A Guide To The Methods, Benefits & Problems of The Interpretation of Data

Table of Contents
1) What Is Data Interpretation?
2) How To Interpret Data?
3) Why Data Interpretation Is Important?
4) Data Interpretation Skills
5) Data Analysis & Interpretation Problems
6) Data Interpretation Techniques & Methods
7) The Use of Dashboards For Data Interpretation
8) Business Data Interpretation Examples
Data analysis and interpretation have now taken center stage with the advent of the digital age… and the sheer amount of data can be frightening. In fact, a Digital Universe study found that the total data supply in 2012 was 2.8 trillion gigabytes! Based on that amount of data alone, it is clear the calling card of any successful enterprise in today’s global world will be the ability to analyze complex data, produce actionable insights, and adapt to new market needs… all at the speed of thought.
Business dashboards are the digital age tools for big data. Capable of displaying key performance indicators (KPIs) for both quantitative and qualitative data analyses, they are ideal for making the fast-paced and data-driven market decisions that push today’s industry leaders to sustainable success. Through the art of streamlined visual communication, data dashboards permit businesses to engage in real-time and informed decision-making and are key instruments in data interpretation. First of all, let’s find a definition to understand what lies behind this practice.

What Is Data Interpretation?
Data interpretation refers to the process of using diverse analytical methods to review data and arrive at relevant conclusions. The interpretation of data helps researchers to categorize, manipulate, and summarize the information in order to answer critical questions.
The importance of data interpretation is evident, and this is why it needs to be done properly. Data is very likely to arrive from multiple sources and has a tendency to enter the analysis process with haphazard ordering. Data analysis tends to be extremely subjective. That is to say, the nature and goal of interpretation will vary from business to business, likely correlating to the type of data being analyzed. While there are several types of processes that are implemented based on the nature of individual data, the two broadest and most common categories are “quantitative and qualitative analysis.”
Yet, before any serious data interpretation inquiry can begin, it should be understood that visual presentations of data findings are irrelevant unless a sound decision is made regarding measurement scales. Before any serious data analysis can begin, the measurement scale must be decided for the data as this will have a long-term impact on data interpretation ROI. The varying scales include:
- Nominal Scale: non-numeric categories that cannot be ranked or compared quantitatively. Variables are exclusive and exhaustive.
- Ordinal Scale: exclusive categories that are exclusive and exhaustive but with a logical order. Quality ratings and agreement ratings are examples of ordinal scales (i.e., good, very good, fair, etc., OR agree, strongly agree, disagree, etc.).
- Interval: a measurement scale where data is grouped into categories with orderly and equal distances between the categories. There is always an arbitrary zero point.
- Ratio: contains features of all three.
For a more in-depth review of scales of measurement, read our article on data analysis questions . Once measurement scales have been selected, it is time to select which of the two broad interpretation processes will best suit your data needs. Let’s take a closer look at those specific methods and possible data interpretation problems.
How To Interpret Data? Top Methods & Techniques

When interpreting data, an analyst must try to discern the differences between correlation, causation, and coincidences, as well as many other biases – but he also has to consider all the factors involved that may have led to a result. There are various data interpretation types and methods one can use to achieve this.
The interpretation of data is designed to help people make sense of numerical data that has been collected, analyzed, and presented. Having a baseline method for interpreting data will provide your analyst teams with a structure and consistent foundation. Indeed, if several departments have different approaches to interpreting the same data while sharing the same goals, some mismatched objectives can result. Disparate methods will lead to duplicated efforts, inconsistent solutions, wasted energy, and inevitably – time and money. In this part, we will look at the two main methods of interpretation of data: qualitative and quantitative analysis.
Qualitative Data Interpretation
Qualitative data analysis can be summed up in one word – categorical. With this type of analysis, data is not described through numerical values or patterns but through the use of descriptive context (i.e., text). Typically, narrative data is gathered by employing a wide variety of person-to-person techniques. These techniques include:
- Observations: detailing behavioral patterns that occur within an observation group. These patterns could be the amount of time spent in an activity, the type of activity, and the method of communication employed.
- Focus groups: Group people and ask them relevant questions to generate a collaborative discussion about a research topic.
- Secondary Research: much like how patterns of behavior can be observed, various types of documentation resources can be coded and divided based on the type of material they contain.
- Interviews: one of the best collection methods for narrative data. Inquiry responses can be grouped by theme, topic, or category. The interview approach allows for highly focused data segmentation.
A key difference between qualitative and quantitative analysis is clearly noticeable in the interpretation stage. The first one is widely open to interpretation and must be “coded” so as to facilitate the grouping and labeling of data into identifiable themes. As person-to-person data collection techniques can often result in disputes pertaining to proper analysis, qualitative data analysis is often summarized through three basic principles: notice things, collect things, and think about things.
After qualitative data has been collected through transcripts, questionnaires, audio and video recordings, or the researcher’s notes, it is time to interpret it. For that purpose, there are some common methods used by researchers and analysts.
- Content analysis : As its name suggests, this is a research method used to identify frequencies and recurring words, subjects, and concepts in image, video, or audio content. It transforms qualitative information into quantitative data to help discover trends and conclusions that will later support important research or business decisions. This method is often used by marketers to understand brand sentiment from the mouths of customers themselves. Through that, they can extract valuable information to improve their products and services. It is recommended to use content analytics tools for this method as manually performing it is very time-consuming and can lead to human error or subjectivity issues. Having a clear goal in mind before diving into it is another great practice for avoiding getting lost in the fog.
- Thematic analysis: This method focuses on analyzing qualitative data, such as interview transcripts, survey questions, and others, to identify common patterns and separate the data into different groups according to found similarities or themes. For example, imagine you want to analyze what customers think about your restaurant. For this purpose, you do a thematic analysis on 1000 reviews and find common themes such as “fresh food”, “cold food”, “small portions”, “friendly staff”, etc. With those recurring themes in hand, you can extract conclusions about what could be improved or enhanced based on your customer’s experiences. Since this technique is more exploratory, be open to changing your research questions or goals as you go.
- Narrative analysis: A bit more specific and complicated than the two previous methods, it is used to analyze stories and discover their meaning. These stories can be extracted from testimonials, case studies, and interviews, as these formats give people more space to tell their experiences. Given that collecting this kind of data is harder and more time-consuming, sample sizes for narrative analysis are usually smaller, which makes it harder to reproduce its findings. However, it is still a valuable technique for understanding customers' preferences and mindsets.
- Discourse analysis : This method is used to draw the meaning of any type of visual, written, or symbolic language in relation to a social, political, cultural, or historical context. It is used to understand how context can affect how language is carried out and understood. For example, if you are doing research on power dynamics, using discourse analysis to analyze a conversation between a janitor and a CEO and draw conclusions about their responses based on the context and your research questions is a great use case for this technique. That said, like all methods in this section, discourse analytics is time-consuming as the data needs to be analyzed until no new insights emerge.
- Grounded theory analysis : The grounded theory approach aims to create or discover a new theory by carefully testing and evaluating the data available. Unlike all other qualitative approaches on this list, grounded theory helps extract conclusions and hypotheses from the data instead of going into the analysis with a defined hypothesis. This method is very popular amongst researchers, analysts, and marketers as the results are completely data-backed, providing a factual explanation of any scenario. It is often used when researching a completely new topic or with little knowledge as this space to start from the ground up.
Quantitative Data Interpretation
If quantitative data interpretation could be summed up in one word (and it really can’t), that word would be “numerical.” There are few certainties when it comes to data analysis, but you can be sure that if the research you are engaging in has no numbers involved, it is not quantitative research, as this analysis refers to a set of processes by which numerical data is analyzed. More often than not, it involves the use of statistical modeling such as standard deviation, mean, and median. Let’s quickly review the most common statistical terms:
- Mean: A mean represents a numerical average for a set of responses. When dealing with a data set (or multiple data sets), a mean will represent the central value of a specific set of numbers. It is the sum of the values divided by the number of values within the data set. Other terms that can be used to describe the concept are arithmetic mean, average, and mathematical expectation.
- Standard deviation: This is another statistical term commonly used in quantitative analysis. Standard deviation reveals the distribution of the responses around the mean. It describes the degree of consistency within the responses; together with the mean, it provides insight into data sets.
- Frequency distribution: This is a measurement gauging the rate of a response appearance within a data set. When using a survey, for example, frequency distribution, it can determine the number of times a specific ordinal scale response appears (i.e., agree, strongly agree, disagree, etc.). Frequency distribution is extremely keen in determining the degree of consensus among data points.
Typically, quantitative data is measured by visually presenting correlation tests between two or more variables of significance. Different processes can be used together or separately, and comparisons can be made to ultimately arrive at a conclusion. Other signature interpretation processes of quantitative data include:
- Regression analysis: Essentially, it uses historical data to understand the relationship between a dependent variable and one or more independent variables. Knowing which variables are related and how they developed in the past allows you to anticipate possible outcomes and make better decisions going forward. For example, if you want to predict your sales for next month, you can use regression to understand what factors will affect them, such as products on sale and the launch of a new campaign, among many others.
- Cohort analysis: This method identifies groups of users who share common characteristics during a particular time period. In a business scenario, cohort analysis is commonly used to understand customer behaviors. For example, a cohort could be all users who have signed up for a free trial on a given day. An analysis would be carried out to see how these users behave, what actions they carry out, and how their behavior differs from other user groups.
- Predictive analysis: As its name suggests, the predictive method aims to predict future developments by analyzing historical and current data. Powered by technologies such as artificial intelligence and machine learning, predictive analytics practices enable businesses to identify patterns or potential issues and plan informed strategies in advance.
- Prescriptive analysis: Also powered by predictions, the prescriptive method uses techniques such as graph analysis, complex event processing, and neural networks, among others, to try to unravel the effect that future decisions will have in order to adjust them before they are actually made. This helps businesses to develop responsive, practical business strategies.
- Conjoint analysis: Typically applied to survey analysis, the conjoint approach is used to analyze how individuals value different attributes of a product or service. This helps researchers and businesses to define pricing, product features, packaging, and many other attributes. A common use is menu-based conjoint analysis, in which individuals are given a “menu” of options from which they can build their ideal concept or product. Through this, analysts can understand which attributes they would pick above others and drive conclusions.
- Cluster analysis: Last but not least, the cluster is a method used to group objects into categories. Since there is no target variable when using cluster analysis, it is a useful method to find hidden trends and patterns in the data. In a business context, clustering is used for audience segmentation to create targeted experiences. In market research, it is often used to identify age groups, geographical information, and earnings, among others.
Now that we have seen how to interpret data, let's move on and ask ourselves some questions: What are some of the benefits of data interpretation? Why do all industries engage in data research and analysis? These are basic questions, but they often don’t receive adequate attention.
Your Chance: Want to test a powerful data analysis software? Use our 14-days free trial & start extracting insights from your data!
Why Data Interpretation Is Important

The purpose of collection and interpretation is to acquire useful and usable information and to make the most informed decisions possible. From businesses to newlyweds researching their first home, data collection and interpretation provide limitless benefits for a wide range of institutions and individuals.
Data analysis and interpretation, regardless of the method and qualitative/quantitative status, may include the following characteristics:
- Data identification and explanation
- Comparing and contrasting data
- Identification of data outliers
- Future predictions
Data analysis and interpretation, in the end, help improve processes and identify problems. It is difficult to grow and make dependable improvements without, at the very least, minimal data collection and interpretation. What is the keyword? Dependable. Vague ideas regarding performance enhancement exist within all institutions and industries. Yet, without proper research and analysis, an idea is likely to remain in a stagnant state forever (i.e., minimal growth). So… what are a few of the business benefits of digital age data analysis and interpretation? Let’s take a look!
1) Informed decision-making: A decision is only as good as the knowledge that formed it. Informed data decision-making can potentially set industry leaders apart from the rest of the market pack. Studies have shown that companies in the top third of their industries are, on average, 5% more productive and 6% more profitable when implementing informed data decision-making processes. Most decisive actions will arise only after a problem has been identified or a goal defined. Data analysis should include identification, thesis development, and data collection, followed by data communication.
If institutions only follow that simple order, one that we should all be familiar with from grade school science fairs, then they will be able to solve issues as they emerge in real-time. Informed decision-making has a tendency to be cyclical. This means there is really no end, and eventually, new questions and conditions arise within the process that need to be studied further. The monitoring of data results will inevitably return the process to the start with new data and sights.
2) Anticipating needs with trends identification: data insights provide knowledge, and knowledge is power. The insights obtained from market and consumer data analyses have the ability to set trends for peers within similar market segments. A perfect example of how data analytics can impact trend prediction is evidenced in the music identification application Shazam . The application allows users to upload an audio clip of a song they like but can’t seem to identify. Users make 15 million song identifications a day. With this data, Shazam has been instrumental in predicting future popular artists.
When industry trends are identified, they can then serve a greater industry purpose. For example, the insights from Shazam’s monitoring benefits not only Shazam in understanding how to meet consumer needs but also grant music executives and record label companies an insight into the pop-culture scene of the day. Data gathering and interpretation processes can allow for industry-wide climate prediction and result in greater revenue streams across the market. For this reason, all institutions should follow the basic data cycle of collection, interpretation, decision-making, and monitoring.
3) Cost efficiency: Proper implementation of analytics processes can provide businesses with profound cost advantages within their industries. A recent data study performed by Deloitte vividly demonstrates this in finding that data analysis ROI is driven by efficient cost reductions. Often, this benefit is overlooked because making money is typically viewed as “sexier” than saving money. Yet, sound data analyses have the ability to alert management to cost-reduction opportunities without any significant exertion of effort on the part of human capital.
A great example of the potential for cost efficiency through data analysis is Intel. Prior to 2012, Intel would conduct over 19,000 manufacturing function tests on their chips before they could be deemed acceptable for release. To cut costs and reduce test time, Intel implemented predictive data analyses. By using historical and current data, Intel now avoids testing each chip 19,000 times by focusing on specific and individual chip tests. After its implementation in 2012, Intel saved over $3 million in manufacturing costs. Cost reduction may not be as “sexy” as data profit, but as Intel proves, it is a benefit of data analysis that should not be neglected.
4) Clear foresight: companies that collect and analyze their data gain better knowledge about themselves, their processes, and their performance. They can identify performance challenges when they arise and take action to overcome them. Data interpretation through visual representations lets them process their findings faster and make better-informed decisions on the company's future.
Key Data Interpretation Skills You Should Have
Just like any other process, data interpretation and analysis require researchers or analysts to have some key skills to be able to perform successfully. It is not enough just to apply some methods and tools to the data; the person who is managing it needs to be objective and have a data-driven mind, among other skills.
It is a common misconception to think that the required skills are mostly number-related. While data interpretation is heavily analytically driven, it also requires communication and narrative skills, as the results of the analysis need to be presented in a way that is easy to understand for all types of audiences.
Luckily, with the rise of self-service tools and AI-driven technologies, data interpretation is no longer segregated for analysts only. However, the topic still remains a big challenge for businesses that make big investments in data and tools to support it, as the interpretation skills required are still lacking. It is worthless to put massive amounts of money into extracting information if you are not going to be able to interpret what that information is telling you. For that reason, below we list the top 5 data interpretation skills your employees or researchers should have to extract the maximum potential from the data.
- Data Literacy: The first and most important skill to have is data literacy. This means having the ability to understand, work, and communicate with data. It involves knowing the types of data sources, methods, and ethical implications of using them. In research, this skill is often a given. However, in a business context, there might be many employees who are not comfortable with data. The issue is the interpretation of data can not be solely responsible for the data team, as it is not sustainable in the long run. Experts advise business leaders to carefully assess the literacy level across their workforce and implement training instances to ensure everyone can interpret their data.
- Data Tools: The data interpretation and analysis process involves using various tools to collect, clean, store, and analyze the data. The complexity of the tools varies depending on the type of data and the analysis goals. Going from simple ones like Excel to more complex ones like databases, such as SQL, or programming languages, such as R or Python. It also involves visual analytics tools to bring the data to life through the use of graphs and charts. Managing these tools is a fundamental skill as they make the process faster and more efficient. As mentioned before, most modern solutions are now self-service, enabling less technical users to use them without problem.
- Critical Thinking: Another very important skill is to have critical thinking. Data hides a range of conclusions, trends, and patterns that must be discovered. It is not just about comparing numbers; it is about putting a story together based on multiple factors that will lead to a conclusion. Therefore, having the ability to look further from what is right in front of you is an invaluable skill for data interpretation.
- Data Ethics: In the information age, being aware of the legal and ethical responsibilities that come with the use of data is of utmost importance. In short, data ethics involves respecting the privacy and confidentiality of data subjects, as well as ensuring accuracy and transparency for data usage. It requires the analyzer or researcher to be completely objective with its interpretation to avoid any biases or discrimination. Many countries have already implemented regulations regarding the use of data, including the GDPR or the ACM Code Of Ethics. Awareness of these regulations and responsibilities is a fundamental skill that anyone working in data interpretation should have.
- Domain Knowledge: Another skill that is considered important when interpreting data is to have domain knowledge. As mentioned before, data hides valuable insights that need to be uncovered. To do so, the analyst needs to know about the industry or domain from which the information is coming and use that knowledge to explore it and put it into a broader context. This is especially valuable in a business context, where most departments are now analyzing data independently with the help of a live dashboard instead of relying on the IT department, which can often overlook some aspects due to a lack of expertise in the topic.
Common Data Analysis And Interpretation Problems

The oft-repeated mantra of those who fear data advancements in the digital age is “big data equals big trouble.” While that statement is not accurate, it is safe to say that certain data interpretation problems or “pitfalls” exist and can occur when analyzing data, especially at the speed of thought. Let’s identify some of the most common data misinterpretation risks and shed some light on how they can be avoided:
1) Correlation mistaken for causation: our first misinterpretation of data refers to the tendency of data analysts to mix the cause of a phenomenon with correlation. It is the assumption that because two actions occurred together, one caused the other. This is inaccurate, as actions can occur together, absent a cause-and-effect relationship.
- Digital age example: assuming that increased revenue results from increased social media followers… there might be a definitive correlation between the two, especially with today’s multi-channel purchasing experiences. But that does not mean an increase in followers is the direct cause of increased revenue. There could be both a common cause and an indirect causality.
- Remedy: attempt to eliminate the variable you believe to be causing the phenomenon.
2) Confirmation bias: our second problem is data interpretation bias. It occurs when you have a theory or hypothesis in mind but are intent on only discovering data patterns that support it while rejecting those that do not.
- Digital age example: your boss asks you to analyze the success of a recent multi-platform social media marketing campaign. While analyzing the potential data variables from the campaign (one that you ran and believe performed well), you see that the share rate for Facebook posts was great, while the share rate for Twitter Tweets was not. Using only Facebook posts to prove your hypothesis that the campaign was successful would be a perfect manifestation of confirmation bias.
- Remedy: as this pitfall is often based on subjective desires, one remedy would be to analyze data with a team of objective individuals. If this is not possible, another solution is to resist the urge to make a conclusion before data exploration has been completed. Remember to always try to disprove a hypothesis, not prove it.
3) Irrelevant data: the third data misinterpretation pitfall is especially important in the digital age. As large data is no longer centrally stored and as it continues to be analyzed at the speed of thought, it is inevitable that analysts will focus on data that is irrelevant to the problem they are trying to correct.
- Digital age example: in attempting to gauge the success of an email lead generation campaign, you notice that the number of homepage views directly resulting from the campaign increased, but the number of monthly newsletter subscribers did not. Based on the number of homepage views, you decide the campaign was a success when really it generated zero leads.
- Remedy: proactively and clearly frame any data analysis variables and KPIs prior to engaging in a data review. If the metric you use to measure the success of a lead generation campaign is newsletter subscribers, there is no need to review the number of homepage visits. Be sure to focus on the data variable that answers your question or solves your problem and not on irrelevant data.
4) Truncating an Axes: When creating a graph to start interpreting the results of your analysis, it is important to keep the axes truthful and avoid generating misleading visualizations. Starting the axes in a value that doesn’t portray the actual truth about the data can lead to false conclusions.
- Digital age example: In the image below, we can see a graph from Fox News in which the Y-axes start at 34%, making it seem that the difference between 35% and 39.6% is way higher than it actually is. This could lead to a misinterpretation of the tax rate changes.

