opinions.
- Specific : A hypothesis should be specific in terms of the variables being tested and the predicted outcome. This will help to ensure that the research is focused and well-designed.
- Tentative: A hypothesis is a tentative statement or assumption that requires further testing and evidence to be confirmed or refuted. It is not a final conclusion or assertion.
- Relevant : A hypothesis should be relevant to the research question or problem being studied. It should address a gap in knowledge or provide a new perspective on the issue.
Advantages of Hypothesis
Hypotheses have several advantages in scientific research and experimentation:
- Guides research: A hypothesis provides a clear and specific direction for research. It helps to focus the research question, select appropriate methods and variables, and interpret the results.
- Predictive powe r: A hypothesis makes predictions about the outcome of research, which can be tested through experimentation. This allows researchers to evaluate the validity of the hypothesis and make new discoveries.
- Facilitates communication: A hypothesis provides a common language and framework for scientists to communicate with one another about their research. This helps to facilitate the exchange of ideas and promotes collaboration.
- Efficient use of resources: A hypothesis helps researchers to use their time, resources, and funding efficiently by directing them towards specific research questions and methods that are most likely to yield results.
- Provides a basis for further research: A hypothesis that is supported by data provides a basis for further research and exploration. It can lead to new hypotheses, theories, and discoveries.
- Increases objectivity: A hypothesis can help to increase objectivity in research by providing a clear and specific framework for testing and interpreting results. This can reduce bias and increase the reliability of research findings.
Limitations of Hypothesis
Some Limitations of the Hypothesis are as follows:
- Limited to observable phenomena: Hypotheses are limited to observable phenomena and cannot account for unobservable or intangible factors. This means that some research questions may not be amenable to hypothesis testing.
- May be inaccurate or incomplete: Hypotheses are based on existing knowledge and research, which may be incomplete or inaccurate. This can lead to flawed hypotheses and erroneous conclusions.
- May be biased: Hypotheses may be biased by the researcher’s own beliefs, values, or assumptions. This can lead to selective interpretation of data and a lack of objectivity in research.
- Cannot prove causation: A hypothesis can only show a correlation between variables, but it cannot prove causation. This requires further experimentation and analysis.
- Limited to specific contexts: Hypotheses are limited to specific contexts and may not be generalizable to other situations or populations. This means that results may not be applicable in other contexts or may require further testing.
- May be affected by chance : Hypotheses may be affected by chance or random variation, which can obscure or distort the true relationship between variables.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

Data Collection – Methods Types and Examples

Delimitations in Research – Types, Examples and...

Research Process – Steps, Examples and Tips

Research Design – Types, Methods and Examples

Institutional Review Board – Application Sample...

Evaluating Research – Process, Examples and...
- What is Strategy?
- Business Models
- Developing a Strategy
- Strategic Planning
- Competitive Advantage
- Growth Strategy
- Market Strategy
- Customer Strategy
- Geographic Strategy
- Product Strategy
- Service Strategy
- Pricing Strategy
- Distribution Strategy
- Sales Strategy
- Marketing Strategy
- Digital Marketing Strategy
- Organizational Strategy
- HR Strategy – Organizational Design
- HR Strategy – Employee Journey & Culture
- Process Strategy
- Procurement Strategy
- Cost and Capital Strategy
- Business Value
- Market Analysis
- Problem Solving Skills
- Strategic Options
- Business Analytics
- Strategic Decision Making
- Process Improvement
- Project Planning
- Team Leadership
- Personal Development
- Leadership Maturity Model
- Leadership Team Strategy
- The Leadership Team
- Leadership Mindset
- Communication & Collaboration
- Problem Solving
- Decision Making
- People Leadership
- Strategic Execution
- Executive Coaching
- Strategy Coaching
- Business Transformation
- Strategy Workshops
- Leadership Strategy Survey
- Leadership Training
- Who’s Joe?
“A fact is a simple statement that everyone believes. It is innocent, unless found guilty. A hypothesis is a novel suggestion that no one wants to believe. It is guilty until found effective.”
– Edward Teller, Nuclear Physicist
During my first brainstorming meeting on my first project at McKinsey, this very serious partner, who had a PhD in Physics, looked at me and said, “So, Joe, what are your main hypotheses.” I looked back at him, perplexed, and said, “Ummm, my what?” I was used to people simply asking, “what are your best ideas, opinions, thoughts, etc.” Over time, I began to understand the importance of hypotheses and how it plays an important role in McKinsey’s problem solving of separating ideas and opinions from facts.
What is a Hypothesis?
“Hypothesis” is probably one of the top 5 words used by McKinsey consultants. And, being hypothesis-driven was required to have any success at McKinsey. A hypothesis is an idea or theory, often based on limited data, which is typically the beginning of a thread of further investigation to prove, disprove or improve the hypothesis through facts and empirical data.
The first step in being hypothesis-driven is to focus on the highest potential ideas and theories of how to solve a problem or realize an opportunity.
Let’s go over an example of being hypothesis-driven.
Let’s say you own a website, and you brainstorm ten ideas to improve web traffic, but you don’t have the budget to execute all ten ideas. The first step in being hypothesis-driven is to prioritize the ten ideas based on how much impact you hypothesize they will create.

The second step in being hypothesis-driven is to apply the scientific method to your hypotheses by creating the fact base to prove or disprove your hypothesis, which then allows you to turn your hypothesis into fact and knowledge. Running with our example, you could prove or disprove your hypothesis on the ideas you think will drive the most impact by executing:
1. An analysis of previous research and the performance of the different ideas 2. A survey where customers rank order the ideas 3. An actual test of the ten ideas to create a fact base on click-through rates and cost
While there are many other ways to validate the hypothesis on your prioritization , I find most people do not take this critical step in validating a hypothesis. Instead, they apply bad logic to many important decisions . An idea pops into their head, and then somehow it just becomes a fact.
One of my favorite lousy logic moments was a CEO who stated,
“I’ve never heard our customers talk about price, so the price doesn’t matter with our products , and I’ve decided we’re going to raise prices.”
Luckily, his management team was able to do a survey to dig deeper into the hypothesis that customers weren’t price-sensitive. Well, of course, they were and through the survey, they built a fantastic fact base that proved and disproved many other important hypotheses.
Why is being hypothesis-driven so important?
Imagine if medicine never actually used the scientific method. We would probably still be living in a world of lobotomies and bleeding people. Many organizations are still stuck in the dark ages, having built a house of cards on opinions disguised as facts, because they don’t prove or disprove their hypotheses. Decisions made on top of decisions, made on top of opinions, steer organizations clear of reality and the facts necessary to objectively evolve their strategic understanding and knowledge. I’ve seen too many leadership teams led solely by gut and opinion. The problem with intuition and gut is if you don’t ever prove or disprove if your gut is right or wrong, you’re never going to improve your intuition. There is a reason why being hypothesis-driven is the cornerstone of problem solving at McKinsey and every other top strategy consulting firm.
How do you become hypothesis-driven?
Most people are idea-driven, and constantly have hypotheses on how the world works and what they or their organization should do to improve. Though, there is often a fatal flaw in that many people turn their hypotheses into false facts, without actually finding or creating the facts to prove or disprove their hypotheses. These people aren’t hypothesis-driven; they are gut-driven.
The conversation typically goes something like “doing this discount promotion will increase our profits” or “our customers need to have this feature” or “morale is in the toilet because we don’t pay well, so we need to increase pay.” These should all be hypotheses that need the appropriate fact base, but instead, they become false facts, often leading to unintended results and consequences. In each of these cases, to become hypothesis-driven necessitates a different framing.
• Instead of “doing this discount promotion will increase our profits,” a hypothesis-driven approach is to ask “what are the best marketing ideas to increase our profits?” and then conduct a marketing experiment to see which ideas increase profits the most.
• Instead of “our customers need to have this feature,” ask the question, “what features would our customers value most?” And, then conduct a simple survey having customers rank order the features based on value to them.
• Instead of “morale is in the toilet because we don’t pay well, so we need to increase pay,” conduct a survey asking, “what is the level of morale?” what are potential issues affecting morale?” and what are the best ideas to improve morale?”
Beyond, watching out for just following your gut, here are some of the other best practices in being hypothesis-driven:
Listen to Your Intuition
Your mind has taken the collision of your experiences and everything you’ve learned over the years to create your intuition, which are those ideas that pop into your head and those hunches that come from your gut. Your intuition is your wellspring of hypotheses. So listen to your intuition, build hypotheses from it, and then prove or disprove those hypotheses, which will, in turn, improve your intuition. Intuition without feedback will over time typically evolve into poor intuition, which leads to poor judgment, thinking, and decisions.
Constantly Be Curious
I’m always curious about cause and effect. At Sports Authority, I had a hypothesis that customers that received service and assistance as they shopped, were worth more than customers who didn’t receive assistance from an associate. We figured out how to prove or disprove this hypothesis by tying surveys to transactional data of customers, and we found the hypothesis was true, which led us to a broad initiative around improving service. The key is you have to be always curious about what you think does or will drive value, create hypotheses and then prove or disprove those hypotheses.
Validate Hypotheses
You need to validate and prove or disprove hypotheses. Don’t just chalk up an idea as fact. In most cases, you’re going to have to create a fact base utilizing logic, observation, testing (see the section on Experimentation ), surveys, and analysis.
Be a Learning Organization
The foundation of learning organizations is the testing of and learning from hypotheses. I remember my first strategy internship at Mercer Management Consulting when I spent a good part of the summer combing through the results, findings, and insights of thousands of experiments that a banking client had conducted. It was fascinating to see the vastness and depth of their collective knowledge base. And, in today’s world of knowledge portals, it is so easy to disseminate, learn from, and build upon the knowledge created by companies.
NEXT SECTION: DISAGGREGATION
DOWNLOAD STRATEGY PRESENTATION TEMPLATES
168-PAGE COMPENDIUM OF STRATEGY FRAMEWORKS & TEMPLATES 186-PAGE HR & ORG STRATEGY PRESENTATION 100-PAGE SALES PLAN PRESENTATION 121-PAGE STRATEGIC PLAN & COMPANY OVERVIEW PRESENTATION 114-PAGE MARKET & COMPETITIVE ANALYSIS PRESENTATION 18-PAGE BUSINESS MODEL TEMPLATE
JOE NEWSUM COACHING
EXECUTIVE COACHING STRATEGY COACHING ELEVATE360 BUSINESS TRANSFORMATION STRATEGY WORKSHOPS LEADERSHIP STRATEGY SURVEY & WORKSHOP STRATEGY & LEADERSHIP TRAINING
THE LEADERSHIP MATURITY MODEL
Explore other types of strategy.
BIG PICTURE WHAT IS STRATEGY? BUSINESS MODEL COMP. ADVANTAGE GROWTH
TARGETS MARKET CUSTOMER GEOGRAPHIC
VALUE PROPOSITION PRODUCT SERVICE PRICING
GO TO MARKET DISTRIBUTION SALES MARKETING
ORGANIZATIONAL ORG DESIGN HR & CULTURE PROCESS PARTNER
EXPLORE THE TOP 100 STRATEGIC LEADERSHIP COMPETENCIES
TYPES OF VALUE MARKET ANALYSIS PROBLEM SOLVING
OPTION CREATION ANALYTICS DECISION MAKING PROCESS TOOLS
PLANNING & PROJECTS PEOPLE LEADERSHIP PERSONAL DEVELOPMENT
- Resources Home 🏠
- Try SciSpace Copilot
- Search research papers
- Add Copilot Extension
- Try AI Detector
- Try Paraphraser
- Try Citation Generator
- April Papers
- June Papers
- July Papers