* Source : www.venngage.com *
- Remedy: Be careful with how your data is visualized. Be respectful and realistic with axes to avoid misinterpretation of your data. See below how the Fox News chart looks when using the correct axis values. This chart was created with datapine's modern online data visualization tool.

5) (Small) sample size: Another common problem is using a small sample size. Logically, the bigger the sample size, the more accurate and reliable the results. However, this also depends on the size of the effect of the study. For example, the sample size in a survey about the quality of education will not be the same as for one about people doing outdoor sports in a specific area.
- Digital age example: Imagine you ask 30 people a question, and 29 answer “yes,” resulting in 95% of the total. Now imagine you ask the same question to 1000, and 950 of them answer “yes,” which is again 95%. While these percentages might look the same, they certainly do not mean the same thing, as a 30-person sample size is not a significant number to establish a truthful conclusion.
- Remedy: Researchers say that in order to determine the correct sample size to get truthful and meaningful results, it is necessary to define a margin of error that will represent the maximum amount they want the results to deviate from the statistical mean. Paired with this, they need to define a confidence level that should be between 90 and 99%. With these two values in hand, researchers can calculate an accurate sample size for their studies.
6) Reliability, subjectivity, and generalizability : When performing qualitative analysis, researchers must consider practical and theoretical limitations when interpreting the data. In some cases, this type of research can be considered unreliable because of uncontrolled factors that might or might not affect the results. This is paired with the fact that the researcher has a primary role in the interpretation process, meaning he or she decides what is relevant and what is not, and as we know, interpretations can be very subjective.
Generalizability is also an issue that researchers face when dealing with qualitative analysis. As mentioned in the point about having a small sample size, it is difficult to draw conclusions that are 100% representative because the results might be biased or unrepresentative of a wider population.
While these factors are mostly present in qualitative research, they can also affect the quantitative analysis. For example, when choosing which KPIs to portray and how to portray them, analysts can also be biased and represent them in a way that benefits their analysis.
- Digital age example: Biased questions in a survey are a great example of reliability and subjectivity issues. Imagine you are sending a survey to your clients to see how satisfied they are with your customer service with this question: “How amazing was your experience with our customer service team?”. Here, we can see that this question clearly influences the response of the individual by putting the word “amazing” on it.
- Remedy: A solution to avoid these issues is to keep your research honest and neutral. Keep the wording of the questions as objective as possible. For example: “On a scale of 1-10, how satisfied were you with our customer service team?”. This does not lead the respondent to any specific answer, meaning the results of your survey will be reliable.
Data Interpretation Best Practices & Tips

Data analysis and interpretation are critical to developing sound conclusions and making better-informed decisions. As we have seen with this article, there is an art and science to the interpretation of data. To help you with this purpose, we will list a few relevant techniques, methods, and tricks you can implement for a successful data management process.
As mentioned at the beginning of this post, the first step to interpreting data in a successful way is to identify the type of analysis you will perform and apply the methods respectively. Clearly differentiate between qualitative (observe, document, and interview notice, collect and think about things) and quantitative analysis (you lead research with a lot of numerical data to be analyzed through various statistical methods).
1) Ask the right data interpretation questions
The first data interpretation technique is to define a clear baseline for your work. This can be done by answering some critical questions that will serve as a useful guideline to start. Some of them include: what are the goals and objectives of my analysis? What type of data interpretation method will I use? Who will use this data in the future? And most importantly, what general question am I trying to answer?
Once all this information has been defined, you will be ready for the next step: collecting your data.
2) Collect and assimilate your data
Now that a clear baseline has been established, it is time to collect the information you will use. Always remember that your methods for data collection will vary depending on what type of analysis method you use, which can be qualitative or quantitative. Based on that, relying on professional online data analysis tools to facilitate the process is a great practice in this regard, as manually collecting and assessing raw data is not only very time-consuming and expensive but is also at risk of errors and subjectivity.
Once your data is collected, you need to carefully assess it to understand if the quality is appropriate to be used during a study. This means, is the sample size big enough? Were the procedures used to collect the data implemented correctly? Is the date range from the data correct? If coming from an external source, is it a trusted and objective one?
With all the needed information in hand, you are ready to start the interpretation process, but first, you need to visualize your data.
3) Use the right data visualization type
Data visualizations such as business graphs , charts, and tables are fundamental to successfully interpreting data. This is because data visualization via interactive charts and graphs makes the information more understandable and accessible. As you might be aware, there are different types of visualizations you can use, but not all of them are suitable for any analysis purpose. Using the wrong graph can lead to misinterpretation of your data, so it’s very important to carefully pick the right visual for it. Let’s look at some use cases of common data visualizations.
- Bar chart: One of the most used chart types, the bar chart uses rectangular bars to show the relationship between 2 or more variables. There are different types of bar charts for different interpretations, including the horizontal bar chart, column bar chart, and stacked bar chart.
- Line chart: Most commonly used to show trends, acceleration or decelerations, and volatility, the line chart aims to show how data changes over a period of time, for example, sales over a year. A few tips to keep this chart ready for interpretation are not using many variables that can overcrowd the graph and keeping your axis scale close to the highest data point to avoid making the information hard to read.
- Pie chart: Although it doesn’t do a lot in terms of analysis due to its uncomplex nature, pie charts are widely used to show the proportional composition of a variable. Visually speaking, showing a percentage in a bar chart is way more complicated than showing it in a pie chart. However, this also depends on the number of variables you are comparing. If your pie chart needs to be divided into 10 portions, then it is better to use a bar chart instead.
- Tables: While they are not a specific type of chart, tables are widely used when interpreting data. Tables are especially useful when you want to portray data in its raw format. They give you the freedom to easily look up or compare individual values while also displaying grand totals.
With the use of data visualizations becoming more and more critical for businesses’ analytical success, many tools have emerged to help users visualize their data in a cohesive and interactive way. One of the most popular ones is the use of BI dashboards . These visual tools provide a centralized view of various graphs and charts that paint a bigger picture of a topic. We will discuss the power of dashboards for an efficient data interpretation practice in the next portion of this post. If you want to learn more about different types of graphs and charts , take a look at our complete guide on the topic.
4) Start interpreting
After the tedious preparation part, you can start extracting conclusions from your data. As mentioned many times throughout the post, the way you decide to interpret the data will solely depend on the methods you initially decided to use. If you had initial research questions or hypotheses, then you should look for ways to prove their validity. If you are going into the data with no defined hypothesis, then start looking for relationships and patterns that will allow you to extract valuable conclusions from the information.
During the process of interpretation, stay curious and creative, dig into the data, and determine if there are any other critical questions that should be asked. If any new questions arise, you need to assess if you have the necessary information to answer them. Being able to identify if you need to dedicate more time and resources to the research is a very important step. No matter if you are studying customer behaviors or a new cancer treatment, the findings from your analysis may dictate important decisions in the future. Therefore, taking the time to really assess the information is key. For that purpose, data interpretation software proves to be very useful.
5) Keep your interpretation objective
As mentioned above, objectivity is one of the most important data interpretation skills but also one of the hardest. Being the person closest to the investigation, it is easy to become subjective when looking for answers in the data. A good way to stay objective is to show the information related to the study to other people, for example, research partners or even the people who will use your findings once they are done. This can help avoid confirmation bias and any reliability issues with your interpretation.
Remember, using a visualization tool such as a modern dashboard will make the interpretation process way easier and more efficient as the data can be navigated and manipulated in an easy and organized way. And not just that, using a dashboard tool to present your findings to a specific audience will make the information easier to understand and the presentation way more engaging thanks to the visual nature of these tools.
6) Mark your findings and draw conclusions
Findings are the observations you extracted from your data. They are the facts that will help you drive deeper conclusions about your research. For example, findings can be trends and patterns you found during your interpretation process. To put your findings into perspective, you can compare them with other resources that use similar methods and use them as benchmarks.
Reflect on your own thinking and reasoning and be aware of the many pitfalls data analysis and interpretation carry—correlation versus causation, subjective bias, false information, inaccurate data, etc. Once you are comfortable with interpreting the data, you will be ready to develop conclusions, see if your initial questions were answered, and suggest recommendations based on them.
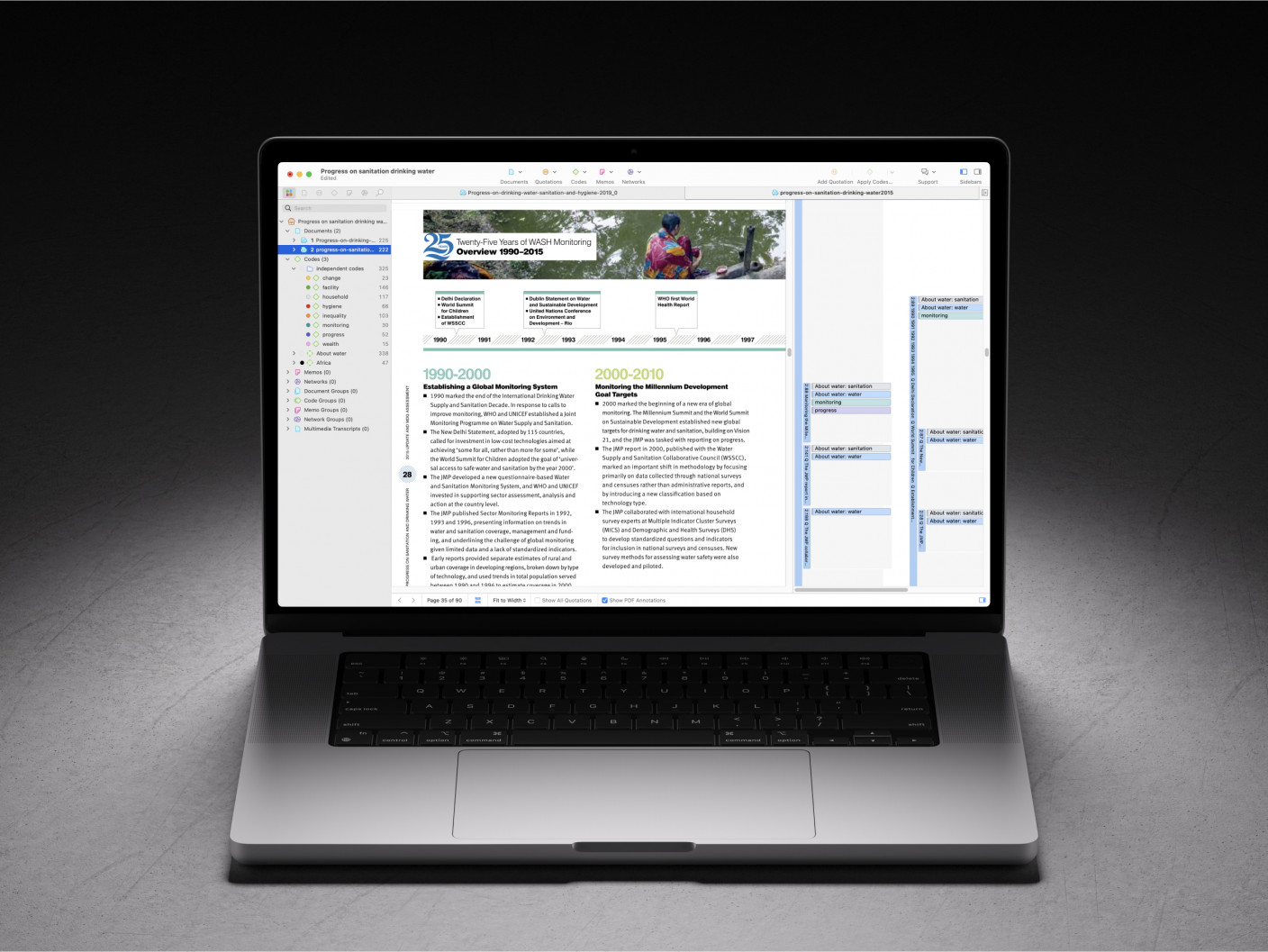
Interpretation of Data: The Use of Dashboards Bridging The Gap
As we have seen, quantitative and qualitative methods are distinct types of data interpretation and analysis. Both offer a varying degree of return on investment (ROI) regarding data investigation, testing, and decision-making. But how do you mix the two and prevent a data disconnect? The answer is professional data dashboards.
For a few years now, dashboards have become invaluable tools to visualize and interpret data. These tools offer a centralized and interactive view of data and provide the perfect environment for exploration and extracting valuable conclusions. They bridge the quantitative and qualitative information gap by unifying all the data in one place with the help of stunning visuals.
Not only that, but these powerful tools offer a large list of benefits, and we will discuss some of them below.
1) Connecting and blending data. With today’s pace of innovation, it is no longer feasible (nor desirable) to have bulk data centrally located. As businesses continue to globalize and borders continue to dissolve, it will become increasingly important for businesses to possess the capability to run diverse data analyses absent the limitations of location. Data dashboards decentralize data without compromising on the necessary speed of thought while blending both quantitative and qualitative data. Whether you want to measure customer trends or organizational performance, you now have the capability to do both without the need for a singular selection.
2) Mobile Data. Related to the notion of “connected and blended data” is that of mobile data. In today’s digital world, employees are spending less time at their desks and simultaneously increasing production. This is made possible because mobile solutions for analytical tools are no longer standalone. Today, mobile analysis applications seamlessly integrate with everyday business tools. In turn, both quantitative and qualitative data are now available on-demand where they’re needed, when they’re needed, and how they’re needed via interactive online dashboards .
3) Visualization. Data dashboards merge the data gap between qualitative and quantitative data interpretation methods through the science of visualization. Dashboard solutions come “out of the box” and are well-equipped to create easy-to-understand data demonstrations. Modern online data visualization tools provide a variety of color and filter patterns, encourage user interaction, and are engineered to help enhance future trend predictability. All of these visual characteristics make for an easy transition among data methods – you only need to find the right types of data visualization to tell your data story the best way possible.
4) Collaboration. Whether in a business environment or a research project, collaboration is key in data interpretation and analysis. Dashboards are online tools that can be easily shared through a password-protected URL or automated email. Through them, users can collaborate and communicate through the data in an efficient way. Eliminating the need for infinite files with lost updates. Tools such as datapine offer real-time updates, meaning your dashboards will update on their own as soon as new information is available.
Examples Of Data Interpretation In Business
To give you an idea of how a dashboard can fulfill the need to bridge quantitative and qualitative analysis and help in understanding how to interpret data in research thanks to visualization, below, we will discuss three valuable examples to put their value into perspective.
1. Customer Satisfaction Dashboard
This market research dashboard brings together both qualitative and quantitative data that are knowledgeably analyzed and visualized in a meaningful way that everyone can understand, thus empowering any viewer to interpret it. Let’s explore it below.

**click to enlarge**
The value of this template lies in its highly visual nature. As mentioned earlier, visuals make the interpretation process way easier and more efficient. Having critical pieces of data represented with colorful and interactive icons and graphs makes it possible to uncover insights at a glance. For example, the colors green, yellow, and red on the charts for the NPS and the customer effort score allow us to conclude that most respondents are satisfied with this brand with a short glance. A further dive into the line chart below can help us dive deeper into this conclusion, as we can see both metrics developed positively in the past 6 months.
The bottom part of the template provides visually stunning representations of different satisfaction scores for quality, pricing, design, and service. By looking at these, we can conclude that, overall, customers are satisfied with this company in most areas.
2. Brand Analysis Dashboard
Next, in our list of data interpretation examples, we have a template that shows the answers to a survey on awareness for Brand D. The sample size is listed on top to get a perspective of the data, which is represented using interactive charts and graphs.

When interpreting information, context is key to understanding it correctly. For that reason, the dashboard starts by offering insights into the demographics of the surveyed audience. In general, we can see ages and gender are diverse. Therefore, we can conclude these brands are not targeting customers from a specified demographic, an important aspect to put the surveyed answers into perspective.
Looking at the awareness portion, we can see that brand B is the most popular one, with brand D coming second on both questions. This means brand D is not doing wrong, but there is still room for improvement compared to brand B. To see where brand D could improve, the researcher could go into the bottom part of the dashboard and consult the answers for branding themes and celebrity analysis. These are important as they give clear insight into what people and messages the audience associates with brand D. This is an opportunity to exploit these topics in different ways and achieve growth and success.
3. Product Innovation Dashboard
Our third and last dashboard example shows the answers to a survey on product innovation for a technology company. Just like the previous templates, the interactive and visual nature of the dashboard makes it the perfect tool to interpret data efficiently and effectively.

Starting from right to left, we first get a list of the top 5 products by purchase intention. This information lets us understand if the product being evaluated resembles what the audience already intends to purchase. It is a great starting point to see how customers would respond to the new product. This information can be complemented with other key metrics displayed in the dashboard. For example, the usage and purchase intention track how the market would receive the product and if they would purchase it, respectively. Interpreting these values as positive or negative will depend on the company and its expectations regarding the survey.
Complementing these metrics, we have the willingness to pay. Arguably, one of the most important metrics to define pricing strategies. Here, we can see that most respondents think the suggested price is a good value for money. Therefore, we can interpret that the product would sell for that price.
To see more data analysis and interpretation examples for different industries and functions, visit our library of business dashboards .
To Conclude…
As we reach the end of this insightful post about data interpretation and analysis, we hope you have a clear understanding of the topic. We've covered the definition and given some examples and methods to perform a successful interpretation process.
The importance of data interpretation is undeniable. Dashboards not only bridge the information gap between traditional data interpretation methods and technology, but they can help remedy and prevent the major pitfalls of the process. As a digital age solution, they combine the best of the past and the present to allow for informed decision-making with maximum data interpretation ROI.
To start visualizing your insights in a meaningful and actionable way, test our online reporting software for free with our 14-day trial !
- What is Data Interpretation? + [Types, Method & Tools]

- Data Collection
Data interpretation and analysis are fast becoming more valuable with the prominence of digital communication, which is responsible for a large amount of data being churned out daily. According to the WEF’s “A Day in Data” Report , the accumulated digital universe of data is set to reach 44 ZB (Zettabyte) in 2020.
Based on this report, it is clear that for any business to be successful in today’s digital world, the founders need to know or employ people who know how to analyze complex data, produce actionable insights and adapt to new market trends. Also, all these need to be done in milliseconds.
So, what is data interpretation and analysis, and how do you leverage this knowledge to help your business or research? All this and more will be revealed in this article.
What is Data Interpretation?
Data interpretation is the process of reviewing data through some predefined processes which will help assign some meaning to the data and arrive at a relevant conclusion. It involves taking the result of data analysis, making inferences on the relations studied, and using them to conclude.
Therefore, before one can talk about interpreting data, they need to be analyzed first. What then, is data analysis?
Data analysis is the process of ordering, categorizing, manipulating, and summarizing data to obtain answers to research questions. It is usually the first step taken towards data interpretation.
It is evident that the interpretation of data is very important, and as such needs to be done properly. Therefore, researchers have identified some data interpretation methods to aid this process.
What are Data Interpretation Methods?
Data interpretation methods are how analysts help people make sense of numerical data that has been collected, analyzed and presented. Data, when collected in raw form, may be difficult for the layman to understand, which is why analysts need to break down the information gathered so that others can make sense of it.
For example, when founders are pitching to potential investors, they must interpret data (e.g. market size, growth rate, etc.) for better understanding. There are 2 main methods in which this can be done, namely; quantitative methods and qualitative methods .
Qualitative Data Interpretation Method
The qualitative data interpretation method is used to analyze qualitative data, which is also known as categorical data . This method uses texts, rather than numbers or patterns to describe data.
Qualitative data is usually gathered using a wide variety of person-to-person techniques , which may be difficult to analyze compared to the quantitative research method .
Unlike the quantitative data which can be analyzed directly after it has been collected and sorted, qualitative data needs to first be coded into numbers before it can be analyzed. This is because texts are usually cumbersome, and will take more time, and result in a lot of errors if analyzed in their original state. Coding done by the analyst should also be documented so that it can be reused by others and also analyzed.
There are 2 main types of qualitative data, namely; nominal and ordinal data . These 2 data types are both interpreted using the same method, but ordinal data interpretation is quite easier than that of nominal data .
In most cases, ordinal data is usually labeled with numbers during the process of data collection, and coding may not be required. This is different from nominal data that still needs to be coded for proper interpretation.
Quantitative Data Interpretation Method
The quantitative data interpretation method is used to analyze quantitative data, which is also known as numerical data . This data type contains numbers and is therefore analyzed with the use of numbers and not texts.
Quantitative data are of 2 main types, namely; discrete and continuous data. Continuous data is further divided into interval data and ratio data, with all the data types being numeric .
Due to its natural existence as a number, analysts do not need to employ the coding technique on quantitative data before it is analyzed. The process of analyzing quantitative data involves statistical modelling techniques such as standard deviation, mean and median.
Some of the statistical methods used in analyzing quantitative data are highlighted below:
The mean is a numerical average for a set of data and is calculated by dividing the sum of the values by the number of values in a dataset. It is used to get an estimate of a large population from the dataset obtained from a sample of the population.
For example, online job boards in the US use the data collected from a group of registered users to estimate the salary paid to people of a particular profession. The estimate is usually made using the average salary submitted on their platform for each profession.
- Standard deviation
This technique is used to measure how well the responses align with or deviates from the mean. It describes the degree of consistency within the responses; together with the mean, it provides insight into data sets.
In the job board example highlighted above, if the average salary of writers in the US is $20,000 per annum, and the standard deviation is 5.0, we can easily deduce that the salaries for the professionals are far away from each other. This will birth other questions like why the salaries deviate from each other that much.
With this question, we may conclude that the sample contains people with few years of experience, which translates to a lower salary, and people with many years of experience, translating to a higher salary. However, it does not contain people with mid-level experience.
- Frequency distribution
This technique is used to assess the demography of the respondents or the number of times a particular response appears in research. It is extremely keen on determining the degree of intersection between data points.
Some other interpretation processes of quantitative data include:
- Regression analysis
- Cohort analysis
- Predictive and prescriptive analysis
Tips for Collecting Accurate Data for Interpretation
- Identify the Required Data Type
Researchers need to identify the type of data required for particular research. Is it nominal, ordinal, interval, or ratio data ?
The key to collecting the required data to conduct research is to properly understand the research question. If the researcher can understand the research question, then he can identify the kind of data that is required to carry out the research.
For example, when collecting customer feedback, the best data type to use is the ordinal data type . Ordinal data can be used to access a customer’s feelings about a brand and is also easy to interpret.
- Avoid Biases
There are different kinds of biases a researcher might encounter when collecting data for analysis. Although biases sometimes come from the researcher, most of the biases encountered during the data collection process is caused by the respondent.
There are 2 main biases, that can be caused by the President, namely; response bias and non-response bias . Researchers may not be able to eliminate these biases, but there are ways in which they can be avoided and reduced to a minimum.
Response biases are biases that are caused by respondents intentionally giving wrong answers to responses, while non-response bias occurs when the respondents don’t give answers to questions at all. Biases are capable of affecting the process of data interpretation .
- Use Close Ended Surveys
Although open-ended surveys are capable of giving detailed information about the questions and allowing respondents to fully express themselves, it is not the best kind of survey for data interpretation. It requires a lot of coding before the data can be analyzed.
Close-ended surveys , on the other hand, restrict the respondents’ answers to some predefined options, while simultaneously eliminating irrelevant data. This way, researchers can easily analyze and interpret data.
However, close-ended surveys may not be applicable in some cases, like when collecting respondents’ personal information like name, credit card details, phone number, etc.
Visualization Techniques in Data Analysis
One of the best practices of data interpretation is the visualization of the dataset. Visualization makes it easy for a layman to understand the data, and also encourages people to view the data, as it provides a visually appealing summary of the data.
There are different techniques of data visualization, some of which are highlighted below.
Bar graphs are graphs that interpret the relationship between 2 or more variables using rectangular bars. These rectangular bars can be drawn either vertically or horizontally, but they are mostly drawn vertically.
The graph contains the horizontal axis (x) and the vertical axis (y), with the former representing the independent variable while the latter is the dependent variable. Bar graphs can be grouped into different types, depending on how the rectangular bars are placed on the graph.
Some types of bar graphs are highlighted below:
- Grouped Bar Graph
The grouped bar graph is used to show more information about variables that are subgroups of the same group with each subgroup bar placed side-by-side like in a histogram.
- Stacked Bar Graph
A stacked bar graph is a grouped bar graph with its rectangular bars stacked on top of each other rather than placed side by side.
- Segmented Bar Graph
Segmented bar graphs are stacked bar graphs where each rectangular bar shows 100% of the dependent variable. It is mostly used when there is an intersection between the variable categories.
Advantages of a Bar Graph
- It helps to summarize a large data
- Estimations of key values c.an be made at a glance
- Can be easily understood
Disadvantages of a Bar Graph
- It may require additional explanation.
- It can be easily manipulated.
- It doesn’t properly describe the dataset.
A pie chart is a circular graph used to represent the percentage of occurrence of a variable using sectors. The size of each sector is dependent on the frequency or percentage of the corresponding variables.
There are different variants of the pie charts, but for the sake of this article, we will be restricting ourselves to only 3. For better illustration of these types, let us consider the following examples.
Pie Chart Example : There are a total of 50 students in a class, and out of them, 10 students like Football, 25 students like snooker, and 15 students like Badminton.
- Simple Pie Chart
The simple pie chart is the most basic type of pie chart, which is used to depict the general representation of a bar chart.
- Doughnut Pie Chart
Doughnut pie is a variant of the pie chart, with a blank center allowing for additional information about the data as a whole to be included.
- 3D Pie Chart
3D pie chart is used to give the chart a 3D look and is often used for aesthetic purposes. It is usually difficult to reach because of the distortion of perspective due to the third dimension.
Advantages of a Pie Chart
- It is visually appealing.
- Best for comparing small data samples.
Disadvantages of a Pie Chart
- It can only compare small sample sizes.
- Unhelpful with observing trends over time.
Tables are used to represent statistical data by placing them in rows and columns. They are one of the most common statistical visualization techniques and are of 2 main types, namely; simple and complex tables.
- Simple Tables
Simple tables summarize information on a single characteristic and may also be called a univariate table. An example of a simple table showing the number of employed people in a community concerning their age group.
- Complex Tables
As its name suggests, complex tables summarize complex information and present them in two or more intersecting categories. A complex table example is a table showing the number of employed people in a population concerning their age group and sex as shown in the table below.
Advantages of Tables
- Can contain large data sets
- Helpful in comparing 2 or more similar things
Disadvantages of Tables
- They do not give detailed information.
- Maybe time-consuming.
Line graphs or charts are a type of graph that displays information as a series of points, usually connected by a straight line. Some of the types of line graphs are highlighted below.
- Simple Line Graphs
Simple line graphs show the trend of data over time, and may also be used to compare categories. Let us assume we got the sales data of a firm for each quarter and are to visualize it using a line graph to estimate sales for the next year.
- Line Graphs with Markers
These are similar to line graphs but have visible markers illustrating the data points
- Stacked Line Graphs
Stacked line graphs are line graphs where the points do not overlap, and the graphs are therefore placed on top of each other. Consider that we got the quarterly sales data for each product sold by the company and are to visualize it to predict company sales for the next year.
Advantages of a Line Graph
- Great for visualizing trends and changes over time.
- It is simple to construct and read.
Disadvantage of a Line Graph
- It can not compare different variables at a single place or time.
Read: 11 Types of Graphs & Charts + [Examples]
What are the Steps in Interpreting Data?
After data collection, you’d want to know the result of your findings. Ultimately, the findings of your data will be largely dependent on the questions you’ve asked in your survey or your initial study questions. Here are the four steps for accurately interpreting data
1. Gather the data
The very first step in interpreting data is having all the relevant data assembled. You can do this by visualizing it first either in a bar, graph, or pie chart. The purpose of this step is to accurately analyze the data without any bias.
Now is the time to remember the details of how you conducted the research. Were there any flaws or changes that occurred when gathering this data? Did you keep any observatory notes and indicators?
Once you have your complete data, you can move to the next stage
2. Develop your findings
This is the summary of your observations. Here, you observe this data thoroughly to find trends, patterns, or behavior. If you are researching about a group of people through a sample population, this is where you analyze behavioral patterns. The purpose of this step is to compare these deductions before drawing any conclusions. You can compare these deductions with each other, similar data sets in the past, or general deductions in your industry.
3. Derive Conclusions
Once you’ve developed your findings from your data sets, you can then draw conclusions based on trends you’ve discovered. Your conclusions should answer the questions that led you to your research. If they do not answer these questions ask why? It may lead to further research or subsequent questions.
4. Give recommendations
For every research conclusion, there has to be a recommendation. This is the final step in data interpretation because recommendations are a summary of your findings and conclusions. For recommendations, it can only go in one of two ways. You can either recommend a line of action or recommend that further research be conducted.
How to Collect Data with Surveys or Questionnaires
As a business owner who wants to regularly track the number of sales made in your business, you need to know how to collect data. Follow these 4 easy steps to collect real-time sales data for your business using Formplus.
Step 1 – Register on Formplus
- Visit Formplus on your PC or mobile device.
- Click on the Start for Free button to start collecting data for your business.
Step 2 – Start Creating Surveys For Free
- Go to the Forms tab beside your Dashboard in the Formplus menu.
- Click on Create Form to start creating your survey
- Take advantage of the dynamic form fields to add questions to your survey.
- You can also add payment options that allow you to receive payments using Paypal, Flutterwave, and Stripe.
Step 3 – Customize Your Survey and Start Collecting Data
- Go to the Customise tab to beautify your survey by adding colours, background images, fonts, or even a custom CSS.
- You can also add your brand logo, colour and other things to define your brand identity.
- Preview your form, share, and start collecting data.
Step 4 – Track Responses Real-time
- Track your sales data in real-time in the Analytics section.
Why Use Formplus to Collect Data?
The responses to each form can be accessed through the analytics section, which automatically analyzes the responses collected through Formplus forms. This section visualizes the collected data using tables and graphs, allowing analysts to easily arrive at an actionable insight without going through the rigorous process of analyzing the data.
- 30+ Form Fields
There is no restriction on the kind of data that can be collected by researchers through the available form fields. Researchers can collect both quantitative and qualitative data types simultaneously through a single questionnaire.
- Data Storage
The data collected through Formplus are safely stored and secured in the Formplus database. You can also choose to store this data in an external storage device.
- Real-time access
Formplus gives real-time access to information, making sure researchers are always informed of the current trends and changes in data. That way, researchers can easily measure a shift in market trends that inform important decisions.
- WordPress Integration
Users can now embed Formplus forms into their WordPress posts and pages using a shortcode. This can be done by installing the Formplus plugin into your WordPress websites.
Advantages and Importance of Data Interpretation
- Data interpretation is important because it helps make data-driven decisions.
- It saves costs by providing costing opportunities
- The insights and findings gotten from interpretation can be used to spot trends in a sector or industry.
Conclusion
Data interpretation and analysis is an important aspect of working with data sets in any field or research and statistics. They both go hand in hand, as the process of data interpretation involves the analysis of data.
The process of data interpretation is usually cumbersome, and should naturally become more difficult with the best amount of data that is being churned out daily. However, with the accessibility of data analysis tools and machine learning techniques, analysts are gradually finding it easier to interpret data.
Data interpretation is very important, as it helps to acquire useful information from a pool of irrelevant ones while making informed decisions. It is found useful for individuals, businesses, and researchers.
Connect to Formplus, Get Started Now - It's Free!
- data analysis
- data interpretation
- data interpretation methods
- how to analyse data
- how to interprete data
- qualitative data
- quantitative data
- busayo.longe
You may also like:
Qualitative vs Quantitative Data:15 Differences & Similarities
Quantitative and qualitative data differences & similarities in definitions, examples, types, analysis, data collection techniques etc.
Collecting Voice of Customer Data: 9 Techniques that Work
In this article, we’ll show you nine(9) practical ways to collect voice of customer data from your clients.
15 Reasons to Choose Quantitative over Qualitative Research
This guide tells you everything you need to know about qualitative and quantitative research, it differences,types, when to use it, how...
What is a Panel Survey?
Introduction Panel surveys are a type of survey conducted over a long period measuring consumer behavior and perception of a product, an...
Formplus - For Seamless Data Collection
Collect data the right way with a versatile data collection tool. try formplus and transform your work productivity today..

The Ultimate Guide to Qualitative Research - Part 2: Handling Qualitative Data

- Handling qualitative data
- Transcripts
- Field notes
- Survey data and responses
- Visual and audio data
- Data organization
- Data coding
- Coding frame
- Auto and smart coding
- Organizing codes
- Qualitative data analysis
- Content analysis
- Thematic analysis
- Thematic analysis vs. content analysis
- Narrative research
- Phenomenological research
- Discourse analysis
- Grounded theory
- Deductive reasoning
- Inductive reasoning
- Inductive vs. deductive reasoning
The role of data interpretation
Quantitative data interpretation, qualitative data interpretation, using atlas.ti for interpreting data, data visualization.
- Qualitative analysis software
What is data interpretation? Tricks & techniques
Raw data by itself isn't helpful to research without data interpretation. The need to organize and analyze data so that research can produce actionable insights and develop new knowledge affirms the importance of the data interpretation process.

Let's look at why data interpretation is important to the research process, how you can interpret data, and how the tools in ATLAS.ti can help you look at your data in meaningful ways.
The data collection process is just one part of research, and one that can often provide a lot of data without any easy answers that instantly stick out to researchers or their audiences. An example of data that requires an interpretation process is a corpus, or a large body of text, meant to represent some language use (e.g., literature, conversation). A corpus of text can collect millions of words from written texts and spoken interactions.
Challenge of data interpretation
While this is an impressive body of data, sifting through this corpus can be difficult. If you are trying to make assertions about language based on the corpus data, what data is useful to you? How do you separate irrelevant data from valuable insights? How can you persuade your audience to understand your research?
Data interpretation is a process that involves assigning meaning to the data. A researcher's responsibility is to explain and persuade their research audience on how they see the data and what insights can be drawn from their interpretation.
Interpreting raw data to produce insights
Unstructured data is any sort of data that is not organized by some predetermined structure or that is in its raw, naturally-occurring form. Without data analysis , the data is difficult to interpret to generate useful insights.
This unstructured data is not always mindless noise, however. The importance of data interpretation can be seen in examples like a blog with a series of articles on a particular subject or a cookbook with a collection of recipes. These pieces of writing are useful and perhaps interesting to readers of various backgrounds or knowledge bases.
Data interpretation starting with research inquiry
People can read a set of information, such as a blog article or a recipe, in different ways (some may read the ingredients first while others skip to the directions). Data interpretation grounds the understanding and reporting of the research in clearly defined terms such that, even if different scholars disagree on the findings of the research, they at least share a foundational understanding of how the research is interpreted.
Moreover, suppose someone is reading a set of recipes to understand the food culture of a particular place or group of people. A straightforward recipe may not explicitly or neatly convey this information. Still, a thorough reader can analyze bits and pieces of each recipe in that cookbook to understand the ingredients, tools, and methods used in that particular food culture.
As a result, your research inquiry may require you to reorganize the data in a way that allows for easier data interpretation. Analyzing data as a part of the interpretation process, especially in qualitative research , means looking for the relevant data, summarizing data for the insights they hold, and discarding any irrelevant data that is not useful to the given research inquiry.