The Craft of Writing a Strong Hypothesis

Table of Contents
Writing a hypothesis is one of the essential elements of a scientific research paper. It needs to be to the point, clearly communicating what your research is trying to accomplish. A blurry, drawn-out, or complexly-structured hypothesis can confuse your readers. Or worse, the editor and peer reviewers.
A captivating hypothesis is not too intricate. This blog will take you through the process so that, by the end of it, you have a better idea of how to convey your research paper's intent in just one sentence.
What is a Hypothesis?
The first step in your scientific endeavor, a hypothesis, is a strong, concise statement that forms the basis of your research. It is not the same as a thesis statement , which is a brief summary of your research paper .
The sole purpose of a hypothesis is to predict your paper's findings, data, and conclusion. It comes from a place of curiosity and intuition . When you write a hypothesis, you're essentially making an educated guess based on scientific prejudices and evidence, which is further proven or disproven through the scientific method.
The reason for undertaking research is to observe a specific phenomenon. A hypothesis, therefore, lays out what the said phenomenon is. And it does so through two variables, an independent and dependent variable.
The independent variable is the cause behind the observation, while the dependent variable is the effect of the cause. A good example of this is “mixing red and blue forms purple.” In this hypothesis, mixing red and blue is the independent variable as you're combining the two colors at your own will. The formation of purple is the dependent variable as, in this case, it is conditional to the independent variable.
Different Types of Hypotheses

Types of hypotheses
Some would stand by the notion that there are only two types of hypotheses: a Null hypothesis and an Alternative hypothesis. While that may have some truth to it, it would be better to fully distinguish the most common forms as these terms come up so often, which might leave you out of context.
Apart from Null and Alternative, there are Complex, Simple, Directional, Non-Directional, Statistical, and Associative and casual hypotheses. They don't necessarily have to be exclusive, as one hypothesis can tick many boxes, but knowing the distinctions between them will make it easier for you to construct your own.
1. Null hypothesis
A null hypothesis proposes no relationship between two variables. Denoted by H 0 , it is a negative statement like “Attending physiotherapy sessions does not affect athletes' on-field performance.” Here, the author claims physiotherapy sessions have no effect on on-field performances. Even if there is, it's only a coincidence.
2. Alternative hypothesis
Considered to be the opposite of a null hypothesis, an alternative hypothesis is donated as H1 or Ha. It explicitly states that the dependent variable affects the independent variable. A good alternative hypothesis example is “Attending physiotherapy sessions improves athletes' on-field performance.” or “Water evaporates at 100 °C. ” The alternative hypothesis further branches into directional and non-directional.
- Directional hypothesis: A hypothesis that states the result would be either positive or negative is called directional hypothesis. It accompanies H1 with either the ‘<' or ‘>' sign.
- Non-directional hypothesis: A non-directional hypothesis only claims an effect on the dependent variable. It does not clarify whether the result would be positive or negative. The sign for a non-directional hypothesis is ‘≠.'
3. Simple hypothesis
A simple hypothesis is a statement made to reflect the relation between exactly two variables. One independent and one dependent. Consider the example, “Smoking is a prominent cause of lung cancer." The dependent variable, lung cancer, is dependent on the independent variable, smoking.
4. Complex hypothesis
In contrast to a simple hypothesis, a complex hypothesis implies the relationship between multiple independent and dependent variables. For instance, “Individuals who eat more fruits tend to have higher immunity, lesser cholesterol, and high metabolism.” The independent variable is eating more fruits, while the dependent variables are higher immunity, lesser cholesterol, and high metabolism.
5. Associative and casual hypothesis
Associative and casual hypotheses don't exhibit how many variables there will be. They define the relationship between the variables. In an associative hypothesis, changing any one variable, dependent or independent, affects others. In a casual hypothesis, the independent variable directly affects the dependent.
6. Empirical hypothesis
Also referred to as the working hypothesis, an empirical hypothesis claims a theory's validation via experiments and observation. This way, the statement appears justifiable and different from a wild guess.
Say, the hypothesis is “Women who take iron tablets face a lesser risk of anemia than those who take vitamin B12.” This is an example of an empirical hypothesis where the researcher the statement after assessing a group of women who take iron tablets and charting the findings.
7. Statistical hypothesis
The point of a statistical hypothesis is to test an already existing hypothesis by studying a population sample. Hypothesis like “44% of the Indian population belong in the age group of 22-27.” leverage evidence to prove or disprove a particular statement.
Characteristics of a Good Hypothesis
Writing a hypothesis is essential as it can make or break your research for you. That includes your chances of getting published in a journal. So when you're designing one, keep an eye out for these pointers:
- A research hypothesis has to be simple yet clear to look justifiable enough.
- It has to be testable — your research would be rendered pointless if too far-fetched into reality or limited by technology.
- It has to be precise about the results —what you are trying to do and achieve through it should come out in your hypothesis.
- A research hypothesis should be self-explanatory, leaving no doubt in the reader's mind.
- If you are developing a relational hypothesis, you need to include the variables and establish an appropriate relationship among them.
- A hypothesis must keep and reflect the scope for further investigations and experiments.
Separating a Hypothesis from a Prediction
Outside of academia, hypothesis and prediction are often used interchangeably. In research writing, this is not only confusing but also incorrect. And although a hypothesis and prediction are guesses at their core, there are many differences between them.
A hypothesis is an educated guess or even a testable prediction validated through research. It aims to analyze the gathered evidence and facts to define a relationship between variables and put forth a logical explanation behind the nature of events.
Predictions are assumptions or expected outcomes made without any backing evidence. They are more fictionally inclined regardless of where they originate from.
For this reason, a hypothesis holds much more weight than a prediction. It sticks to the scientific method rather than pure guesswork. "Planets revolve around the Sun." is an example of a hypothesis as it is previous knowledge and observed trends. Additionally, we can test it through the scientific method.
Whereas "COVID-19 will be eradicated by 2030." is a prediction. Even though it results from past trends, we can't prove or disprove it. So, the only way this gets validated is to wait and watch if COVID-19 cases end by 2030.
Finally, How to Write a Hypothesis

Quick tips on writing a hypothesis
1. Be clear about your research question
A hypothesis should instantly address the research question or the problem statement. To do so, you need to ask a question. Understand the constraints of your undertaken research topic and then formulate a simple and topic-centric problem. Only after that can you develop a hypothesis and further test for evidence.
2. Carry out a recce
Once you have your research's foundation laid out, it would be best to conduct preliminary research. Go through previous theories, academic papers, data, and experiments before you start curating your research hypothesis. It will give you an idea of your hypothesis's viability or originality.
Making use of references from relevant research papers helps draft a good research hypothesis. SciSpace Discover offers a repository of over 270 million research papers to browse through and gain a deeper understanding of related studies on a particular topic. Additionally, you can use SciSpace Copilot , your AI research assistant, for reading any lengthy research paper and getting a more summarized context of it. A hypothesis can be formed after evaluating many such summarized research papers. Copilot also offers explanations for theories and equations, explains paper in simplified version, allows you to highlight any text in the paper or clip math equations and tables and provides a deeper, clear understanding of what is being said. This can improve the hypothesis by helping you identify potential research gaps.
3. Create a 3-dimensional hypothesis
Variables are an essential part of any reasonable hypothesis. So, identify your independent and dependent variable(s) and form a correlation between them. The ideal way to do this is to write the hypothetical assumption in the ‘if-then' form. If you use this form, make sure that you state the predefined relationship between the variables.
In another way, you can choose to present your hypothesis as a comparison between two variables. Here, you must specify the difference you expect to observe in the results.
4. Write the first draft
Now that everything is in place, it's time to write your hypothesis. For starters, create the first draft. In this version, write what you expect to find from your research.
Clearly separate your independent and dependent variables and the link between them. Don't fixate on syntax at this stage. The goal is to ensure your hypothesis addresses the issue.
5. Proof your hypothesis
After preparing the first draft of your hypothesis, you need to inspect it thoroughly. It should tick all the boxes, like being concise, straightforward, relevant, and accurate. Your final hypothesis has to be well-structured as well.
Research projects are an exciting and crucial part of being a scholar. And once you have your research question, you need a great hypothesis to begin conducting research. Thus, knowing how to write a hypothesis is very important.
Now that you have a firmer grasp on what a good hypothesis constitutes, the different kinds there are, and what process to follow, you will find it much easier to write your hypothesis, which ultimately helps your research.
Now it's easier than ever to streamline your research workflow with SciSpace Discover . Its integrated, comprehensive end-to-end platform for research allows scholars to easily discover, write and publish their research and fosters collaboration.
It includes everything you need, including a repository of over 270 million research papers across disciplines, SEO-optimized summaries and public profiles to show your expertise and experience.
If you found these tips on writing a research hypothesis useful, head over to our blog on Statistical Hypothesis Testing to learn about the top researchers, papers, and institutions in this domain.
Frequently Asked Questions (FAQs)
1. what is the definition of hypothesis.
According to the Oxford dictionary, a hypothesis is defined as “An idea or explanation of something that is based on a few known facts, but that has not yet been proved to be true or correct”.
2. What is an example of hypothesis?
The hypothesis is a statement that proposes a relationship between two or more variables. An example: "If we increase the number of new users who join our platform by 25%, then we will see an increase in revenue."
3. What is an example of null hypothesis?
A null hypothesis is a statement that there is no relationship between two variables. The null hypothesis is written as H0. The null hypothesis states that there is no effect. For example, if you're studying whether or not a particular type of exercise increases strength, your null hypothesis will be "there is no difference in strength between people who exercise and people who don't."
4. What are the types of research?
• Fundamental research
• Applied research
• Qualitative research
• Quantitative research
• Mixed research
• Exploratory research
• Longitudinal research
• Cross-sectional research
• Field research
• Laboratory research
• Fixed research
• Flexible research
• Action research
• Policy research
• Classification research
• Comparative research
• Causal research
• Inductive research
• Deductive research
5. How to write a hypothesis?
• Your hypothesis should be able to predict the relationship and outcome.
• Avoid wordiness by keeping it simple and brief.
• Your hypothesis should contain observable and testable outcomes.
• Your hypothesis should be relevant to the research question.
6. What are the 2 types of hypothesis?
• Null hypotheses are used to test the claim that "there is no difference between two groups of data".
• Alternative hypotheses test the claim that "there is a difference between two data groups".
7. Difference between research question and research hypothesis?
A research question is a broad, open-ended question you will try to answer through your research. A hypothesis is a statement based on prior research or theory that you expect to be true due to your study. Example - Research question: What are the factors that influence the adoption of the new technology? Research hypothesis: There is a positive relationship between age, education and income level with the adoption of the new technology.
8. What is plural for hypothesis?
The plural of hypothesis is hypotheses. Here's an example of how it would be used in a statement, "Numerous well-considered hypotheses are presented in this part, and they are supported by tables and figures that are well-illustrated."
9. What is the red queen hypothesis?
The red queen hypothesis in evolutionary biology states that species must constantly evolve to avoid extinction because if they don't, they will be outcompeted by other species that are evolving. Leigh Van Valen first proposed it in 1973; since then, it has been tested and substantiated many times.
10. Who is known as the father of null hypothesis?
The father of the null hypothesis is Sir Ronald Fisher. He published a paper in 1925 that introduced the concept of null hypothesis testing, and he was also the first to use the term itself.
11. When to reject null hypothesis?
You need to find a significant difference between your two populations to reject the null hypothesis. You can determine that by running statistical tests such as an independent sample t-test or a dependent sample t-test. You should reject the null hypothesis if the p-value is less than 0.05.
You might also like