Let's look at a fairly straightforward process that can be used to turn data into valuable insights through data interpretation.
Sorting the data
Think about our previous example with a collection of recipes. You can break down a recipe into various "data points," which you might consider categories or points of measurement. A recipe can be broken down into ingredients, directions, or even preparation time, things that are often written into a recipe. Or you might look at recipes from a different angle using less observed categories, such as the cost to make the recipe or skills required to make the recipe. Whatever categories you choose, however, will determine how you interpret the data.
As a result, think about what you are trying to examine and identify what categories or measures should be used to analyze and understand the data. These data points will form your "buckets" to sort your collected data into more meaningful information for data interpretation.
Identifying trends and patterns
Once you've sorted enough of the data into your categorical buckets, you might begin to notice some telling patterns. Suppose you are analyzing a cookbook of barbecue recipes for nutritional value. In that case, you might find an abundance of recipes with high fat and sugar, while a collection of salad recipes might yield patterns of dishes with low carbohydrates. These patterns will form the basis for answering your research inquiry.
Drawing connections
The meaning of these trends and patterns is not always self-evident. When people wear the same trendy clothes or listen to the same popular music, they may do so because the clothing or music is genuinely good or because they are following the crowd. They may even be trying to impress someone they know.
As you look at the patterns in your data, you can start to look at whether the patterns coincide (or co-occur) to determine a starting point for discussion about whether they are related to each other. Whether these co-occurrences share a meaningful relationship or are only loosely correlated with each other, all data interpretation of patterns starts by looking within and across patterns and co-occurrences among them.
Use ATLAS.ti to interpret data for your research
An intuitive interface combined with powerful data interpretation tools, available starting with a free trial.
Quantitative analysis through statistical methods benefits researchers who are looking to measure a particular phenomenon. Numerical data can measure the different degrees of a concept, such as temperature, speed, wealth, or even academic achievement.
Quantitative data analysis is a matter of rearranging the data to make it easier to measure. Imagine sorting a child's piggy bank full of coins into different types of coins (e.g., pennies, nickels, dimes, and quarters). Without sorting these coins for measurement, it becomes difficult to efficiently measure the value of the coins in that piggy bank.
Quantitative data interpretation method
A good data interpretation question regarding that child's piggy bank might be, "Has the child saved up enough money?" Then it's a matter of deciding what "enough money" might be, whether it's $20, $50, or even $100. Once that determination has been made, you can then answer your question after your quantitative analysis (i.e., counting the coins).
Although counting the money in a child’s piggy bank is a simple example, it illustrates the fact that a lot of quantitative data interpretation depends on having a particular value or set of values in mind against which your analysis will be compared. The number of calories or the amount of sodium you might consider healthy will allow you to determine whether a particular food is healthy. At the same time, your monthly income will inform whether you see a certain product as cheap or expensive. In any case, interpreting quantitative data often starts with having a set theory or prediction that you apply to the data.
Data interpretation refers to the process of examining and reviewing data for the purpose of describing the aspects of a phenomenon or concept. Qualitative research seldom has numerical data arising from data collection; instead, qualities of a phenomenon are often generated from this research. With this in mind, the role of data interpretation is to persuade research audiences as to what qualities in a particular concept or phenomenon are significant.
While there are many different ways to analyze complex data that is qualitative in nature, here is a simple process for data interpretation that might be persuasive to your research audience:
- Describe data in explicit detail - what is happening in the data?
- Describe the meaning of the data - why is it important?
- Describe the significance - what can this meaning be used for?
Qualitative data interpretation method
Coding remains one of the most important data interpretation methods in qualitative research. Coding provides a structure to the data that facilitates empirical analysis. Without this coding, a researcher can give their impression of what the data means but may not be able to persuade their audience with the sufficient evidence that structured data can provide.
Ultimately, coding reduces the breadth of the collected data to make it more manageable. Instead of thousands of lines of raw data, effective coding can produce a couple of dozen codes that can be analyzed for frequency or used to organize categorical data along the lines of themes or patterns. Analyzing qualitative data through coding involves closely looking at the data and summarizing data segments into short but descriptive phrases. These phrases or codes, when applied throughout entire data sets, can help to restructure the data in a manner that allows for easier analysis or greater clarity as to the meaning of the data relevant to the research inquiry.
Code-Document Analysis
A comparison of data sets can be useful to interpret patterns in the data. Code-Document Analysis in ATLAS.ti looks for code frequencies in particular documents or document groups. This is useful for many tasks, such as interpreting perspectives across multiple interviews or survey records. Where each document represents the opinions of a distinct person, how do perspectives differ from person to person? Understanding these differences, in this case, starts with determining where the interpretive codes in your project are applied.
Software is great at accomplishing mechanical tasks that would otherwise take time and effort better spent on analysis. Such tasks include searching for words or phrases across documents, completing complicated queries to organize the relevant information in one place, and employing statistical methods to allow the researcher to reach relevant conclusions about their data. What technology cannot do is interpret data for you; it can reorganize the data in a way that allows you to more easily reach a conclusion as to the insights you can draw from the research, but ultimately it is up to you to make the final determination as to the meaning of the patterns in the data.
This is true whether you are engaged in qualitative or quantitative research. Whether you are trying to define "happiness" or "hot" (because a "hot day" will mean different things to different people, regardless of the number representing the temperature), it is inevitably your decision to interpret the data you're given, regardless of the help a computer may provide to you.
Think of qualitative data analysis software like ATLAS.ti as an assistant to support you through the research process so you can identify key insights from your data, as opposed to identifying those insights for you. This is especially preferable in the social sciences, where human interaction and cultural practices are subjectively and socially constructed in a way that only humans can adequately understand. Human interpretation of qualitative data is not merely unavoidable; in the social sciences, it is an outright necessity.

With this in mind, ATLAS.ti has several tools that can help make interpreting data easier and more insightful. These tools can facilitate the reporting and visualization of the data analysis for your benefit and the benefit of your research audience.
Code Co-Occurrence Analysis
The overlapping of codes in qualitative data is a useful starting point to determine relationships between phenomena. ATLAS.ti's Code Co-Occurrence Analysis tool helps researchers identify relationships between codes so that data interpretation regarding any possible connections can contribute to a greater understanding of the data.
Memos are an important part of any research, which is why ATLAS.ti provides a space separate from your data and codes for research notes and reflection memos. Especially in the social sciences or any field that explores socially constructed concepts, a reflective memo can provide essential documentation of how researchers are involved in data gathering and data interpretation.
With memos, the steps of analysis can be traced, and the entire process is open to view. Detailed documentation of the data analysis and data interpretation process can also facilitate the reporting and visualization of research when it comes time to share the research with audiences.

In research, the main objective in explicitly conducting and detailing your data interpretation process is to report your research in a manner that is meaningful and persuasive to your audience. Where possible, researchers benefit from visualizing their data interpretation to provide research audiences with the necessary clarity to understand the findings of the research.
Ultimately, the various data analysis processes you employ should lead to some form of reporting where the research audience can easily understand the data interpretation. Otherwise, data interpretation holds no value if it is not understood, let alone accepted, by the research audience.
Data visualization tools in ATLAS.ti
ATLAS.ti has a number of tools that can assist with creating illustrations that contribute to explaining your data interpretation to your research audience.

A TreeMap of your codes can be a useful visualization if you are conducting a thematic analysis of your data. Codes in ATLAS.ti can be marked by different colors, which is illustrative if you use colors to distinguish between different themes in your research. As codes are applied to your data, the more frequently occurring codes take up more space in the TreeMap, allowing you to examine which codes and, by use of colors, which themes are more and less apparent and help you generate theory.
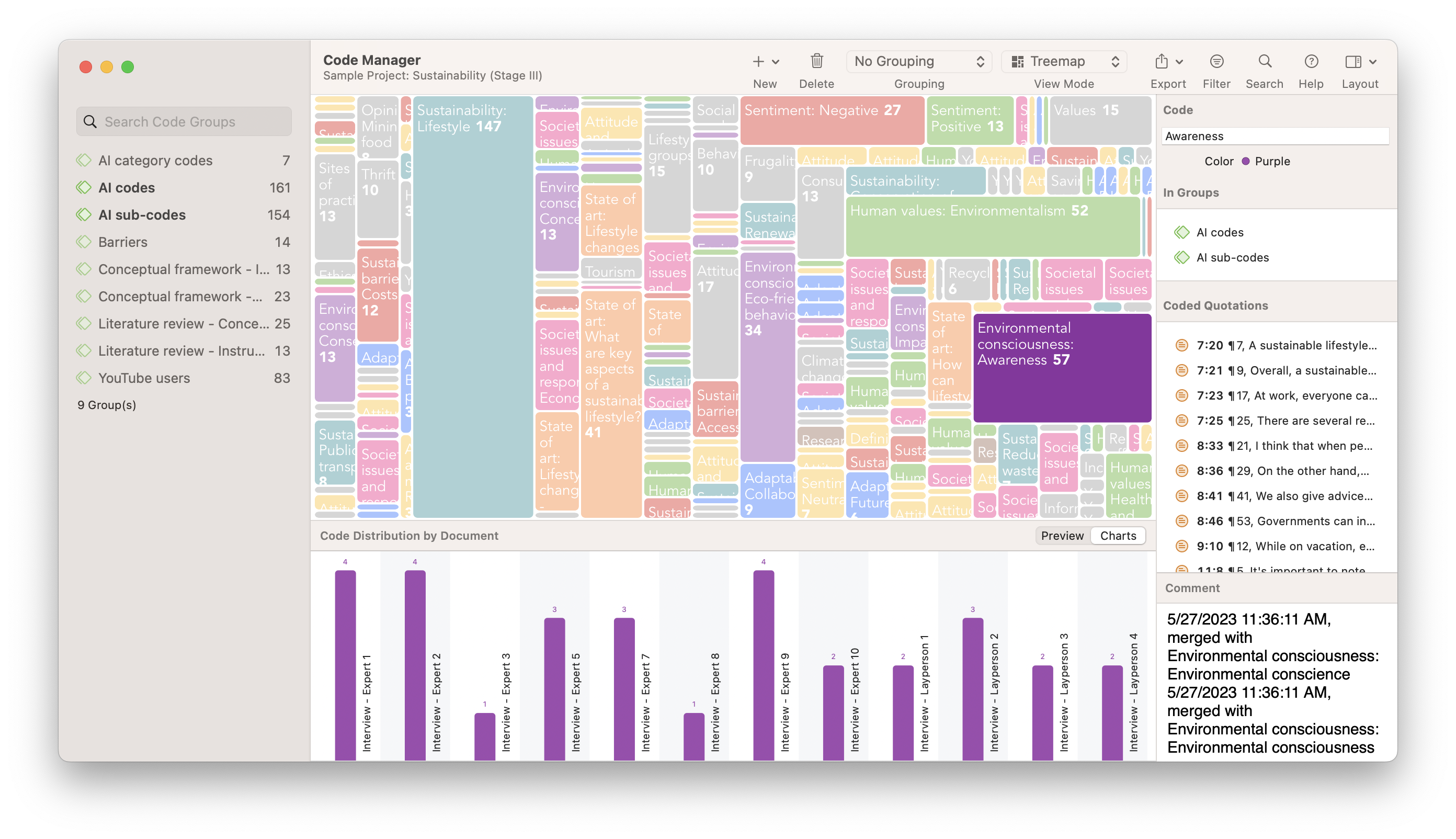
Sankey diagrams
The Code Co-Occurrence and Code-Document Analyses in ATLAS.ti can produce tables, graphs, and also Sankey diagrams, which are useful for visualizing the relative relationships between different codes or between codes and documents. While numerical data generated for tables can tell one story of your data interpretation, the visual information in a Sankey diagram, where higher frequencies are represented by thicker lines, can be particularly persuasive to your research audience.
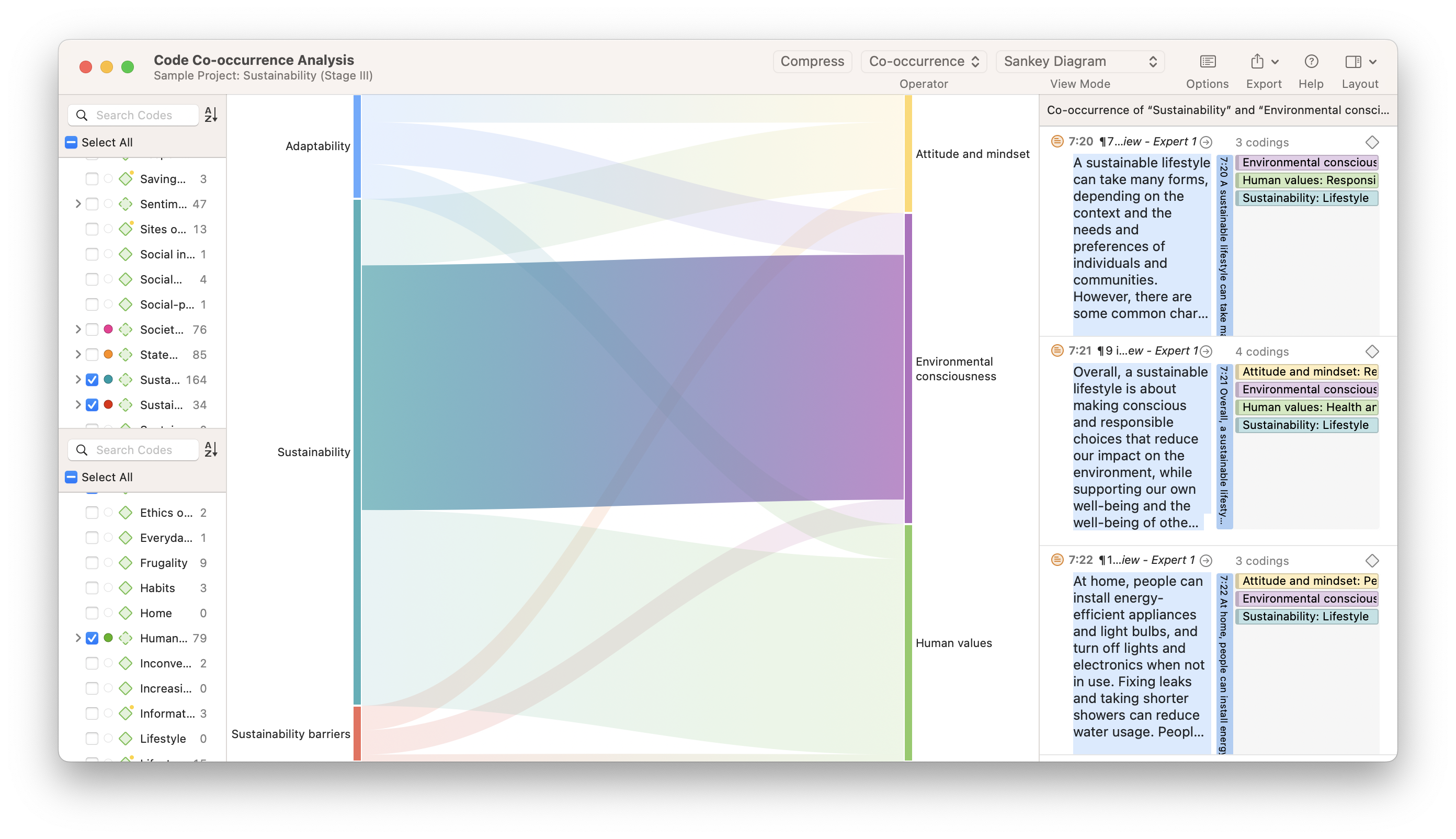
When it comes time to report actionable insights contributing to a theory or conceptualization, you can benefit from a visualization of the theory you have generated from your data interpretation. Networks are made up of elements of your project, usually codes, but also other elements such as documents, code groups, document groups, quotations, and memos. Researchers can then define links between these elements to illustrate connections that arise from your data interpretation.
Turn data into insights with ATLAS.ti
Powerful tools to help you interpret data at your fingertips. Click here for a free trial.
Data Interpretation: Definition, Method, Benefits & Examples
In today's digital world, any business owner understands the importance of collecting, analyzing, and interpreting data. Some statistical methods are always employed in this process. Continue reading to learn how to make the most of your data.

Apr 20 2021 ● 7 min read

Table of Contents
What is data interpretation, data interpretation examples, steps of data interpretation, what should users question during data interpretation, data interpretation methods, qualitative data interpretation method, quantitative data interpretation method, benefits of data interpretation.
Syracuse University defined data interpretation as the process of assigning meaning to the collected information and determining the conclusions, significance, and implications of the findings. In other words, normalizing data, aka giving meaning to the collected 'cleaned' raw data .
Data interpretation is the final step of data analysis . This is where you turn results into actionable items. To better understand it, here are 2 instances of interpreting data:

Let's say you've got four age groups of the user base. So a company can notice which age group is most engaged with their content or product. Based on bar charts or pie charts, they can either: develop a marketing strategy to make their product more appealing to non-involved groups or develop an outreach strategy that expands on their core user base.
Another case of data interpretation is how companies use recruitment CRM . They use it to source, track, and manage their entire hiring pipeline to see how they can automate their workflow better. This helps companies save time and improve productivity.

Interpreting data: Performance by gender
Data interpretation is conducted in 4 steps:
- Assembling the information you need (like bar graphs and pie charts);
- Developing findings or isolating the most relevant inputs;
- Developing conclusions;
- Coming up with recommendations or actionable solutions.
Considering how these findings dictate the course of action, data analysts must be accurate with their conclusions and examine the raw data from multiple angles. Different variables may allude to various problems, so having the ability to backtrack data and repeat the analysis using different templates is an integral part of a successful business strategy.
To interpret data accurately, users should be aware of potential pitfalls present within this process. You need to ask yourself if you are mistaking correlation for causation. If two things occur together, it does not indicate that one caused the other.

The 2nd thing you need to be aware of is your own confirmation bias . This occurs when you try to prove a point or a theory and focus only on the patterns or findings that support that theory while discarding those that do not.
The 3rd problem is irrelevant data. To be specific, you need to make sure that the data you have collected and analyzed is relevant to the problem you are trying to solve.
Data analysts or data analytics tools help people make sense of the numerical data that has been aggregated, transformed, and displayed. There are two main methods for data interpretation: quantitative and qualitative.
This is a method for breaking down or analyzing so-called qualitative data, also known as categorical data. It is important to note that no bar graphs or line charts are used in this method. Instead, they rely on text. Because qualitative data is collected through person-to-person techniques, it isn't easy to present using a numerical approach.
Surveys are used to collect data because they allow you to assign numerical values to answers, making them easier to analyze. If we rely solely on the text, it would be a time-consuming and error-prone process. This is why it must be transformed .
This data interpretation is applied when we are dealing with quantitative or numerical data. Since we are dealing with numbers, the values can be displayed in a bar chart or pie chart. There are two main types: Discrete and Continuous. Moreover, numbers are easier to analyze since they involve statistical modeling techniques like mean and standard deviation.
Mean is an average value of a particular data set obtained or calculated by dividing the sum of the values within that data set by the number of values within that same set.
Standard Deviation is a technique is used to ascertain how responses align with or deviate from the average value or mean. It relies on the meaning to describe the consistency of the replies within a particular data set. You can use this when calculating the average pay for a certain profession and then displaying the upper and lower values in the data set.
As stated, some tools can do this automatically, especially when it comes to quantitative data. Whatagraph is one such tool as it can aggregate data from multiple sources using different system integrations. It will also automatically organize and analyze that which will later be displayed in pie charts, line charts, or bar charts, however you wish.

Multiple data interpretation benefits explain its significance within the corporate world, medical industry, and financial industry:

Anticipating needs and identifying trends . Data analysis provides users with relevant insights that they can use to forecast trends. It would be based on customer concerns and expectations .
For example, a large number of people are concerned about privacy and the leakage of personal information . Products that provide greater protection and anonymity are more likely to become popular.

Clear foresight. Companies that analyze and aggregate data better understand their own performance and how consumers perceive them. This provides them with a better understanding of their shortcomings, allowing them to work on solutions that will significantly improve their performance.
Published on Apr 20 2021
Indrė is a copywriter at Whatagraph with extensive experience in search engine optimization and public relations. She holds a degree in International Relations, while her professional background includes different marketing and advertising niches. She manages to merge marketing strategy and public speaking while educating readers on how to automate their businesses.