Consensus GPT vs. SciSpace GPT: Choose the Best GPT for Research

Literature Review and Theoretical Framework: Understanding the Differences

Types of Essays in Academic Writing
9.4 Full Hypothesis Test Examples
Tests on means, example 9.8.
Jeffrey, as an eight-year old, established a mean time of 16.43 seconds for swimming the 25-yard freestyle, with a standard deviation of 0.8 seconds . His dad, Frank, thought that Jeffrey could swim the 25-yard freestyle faster using goggles. Frank bought Jeffrey a new pair of expensive goggles and timed Jeffrey for 15 25-yard freestyle swims . For the 15 swims, Jeffrey's mean time was 16 seconds. Frank thought that the goggles helped Jeffrey to swim faster than the 16.43 seconds. Conduct a hypothesis test using a preset α = 0.05. Assume that the swim times for the 25-yard freestyle are normal.
Set up the Hypothesis Test:
Since the problem is about a mean, this is a test of a single population mean .
H 0 : μ = 16.43 H a : μ < 16.43
For Jeffrey to swim faster, his time will be less than 16.43 seconds. The "<" tells you this is left-tailed.
Determine the distribution needed:
Random variable: X ¯ X ¯ = the mean time to swim the 25-yard freestyle.
Distribution for the test: X ¯ X ¯ is normal (population standard deviation is known: σ = 0.8)
X ¯ ~ N ( μ , σ X n ) X ¯ ~ N ( μ , σ X n ) Therefore, X ¯ ~ N ( 16.43 , 0.8 15 ) X ¯ ~ N ( 16.43 , 0.8 15 )
μ = 16.43 comes from H 0 and not the data. σ = 0.8, and n = 15.
Calculate the p -value using the normal distribution for a mean:
p -value = P ( x ¯ x ¯ < 16) = 0.0187 where the sample mean in the problem is given as 16.
p -value = 0.0187 (This is called the actual level of significance .) The p -value is the area to the left of the sample mean is given as 16.
μ = 16.43 comes from H 0 . Our assumption is μ = 16.43.
Interpretation of the p -value: If H 0 is true , there is a 0.0187 probability (1.87%)that Jeffrey's mean time to swim the 25-yard freestyle is 16 seconds or less. Because a 1.87% chance is small, the mean time of 16 seconds or less is unlikely to have happened randomly. It is a rare event.
Compare α and the p -value:
α = 0.05 p -value = 0.0187 α > p -value
Make a decision: Since α > α > p -value, reject H 0 .
This indicates that you reject the null hypothesis that the mean time to swim the 25-yard freestyle is at least 16.43 seconds.
Conclusion: At the 5% significance level, there is sufficient evidence that Jeffrey's mean time to swim the 25-yard freestyle is less than 16.43 seconds. Thus, based on the sample data, we conclude that Jeffrey swims faster using the new goggles.
The Type I and Type II errors for this problem are as follows: The Type I error is to conclude that Jeffrey swims the 25-yard freestyle, on average, in less than 16.43 seconds when, in fact, he actually swims the 25-yard freestyle, on average, in at least 16.43 seconds. (Reject the null hypothesis when the null hypothesis is true.)
The Type II error is that there is not evidence to conclude that Jeffrey swims the 25-yard freestyle, on average, in less than 16.43 seconds when, in fact, he actually does swim the 25-yard free-style, on average, in less than 16.43 seconds. (Do not reject the null hypothesis when the null hypothesis is false.)
The mean throwing distance of a football for Marco, a high school quarterback, is 40 yards, with a standard deviation of two yards. The team coach tells Marco to adjust his grip to get more distance. The coach records the distances for 20 throws. For the 20 throws, Marco’s mean distance was 45 yards. The coach thought the different grip helped Marco throw farther than 40 yards. Conduct a hypothesis test using a preset α = 0.05. Assume the throw distances for footballs are normal.
First, determine what type of test this is, set up the hypothesis test, find the p -value, sketch the graph, and state your conclusion.
Example 9.9
Jasmine has just begun her new job on the sales force of a very competitive company. In a sample of 16 sales calls it was found that she closed the contract for an average value of 108 dollars with a standard deviation of 12 dollars. Test at 5% significance that the population mean is at least 100 dollars against the alternative that it is less than 100 dollars. Company policy requires that new members of the sales force must exceed an average of $100 per contract during the trial employment period. Can we conclude that Jasmine has met this requirement at the significance level of 95%?
- H 0 : µ ≤ 100 H a : µ > 100 The null and alternative hypothesis are for the parameter µ because the number of dollars of the contracts is a continuous random variable. Also, this is a one-tailed test because the company has only an interested if the number of dollars per contact is below a particular number not "too high" a number. This can be thought of as making a claim that the requirement is being met and thus the claim is in the alternative hypothesis.
- Test statistic: t c = x ¯ − µ 0 s n = 108 − 100 ( 12 16 ) = 2.67 t c = x ¯ − µ 0 s n = 108 − 100 ( 12 16 ) = 2.67
- Critical value: t a = 1.753 t a = 1.753 with n-1 degrees of freedom= 15
The test statistic is a Student's t because the sample size is below 30; therefore, we cannot use the normal distribution. Comparing the calculated value of the test statistic and the critical value of t t ( t a ) ( t a ) at a 5% significance level, we see that the calculated value is in the tail of the distribution. Thus, we conclude that 108 dollars per contract is significantly larger than the hypothesized value of 100 and thus we cannot accept the null hypothesis. There is evidence that supports Jasmine's performance meets company standards.
It is believed that a stock price for a particular company will grow at a rate of $5 per week with a standard deviation of $1. An investor believes the stock won’t grow as quickly. The changes in stock price is recorded for ten weeks and are as follows: $4, $3, $2, $3, $1, $7, $2, $1, $1, $2. Perform a hypothesis test using a 5% level of significance. State the null and alternative hypotheses, state your conclusion, and identify the Type I errors.
Example 9.10
A manufacturer of salad dressings uses machines to dispense liquid ingredients into bottles that move along a filling line. The machine that dispenses salad dressings is working properly when 8 ounces are dispensed. Suppose that the average amount dispensed in a particular sample of 35 bottles is 7.91 ounces with a variance of 0.03 ounces squared, s 2 s 2 . Is there evidence that the machine should be stopped and production wait for repairs? The lost production from a shutdown is potentially so great that management feels that the level of significance in the analysis should be 99%.
Again we will follow the steps in our analysis of this problem.
STEP 1 : Set the Null and Alternative Hypothesis. The random variable is the quantity of fluid placed in the bottles. This is a continuous random variable and the parameter we are interested in is the mean. Our hypothesis therefore is about the mean. In this case we are concerned that the machine is not filling properly. From what we are told it does not matter if the machine is over-filling or under-filling, both seem to be an equally bad error. This tells us that this is a two-tailed test: if the machine is malfunctioning it will be shutdown regardless if it is from over-filling or under-filling. The null and alternative hypotheses are thus:
STEP 2 : Decide the level of significance and draw the graph showing the critical value.
This problem has already set the level of significance at 99%. The decision seems an appropriate one and shows the thought process when setting the significance level. Management wants to be very certain, as certain as probability will allow, that they are not shutting down a machine that is not in need of repair. To draw the distribution and the critical value, we need to know which distribution to use. Because this is a continuous random variable and we are interested in the mean, and the sample size is greater than 30, the appropriate distribution is the normal distribution and the relevant critical value is 2.575 from the normal table or the t-table at 0.005 column and infinite degrees of freedom. We draw the graph and mark these points.
STEP 3 : Calculate sample parameters and the test statistic. The sample parameters are provided, the sample mean is 7.91 and the sample variance is .03 and the sample size is 35. We need to note that the sample variance was provided not the sample standard deviation, which is what we need for the formula. Remembering that the standard deviation is simply the square root of the variance, we therefore know the sample standard deviation, s, is 0.173. With this information we calculate the test statistic as -3.07, and mark it on the graph.
STEP 4 : Compare test statistic and the critical values Now we compare the test statistic and the critical value by placing the test statistic on the graph. We see that the test statistic is in the tail, decidedly greater than the critical value of 2.575. We note that even the very small difference between the hypothesized value and the sample value is still a large number of standard deviations. The sample mean is only 0.08 ounces different from the required level of 8 ounces, but it is 3 plus standard deviations away and thus we cannot accept the null hypothesis.
STEP 5 : Reach a Conclusion
Three standard deviations of a test statistic will guarantee that the test will fail. The probability that anything is within three standard deviations is almost zero. Actually it is 0.0026 on the normal distribution, which is certainly almost zero in a practical sense. Our formal conclusion would be “ At a 99% level of significance we cannot accept the hypothesis that the sample mean came from a distribution with a mean of 8 ounces” Or less formally, and getting to the point, “At a 99% level of significance we conclude that the machine is under filling the bottles and is in need of repair”.
Try It 9.10
A company records the mean time of employees working in a day. The mean comes out to be 475 minutes, with a standard deviation of 45 minutes. A manager recorded times of 20 employees. The times of working were (frequencies are in parentheses) 460(3); 465(2); 470(3); 475(1); 480(6); 485(3); 490(2).
Conduct a hypothesis test using a 2.5% level of significance to determine if the mean time is more than 475 .
Hypothesis Test for Proportions
Just as there were confidence intervals for proportions, or more formally, the population parameter p of the binomial distribution, there is the ability to test hypotheses concerning p .
The population parameter for the binomial is p . The estimated value (point estimate) for p is p′ where p′ = x/n , x is the number of successes in the sample and n is the sample size.
When you perform a hypothesis test of a population proportion p , you take a simple random sample from the population. The conditions for a binomial distribution must be met, which are: there are a certain number n of independent trials meaning random sampling, the outcomes of any trial are binary, success or failure, and each trial has the same probability of a success p . The shape of the binomial distribution needs to be similar to the shape of the normal distribution. To ensure this, the quantities np′ and nq′ must both be greater than five ( np′ > 5 and nq′ > 5). In this case the binomial distribution of a sample (estimated) proportion can be approximated by the normal distribution with μ = np μ = np and σ = npq σ = npq . Remember that q = 1 – p q = 1 – p . There is no distribution that can correct for this small sample bias and thus if these conditions are not met we simply cannot test the hypothesis with the data available at that time. We met this condition when we first were estimating confidence intervals for p .
Again, we begin with the standardizing formula modified because this is the distribution of a binomial.
Substituting p 0 p 0 , the hypothesized value of p , we have:
This is the test statistic for testing hypothesized values of p , where the null and alternative hypotheses take one of the following forms:
The decision rule stated above applies here also: if the calculated value of Z c shows that the sample proportion is "too many" standard deviations from the hypothesized proportion, the null hypothesis cannot be accepted. The decision as to what is "too many" is pre-determined by the analyst depending on the level of significance required in the test.
Example 9.11
The mortgage department of a large bank is interested in the nature of loans of first-time borrowers. This information will be used to tailor their marketing strategy. They believe that 50% of first-time borrowers take out smaller loans than other borrowers. They perform a hypothesis test to determine if the percentage is the same or different from 50% . They sample 100 first-time borrowers and find 53 of these loans are smaller that the other borrowers. For the hypothesis test, they choose a 5% level of significance.
STEP 1 : Set the null and alternative hypothesis.
H 0 : p = 0.50 H a : p ≠ 0.50
The words "is the same or different from" tell you this is a two-tailed test. The Type I and Type II errors are as follows: The Type I error is to conclude that the proportion of borrowers is different from 50% when, in fact, the proportion is actually 50%. (Reject the null hypothesis when the null hypothesis is true). The Type II error is there is not enough evidence to conclude that the proportion of first time borrowers differs from 50% when, in fact, the proportion does differ from 50%. (You fail to reject the null hypothesis when the null hypothesis is false.)
STEP 2 : Decide the level of significance and draw the graph showing the critical value
The level of significance has been set by the problem at the 5% level. Because this is two-tailed test one-half of the alpha value will be in the upper tail and one-half in the lower tail as shown on the graph. The critical value for the normal distribution at the 95% level of confidence is 1.96. This can easily be found on the student’s t-table at the very bottom at infinite degrees of freedom remembering that at infinity the t-distribution is the normal distribution. Of course the value can also be found on the normal table but you have go looking for one-half of 95 (0.475) inside the body of the table and then read out to the sides and top for the number of standard deviations.
STEP 3 : Calculate the sample parameters and critical value of the test statistic.
The test statistic is a normal distribution, Z, for testing proportions and is:
For this case, the sample of 100 found 53 of these loans were smaller than those of other borrowers. The sample proportion, p′ = 53/100= 0.53 The test question, therefore, is : “Is 0.53 significantly different from .50?” Putting these values into the formula for the test statistic we find that 0.53 is only 0.60 standard deviations away from .50. This is barely off of the mean of the standard normal distribution of zero. There is virtually no difference from the sample proportion and the hypothesized proportion in terms of standard deviations.
STEP 4 : Compare the test statistic and the critical value.
The calculated value is well within the critical values of ± 1.96 standard deviations and thus we cannot reject the null hypothesis. To reject the null hypothesis we need significant evident of difference between the hypothesized value and the sample value. In this case the sample value is very nearly the same as the hypothesized value measured in terms of standard deviations.
STEP 5 : Reach a conclusion
The formal conclusion would be “At a 5% level of significance we cannot reject the null hypothesis that 50% of first-time borrowers take out smaller loans than other borrowers.” Notice the length to which the conclusion goes to include all of the conditions that are attached to the conclusion. Statisticians, for all the criticism they receive, are careful to be very specific even when this seems trivial. Statisticians cannot say more than they know, and the data constrain the conclusion to be within the metes and bounds of the data.
Try It 9.11
A teacher believes that 85% of students in the class will want to go on a field trip to the local zoo. The teacher performs a hypothesis test to determine if the percentage is the same or different from 85%. The teacher samples 50 students and 39 reply that they would want to go to the zoo. For the hypothesis test, use a 1% level of significance.
Example 9.12
Suppose a consumer group suspects that the proportion of households that have three or more cell phones is 30%. A cell phone company has reason to believe that the proportion is not 30%. Before they start a big advertising campaign, they conduct a hypothesis test. Their marketing people survey 150 households with the result that 43 of the households have three or more cell phones.
Here is an abbreviate version of the system to solve hypothesis tests applied to a test on a proportions.
Try It 9.12
Marketers believe that 92% of adults in the United States own a cell phone. A cell phone manufacturer believes that number is actually lower. 200 American adults are surveyed, of which, 174 report having cell phones. Use a 5% level of significance. State the null and alternative hypothesis, find the p -value, state your conclusion, and identify the Type I and Type II errors.
Example 9.13
The National Institute of Standards and Technology provides exact data on conductivity properties of materials. Following are conductivity measurements for 11 randomly selected pieces of a particular type of glass.
1.11; 1.07; 1.11; 1.07; 1.12; 1.08; .98; .98; 1.02; .95; .95 Is there convincing evidence that the average conductivity of this type of glass is greater than one? Use a significance level of 0.05.
Let’s follow a four-step process to answer this statistical question.
- H 0 : μ ≤ 1
- H a : μ > 1
- Plan : We are testing a sample mean without a known population standard deviation with less than 30 observations. Therefore, we need to use a Student's-t distribution. Assume the underlying population is normal.
- Do the calculations and draw the graph .
- State the Conclusions : We cannot accept the null hypothesis. It is reasonable to state that the data supports the claim that the average conductivity level is greater than one.
Try It 9.13
The boiling point of a specific liquid is measured for 15 samples, and the boiling points are obtained as follows:
205; 206; 206; 202; 199; 194; 197; 198; 198; 201; 201; 202; 207; 211; 205
Is there convincing evidence that the average boiling point is greater than 200? Use a significance level of 0.1. Assume the population is normal.
Example 9.14
In a study of 420,019 cell phone users, 172 of the subjects developed brain cancer. Test the claim that cell phone users developed brain cancer at a greater rate than that for non-cell phone users (the rate of brain cancer for non-cell phone users is 0.0340%). Since this is a critical issue, use a 0.005 significance level. Explain why the significance level should be so low in terms of a Type I error.
- H 0 : p ≤ 0.00034
- H a : p > 0.00034
If we commit a Type I error, we are essentially accepting a false claim. Since the claim describes cancer-causing environments, we want to minimize the chances of incorrectly identifying causes of cancer.
- We will be testing a sample proportion with x = 172 and n = 420,019. The sample is sufficiently large because we have np' = 420,019(0.00034) = 142.8, nq' = 420,019(0.99966) = 419,876.2, two independent outcomes, and a fixed probability of success p' = 0.00034. Thus we will be able to generalize our results to the population.
Try It 9.14
In a study of 390,000 moisturizer users, 138 of the subjects developed skin diseases. Test the claim that moisturizer users developed skin diseases at a greater rate than that for non-moisturizer users (the rate of skin diseases for non-moisturizer users is 0.041%). Since this is a critical issue, use a 0.005 significance level. Explain why the significance level should be so low in terms of a Type I error.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute OpenStax.
Access for free at https://openstax.org/books/introductory-business-statistics-2e/pages/1-introduction
- Authors: Alexander Holmes, Barbara Illowsky, Susan Dean
- Publisher/website: OpenStax
- Book title: Introductory Business Statistics 2e
- Publication date: Dec 13, 2023
- Location: Houston, Texas
- Book URL: https://openstax.org/books/introductory-business-statistics-2e/pages/1-introduction
- Section URL: https://openstax.org/books/introductory-business-statistics-2e/pages/9-4-full-hypothesis-test-examples
© Dec 6, 2023 OpenStax. Textbook content produced by OpenStax is licensed under a Creative Commons Attribution License . The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Best Family Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Verywell Mind Insights
- 2023 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
How to Write a Great Hypothesis
Hypothesis Format, Examples, and Tips
Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."
:max_bytes(150000):strip_icc():format(webp)/IMG_9791-89504ab694d54b66bbd72cb84ffb860e.jpg "hypothesis examples marketing")
Amy Morin, LCSW, is a psychotherapist and international bestselling author. Her books, including "13 Things Mentally Strong People Don't Do," have been translated into more than 40 languages. Her TEDx talk, "The Secret of Becoming Mentally Strong," is one of the most viewed talks of all time.
:max_bytes(150000):strip_icc():format(webp)/VW-MIND-Amy-2b338105f1ee493f94d7e333e410fa76.jpg "hypothesis examples marketing")
Verywell / Alex Dos Diaz
- The Scientific Method
Hypothesis Format
Falsifiability of a hypothesis, operational definitions, types of hypotheses, hypotheses examples.
- Collecting Data
Frequently Asked Questions
A hypothesis is a tentative statement about the relationship between two or more variables. It is a specific, testable prediction about what you expect to happen in a study.
One hypothesis example would be a study designed to look at the relationship between sleep deprivation and test performance might have a hypothesis that states: "This study is designed to assess the hypothesis that sleep-deprived people will perform worse on a test than individuals who are not sleep-deprived."
This article explores how a hypothesis is used in psychology research, how to write a good hypothesis, and the different types of hypotheses you might use.
The Hypothesis in the Scientific Method
In the scientific method , whether it involves research in psychology, biology, or some other area, a hypothesis represents what the researchers think will happen in an experiment. The scientific method involves the following steps:
- Forming a question
- Performing background research
- Creating a hypothesis
- Designing an experiment
- Collecting data
- Analyzing the results
- Drawing conclusions
- Communicating the results
The hypothesis is a prediction, but it involves more than a guess. Most of the time, the hypothesis begins with a question which is then explored through background research. It is only at this point that researchers begin to develop a testable hypothesis. Unless you are creating an exploratory study, your hypothesis should always explain what you expect to happen.
In a study exploring the effects of a particular drug, the hypothesis might be that researchers expect the drug to have some type of effect on the symptoms of a specific illness. In psychology, the hypothesis might focus on how a certain aspect of the environment might influence a particular behavior.
Remember, a hypothesis does not have to be correct. While the hypothesis predicts what the researchers expect to see, the goal of the research is to determine whether this guess is right or wrong. When conducting an experiment, researchers might explore a number of factors to determine which ones might contribute to the ultimate outcome.
In many cases, researchers may find that the results of an experiment do not support the original hypothesis. When writing up these results, the researchers might suggest other options that should be explored in future studies.
In many cases, researchers might draw a hypothesis from a specific theory or build on previous research. For example, prior research has shown that stress can impact the immune system. So a researcher might hypothesize: "People with high-stress levels will be more likely to contract a common cold after being exposed to the virus than people who have low-stress levels."
In other instances, researchers might look at commonly held beliefs or folk wisdom. "Birds of a feather flock together" is one example of folk wisdom that a psychologist might try to investigate. The researcher might pose a specific hypothesis that "People tend to select romantic partners who are similar to them in interests and educational level."
Elements of a Good Hypothesis
So how do you write a good hypothesis? When trying to come up with a hypothesis for your research or experiments, ask yourself the following questions:
- Is your hypothesis based on your research on a topic?
- Can your hypothesis be tested?
- Does your hypothesis include independent and dependent variables?
Before you come up with a specific hypothesis, spend some time doing background research. Once you have completed a literature review, start thinking about potential questions you still have. Pay attention to the discussion section in the journal articles you read . Many authors will suggest questions that still need to be explored.
To form a hypothesis, you should take these steps:
- Collect as many observations about a topic or problem as you can.
- Evaluate these observations and look for possible causes of the problem.
- Create a list of possible explanations that you might want to explore.
- After you have developed some possible hypotheses, think of ways that you could confirm or disprove each hypothesis through experimentation. This is known as falsifiability.