Related articles

Data analytics · 7 mins
Data Blending: Clear Insights for Data-Driven Marketing

Blending Data in Looker Studio? Here’s a Faster and More Reliable Alternative

Marketing Data Transformation: How to Organize Unstructured Marketing Data?

Top 15 Data Transformation Tools for Marketers in 2024

KPIs & metrics · 7 mins
15 Inspiring TikTok Campaigns: Success Stories To Learn From

Product news · 2 mins
Whatagraph Expands to Become a One-Stop Marketing Data Platform
Get marketing insights direct to your inbox.
By submitting this form, you agree to our privacy policy
- Submit your COVID-19 Pandemic Research
- Research Leap Manual on Academic Writing
- Conduct Your Survey Easily
- Research Tools for Primary and Secondary Research
- Useful and Reliable Article Sources for Researchers
- Tips on writing a Research Paper
- Stuck on Your Thesis Statement?
- Out of the Box
- How to Organize the Format of Your Writing
- Argumentative Versus Persuasive. Comparing the 2 Types of Academic Writing Styles
- Very Quick Academic Writing Tips and Advices
- Top 4 Quick Useful Tips for Your Introduction
- Have You Chosen the Right Topic for Your Research Paper?
- Follow These Easy 8 Steps to Write an Effective Paper
- 7 Errors in your thesis statement
- How do I even Write an Academic Paper?
- Useful Tips for Successful Academic Writing
Collaborative Governance in Government Administration in the Field of State Security Along the Republic of Indonesia (RI)-Malaysia Border Area
It service management system practices in kenya, introduction economic and psychological well-being during covid-19 pandemic in albania, a need for sustainability.
- Designing a Framework for Assessing Agripreneurship Action for the Green Scheme Irrigation Projects, Namibia
- The Potential Utilisation of Artificial Intelligence (AI) in Enterprises
- Case Study – Developing a National Research and Evidence Base for The Health and Wellbeing Chapter of The Welsh Government’s 2023 Innovation Strategy for Wales
- The Impacts of Technology Innovation on Customer Satisfaction, Employee and Leadership Commitment in CSR Practice
- Current Developments on the Chinese Real Estate Market
- Slide Share
Understanding statistical analysis: A beginner’s guide to data interpretation
Statistical analysis is a crucial part of research in many fields. It is used to analyze data and draw conclusions about the population being studied. However, statistical analysis can be complex and intimidating for beginners. In this article, we will provide a beginner’s guide to statistical analysis and data interpretation, with the aim of helping researchers understand the basics of statistical methods and their application in research.
What is Statistical Analysis?
Statistical analysis is a collection of methods used to analyze data. These methods are used to summarize data, make predictions, and draw conclusions about the population being studied. Statistical analysis is used in a variety of fields, including medicine, social sciences, economics, and more.
Statistical analysis can be broadly divided into two categories: descriptive statistics and inferential statistics. Descriptive statistics are used to summarize data, while inferential statistics are used to draw conclusions about the population based on a sample of data.
Descriptive Statistics
Descriptive statistics are used to summarize data. This includes measures such as the mean, median, mode, and standard deviation. These measures provide information about the central tendency and variability of the data. For example, the mean provides information about the average value of the data, while the standard deviation provides information about the variability of the data.
Inferential Statistics
Inferential statistics are used to draw conclusions about the population based on a sample of data. This involves making inferences about the population based on the sample data. For example, a researcher might use inferential statistics to test whether there is a significant difference between two groups in a study.
Statistical Analysis Techniques
There are many different statistical analysis techniques that can be used in research. Some of the most common techniques include:
Correlation Analysis: This involves analyzing the relationship between two or more variables.
Regression Analysis: This involves analyzing the relationship between a dependent variable and one or more independent variables.
T-Tests: This is a statistical test used to compare the means of two groups.
Analysis of Variance (ANOVA): This is a statistical test used to compare the means of three or more groups.
Chi-Square Test: This is a statistical test used to determine whether there is a significant association between two categorical variables.
Data Interpretation
Once data has been analyzed, it must be interpreted. This involves making sense of the data and drawing conclusions based on the results of the analysis. Data interpretation is a crucial part of statistical analysis, as it is used to draw conclusions and make recommendations based on the data.
When interpreting data, it is important to consider the context in which the data was collected. This includes factors such as the sample size, the sampling method, and the population being studied. It is also important to consider the limitations of the data and the statistical methods used.
Best Practices for Statistical Analysis
To ensure that statistical analysis is conducted correctly and effectively, there are several best practices that should be followed. These include:
Clearly define the research question : This is the foundation of the study and will guide the analysis.
Choose appropriate statistical methods: Different statistical methods are appropriate for different types of data and research questions.
Use reliable and valid data: The data used for analysis should be reliable and valid. This means that it should accurately represent the population being studied and be collected using appropriate methods.
Ensure that the data is representative: The sample used for analysis should be representative of the population being studied. This helps to ensure that the results of the analysis are applicable to the population.
Follow ethical guidelines : Researchers should follow ethical guidelines when conducting research. This includes obtaining informed consent from participants, protecting their privacy, and ensuring that the study does not cause harm.
Statistical analysis and data interpretation are essential tools for any researcher. Whether you are conducting research in the social sciences, natural sciences, or humanities, understanding statistical methods and interpreting data correctly is crucial to drawing accurate conclusions and making informed decisions. By following the best practices for statistical analysis and data interpretation outlined in this article, you can ensure that your research is based on sound statistical principles and is therefore more credible and reliable. Remember to start with a clear research question, use appropriate statistical methods, and always interpret your data in context. With these guidelines in mind, you can confidently approach statistical analysis and data interpretation and make meaningful contributions to your field of study.
Suggested Articles

Types of data analysis software In research work, received cluster of results and dispersion in…

How to use quantitative data analysis software Data analysis differentiates the scientist from the…

Using free research Qualitative Data Analysis Software is a great way to save money, highlight…

Research is a vital part of advancing knowledge in any field, but it must be…
Related Posts

Comments are closed.
- 13 min read
What is Data Interpretation? Methods, Examples & Tools

What is Data Interpretation?
- Importance of Data Interpretation in Today's World
Types of Data Interpretation
Quantitative data interpretation, qualitative data interpretation, mixed methods data interpretation, methods of data interpretation, descriptive statistics, inferential statistics, visualization techniques, benefits of data interpretation, data interpretation process, data interpretation use cases, data interpretation tools, data interpretation challenges and solutions, overcoming bias in data, dealing with missing data, addressing data privacy concerns, data interpretation examples, sales trend analysis, customer segmentation, predictive maintenance, fraud detection, data interpretation best practices, maintaining data quality, choosing the right tools, effective communication of results, ongoing learning and development, data interpretation tips.
Data interpretation is the process of making sense of data and turning it into actionable insights. With the rise of big data and advanced technologies, it has become more important than ever to be able to effectively interpret and understand data.
In today's fast-paced business environment, companies rely on data to make informed decisions and drive growth. However, with the sheer volume of data available, it can be challenging to know where to start and how to make the most of it.
This guide provides a comprehensive overview of data interpretation, covering everything from the basics of what it is to the benefits and best practices.
Data interpretation refers to the process of taking raw data and transforming it into useful information. This involves analyzing the data to identify patterns, trends, and relationships, and then presenting the results in a meaningful way. Data interpretation is an essential part of data analysis, and it is used in a wide range of fields, including business, marketing, healthcare, and many more.
Importance of Data Interpretation in Today's World
Data interpretation is critical to making informed decisions and driving growth in today's data-driven world. With the increasing availability of data, companies can now gain valuable insights into their operations, customer behavior, and market trends. Data interpretation allows businesses to make informed decisions, identify new opportunities, and improve overall efficiency.
There are three main types of data interpretation: quantitative, qualitative, and mixed methods.
Quantitative data interpretation refers to the process of analyzing numerical data. This type of data is often used to measure and quantify specific characteristics, such as sales figures, customer satisfaction ratings, and employee productivity.
Qualitative data interpretation refers to the process of analyzing non-numerical data, such as text, images, and audio. This data type is often used to gain a deeper understanding of customer attitudes and opinions and to identify patterns and trends.
Mixed methods data interpretation combines both quantitative and qualitative data to provide a more comprehensive understanding of a particular subject. This approach is particularly useful when analyzing data that has both numerical and non-numerical components, such as customer feedback data.
There are several data interpretation methods, including descriptive statistics, inferential statistics, and visualization techniques.
Descriptive statistics involve summarizing and presenting data in a way that makes it easy to understand. This can include calculating measures such as mean, median, mode, and standard deviation.
Inferential statistics involves making inferences and predictions about a population based on a sample of data. This type of data interpretation involves the use of statistical models and algorithms to identify patterns and relationships in the data.
Visualization techniques involve creating visual representations of data, such as graphs, charts, and maps. These techniques are particularly useful for communicating complex data in an easy-to-understand manner and identifying data patterns and trends.

When sharing a Google Sheets spreadsheet Google usually tries to share the entire document. Here’s how to share only one tab instead.
Data interpretation plays a crucial role in decision-making and helps organizations make informed choices. There are numerous benefits of data interpretation, including:
- Improved decision-making: Data interpretation provides organizations with the information they need to make informed decisions. By analyzing data, organizations can identify trends, patterns, and relationships that they may not have been able to see otherwise.
- Increased efficiency: By automating the data interpretation process, organizations can save time and improve their overall efficiency. With the right tools and methods, data interpretation can be completed quickly and accurately, providing organizations with the information they need to make decisions more efficiently.
- Better collaboration: Data interpretation can help organizations work more effectively with others, such as stakeholders, partners, and clients. By providing a common understanding of the data and its implications, organizations can collaborate more effectively and make better decisions.
- Increased accuracy: Data interpretation helps to ensure that data is accurate and consistent, reducing the risk of errors and miscommunication. By using data interpretation techniques, organizations can identify errors and inconsistencies in their data, making it possible to correct them and ensure the accuracy of their information.
- Enhanced transparency: Data interpretation can also increase transparency, helping organizations demonstrate their commitment to ethical and responsible data management. By providing clear and concise information, organizations can build trust and credibility with their stakeholders.
- Better resource allocation: Data interpretation can help organizations make better decisions about resource allocation. By analyzing data, organizations can identify areas where they are spending too much time or money and make adjustments to optimize their resources.
- Improved planning and forecasting: Data interpretation can also help organizations plan for the future. By analyzing historical data, organizations can identify trends and patterns that inform their forecasting and planning efforts.
Data interpretation is a process that involves several steps, including:
- Data collection: The first step in data interpretation is to collect data from various sources, such as surveys, databases, and websites. This data should be relevant to the issue or problem the organization is trying to solve.
- Data preparation: Once data is collected, it needs to be prepared for analysis. This may involve cleaning the data to remove errors, missing values, or outliers. It may also include transforming the data into a more suitable format for analysis.
- Data analysis: The next step is to analyze the data using various techniques, such as statistical analysis, visualization, and modeling. This analysis should be focused on uncovering trends, patterns, and relationships in the data.
- Data interpretation: Once the data has been analyzed, it needs to be interpreted to determine what the results mean. This may involve identifying key insights, drawing conclusions, and making recommendations.
- Data communication: The final step in the data interpretation process is to communicate the results and insights to others. This may involve creating visualizations, reports, or presentations to share the results with stakeholders.
Data interpretation can be applied in a variety of settings and industries. Here are a few examples of how data interpretation can be used:
- Marketing: Marketers use data interpretation to analyze customer behavior, preferences, and trends to inform marketing strategies and campaigns.
- Healthcare: Healthcare professionals use data interpretation to analyze patient data, including medical histories and test results, to diagnose and treat illnesses.
- Financial Services: Financial services companies use data interpretation to analyze financial data, such as investment performance, to inform investment decisions and strategies.
- Retail: Retail companies use data interpretation to analyze sales data, customer behavior, and market trends to inform merchandising and pricing strategies.
- Manufacturing: Manufacturers use data interpretation to analyze production data, such as machine performance and inventory levels, to inform production and inventory management decisions.
These are just a few examples of how data interpretation can be applied in various settings. The possibilities are endless, and data interpretation can provide valuable insights in any industry where data is collected and analyzed.
Data interpretation is a crucial step in the data analysis process, and the right tools can make a significant difference in accuracy and efficiency. Here are a few tools that can help you with data interpretation:
- Share parts of your spreadsheet, including sheets or even cell ranges, with different collaborators or stakeholders.
- Review and approve edits by collaborators to their respective sheets before merging them back with your master spreadsheet.
- Integrate popular tools and connect your tech stack to sync data from different sources, giving you a timely, holistic view of your data.
- Google Sheets: Google Sheets is a free, web-based spreadsheet application that allows users to create, edit, and format spreadsheets. It provides a range of features for data interpretation, including functions, charts, and pivot tables.
- Microsoft Excel: Microsoft Excel is a spreadsheet software widely used for data interpretation. It provides various functions and features to help you analyze and interpret data, including sorting, filtering, pivot tables, and charts.
- Tableau: Tableau is a data visualization tool that helps you see and understand your data. It allows you to connect to various data sources and create interactive dashboards and visualizations to communicate insights.
- Power BI: Power BI is a business analytics service that provides interactive visualizations and business intelligence capabilities with an easy interface for end users to create their own reports and dashboards.
- R: R is a programming language and software environment for statistical computing and graphics. It is widely used by statisticians, data scientists, and researchers to analyze and interpret data.
Each of these tools has its strengths and weaknesses, and the right tool for you will depend on your specific needs and requirements. Consider the size and complexity of your data, the analysis methods you need to use, and the level of customization you require, before making a decision.

If you work with important data in Google Sheets, you probably want an extra layer of protection. Here's how you can password protect a Google Sheet
Data interpretation can be a complex and challenging process, but there are several solutions that can help overcome some of the most common difficulties.
Data interpretation can often be biased based on the data sources and the people who interpret it. It is important to eliminate these biases to get a clear and accurate understanding of the data. This can be achieved by diversifying the data sources, involving multiple stakeholders in the data interpretation process, and regularly reviewing the data interpretation methodology.
Missing data can often result in inaccuracies in the data interpretation process. To overcome this challenge, data scientists can use imputation methods to fill in missing data or use statistical models that can account for missing data.
Data privacy is a crucial concern in today's data-driven world. To address this, organizations should ensure that their data interpretation processes align with data privacy regulations and that the data being analyzed is adequately secured.
Data interpretation is used in a variety of industries and for a range of purposes. Here are a few examples:
Sales trend analysis is a common use of data interpretation in the business world. This type of analysis involves looking at sales data over time to identify trends and patterns, which can then be used to make informed business decisions.
Customer segmentation is a data interpretation technique that categorizes customers into segments based on common characteristics. This can be used to create more targeted marketing campaigns and to improve customer engagement.
Predictive maintenance is a data interpretation technique that uses machine learning algorithms to predict when equipment is likely to fail. This can help organizations proactively address potential issues and reduce downtime.
Fraud detection is a use case for data interpretation involving data and machine learning algorithms to identify patterns and anomalies that may indicate fraudulent activity.
To ensure that data interpretation processes are as effective and accurate as possible, it is recommended to follow some best practices.
Data quality is critical to the accuracy of data interpretation. To maintain data quality, organizations should regularly review and validate their data, eliminate data biases, and address missing data.
Choosing the right data interpretation tools is crucial to the success of the data interpretation process. Organizations should consider factors such as cost, compatibility with existing tools and processes, and the complexity of the data to be analyzed when choosing the right data interpretation tool. Layer, an add-on that equips teams with the tools to increase efficiency and data quality in their processes on top of Google Sheets, is an excellent choice for organizations looking to optimize their data interpretation process.
Data interpretation results need to be communicated effectively to stakeholders in a way they can understand. This can be achieved by using visual aids such as charts and graphs and presenting the results clearly and concisely.
The world of data interpretation is constantly evolving, and organizations must stay up to date with the latest developments and best practices. Ongoing learning and development initiatives, such as attending workshops and conferences, can help organizations stay ahead of the curve.
Regardless of the data interpretation method used, following best practices can help ensure accurate and reliable results. These best practices include:
- Validate data sources: It is essential to validate the data sources used to ensure they are accurate, up-to-date, and relevant. This helps to minimize the potential for errors in the data interpretation process.
- Use appropriate statistical techniques: The choice of statistical methods used for data interpretation should be suitable for the type of data being analyzed. For example, regression analysis is often used for analyzing trends in large data sets, while chi-square tests are used for categorical data.
- Graph and visualize data: Graphical representations of data can help to quickly identify patterns and trends. Visualization tools like histograms, scatter plots, and bar graphs can make the data more understandable and easier to interpret.
- Document and explain results: Results from data interpretation should be documented and presented in a clear and concise manner. This includes providing context for the results and explaining how they were obtained.
- Use a robust data interpretation tool: Data interpretation tools can help to automate the process and minimize the risk of errors. However, choosing a reliable, user-friendly tool that provides the features and functionalities needed to support the data interpretation process is vital.
Data interpretation is a crucial aspect of data analysis and enables organizations to turn large amounts of data into actionable insights. The guide covered the definition, importance, types, methods, benefits, process, analysis, tools, use cases, and best practices of data interpretation.
As technology continues to advance, the methods and tools used in data interpretation will also evolve. Predictive analytics and artificial intelligence will play an increasingly important role in data interpretation as organizations strive to automate and streamline their data analysis processes. In addition, big data and the Internet of Things (IoT) will lead to the generation of vast amounts of data that will need to be analyzed and interpreted effectively.
Data interpretation is a critical skill that enables organizations to make informed decisions based on data. It is essential that organizations invest in data interpretation and the development of their in-house data interpretation skills, whether through training programs or the use of specialized tools like Layer. By staying up-to-date with the latest trends and best practices in data interpretation, organizations can maximize the value of their data and drive growth and success.
Hady has a passion for tech, marketing, and spreadsheets. Besides his Computer Science degree, he has vast experience in developing, launching, and scaling content marketing processes at SaaS startups.
Layer is now Sheetgo
Automate your procesess on top of spreadsheets.

Research Methods
- Getting Started
- What is Research Design?
- Research Approach
- Research Methodology
- Data Collection
- Data Analysis & Interpretation
- Population & Sampling
- Theories, Theoretical Perspective & Theoretical Framework
- Useful Resources
Further Resources

Data Analysis & Interpretation
- Quantitative Data
Qualitative Data
- Mixed Methods
You will need to tidy, analyse and interpret the data you collected to give meaning to it, and to answer your research question. Your choice of methodology points the way to the most suitable method of analysing your data.