In the scientific method , falsifiability is an important part of any valid hypothesis. In order to test a claim scientifically, it must be possible that the claim could be proven false.
Students sometimes confuse the idea of falsifiability with the idea that it means that something is false, which is not the case. What falsifiability means is that if something was false, then it is possible to demonstrate that it is false.
One of the hallmarks of pseudoscience is that it makes claims that cannot be refuted or proven false.
A variable is a factor or element that can be changed and manipulated in ways that are observable and measurable. However, the researcher must also define how the variable will be manipulated and measured in the study.
For example, a researcher might operationally define the variable " test anxiety " as the results of a self-report measure of anxiety experienced during an exam. A "study habits" variable might be defined by the amount of studying that actually occurs as measured by time.
These precise descriptions are important because many things can be measured in a number of different ways. One of the basic principles of any type of scientific research is that the results must be replicable. By clearly detailing the specifics of how the variables were measured and manipulated, other researchers can better understand the results and repeat the study if needed.
Some variables are more difficult than others to define. How would you operationally define a variable such as aggression ? For obvious ethical reasons, researchers cannot create a situation in which a person behaves aggressively toward others.
In order to measure this variable, the researcher must devise a measurement that assesses aggressive behavior without harming other people. In this situation, the researcher might utilize a simulated task to measure aggressiveness.
Hypothesis Checklist
- Does your hypothesis focus on something that you can actually test?
- Does your hypothesis include both an independent and dependent variable?
- Can you manipulate the variables?
- Can your hypothesis be tested without violating ethical standards?
The hypothesis you use will depend on what you are investigating and hoping to find. Some of the main types of hypotheses that you might use include:
- Simple hypothesis : This type of hypothesis suggests that there is a relationship between one independent variable and one dependent variable.
- Complex hypothesis : This type of hypothesis suggests a relationship between three or more variables, such as two independent variables and a dependent variable.
- Null hypothesis : This hypothesis suggests no relationship exists between two or more variables.
- Alternative hypothesis : This hypothesis states the opposite of the null hypothesis.
- Statistical hypothesis : This hypothesis uses statistical analysis to evaluate a representative sample of the population and then generalizes the findings to the larger group.
- Logical hypothesis : This hypothesis assumes a relationship between variables without collecting data or evidence.
A hypothesis often follows a basic format of "If {this happens} then {this will happen}." One way to structure your hypothesis is to describe what will happen to the dependent variable if you change the independent variable .
The basic format might be: "If {these changes are made to a certain independent variable}, then we will observe {a change in a specific dependent variable}."
A few examples of simple hypotheses:
- "Students who eat breakfast will perform better on a math exam than students who do not eat breakfast."
- Complex hypothesis: "Students who experience test anxiety before an English exam will get lower scores than students who do not experience test anxiety."
- "Motorists who talk on the phone while driving will be more likely to make errors on a driving course than those who do not talk on the phone."
Examples of a complex hypothesis include:
- "People with high-sugar diets and sedentary activity levels are more likely to develop depression."
- "Younger people who are regularly exposed to green, outdoor areas have better subjective well-being than older adults who have limited exposure to green spaces."
Examples of a null hypothesis include:
- "Children who receive a new reading intervention will have scores different than students who do not receive the intervention."
- "There will be no difference in scores on a memory recall task between children and adults."
Examples of an alternative hypothesis:
- "Children who receive a new reading intervention will perform better than students who did not receive the intervention."
- "Adults will perform better on a memory task than children."
Collecting Data on Your Hypothesis
Once a researcher has formed a testable hypothesis, the next step is to select a research design and start collecting data. The research method depends largely on exactly what they are studying. There are two basic types of research methods: descriptive research and experimental research.
Descriptive Research Methods
Descriptive research such as case studies , naturalistic observations , and surveys are often used when it would be impossible or difficult to conduct an experiment . These methods are best used to describe different aspects of a behavior or psychological phenomenon.
Once a researcher has collected data using descriptive methods, a correlational study can then be used to look at how the variables are related. This type of research method might be used to investigate a hypothesis that is difficult to test experimentally.
Experimental Research Methods
Experimental methods are used to demonstrate causal relationships between variables. In an experiment, the researcher systematically manipulates a variable of interest (known as the independent variable) and measures the effect on another variable (known as the dependent variable).
Unlike correlational studies, which can only be used to determine if there is a relationship between two variables, experimental methods can be used to determine the actual nature of the relationship—whether changes in one variable actually cause another to change.
A Word From Verywell
The hypothesis is a critical part of any scientific exploration. It represents what researchers expect to find in a study or experiment. In situations where the hypothesis is unsupported by the research, the research still has value. Such research helps us better understand how different aspects of the natural world relate to one another. It also helps us develop new hypotheses that can then be tested in the future.
Some examples of how to write a hypothesis include:
- "Staying up late will lead to worse test performance the next day."
- "People who consume one apple each day will visit the doctor fewer times each year."
- "Breaking study sessions up into three 20-minute sessions will lead to better test results than a single 60-minute study session."
The four parts of a hypothesis are:
- The research question
- The independent variable (IV)
- The dependent variable (DV)
- The proposed relationship between the IV and DV
Castillo M. The scientific method: a need for something better? . AJNR Am J Neuroradiol. 2013;34(9):1669-71. doi:10.3174/ajnr.A3401
Nevid J. Psychology: Concepts and Applications. Wadworth, 2013.
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
7.5: Full Hypothesis Test Examples
- Last updated
- Save as PDF
- Page ID 79055
Tests on Means
Example \(\PageIndex{1}\)
Jeffrey, as an eight-year old, established a mean time of 16.43 seconds for swimming the 25-yard freestyle.
His dad, Frank, thought that Jeffrey could swim the 25-yard freestyle faster using goggles. Frank bought Jeffrey a new pair of expensive goggles and timed Jeffrey for 15 25-yard freestyle swims . For the 15 swims, Jeffrey's mean time was 16 seconds , with a standard deviation of 0.8 seconds . Frank thought that the goggles helped Jeffrey to swim faster than the 16.43 seconds. Conduct a hypothesis test using test statistics and \(p\)-values with a preset \(\alpha = 0.05\).
Set up the Hypothesis Test:
Since the problem is about a mean, this is a test of a single population mean .
Set the null and alternative hypothesis:
In this case there is an implied challenge or claim. This is that the goggles will reduce the swimming time. The effect of this is to set the hypothesis as a one-tailed test. The claim will always be in the alternative hypothesis because the burden of proof always lies with the alternative. Remember that the status quo must be defeated with a high degree of confidence, in this case 95% confidence. The null and alternative hypotheses are thus:
\(H_0: \mu \geq 16.43\) \(H_a: \mu < 16.43\)
For Jeffrey to swim faster, his time should be less than 16.43 seconds. The "<" tells you this is left-tailed.
Determine the distribution needed:
Random variable: \(\overline x\) = the mean time to swim the 25-yard freestyle.
Distribution for the test statistic:
The sample size is less than 30 and we do not know the population standard deviation so this is a t -test. The proper formula is: \(t_{obs}=\frac{\overline{x}-\mu_{0}}{s / \sqrt{n}}\)
\(\mu_ 0 = 16.43\) comes from \(H_0\) and not the data. \(\overline x = 16\), \(s = 0.8\), and \(n = 15\).
Our step 2, setting the level of confidence, has already been determined by the problem, \(\alpha\) of .05 corresponds to a 95% confidence level. It is worth thinking about the meaning of this choice. The Type I error is to conclude that Jeffrey swims the 25-yard freestyle, on average, in less than 16.43 seconds when, in fact, he actually swims the 25-yard freestyle, on average, in 16.43 seconds or more. (Reject the null hypothesis when the null hypothesis is true.) For this case the only concern with a Type I error would seem to be that Jeffrey’s dad may fail to bet on his son’s victory because he does not have appropriate confidence in the effect of the goggles.
To find the critical value we need to select the appropriate test statistic. We have concluded that this is a t -test on the basis of the sample size and that we are interested in a population mean. We can now draw the graph of the t -distribution and mark the critical value. For this problem the degrees of freedom are n-1, or 14. Looking up 14 degrees of freedom at the 0.05 column of the t -table we find 1.761. This is the critical value and we can put this on our graph.
Step 3 is the calculation of the test statistic using the formula we have selected. We find that the observed test statistic is -2.08, meaning that the sample mean is 2.08 standard errors below the hypothesized mean of 16.43.
\[t_{obs}=\frac{\overline{x}-\mu_{0}}{s / \sqrt{n}}=\frac{16-16.43}{.8 / \sqrt{15}}=-2.08\nonumber\]
Figure \(\PageIndex{1}\)
Step 4 has us compare the test statistic and the critical value and mark these on the graph. We see that the test statistic is in the tail and thus we move to step 4 and reach a conclusion. The probability that an average time of 16 minutes could come from a distribution with a population mean of 16.43 minutes is too unlikely to have occurred under the null hypothesis. We reject the null.
Step 5 has us state our conclusions first formally and then less formally. A formal conclusion would be stated as: “With a 95% level of confidence we reject the null hypothesis that the swimming time with goggles comes from a distribution with a population mean time of 16.43 minutes.” Less formally, “With 95% confidence, we believe that the goggles improved swimming speed".
If we wished to use the \(p\)-value system of reaching a conclusion we would calculate the statistic and take the additional step to find the probability of being 2.08 standard errors from the mean on a t -distribution. The \(p\)-value interval is (.025, .05), that we get by looking up the one-tailed probabilities associated with the closest t -scores (1.761 and 2.145) to the observed test statistic (-2.08) in the relevant df row of 14 in the t -table. Comparing this interval to the significance level of .05 we see that we reject the null. The \(p\)-value has been put on the graph as the shaded area beyond -2.08 and it shows that it is smaller than the hatched area which is the \(\alpha\) level of 0.05. Both methods reach the same conclusion that we reject the null hypothesis.
Exercise \(\PageIndex{1}\)
The mean throwing distance of a football for Marco, a high school freshman quarterback, is 40 yards, with a standard deviation of two yards. The team coach tells Marco to adjust his grip to get more distance. The coach records the distances for 20 throws. For the 20 throws, Marco’s mean distance was 45 yards. The coach thought the different grip helped Marco throw farther than 40 yards. Conduct a hypothesis test using a preset \(\alpha = 0.05\). Assume the throw distances for footballs are normal.
First, determine what type of test this is, set up the hypothesis test, find the \(p\)-value, sketch the graph, and state your conclusion.
Example \(\PageIndex{2}\)
Jane has just begun her new job as on the sales force of a very competitive company. In a sample of 16 sales calls it was found that she closed the contract for an average value of 108 dollars with a standard deviation of 12 dollars. Company policy requires that new members of the sales force must exceed an average of $100 per contract during the trial employment period. Can we conclude that Jane has met this requirement at the significance level of 5%?
- \(H_0: \mu \leq 100\) \(H_a: \mu > 100\) The null and alternative hypothesis are for the parameter \(\mu\) because the number of dollars of the contracts is a continuous random variable. Also, this is a one-tailed test because the company has only an interested if the number of dollars per contact is below a particular number not "too high" a number. This can be thought of as making a claim that the requirement is being met and thus the claim is in the alternative hypothesis.
- Test statistic: \(t_{obs}=\frac{\overline{x}-\mu_{0}}{\frac{s}{\sqrt{n}}}=\frac{108-100}{\left(\frac{12}{\sqrt{16}}\right)}=2.67\)
- Critical value: \(t_\alpha=1.753\) with \(n-1\) degrees of freedom = 15
The test statistic is a Student's t because the sample size is below 100; therefore, we cannot use the normal distribution. Comparing the observed value of the test statistic and the critical value of t at a 5% significance level, we see that the observed value is in the tail of the distribution. Thus, we conclude that 108 dollars per contract is significantly larger than the hypothesized value of 100 and thus we must reject the null hypothesis. There is evidence that Jane's performance meets company standards.
Figure \(\PageIndex{2}\)
Exercise \(\PageIndex{2}\)
It is believed that a stock price for a particular company will grow at a rate of $5 per week with a standard deviation of $1. An investor believes the stock won’t grow as quickly. The changes in stock price is recorded for ten weeks and are as follows: $4, $3, $2, $3, $1, $7, $2, $1, $1, $2. Perform a hypothesis test using a 5% level of significance. State the null and alternative hypotheses, state your conclusion, and identify the Type I and Type II errors.
Example \(\PageIndex{3}\)
A manufacturer of salad dressings uses machines to dispense liquid ingredients into bottles that move along a filling line. The machine that dispenses salad dressings is working properly when 8 ounces are dispensed. Suppose that the average amount dispensed in a particular sample of 35 bottles is 7.91 ounces with a variance of 0.03 ounces squared, \(s^2\). Is there evidence that the machine should be stopped and production wait for repairs? The lost production from a shutdown is potentially so great that management feels that the level of confidence in the analysis should be 99%.
Again we will follow the steps in our analysis of this problem.
STEP 1 : Set the null and alternative hypothesis.
The random variable is the quantity of fluid placed in the bottles. This is a continuous random variable and the parameter we are interested in is the mean. Our hypothesis therefore is about the mean. In this case we are concerned that the machine is not filling properly. From what we are told it does not matter if the machine is over-filling or under-filling, both seem to be an equally bad error. This tells us that this is a two-tailed test: if the machine is malfunctioning it will be shutdown regardless if it is from over-filling or under-filling. The null and alternative hypotheses are thus:
\[H_0:\mu=8\nonumber\]
\[Ha:\mu \neq 8\nonumber\]
STEP 2 : Decide the level of significance and draw the graph showing the critical value.
This problem has already set the level of confidence at 99%. The decision seems an appropriate one and shows the thought process when setting the significance level. Management wants to be very certain, as certain as probability will allow, that they are not shutting down a machine that is not in need of repair. To draw the distribution and the critical value, we need to know which distribution to use. Because the sample size is under 100, the appropriate distribution is the t -distribution and the relevant critical value is 2.750 from the t -table at 0.005 column and 30 degrees of freedom (closest available row to our actual 34 df here). We need to draw the graph and mark these points.
STEP 3 : Calculate sample parameters and the test statistic.
The sample parameters are provided, the sample mean is 7.91 and the sample variance is .03 and the sample size is 35. We need to note that the sample variance was provided, not the sample standard deviation, which is what we need for the formula. Remembering that the standard deviation is simply the square root of the variance, we therefore know the sample standard deviation, \(s\), is 0.173. With this information we can calculate the test statistic as -3.07, and mark it on the graph.
\[t_{obs}=\frac{\overline{x}-\mu_{0}}{s / \sqrt{n}}=\frac{7.91-8}{\cdot 173 / \sqrt{35}}=-3.07\nonumber\]
STEP 4 : Compare test statistic and the critical values.
Now we compare the test statistic and the critical value by placing the test statistic on the graph. The test statistic is in the tail, decidedly greater than the critical value of 2.750. We note that even the very small difference between the hypothesized value and the sample value is still a large number of standard errors. The sample mean is only 0.08 ounces different from the required level of 8 ounces, but it is 3+ standard errors away from the required 8 ounces, and thus we reject the null hypothesis.
STEP 5 : Reach a conclusion.
Three standard errors of a test statistic will guarantee that the test will fail. The probability that anything is beyond three standard errors of a hypothesized null value - given a large enough sample size - is close to zero. Looking at the closest t -scores in df =30 row in the t -table, we get the \(p\)-value interval of (.01, .002) after doubling the one-tailed probabilities of .005 and .001. Our formal conclusion would be “At a 99% level of confidence, we reject the null hypothesis that the sample mean came from a distribution with a mean of 8 ounces”. Or less formally, and getting to the point, “At a 99% level of confidence, we conclude that the machine is under-filling the bottles and is in need of repair”.
Hypothesis Test for Proportions
Just as there were confidence intervals for proportions, or more formally, the population parameter \(P\), there is the ability to test hypotheses concerning \(P\).
The estimated value (point estimate) for \(P\) is \(P^{\prime}\) where \(P^{\prime} = x/n\), \(x\) is the number of observations in the category of interest in the sample and \(n\) is the sample size.
When you perform a hypothesis test of a population proportion \(P\), you take a random sample from the population. To ensure normality of the distribution, sampling must be random and the total sample size must be greater than 100. There is no distribution that can correct for this small sample bias and thus if these conditions are not met we simply cannot test the hypothesis with the data available at that time. We met this condition when we were first estimating confidence intervals for \(P\).
Again, we begin with the modified standardizing formula:
\[z=\frac{P^{\prime}-P}{\sqrt{\frac{P(1-P)}{n}}}\nonumber\]
Substituting \(P_0\), the hypothesized value of \(P\), we have:
\[z_{obs}=\frac{P^{\prime}-P_{0}}{\sqrt{\frac{P_{0} (1-P_{0})}{n}}}\nonumber\]
This is the test statistic for testing hypothesized values of \(P\), where the null and alternative hypotheses take one of the following forms:
Table \(\PageIndex{1}\)
The decision rule stated above applies here also: if the calculated value of \(z_{obs}\) shows that the sample proportion is "too many" standard errors from the hypothesized proportion, the null hypothesis is rejected. The decision as to what is "too many" is pre-determined by the analyst depending on the level of significance required in the test.
Example \(\PageIndex{4}\)
The mortgage department of a large bank is interested in the nature of loans of first-time borrowers. This information will be used to tailor their marketing strategy. They believe that 50% of first-time borrowers take out smaller loans than other borrowers. They perform a hypothesis test to determine if the percentage is different from 50% . They sample 101 first-time borrowers and find 54 of these loans are smaller that the other borrowers. For the hypothesis test, they choose a 5% level of significance.
\(H_0: P = 0.50\) \(H_a: P \neq 0.50\)
The words "is different from" tell you this is a two-tailed test. The Type I and Type II errors are as follows: The Type I error is to conclude that the proportion of borrowers is different from 50% when, in fact, the proportion is actually 50%. (Reject the null hypothesis when the null hypothesis is true). The Type II error is there is not enough evidence to conclude that the proportion of first time borrowers differs from 50% when, in fact, the proportion does differ from 50%. (You fail to reject the null hypothesis when the null hypothesis is false.)
STEP 2 : Decide the level of significance and draw the graph showing the critical value
The level of confidence has been set by the problem at 95%. Because this is two-tailed test one-half of the \(\alpha\) value will be in the upper tail and one-half in the lower tail as shown on the graph. The critical value for the normal distribution at the 95% level of confidence is 1.96. This can easily be found on the Student’s t -table at the very bottom at infinite degrees of freedom remembering that at infinity the t -distribution is the normal distribution. Of course, the value can also be found on the standard normal table but you have go looking for the tail probability, \(\alpha\)/2, inside the body of the table and then read out to the sides and top for the number of standard errors.
Figure \(\PageIndex{3}\)
STEP 3 : Calculate the sample parameters and critical value of the test statistic.
The test statistic is a normal distribution, \(z\), for testing proportions and is:
\[z=\frac{P^{\prime}-P_{0}}{\sqrt{\frac{P_{0} (1-P_{0})}{n}}}=\frac{.53-.50}{\sqrt{\frac{.5(.5)}{101}}}=0.60\nonumber\]
For this case, the sample of 101 found 54 first-time borrowers were different from other borrowers. The sample proportion, \(P^{\prime} = 54/101= 0.53\) The test question, therefore, is : “Is 0.53 significantly different from 0.50?” Putting these values into the formula for the test statistic we find that 0.53 is only 0.60 standard errors away from 0.50. This is barely off of the mean of the standard normal distribution of zero. There is virtually no difference from the sample proportion and the hypothesized proportion in terms of standard errors.
STEP 4 : Compare the test statistic and the critical value.
The observed value is well within the critical values of \(\pm 1.96\) standard errors and thus we cannot reject the null hypothesis. To reject the null hypothesis we need significant evidence of difference between the hypothesized value and the sample value. In this case the sample value is very nearly the same as the hypothesized value measured in terms of standard errors.
The formal conclusion would be “At a 95% level of confidence we cannot reject the null hypothesis that 50% of first-time borrowers have the same size loans as other borrowers”. Less formally, we would say that “There is no evidence that one-half of first-time borrowers are significantly different in loan size from other borrowers”. Notice the length to which the conclusion goes to include all of the conditions that are attached to the conclusion. Statisticians, for all the criticism they receive, are careful to be very specific even when this seems trivial. Statisticians cannot say more than they know and the data constrain the conclusion to be within the metes and bounds of the data.
Exercise \(\PageIndex{3}\)
A teacher believes that 85% of students in the class will want to go on a field trip to the local zoo. She performs a hypothesis test to determine if the percentage is the same or different from 85%. The teacher samples 104 students and 89 reply that they would want to go to the zoo. For the hypothesis test, use a 1% level of significance.
Example \(\PageIndex{5}\)
Suppose a consumer group suspects that the proportion of households that have three or more cell phones is 30%. A cell phone company has reason to believe that the proportion is not 30%. Before they start a big advertising campaign, they conduct a hypothesis test using 90% confidence. Their marketing people survey 150 households with the result that 43 of the households have three or more cell phones.
Here is an abbreviated version of the system to solve hypothesis tests applied to a test on a proportions.
\[H_0 : P = 0.3 \nonumber\]
\[H_a : P \neq 0.3 \nonumber\]
\[n = 150\nonumber\]
\[P^{\prime}=\frac{x}{n}=\frac{43}{150}=0.287\nonumber\]
\[z_{obs}=\frac{P^{\prime}-P_{0}}{\sqrt{\frac{P_{0} (1-P_{0})}{n}}}=\frac{0.287-0.3}{\sqrt{\frac{.3(.7)}{150}}}=0.347\nonumber\]
At a confidence level of 90% we cannot reject the null hypothesis that the consumer group is correct.