If the data is numeric you can use a software package such as SPSS, Excel Spreadsheet or “R” to do statistical analysis. You can identify things like mean, median and average or identify a causal or correlational relationship between variables.
The University of Connecticut has useful information on statistical analysis.
If your research set out to test a hypothesis your research will either support or refute it, and you will need to explain why this is the case. You should also highlight and discuss any issues or actions that may have impacted on your results, either positively or negatively. To fully contribute to the body of knowledge in your area be sure to discuss and interpret your results within the context of your research and the existing literature on the topic.
Data analysis for a qualitative study can be complex because of the variety of types of data that can be collected. Qualitative researchers aren’t attempting to measure observable characteristics, they are often attempting to capture an individual’s interpretation of a phenomena or situation in a particular context or setting. This data could be captured in text from an interview or focus group, a movie, images, or documents. Analysis of this type of data is usually done by analysing each artefact according to a predefined and outlined criteria for analysis and then by using a coding system. The code can be developed by the researcher before analysis or the researcher may develop a code from the research data. This can be done by hand or by using thematic analysis software such as NVivo.
Interpretation of qualitative data can be presented as a narrative. The themes identified from the research can be organised and integrated with themes in the existing literature to give further weight and meaning to the research. The interpretation should also state if the aims and objectives of the research were met. Any shortcomings with research or areas for further research should also be discussed (Creswell,2009)*.
For further information on analysing and presenting qualitative date, read this article in Nature .
Mixed Methods Data
Data analysis for mixed methods involves aspects of both quantitative and qualitative methods. However, the sequencing of data collection and analysis is important in terms of the mixed method approach that you are taking. For example, you could be using a convergent, sequential or transformative model which directly impacts how you use different data to inform, support or direct the course of your study.
The intention in using mixed methods is to produce a synthesis of both quantitative and qualitative information to give a detailed picture of a phenomena in a particular context or setting. To fully understand how best to produce this synthesis it might be worth looking at why researchers choose this method. Bergin**(2018) states that researchers choose mixed methods because it allows them to triangulate, illuminate or discover a more diverse set of findings. Therefore, when it comes to interpretation you will need to return to the purpose of your research and discuss and interpret your data in that context. As with quantitative and qualitative methods, interpretation of data should be discussed within the context of the existing literature.
Bergin’s book is available in the Library to borrow. Bolton LTT collection 519.5 BER
Creswell’s book is available in the Library to borrow. Bolton LTT collection 300.72 CRE
For more information on data analysis look at Sage Research Methods database on the library website.
*Creswell, John W.(2009) Research design: qualitative, and mixed methods approaches. Sage, Los Angeles, pp 183
**Bergin, T (2018), Data analysis: quantitative, qualitative and mixed methods. Sage, Los Angeles, pp182
- << Previous: Data Collection
- Next: Population & Sampling >>
- Last Updated: Sep 7, 2023 3:09 PM
- URL: https://tudublin.libguides.com/research_methods
Data Analysis and Interpretation: Revealing and explaining trends
by Anne E. Egger, Ph.D., Anthony Carpi, Ph.D.
Listen to this reading
Did you know that scientists don't always agree on what data mean? Different scientists can look at the same set of data and come up with different explanations for it, and disagreement among scientists doesn't point to bad science.
Data collection is the systematic recording of information; data analysis involves working to uncover patterns and trends in datasets; data interpretation involves explaining those patterns and trends.
Scientists interpret data based on their background knowledge and experience; thus, different scientists can interpret the same data in different ways.
By publishing their data and the techniques they used to analyze and interpret those data, scientists give the community the opportunity to both review the data and use them in future research.
Before you decide what to wear in the morning, you collect a variety of data: the season of the year, what the forecast says the weather is going to be like, which clothes are clean and which are dirty, and what you will be doing during the day. You then analyze those data . Perhaps you think, "It's summer, so it's usually warm." That analysis helps you determine the best course of action, and you base your apparel decision on your interpretation of the information. You might choose a t-shirt and shorts on a summer day when you know you'll be outside, but bring a sweater with you if you know you'll be in an air-conditioned building.
Though this example may seem simplistic, it reflects the way scientists pursue data collection, analysis , and interpretation . Data (the plural form of the word datum) are scientific observations and measurements that, once analyzed and interpreted, can be developed into evidence to address a question. Data lie at the heart of all scientific investigations, and all scientists collect data in one form or another. The weather forecast that helped you decide what to wear, for example, was an interpretation made by a meteorologist who analyzed data collected by satellites. Data may take the form of the number of bacteria colonies growing in soup broth (see our Experimentation in Science module), a series of drawings or photographs of the different layers of rock that form a mountain range (see our Description in Science module), a tally of lung cancer victims in populations of cigarette smokers and non-smokers (see our Comparison in Science module), or the changes in average annual temperature predicted by a model of global climate (see our Modeling in Science module).
Scientific data collection involves more care than you might use in a casual glance at the thermometer to see what you should wear. Because scientists build on their own work and the work of others, it is important that they are systematic and consistent in their data collection methods and make detailed records so that others can see and use the data they collect.
But collecting data is only one step in a scientific investigation, and scientific knowledge is much more than a simple compilation of data points. The world is full of observations that can be made, but not every observation constitutes a useful piece of data. For example, your meteorologist could record the outside air temperature every second of the day, but would that make the forecast any more accurate than recording it once an hour? Probably not. All scientists make choices about which data are most relevant to their research and what to do with those data: how to turn a collection of measurements into a useful dataset through processing and analysis , and how to interpret those analyzed data in the context of what they already know. The thoughtful and systematic collection, analysis, and interpretation of data allow them to be developed into evidence that supports scientific ideas, arguments, and hypotheses .
Data collection, analysis , and interpretation: Weather and climate
The weather has long been a subject of widespread data collection, analysis , and interpretation . Accurate measurements of air temperature became possible in the mid-1700s when Daniel Gabriel Fahrenheit invented the first standardized mercury thermometer in 1714 (see our Temperature module). Air temperature, wind speed, and wind direction are all critical navigational information for sailors on the ocean, but in the late 1700s and early 1800s, as sailing expeditions became common, this information was not easy to come by. The lack of reliable data was of great concern to Matthew Fontaine Maury, the superintendent of the Depot of Charts and Instruments of the US Navy. As a result, Maury organized the first international Maritime Conference , held in Brussels, Belgium, in 1853. At this meeting, international standards for taking weather measurements on ships were established and a system for sharing this information between countries was founded.
Defining uniform data collection standards was an important step in producing a truly global dataset of meteorological information, allowing data collected by many different people in different parts of the world to be gathered together into a single database. Maury's compilation of sailors' standardized data on wind and currents is shown in Figure 1. The early international cooperation and investment in weather-related data collection has produced a valuable long-term record of air temperature that goes back to the 1850s.

Figure 1: Plate XV from Maury, Matthew F. 1858. The Winds. Chapter in Explanations and Sailing Directions. Washington: Hon. Isaac Toucey.
This vast store of information is considered "raw" data: tables of numbers (dates and temperatures), descriptions (cloud cover), location, etc. Raw data can be useful in and of itself – for example, if you wanted to know the air temperature in London on June 5, 1801. But the data alone cannot tell you anything about how temperature has changed in London over the past two hundred years, or how that information is related to global-scale climate change. In order for patterns and trends to be seen, data must be analyzed and interpreted first. The analyzed and interpreted data may then be used as evidence in scientific arguments, to support a hypothesis or a theory .
Good data are a potential treasure trove – they can be mined by scientists at any time – and thus an important part of any scientific investigation is accurate and consistent recording of data and the methods used to collect those data. The weather data collected since the 1850s have been just such a treasure trove, based in part upon the standards established by Matthew Maury . These standards provided guidelines for data collections and recording that assured consistency within the dataset . At the time, ship captains were able to utilize the data to determine the most reliable routes to sail across the oceans. Many modern scientists studying climate change have taken advantage of this same dataset to understand how global air temperatures have changed over the recent past. In neither case can one simply look at the table of numbers and observations and answer the question – which route to take, or how global climate has changed. Instead, both questions require analysis and interpretation of the data.
Comprehension Checkpoint
- Data analysis: A complex and challenging process
Though it may sound straightforward to take 150 years of air temperature data and describe how global climate has changed, the process of analyzing and interpreting those data is actually quite complex. Consider the range of temperatures around the world on any given day in January (see Figure 2): In Johannesburg, South Africa, where it is summer, the air temperature can reach 35° C (95° F), and in Fairbanks, Alaska at that same time of year, it is the middle of winter and air temperatures might be -35° C (-31° F). Now consider that over huge expanses of the ocean, where no consistent measurements are available. One could simply take an average of all of the available measurements for a single day to get a global air temperature average for that day, but that number would not take into account the natural variability within and uneven distribution of those measurements.

Figure 2: Satellite image composite of average air temperatures (in degrees Celsius) across the globe on January 2, 2008 (http://www.ssec.wisc.edu/data/).
Defining a single global average temperature requires scientists to make several decisions about how to process all of those data into a meaningful set of numbers. In 1986, climatologists Phil Jones, Tom Wigley, and Peter Wright published one of the first attempts to assess changes in global mean surface air temperature from 1861 to 1984 (Jones, Wigley, & Wright, 1986). The majority of their paper – three out of five pages – describes the processing techniques they used to correct for the problems and inconsistencies in the historical data that would not be related to climate. For example, the authors note:
Early SSTs [sea surface temperatures] were measured using water collected in uninsulated, canvas buckets, while more recent data come either from insulated bucket or cooling water intake measurements, with the latter considered to be 0.3-0.7° C warmer than uninsulated bucket measurements.
Correcting for this bias may seem simple, just adding ~0.5° C to early canvas bucket measurements, but it becomes more complicated than that because, the authors continue, the majority of SST data do not include a description of what kind of bucket or system was used.
Similar problems were encountered with marine air temperature data . Historical air temperature measurements over the ocean were taken aboard ships, but the type and size of ship could affect the measurement because size "determines the height at which observations were taken." Air temperature can change rapidly with height above the ocean. The authors therefore applied a correction for ship size in their data. Once Jones, Wigley, and Wright had made several of these kinds of corrections, they analyzed their data using a spatial averaging technique that placed measurements within grid cells on the Earth's surface in order to account for the fact that there were many more measurements taken on land than over the oceans.
Developing this grid required many decisions based on their experience and judgment, such as how large each grid cell needed to be and how to distribute the cells over the Earth. They then calculated the mean temperature within each grid cell, and combined all of these means to calculate a global average air temperature for each year. Statistical techniques such as averaging are commonly used in the research process and can help identify trends and relationships within and between datasets (see our Statistics in Science module). Once these spatially averaged global mean temperatures were calculated, the authors compared the means over time from 1861 to 1984.
A common method for analyzing data that occur in a series, such as temperature measurements over time, is to look at anomalies, or differences from a pre-defined reference value . In this case, the authors compared their temperature values to the mean of the years 1970-1979 (see Figure 3). This reference mean is subtracted from each annual mean to produce the jagged lines in Figure 3, which display positive or negative anomalies (values greater or less than zero). Though this may seem to be a circular or complex way to display these data, it is useful because the goal is to show change in mean temperatures rather than absolute values.