Figure \(\PageIndex{4}\)
Example \(\PageIndex{6}\)
In a study of 420,019 cell phone users, 172 of the subjects developed brain cancer. Test the claim that cell phone users developed brain cancer at a greater rate than that for non-cell phone users (the rate of brain cancer for non-cell phone users is 0.0340%). Since this is a critical issue, use a 0.005 significance level. Explain why the significance level should be so low in terms of a Type I error.
We need to conduct a hypothesis test on the claimed cancer rate. Our hypotheses will be:
If we commit a Type I error, we are essentially accepting an incorrect claim. Since the claim describes cancer-causing environments, we want to minimize the chances of incorrectly identifying causes of cancer.
How to Use hypothesis in a Sentence
- The results of the experiment did not support his hypothesis .
- Their hypothesis is that watching excessive amounts of television reduces a person's ability to concentrate.
Some of these examples are programmatically compiled from various online sources to illustrate current usage of the word 'hypothesis.' Any opinions expressed in the examples do not represent those of Merriam-Webster or its editors. Send us feedback about these examples.

Can you solve 4 words at once?
Word of the day, braggadocio.
See Definitions and Examples »
Get Word of the Day daily email!
IMAGES
VIDEO
COMMENTS
Following the hypothesis structure: "A new CTA on my page will increase [conversion goal]". The first test implied a problem with clarity, provides a potential theme: "Improving the clarity of the page will reduce confusion and improve [conversion goal].". The potential clarity theme leads to a new hypothesis: "Changing the wording of ...
You may want to come up with both a problem statement and a hypothesis. For example: Problem Statement: "The lead generation form is too long, causing unnecessary friction.". Hypothesis: "By changing the amount of form fields from 20 to 10, we will increase number of leads.".
A hypothesis or hypothesis statement seeks to explain why something has happened, or what might happen, under certain conditions. It can also be used to understand how different variables relate to each other. Hypotheses are often written as if-then statements; for example, "If this happens, then this will happen.".
A common way to create a hypothesis for a marketing campaign is to use the following formula: If [variable], then [outcome], because [reason]. The variable is the element of your campaign that you ...
Make a hypothesis. Collect research. Select your metrics. Execute the experiment. Analyze the results. Performing a marketing experiment involves doing research, structuring the experiment, and analyzing the results. Let's go through the seven steps necessary to conduct a marketing experiment. 1.
Developing a hypothesis is an essential part of marketing experimentation. Qualitative-based research should inform hypotheses that you test with real-world behavior. The hypotheses help you discover how accurate those insights from qualitative research are. If you engage in hypothesis-driven testing, then you ensure your tests are strategic ...
In this A/B test example, the team ran a 6-week test with the control against an updated landing page with testimonials. Results. This change netted a 13% increase in sales. The control page had a 2.2% conversion rate, but the new variant showed a 2.75% conversion rate. Email A/B Testing Examples 5. HubSpot's Email Subscriber Experience
The Basics: Marketing Experimentation Hypothesis. A hypothesis is a research-based statement that aims to explain an observed trend and create a solution that will improve the result. This statement is an educated, testable prediction about what will happen. It has to be stated in declarative form and not as a question.
By transforming marketing ideas into hypotheses, we orient our test to learn about our customer rather than merely trying out an idea. Here is a 4-step framework for creating a hypothesis, along with good and bad examples.
For example, we can observe the actual behaviour of a sample comprising two groups post-marketing exposure. The hypothesis testing process involves assuming a neutral H0 and seeking evidence in ...
Developing a hypothesis (with example) Step 1. Ask a question. Writing a hypothesis begins with a research question that you want to answer. The question should be focused, specific, and researchable within the constraints of your project. Example: Research question.
Hint: it's the same as the other hypothesis examples we've described so far. Example: If we change the landing page copy, then the number of signups will increase. Null hypothesis: ... Copy that we paid a marketing agency 10 grand for; Generic copy we wrote ourselves, or removing most of the original copy - just to see how making even a ...
Here are the calculated results. As we stated earlier, one-tailed p-values are just a two-tailed p-value divide by two. Step 4: Draw a conclusion. At this point, I hope you still remember your ...
2. Make a good hypothesis. Making a hypothesis before conducting marketing experiments is crucial because it provides a clear direction for the experiment and helps in setting specific goals to be achieved. A hypothesis allows marketers to articulate their assumptions about the expected outcomes of various changes or strategies they plan to ...
This can be formally expressed as follows: ˉx − μ0 = zσˉx. In this equation, z will tell us how many standard deviations the sample mean ˉx¯x is away from the null hypothesis μ0μ0. Solving for z gives us: z = ˉx − μ0 σˉx = ˉx − μ0 σ / √n. This standardized value (or "z-score") is also referred to as a test statistic.
Hypothesis. The first step in any marketing research experiment is to develop a hypothesis. ... For example, a marketing manager may design an experiment involving participants going to a store ...
For example, a hypothesis might be formulated to test the effects of a new marketing campaign on consumer buying behavior. Engineering: In engineering, hypotheses are used to test the effectiveness of new technologies or designs. For example, a hypothesis might be formulated to test the efficiency of a new solar panel design. How to write a ...
The first step in being hypothesis-driven is to focus on the highest potential ideas and theories of how to solve a problem or realize an opportunity. Let's go over an example of being hypothesis-driven. Let's say you own a website, and you brainstorm ten ideas to improve web traffic, but you don't have the budget to execute all ten ideas.
Simple hypothesis. A simple hypothesis is a statement made to reflect the relation between exactly two variables. One independent and one dependent. Consider the example, "Smoking is a prominent cause of lung cancer." The dependent variable, lung cancer, is dependent on the independent variable, smoking. 4.
Example 9.8. Problem. Jeffrey, as an eight-year old, established a mean time of 16.43 seconds for swimming the 25-yard freestyle, with a standard deviation of 0.8 seconds. His dad, Frank, thought that Jeffrey could swim the 25-yard freestyle faster using goggles. Frank bought Jeffrey a new pair of expensive goggles and timed Jeffrey for 15 25 ...
Examples of a complex hypothesis include: "People with high-sugar diets and sedentary activity levels are more likely to develop depression." "Younger people who are regularly exposed to green, outdoor areas have better subjective well-being than older adults who have limited exposure to green spaces."
First, determine what type of test this is, set up the hypothesis test, find the p p -value, sketch the graph, and state your conclusion. Example 7.5.2 7.5. 2. Jane has just begun her new job as on the sales force of a very competitive company.
hypothesis. noun. Definition of hypothesis. Synonyms for hypothesis. The results of the experiment did not support his hypothesis. Their hypothesis is that watching excessive amounts of television reduces a person's ability to concentrate. The coming days and weeks will put that hypothesis to the test. —.