Figure 3: The black line shows global temperature anomalies, or differences between averaged yearly temperature measurements and the reference value for the entire globe. The smooth, red line is a filtered 10-year average. (Based on Figure 5 in Jones et al., 1986).
Putting data into a visual format can facilitate additional analysis (see our Using Graphs and Visual Data module). Figure 3 shows a lot of variability in the data: There are a number of spikes and dips in global temperature throughout the period examined. It can be challenging to see trends in data that have so much variability; our eyes are drawn to the extreme values in the jagged lines like the large spike in temperature around 1876 or the significant dip around 1918. However, these extremes do not necessarily reflect long-term trends in the data.
In order to more clearly see long-term patterns and trends, Jones and his co-authors used another processing technique and applied a filter to the data by calculating a 10-year running average to smooth the data. The smooth lines in the graph represent the filtered data. The smooth line follows the data closely, but it does not reach the extreme values .
Data processing and analysis are sometimes misinterpreted as manipulating data to achieve the desired results, but in reality, the goal of these methods is to make the data clearer, not to change it fundamentally. As described above, in addition to reporting data, scientists report the data processing and analysis methods they use when they publish their work (see our Understanding Scientific Journals and Articles module), allowing their peers the opportunity to assess both the raw data and the techniques used to analyze them.
- Data interpretation: Uncovering and explaining trends in the data
The analyzed data can then be interpreted and explained. In general, when scientists interpret data, they attempt to explain the patterns and trends uncovered through analysis , bringing all of their background knowledge, experience, and skills to bear on the question and relating their data to existing scientific ideas. Given the personal nature of the knowledge they draw upon, this step can be subjective, but that subjectivity is scrutinized through the peer review process (see our Peer Review in Science module). Based on the smoothed curves, Jones, Wigley, and Wright interpreted their data to show a long-term warming trend. They note that the three warmest years in the entire dataset are 1980, 1981, and 1983. They do not go further in their interpretation to suggest possible causes for the temperature increase, however, but merely state that the results are "extremely interesting when viewed in the light of recent ideas of the causes of climate change."
- Making data available
The process of data collection, analysis , and interpretation happens on multiple scales. It occurs over the course of a day, a year, or many years, and may involve one or many scientists whose priorities change over time. One of the fundamentally important components of the practice of science is therefore the publication of data in the scientific literature (see our Utilizing the Scientific Literature module). Properly collected and archived data continues to be useful as new research questions emerge. In fact, some research involves re-analysis of data with new techniques, different ways of looking at the data, or combining the results of several studies.
For example, in 1997, the Collaborative Group on Hormonal Factors in Breast Cancer published a widely-publicized study in the prestigious medical journal The Lancet entitled, "Breast cancer and hormone replacement therapy: collaborative reanalysis of data from 51 epidemiological studies of 52,705 women with breast cancer and 108,411 women without breast cancer" (Collaborative Group on Hormonal Factors in Breast Cancer, 1997). The possible link between breast cancer and hormone replacement therapy (HRT) had been studied for years, with mixed results: Some scientists suggested a small increase of cancer risk associated with HRT as early as 1981 (Brinton et al., 1981), but later research suggested no increased risk (Kaufman et al., 1984). By bringing together results from numerous studies and reanalyzing the data together, the researchers concluded that women who were treated with hormone replacement therapy were more like to develop breast cancer. In describing why the reanalysis was used, the authors write:
The increase in the relative risk of breast cancer associated with each year of [HRT] use in current and recent users is small, so inevitably some studies would, by chance alone, show significant associations and others would not. Combination of the results across many studies has the obvious advantage of reducing such random fluctuations.
In many cases, data collected for other purposes can be used to address new questions. The initial reason for collecting weather data, for example, was to better predict winds and storms to help assure safe travel for trading ships. It is only more recently that interest shifted to long-term changes in the weather, but the same data easily contribute to answering both of those questions.
- Technology for sharing data advances science
One of the most exciting advances in science today is the development of public databases of scientific information that can be accessed and used by anyone. For example, climatic and oceanographic data , which are generally very expensive to obtain because they require large-scale operations like drilling ice cores or establishing a network of buoys across the Pacific Ocean, are shared online through several web sites run by agencies responsible for maintaining and distributing those data, such as the Carbon Dioxide Information Analysis Center run by the US Department of Energy (see Research under the Resources tab). Anyone can download those data to conduct their own analyses and make interpretations . Likewise, the Human Genome Project has a searchable database of the human genome, where researchers can both upload and download their data (see Research under the Resources tab).
The number of these widely available datasets has grown to the point where the National Institute of Standards and Technology actually maintains a database of databases. Some organizations require their participants to make their data publicly available, such as the Incorporated Research Institutions for Seismology (IRIS): The instrumentation branch of IRIS provides support for researchers by offering seismic instrumentation, equipment maintenance and training, and logistical field support for experiments . Anyone can apply to use the instruments as long as they provide IRIS with the data they collect during their seismic experiments. IRIS then makes these data available to the public.
Making data available to other scientists is not a new idea, but having those data available on the Internet in a searchable format has revolutionized the way that scientists can interact with the data, allowing for research efforts that would have been impossible before. This collective pooling of data also allows for new kinds of analysis and interpretation on global scales and over long periods of time. In addition, making data easily accessible helps promote interdisciplinary research by opening the doors to exploration by diverse scientists in many fields.
Table of Contents
- Data collection, analysis, and interpretation: Weather and climate
- Different interpretations in the scientific community
- Debate over data interpretation spurs further research
Activate glossary term highlighting to easily identify key terms within the module. Once highlighted, you can click on these terms to view their definitions.
Activate NGSS annotations to easily identify NGSS standards within the module. Once highlighted, you can click on them to view these standards.
- Search Menu
- Browse content in Arts and Humanities
- Browse content in Archaeology
- Anglo-Saxon and Medieval Archaeology
- Archaeological Methodology and Techniques
- Archaeology by Region
- Archaeology of Religion
- Archaeology of Trade and Exchange
- Biblical Archaeology
- Contemporary and Public Archaeology
- Environmental Archaeology
- Historical Archaeology
- History and Theory of Archaeology
- Industrial Archaeology
- Landscape Archaeology
- Mortuary Archaeology
- Prehistoric Archaeology
- Underwater Archaeology
- Urban Archaeology
- Zooarchaeology
- Browse content in Architecture
- Architectural Structure and Design
- History of Architecture
- Residential and Domestic Buildings
- Theory of Architecture
- Browse content in Art
- Art Subjects and Themes
- History of Art
- Industrial and Commercial Art
- Theory of Art
- Biographical Studies
- Byzantine Studies
- Browse content in Classical Studies
- Classical History
- Classical Philosophy
- Classical Mythology
- Classical Literature
- Classical Reception
- Classical Art and Architecture
- Classical Oratory and Rhetoric
- Greek and Roman Epigraphy
- Greek and Roman Law
- Greek and Roman Archaeology
- Greek and Roman Papyrology
- Late Antiquity
- Religion in the Ancient World
- Digital Humanities
- Browse content in History
- Colonialism and Imperialism
- Diplomatic History
- Environmental History
- Genealogy, Heraldry, Names, and Honours
- Genocide and Ethnic Cleansing
- Historical Geography
- History by Period
- History of Agriculture
- History of Education
- History of Emotions
- History of Gender and Sexuality
- Industrial History
- Intellectual History
- International History
- Labour History
- Legal and Constitutional History
- Local and Family History
- Maritime History
- Military History
- National Liberation and Post-Colonialism
- Oral History
- Political History
- Public History
- Regional and National History
- Revolutions and Rebellions
- Slavery and Abolition of Slavery
- Social and Cultural History
- Theory, Methods, and Historiography
- Urban History
- World History
- Browse content in Language Teaching and Learning
- Language Learning (Specific Skills)
- Language Teaching Theory and Methods
- Browse content in Linguistics
- Applied Linguistics
- Cognitive Linguistics
- Computational Linguistics
- Forensic Linguistics
- Grammar, Syntax and Morphology
- Historical and Diachronic Linguistics
- History of English
- Language Acquisition
- Language Variation
- Language Families
- Language Evolution
- Language Reference
- Lexicography
- Linguistic Theories
- Linguistic Typology
- Linguistic Anthropology
- Phonetics and Phonology
- Psycholinguistics
- Sociolinguistics
- Translation and Interpretation
- Writing Systems
- Browse content in Literature
- Bibliography
- Children's Literature Studies
- Literary Studies (Asian)
- Literary Studies (European)
- Literary Studies (Eco-criticism)
- Literary Studies (Modernism)
- Literary Studies (Romanticism)
- Literary Studies (American)
- Literary Studies - World
- Literary Studies (1500 to 1800)
- Literary Studies (19th Century)
- Literary Studies (20th Century onwards)
- Literary Studies (African American Literature)
- Literary Studies (British and Irish)
- Literary Studies (Early and Medieval)
- Literary Studies (Fiction, Novelists, and Prose Writers)
- Literary Studies (Gender Studies)
- Literary Studies (Graphic Novels)
- Literary Studies (History of the Book)
- Literary Studies (Plays and Playwrights)
- Literary Studies (Poetry and Poets)
- Literary Studies (Postcolonial Literature)
- Literary Studies (Queer Studies)
- Literary Studies (Science Fiction)
- Literary Studies (Travel Literature)
- Literary Studies (War Literature)
- Literary Studies (Women's Writing)
- Literary Theory and Cultural Studies
- Mythology and Folklore
- Shakespeare Studies and Criticism
- Browse content in Media Studies
- Browse content in Music
- Applied Music
- Dance and Music
- Ethics in Music
- Ethnomusicology
- Gender and Sexuality in Music
- Medicine and Music
- Music Cultures
- Music and Religion
- Music and Culture
- Music and Media
- Music Education and Pedagogy
- Music Theory and Analysis
- Musical Scores, Lyrics, and Libretti
- Musical Structures, Styles, and Techniques
- Musicology and Music History
- Performance Practice and Studies
- Race and Ethnicity in Music
- Sound Studies
- Browse content in Performing Arts
- Browse content in Philosophy
- Aesthetics and Philosophy of Art
- Epistemology
- Feminist Philosophy
- History of Western Philosophy
- Metaphysics
- Moral Philosophy
- Non-Western Philosophy
- Philosophy of Science
- Philosophy of Action
- Philosophy of Law
- Philosophy of Religion
- Philosophy of Language
- Philosophy of Mind
- Philosophy of Perception
- Philosophy of Mathematics and Logic
- Practical Ethics
- Social and Political Philosophy
- Browse content in Religion
- Biblical Studies
- Christianity
- East Asian Religions
- History of Religion
- Judaism and Jewish Studies
- Qumran Studies
- Religion and Education
- Religion and Health
- Religion and Politics
- Religion and Science
- Religion and Law
- Religion and Art, Literature, and Music
- Religious Studies
- Browse content in Society and Culture
- Cookery, Food, and Drink
- Cultural Studies
- Customs and Traditions
- Ethical Issues and Debates
- Hobbies, Games, Arts and Crafts
- Lifestyle, Home, and Garden
- Natural world, Country Life, and Pets
- Popular Beliefs and Controversial Knowledge
- Sports and Outdoor Recreation
- Technology and Society
- Travel and Holiday
- Visual Culture
- Browse content in Law
- Arbitration
- Browse content in Company and Commercial Law
- Commercial Law
- Company Law
- Browse content in Comparative Law
- Systems of Law
- Competition Law
- Browse content in Constitutional and Administrative Law
- Government Powers
- Judicial Review
- Local Government Law
- Military and Defence Law
- Parliamentary and Legislative Practice
- Construction Law
- Contract Law
- Browse content in Criminal Law
- Criminal Procedure
- Criminal Evidence Law
- Sentencing and Punishment
- Employment and Labour Law
- Environment and Energy Law
- Browse content in Financial Law
- Banking Law
- Insolvency Law
- History of Law
- Human Rights and Immigration
- Intellectual Property Law
- Browse content in International Law
- Private International Law and Conflict of Laws
- Public International Law
- IT and Communications Law
- Jurisprudence and Philosophy of Law
- Law and Politics
- Law and Society
- Browse content in Legal System and Practice
- Courts and Procedure
- Legal Skills and Practice
- Primary Sources of Law
- Regulation of Legal Profession
- Medical and Healthcare Law
- Browse content in Policing
- Criminal Investigation and Detection
- Police and Security Services
- Police Procedure and Law
- Police Regional Planning
- Browse content in Property Law
- Personal Property Law
- Study and Revision
- Terrorism and National Security Law
- Browse content in Trusts Law
- Wills and Probate or Succession
- Browse content in Medicine and Health
- Browse content in Allied Health Professions
- Arts Therapies
- Clinical Science
- Dietetics and Nutrition
- Occupational Therapy
- Operating Department Practice
- Physiotherapy
- Radiography
- Speech and Language Therapy
- Browse content in Anaesthetics
- General Anaesthesia
- Neuroanaesthesia
- Browse content in Clinical Medicine
- Acute Medicine
- Cardiovascular Medicine
- Clinical Genetics
- Clinical Pharmacology and Therapeutics
- Dermatology
- Endocrinology and Diabetes
- Gastroenterology
- Genito-urinary Medicine
- Geriatric Medicine
- Infectious Diseases
- Medical Oncology
- Medical Toxicology
- Pain Medicine
- Palliative Medicine
- Rehabilitation Medicine
- Respiratory Medicine and Pulmonology
- Rheumatology
- Sleep Medicine
- Sports and Exercise Medicine
- Clinical Neuroscience
- Community Medical Services
- Critical Care
- Emergency Medicine
- Forensic Medicine
- Haematology
- History of Medicine
- Browse content in Medical Dentistry
- Oral and Maxillofacial Surgery
- Paediatric Dentistry
- Restorative Dentistry and Orthodontics
- Surgical Dentistry
- Medical Ethics
- Browse content in Medical Skills
- Clinical Skills
- Communication Skills
- Nursing Skills
- Surgical Skills
- Medical Statistics and Methodology
- Browse content in Neurology
- Clinical Neurophysiology
- Neuropathology
- Nursing Studies
- Browse content in Obstetrics and Gynaecology
- Gynaecology
- Occupational Medicine
- Ophthalmology
- Otolaryngology (ENT)
- Browse content in Paediatrics
- Neonatology
- Browse content in Pathology
- Chemical Pathology
- Clinical Cytogenetics and Molecular Genetics
- Histopathology
- Medical Microbiology and Virology
- Patient Education and Information
- Browse content in Pharmacology
- Psychopharmacology
- Browse content in Popular Health
- Caring for Others
- Complementary and Alternative Medicine
- Self-help and Personal Development
- Browse content in Preclinical Medicine
- Cell Biology
- Molecular Biology and Genetics
- Reproduction, Growth and Development
- Primary Care
- Professional Development in Medicine
- Browse content in Psychiatry
- Addiction Medicine
- Child and Adolescent Psychiatry
- Forensic Psychiatry
- Learning Disabilities
- Old Age Psychiatry
- Psychotherapy
- Browse content in Public Health and Epidemiology
- Epidemiology
- Public Health
- Browse content in Radiology
- Clinical Radiology
- Interventional Radiology
- Nuclear Medicine
- Radiation Oncology
- Reproductive Medicine
- Browse content in Surgery
- Cardiothoracic Surgery
- Gastro-intestinal and Colorectal Surgery
- General Surgery
- Neurosurgery
- Paediatric Surgery
- Peri-operative Care
- Plastic and Reconstructive Surgery
- Surgical Oncology
- Transplant Surgery
- Trauma and Orthopaedic Surgery
- Vascular Surgery
- Browse content in Science and Mathematics
- Browse content in Biological Sciences
- Aquatic Biology
- Biochemistry
- Bioinformatics and Computational Biology
- Developmental Biology
- Ecology and Conservation
- Evolutionary Biology
- Genetics and Genomics
- Microbiology
- Molecular and Cell Biology
- Natural History
- Plant Sciences and Forestry
- Research Methods in Life Sciences
- Structural Biology
- Systems Biology
- Zoology and Animal Sciences
- Browse content in Chemistry
- Analytical Chemistry
- Computational Chemistry
- Crystallography
- Environmental Chemistry
- Industrial Chemistry
- Inorganic Chemistry
- Materials Chemistry
- Medicinal Chemistry
- Mineralogy and Gems
- Organic Chemistry
- Physical Chemistry
- Polymer Chemistry
- Study and Communication Skills in Chemistry
- Theoretical Chemistry
- Browse content in Computer Science
- Artificial Intelligence
- Computer Architecture and Logic Design
- Game Studies
- Human-Computer Interaction
- Mathematical Theory of Computation
- Programming Languages
- Software Engineering
- Systems Analysis and Design
- Virtual Reality
- Browse content in Computing
- Business Applications
- Computer Security
- Computer Games
- Computer Networking and Communications
- Digital Lifestyle
- Graphical and Digital Media Applications
- Operating Systems
- Browse content in Earth Sciences and Geography
- Atmospheric Sciences
- Environmental Geography
- Geology and the Lithosphere
- Maps and Map-making
- Meteorology and Climatology
- Oceanography and Hydrology
- Palaeontology
- Physical Geography and Topography
- Regional Geography
- Soil Science
- Urban Geography
- Browse content in Engineering and Technology
- Agriculture and Farming
- Biological Engineering
- Civil Engineering, Surveying, and Building
- Electronics and Communications Engineering
- Energy Technology
- Engineering (General)
- Environmental Science, Engineering, and Technology
- History of Engineering and Technology
- Mechanical Engineering and Materials
- Technology of Industrial Chemistry
- Transport Technology and Trades
- Browse content in Environmental Science
- Applied Ecology (Environmental Science)
- Conservation of the Environment (Environmental Science)
- Environmental Sustainability
- Environmentalist Thought and Ideology (Environmental Science)
- Management of Land and Natural Resources (Environmental Science)
- Natural Disasters (Environmental Science)
- Nuclear Issues (Environmental Science)
- Pollution and Threats to the Environment (Environmental Science)
- Social Impact of Environmental Issues (Environmental Science)
- History of Science and Technology
- Browse content in Materials Science
- Ceramics and Glasses
- Composite Materials
- Metals, Alloying, and Corrosion
- Nanotechnology
- Browse content in Mathematics
- Applied Mathematics
- Biomathematics and Statistics
- History of Mathematics
- Mathematical Education
- Mathematical Finance
- Mathematical Analysis
- Numerical and Computational Mathematics
- Probability and Statistics
- Pure Mathematics
- Browse content in Neuroscience
- Cognition and Behavioural Neuroscience
- Development of the Nervous System
- Disorders of the Nervous System
- History of Neuroscience
- Invertebrate Neurobiology
- Molecular and Cellular Systems
- Neuroendocrinology and Autonomic Nervous System
- Neuroscientific Techniques
- Sensory and Motor Systems
- Browse content in Physics
- Astronomy and Astrophysics
- Atomic, Molecular, and Optical Physics
- Biological and Medical Physics
- Classical Mechanics
- Computational Physics
- Condensed Matter Physics
- Electromagnetism, Optics, and Acoustics
- History of Physics
- Mathematical and Statistical Physics
- Measurement Science
- Nuclear Physics
- Particles and Fields
- Plasma Physics
- Quantum Physics
- Relativity and Gravitation
- Semiconductor and Mesoscopic Physics
- Browse content in Psychology
- Affective Sciences
- Clinical Psychology
- Cognitive Neuroscience
- Cognitive Psychology
- Criminal and Forensic Psychology
- Developmental Psychology
- Educational Psychology
- Evolutionary Psychology
- Health Psychology
- History and Systems in Psychology
- Music Psychology
- Neuropsychology
- Organizational Psychology
- Psychological Assessment and Testing
- Psychology of Human-Technology Interaction
- Psychology Professional Development and Training
- Research Methods in Psychology
- Social Psychology
- Browse content in Social Sciences
- Browse content in Anthropology
- Anthropology of Religion
- Human Evolution
- Medical Anthropology
- Physical Anthropology
- Regional Anthropology
- Social and Cultural Anthropology
- Theory and Practice of Anthropology
- Browse content in Business and Management
- Business Strategy
- Business History
- Business Ethics
- Business and Government
- Business and Technology
- Business and the Environment
- Comparative Management
- Corporate Governance
- Corporate Social Responsibility
- Entrepreneurship
- Health Management
- Human Resource Management
- Industrial and Employment Relations
- Industry Studies
- Information and Communication Technologies
- International Business
- Knowledge Management
- Management and Management Techniques
- Operations Management
- Organizational Theory and Behaviour
- Pensions and Pension Management
- Public and Nonprofit Management
- Strategic Management
- Supply Chain Management
- Browse content in Criminology and Criminal Justice
- Criminal Justice
- Criminology
- Forms of Crime
- International and Comparative Criminology
- Youth Violence and Juvenile Justice
- Development Studies
- Browse content in Economics
- Agricultural, Environmental, and Natural Resource Economics
- Asian Economics
- Behavioural Finance
- Behavioural Economics and Neuroeconomics
- Econometrics and Mathematical Economics
- Economic Systems
- Economic Methodology
- Economic History
- Economic Development and Growth
- Financial Markets
- Financial Institutions and Services
- General Economics and Teaching
- Health, Education, and Welfare
- History of Economic Thought
- International Economics
- Labour and Demographic Economics
- Law and Economics
- Macroeconomics and Monetary Economics
- Microeconomics
- Public Economics
- Urban, Rural, and Regional Economics
- Welfare Economics
- Browse content in Education
- Adult Education and Continuous Learning
- Care and Counselling of Students
- Early Childhood and Elementary Education
- Educational Equipment and Technology
- Educational Strategies and Policy
- Higher and Further Education
- Organization and Management of Education
- Philosophy and Theory of Education
- Schools Studies
- Secondary Education
- Teaching of a Specific Subject
- Teaching of Specific Groups and Special Educational Needs
- Teaching Skills and Techniques
- Browse content in Environment
- Applied Ecology (Social Science)
- Climate Change
- Conservation of the Environment (Social Science)
- Environmentalist Thought and Ideology (Social Science)
- Natural Disasters (Environment)
- Social Impact of Environmental Issues (Social Science)
- Browse content in Human Geography
- Cultural Geography
- Economic Geography
- Political Geography
- Browse content in Interdisciplinary Studies
- Communication Studies
- Museums, Libraries, and Information Sciences
- Browse content in Politics
- African Politics
- Asian Politics
- Chinese Politics
- Comparative Politics
- Conflict Politics
- Elections and Electoral Studies
- Environmental Politics
- European Union
- Foreign Policy
- Gender and Politics
- Human Rights and Politics
- Indian Politics
- International Relations
- International Organization (Politics)
- International Political Economy
- Irish Politics
- Latin American Politics
- Middle Eastern Politics
- Political Methodology
- Political Communication
- Political Philosophy
- Political Sociology
- Political Theory
- Political Behaviour
- Political Economy
- Political Institutions
- Politics and Law
- Public Administration
- Public Policy
- Quantitative Political Methodology
- Regional Political Studies
- Russian Politics
- Security Studies
- State and Local Government
- UK Politics
- US Politics
- Browse content in Regional and Area Studies
- African Studies
- Asian Studies
- East Asian Studies
- Japanese Studies
- Latin American Studies
- Middle Eastern Studies
- Native American Studies
- Scottish Studies
- Browse content in Research and Information
- Research Methods
- Browse content in Social Work
- Addictions and Substance Misuse
- Adoption and Fostering
- Care of the Elderly
- Child and Adolescent Social Work
- Couple and Family Social Work
- Developmental and Physical Disabilities Social Work
- Direct Practice and Clinical Social Work
- Emergency Services
- Human Behaviour and the Social Environment
- International and Global Issues in Social Work
- Mental and Behavioural Health
- Social Justice and Human Rights
- Social Policy and Advocacy
- Social Work and Crime and Justice
- Social Work Macro Practice
- Social Work Practice Settings
- Social Work Research and Evidence-based Practice
- Welfare and Benefit Systems
- Browse content in Sociology
- Childhood Studies
- Community Development
- Comparative and Historical Sociology
- Economic Sociology
- Gender and Sexuality
- Gerontology and Ageing
- Health, Illness, and Medicine
- Marriage and the Family
- Migration Studies
- Occupations, Professions, and Work
- Organizations
- Population and Demography
- Race and Ethnicity
- Social Theory
- Social Movements and Social Change
- Social Research and Statistics
- Social Stratification, Inequality, and Mobility
- Sociology of Religion
- Sociology of Education
- Sport and Leisure
- Urban and Rural Studies
- Browse content in Warfare and Defence
- Defence Strategy, Planning, and Research
- Land Forces and Warfare
- Military Administration
- Military Life and Institutions
- Naval Forces and Warfare
- Other Warfare and Defence Issues
- Peace Studies and Conflict Resolution
- Weapons and Equipment

A newer edition of this book is available.
- < Previous chapter
- Next chapter >
30 Interpretation Strategies: Appropriate Concepts
Allen Trent, College of Education, University of Wyoming
Jeasik Cho, Department of Educational Studies, University of Wyoming
- Published: 04 August 2014
- Cite Icon Cite
- Permissions Icon Permissions
This essay addresses a wide range of concepts related to interpretation in qualitative research, examines the meaning and importance of interpretation in qualitative inquiry, and explores the ways methodology, data, and the self/researcher as instrument interact and impact interpretive processes. Additionally, the essay presents a series of strategies for qualitative researchers engaged in the process of interpretation. The article closes by presenting a framework for qualitative researchers designed to inform their interpretations. The framework includes attention to the key qualitative research concepts transparency, reflexivity, analysis, validity, evidence, and literature. Four questions frame the article: What is interpretation, and why are interpretive strategies important in qualitative research? How do methodology, data, and the researcher/self impact interpretation in qualitative research? How do qualitative researchers engage in the process of interpretation? And, in what ways can a framework for interpretation strategies support qualitative researchers across multiple methodologies and paradigms?
“All human knowledge takes the form of interpretation.” In this seemingly simple statement, the late German philosopher Walter Benjamin asserts that all knowledge is mediated and constructed. He makes no distinction between physical and social sciences, and so situates himself as an interpretivist, one who believes that human subjectivity, individuals’ characteristics, feelings, opinions, and experiential backgrounds impact observations, analysis of these observations, and resultant knowledge/truth constructions. Contrast this perspective with positivist claims that knowledge is based exclusively on external facts, objectively observed and recorded. Interpretivists then, acknowledge that, if positivistic notions of knowledge and truth are inadequate to explain social phenomena, then positivist, hard science approaches to research (i.e., the scientific method and its variants) are also inadequate. So, although the literature often contrasts quantitative and qualitative research as largely a difference in kinds of data employed (numerical vs. linguistic), instead, the primary differentiation is in the foundational, paradigmatic assumptions about truth, knowledge, and objectivity.
This chapter is about interpretation and the strategies that qualitative researchers use to interpret a wide variety of “texts.” Knowledge, we assert, is constructed, both individually (constructivism) and socially (constructionism). We accept this as our starting point. Our aim here is to share our perspective on a broad set of concepts associated with the interpretive or meaning-making process. Although it may happen at different times and in different ways, interpretation is a part of almost all qualitative research.
Qualitative research is an umbrella term that encompasses a wide array of paradigmatic views, goals, and methods. Still, there are key unifying elements that include a generally constructionist epistemological standpoint, attention to primarily linguistic data, and generally accepted protocols or syntax for conducting research. Typically, qualitative researchers begin with a starting point—a curiosity, a problem in need of solutions, a research question, or a desire to better understand a situation from the perspectives of the individuals who inhabit that context (what qualitative researchers call the “emic,” or insider’s, perspective).
From this starting point, researchers determine the appropriate kinds of data to collect, engage in fieldwork as participant-observers to gather these data, organize the data, look for patterns, and then attempt to make sense out of the data by synthesizing research “findings,” “assertions,” or “theories” in ways that can be shared so that others may also gain insights from the conducted inquiry.
Although there are commonalities that cut across most forms of qualitative research, this is not to say that there is an accepted, linear, standardized approach. To be sure, there are an infinite number of variations and nuances in the qualitative research process. For example, some forms of inquiry begin with a firm research question, others without even a clear focus for study. Grounded theorists begin data analysis and interpretation very early in the research process, whereas some case study researchers, for example, may collect data in the field for a period of time before seriously considering the data and its implications. Some ethnographers may be a part of the context (e.g., observing in classrooms), but they may assume more observer-like roles, as opposed to actively participating in the context. Alternatively, action researchers, in studying issues about their own practice, are necessarily situated toward the “participant” end of the participant–observer continuum.
Our focus here is on one integrated part of the qualitative research process, interpretation, the process of collective and individual “meaning making.” As we discuss throughout this chapter, researchers take a variety of approaches to interpretation in qualitative work. Four general questions guide our explorations:
What is interpretation, and why are interpretive strategies important in qualitative research?
How do methodology, data, and the researcher/self impact interpretation in qualitative research?
How do qualitative researchers engage in the process of interpretation?
In what ways can a framework for interpretation strategies support qualitative researchers across multiple methodological and paradigmatic views?
We address each of these guiding questions in our attempt to explicate our interpretation of “interpretation,” and, as educational researchers, we include examples from our own work to illustrate some key concepts.
What Is Interpretation, and Why Are Interpretive Strategies Important in Qualitative Research?
Qualitative researchers and those writing about qualitative methods often intertwine the terms analysis and interpretation . For example, Hubbard and Power (2003) describe data analysis as, “bringing order, structure, and meaning to the data” (p. 88). To us, this description combines analysis with interpretation. Although there is nothing wrong with this construction, our understanding aligns more closely with Mills’s (2007) claim that, “put simply, analysis involves summarizing what’s in the data, whereas interpretation involves making sense of—finding meaning in—that data” (p. 122). For the purpose of this chapter, we’ll adhere to Mills’s distinction, understanding analysis as summarizing and organizing, and interpretation as meaning making. Unavoidably, these closely related processes overlap and interact, but our focus will be primarily on the more complex of these endeavors, interpretation. Interpretation, in this sense, is in part translation, but translation is not an objective act. Instead, translation necessarily involves selectivity and the ascribing of meaning. Qualitative researchers “aim beneath manifest behavior to the meaning events have for those who experience them” ( Eisner, 1991 , p. 35). The presentation of these insider/emic perspectives is a hallmark of qualitative research.
Qualitative researchers have long borrowed from extant models for fieldwork and interpretation. Approaches from anthropology and the arts have become especially prominent. For example, Eisner’s form of qualitative inquiry, “educational criticism” (1991), draws heavily on accepted models of art criticism. Barrett (2000) , an authority on art criticism, describes interpretation as a complex set of processes based on a set of principles. We believe many of these principles apply as readily to qualitative research as they do to critique. The following principles, adapted from Barrett’s principles of interpretation (2000, pp. 113–120), inform our examination:
Qualitative phenomena have “aboutness ”: All social phenomena have meaning, but meanings in this context can be multiple, even contradictory.
Interpretations are persuasive arguments : All interpretations are arguments, and qualitative researchers, like critics, strive to build strong arguments grounded in the information, or data, available.
Some interpretations are better than others : Barrett notes that, “some interpretations are better argued, better grounded with evidence, and therefore more reasonable, more certain, and more acceptable than others” (p. 115). This contradicts the argument that “all interpretations are equal,” heard in the common refrain, “well, that’s just your interpretation.”
There can be different, competing, and contradictory interpretations of the same phenomena : As noted at the beginning of this chapter, we acknowledge that subjectivity matters, and, unavoidably, it impacts one’s interpretations. As Barrett notes (2000) , “Interpretations are often based on a worldview” (p. 116).
Interpretations are not (and can’t be) “right,” but instead, they can be more or less reasonable, convincing, and informative : There is never one “true” interpretation, but some interpretations are more compelling than others.
Interpretations can be judged by coherence, correspondence, and inclusiveness : Does the argument/interpretation make sense (coherence)? Does the interpretation fit the data (correspondence)? Have all data been attended to, including outlier data that don’t necessarily support identified themes (inclusiveness)?
Interpretation is ultimately a communal endeavor : Initial interpretations may be incomplete, nearsighted, and/or narrow, but eventually, these interpretations become richer, broader, and more inclusive. Feminist revisionist history projects are an exemplary case. Over time, the writing, art, and cultural contributions of countless women, previously ignored, diminished, or distorted, have come to be accepted as prominent contributions given serious consideration.
So, meaning is conferred; interpretations are socially constructed arguments; multiple interpretations are to be expected; and some interpretations are better than others. As we discuss later in this chapter, what makes an interpretation “better” often hinges on the purpose/goals of the research in question. Interpretations designed to generate theory, or generalizable rules, will be “better” for responding to research questions aligned with the aims of more traditional quantitative/positivist research, whereas interpretations designed to construct meanings through social interaction, to generate multiple perspectives, and to represent the context-specific perspectives of the research participants are “better” for researchers constructing thick, contextually rich descriptions, stories, or narratives. The former relies on more “atomistic” interpretive strategies, whereas the latter adheres to a more “holistic” approach ( Willis, 2007 ). Both approaches to analysis/interpretation are addressed in more detail later in this chapter.
At this point, readers might ask, why does interpretation matter, anyway? Our response to this question involves the distinctive nature of interpretation and the ability of the interpretive process to put unique fingerprints on an otherwise relatively static set of data. Once interview data are collected and transcribed (and we realize that even the process of transcription is, in part, interpretive), documents are collected, and observations are recorded, qualitative researchers could just, in good faith and with fidelity, represent the data in as straightforward ways as possible, allowing readers to “see for themselves” by sharing as much actual data (e.g., the transcribed words of the research participants) as possible. This approach, however, includes analysis, what we have defined as summarizing and organizing data for presentation, but it falls short of what we actually reference and define as interpretation—attempting to explain the meaning of others’ words and actions. “While early efforts at qualitative research might have stopped at description, it is now more generally accepted that a qualitative researcher adds understanding and interpretation to the description” ( Lichtman, 2006 , p. 8).
As we are fond of the arts and arts-based approaches to qualitative research, an example from the late jazz drummer, Buddy Rich, seems fitting. Rich explains the importance of having the flexibility to interpret: “I don’t think any arranger should ever write a drum part for a drummer, because if a drummer can’t create his own interpretation of the chart, and he plays everything that’s written, he becomes mechanical; he has no freedom.” The same is true for qualitative researchers; without the freedom to interpret, the researcher merely regurgitates, attempting to share with readers/reviewers exactly what the research subjects shared with him or her. It is only through interpretation that the researcher, as collaborator with unavoidable subjectivities, is able to construct unique, contextualized meaning. Interpretation then, in this sense, is knowledge construction.
In closing this section, we’ll illustrate the analysis versus interpretation distinction with the following transcript excerpt. In this study, the authors ( Trent & Zorko, 2006 ) were studying student teaching from the perspective of K–12 students. This quote comes from a high school student in a focus group interview. She is describing a student teacher she had:
The right-hand column contains “codes” or labels applied to parts of the transcript text. Coding will be discussed in more depth later in this chapter, but, for now, note that the codes are mostly summarizing the main ideas of the text, sometimes using the exact words of the research participant. This type of coding is a part of what we’ve called analysis—organizing and summarizing the data. It’s a way of beginning to say, “what is” there. As noted, though, most qualitative researchers go deeper. They want to know more than “what is”; they also ask, “what does it mean?” This is a question of interpretation.
Specific to the transcript excerpt, researchers might next begin to cluster the early codes into like groups. For example, the teacher “felt targeted,” “assumed kids were going to behave inappropriately,” and appeared to be “overwhelmed.” A researcher might cluster this group of codes in a category called “teacher feelings and perceptions” and may then cluster the codes “could not control class,” and “students off task” into a category called “classroom management.” The researcher then, in taking a fresh look at these categories and the included codes, may begin to conclude that what’s going on in this situation is that the student teacher does not have sufficient training in classroom management models and strategies and may also be lacking the skills she needs to build relationships with her students. These then would be interpretations, persuasive arguments connected to the study’s data. In this specific example, the researchers might proceed to write a memo about these emerging interpretations. In this memo, they might more clearly define their early categories and may also look through other data to see if there are other codes or categories that align with or overlap with this initial analysis. They might write further about their emergent interpretations and, in doing so, may inform future data collection in ways that will allow them to either support or refute their early interpretations. These researchers will also likely find that the processes of analysis and interpretation are inextricably intertwined. Good interpretations very often depend on thorough and thoughtful analyses.
How Do Methodology, Data, and the Researcher/Self Impact Interpretation in Qualitative Research?
Methodological conventions guide interpretation and the use of interpretive strategies. For example, in grounded theory and in similar methodological traditions, “formal analysis begins early in the study and is nearly completed by the end of data collection” ( Bogdan & Biklen, 2003 , p. 66). Alternatively, for researchers from other traditions, for example, case study researchers, “Formal analysis and theory development [interpretation] do not occur until after the data collection is near complete” (p. 66).
Researchers subscribing to methodologies that prescribe early data analysis and interpretation may employ methods like analytic induction or the constant comparison method. In using analytic induction, researchers develop a rough definition of the phenomena under study; collect data to compare to this rough definition; modify the definition as needed, based on cases that both fit and don’t fit the definition; and finally, establish a clear, universal definition (theory) of the phenomena (Robinson, 1951, cited in Bogdan & Biklen, 2003 , p. 65). Generally, those using a constant comparison approach begin data collection immediately; identify key issues, events, and activities related to the study that then become categories of focus; collect data that provide incidents of these categories; write about and describe the categories, accounting for specific incidents and seeking others; discover basic processes and relationships; and, finally, code and write about the categories as theory, “grounded” in the data ( Glaser, 1965 ). Although processes like analytic induction and constant comparison can be listed as “steps” to follow, in actuality, these are more typically recursive processes in which the researcher repeatedly goes back and forth between the data and emerging analyses and interpretations.
In addition to methodological conventions that prescribe data analysis early (e.g., grounded theory) or later (e.g., case study) in the inquiry process, methodological approaches also impact the general approach to analysis and interpretation. Ellingson (2011) situates qualitative research methodologies on a continuum spanning “science”-like approaches on one end juxtaposed with “art”-like approaches on the other.
Researchers pursuing a more science-oriented approach seek valid, reliable, generalizable knowledge; believe in neutral, objective researchers; and ultimately claim single, authoritative interpretations. Researchers adhering to these science-focused, post-positivistic approaches may count frequencies, emphasize the validity of the employed coding system, and point to intercoder reliability and random sampling as criteria that bolsters the research credibility. Researchers at or near the science end of the continuum might employ analysis and interpretation strategies that include “paired comparisons,” “pile sorts,” “word counts,” identifying “key words in context,” and “triad tests” ( Ryan & Bernard, 2000 , pp. 770–776). These researchers may ultimately seek to develop taxonomies or other authoritative final products that organize and explain the collected data.
For example, in a study we conducted about preservice teachers’ experiences learning to teach second-language learners, the researchers collected larger datasets and used a statistical analysis package to analyze survey data, and the resultant findings included descriptive statistics. These survey results were supported with open-ended, qualitative data. For example, one of the study’s findings was “a strong majority of candidates (96%) agreed that an immersion approach alone will not guarantee academic or linguistic success for second language learners.” In narrative explanations, one preservice teacher remarked, “there has to be extra instructional efforts to help their students learn English... they won’t learn English by merely sitting in the classrooms” ( Cho, Rios, Trent, & Mayfield, 2012 , p. 75).
Methodologies on the “art” side of Ellingson’s (2011) continuum, alternatively, “value humanistic, openly subjective knowledge, such as that embodied in stories, poetry, photography, and painting” (p. 599). Analysis and interpretation in these (often more contemporary) methodological approaches strive not for “social scientific truth,” but instead are formulated to “enable us to learn about ourselves, each other, and the world through encountering the unique lens of a person’s (or a group’s) passionate rendering of a reality into a moving, aesthetic expression of meaning” (p. 599). For these “artistic/interpretivists, truths are multiple, fluctuating and ambiguous” (p. 599). Methodologies taking more artistic, subjective approaches to analysis and interpretation include autoethnography, testimonio, performance studies, feminist theorists/researchers, and others from related critical methodological forms of qualitative practice.
As an example, one of us engaged in an artistic inquiry with a group of students in an art class for elementary teachers. We called it “Dreams as Data” and, among the project aims, we wanted to gather participants’ “dreams for education in the future” and display these dreams in an accessible, interactive, artistic display (see Trent, 2002 ). The intent here was not to statistically analyze the dreams/data; instead, it was more universal. We wanted, as Ellingson (2011) noted, to use participant responses in ways that “enable us to learn about ourselves, each other, and the world.” The decision was made to leave responses intact and to share the whole/raw dataset in the artistic display in ways that allowed the viewers to holistically analyze and interpret for themselves. The following text is an excerpt from one response:
Almost a century ago, John Dewey eloquently wrote about the need to imagine and create the education that ALL children deserve, not just the richest, the Whitest, or the easiest to teach. At the dawn of this new century, on some mornings, I wake up fearful that we are further away from this ideal than ever.... Collective action, in a critical, hopeful, joyful, anti-racist and pro-justice spirit, is foremost in my mind as I reflect on and act in my daily work.... Although I realize the constraints on teachers and schools in the current political arena, I do believe in the power of teachers to stand next to, encourage, and believe in the students they teach—in short, to change lives. ( Trent, 2002 , p. 49)
In sum, researchers whom Ellingson (2011) characterizes as being on the science end of the continuum typically use more detailed or “atomistic” strategies to analyze and interpret qualitative data, whereas those toward the artistic end most often employ more holistic strategies. Both of these general approaches to qualitative data analysis and interpretation, atomistic and holistic, will be addressed later in this chapter.
As noted, qualitative researchers attend to data in a wide variety of ways depending on paradigmatic and epistemological beliefs, methodological conventions, and the purpose/aims of the research. These factors impact the kinds of data collected and the ways these data are ultimately analyzed and interpreted. For example, life history or testimonio researchers conduct extensive individual interviews, ethnographers record detailed observational notes, critical theorists may examine documents from pop culture, and ethnomethodologists may collect videotapes of interaction for analysis and interpretation.
In addition to the wide range of data types that are collected by qualitative researchers (and most qualitative researchers collect multiple forms of data), qualitative researchers, again influenced by the factors noted earlier, employ a variety of approaches to analyzing and interpreting data. As mentioned earlier in this article, some advocate for a detailed/atomistic, fine-grained approach to data (see e.g., Miles & Huberman, 1994 ); others, a more broad-based, holistic, “eyeballing” of the data. “Eyeballers reject the more structured approaches to analysis that break down the data into small units and, from the perspective of the eyeballers, destroy the wholeness and some of the meaningfulness of the data” ( Willis, 2007 , p. 298).
Regardless, we assert, as illustrated in Figure 30.1 , that as the process evolves, data collection becomes less prominent later in the process, as interpretation and making sense/meaning of the data becomes more prominent. It is through this emphasis on interpretation that qualitative researchers put their individual imprints on the data, allowing for the emergence of multiple, rich perspectives. This space for interpretation allows researchers the “freedom” Buddy Rich alluded to in his quote about interpreting musical charts. Without this freedom, Rich noted that the process would be simply “mechanical.” Furthermore, allowing space for multiple interpretations nourishes the perspectives of many
As emphasis on data/data collection decreases, emphasis on interpretation increases.
others in the community. Writer and theorist Meg Wheatley explains, “everyone in a complex system has a slightly different interpretation. The more interpretations we gather, the easier it becomes to gain a sense of the whole.”
In addition to the roles methodology and data play in the interpretive process, perhaps the most important is the role of the self/the researcher in the interpretive process. “She is the one who asks the questions. She is the one who conducts the analyses. She is the one who decides who to study and what to study. The researcher is the conduit through which information is gathered and filtered” ( Lichtman, 2006 , p. 16). Eisner (1991) supports the notion of the researcher “self as instrument,” noting that expert researchers don’t simply know what to attend to, but also what to neglect. He describes the researcher’s role in the interpretive process as combining sensibility , the ability to observe and ascertain nuances, with schema , a deep understanding or cognitive framework of the phenomena under study.
Barrett (2007) describes self/researcher roles as “transformations” (p. 418) at multiple points throughout the inquiry process: early in the process, researchers create representations through data generation, conducting observations and interviews and collecting documents and artifacts. Another “transformation occurs when the ‘raw’ data generated in the field are shaped into data records by the researcher. These data records are produced through organizing and reconstructing the researcher’s notes and transcribing audio and video recordings in the form of permanent records that serve as the ‘evidentiary warrants’ of the generated data. The researcher strives to capture aspects of the phenomenal world with fidelity by selecting salient aspects to incorporate into the data record” (p. 418). Transformation continues when the researcher analyzes, codes, categorizes, and explores patterns in the data (the process we call analysis). Transformations also involve interpreting what the data mean and relating these “interpretations to other sources of insight about the phenomena, including findings from related research, conceptual literature, and common experience.... Data analysis and interpretation are often intertwined and rely upon the researcher’s logic, artistry, imagination, clarity, and knowledge of the field under study” ( Barrett, 2007 , p. 418).
We mentioned the often-blended roles of participation and observation earlier in this chapter. The role(s) of the self/researcher are often described as points along a “participant/observer continuum” (see, e.g., Bogdan & Biklen, 2003 ). On the far “observer” end of this continuum, the researcher situates as detached, tries to be inconspicuous (so as not to impact/disrupt the phenomena under study), and approaches the studied context as if viewing it from behind a one-way mirror. On the opposite, “participant” end, the researcher is completely immersed and involved in the context. It would be difficult for an outsider to distinguish between researcher and subjects. For example, “some feminist researchers and some postmodernists take on a political stance as well and have an agenda that places the researcher in an activist posture. These researchers often become quite involved with the individuals they study and try to improve their human condition” ( Lichtman, 2006 , p. 9).
We assert that most researchers fall somewhere between these poles. We believe that complete detachment is both impossible and misguided. In doing so, we, along with many others, acknowledge (and honor) the role of subjectivity, the researcher’s beliefs, opinions, biases, and predispositions. Positivist researchers seeking objective data and accounts either ignore the impact of subjectivity or attempt to drastically diminish/eliminate its impact. Even qualitative researchers have developed methods to avoid researcher subjectivity affecting research data collection, analysis, and interpretation. For example, foundational phenomenologist Husserl (1962/1913) developed the concept of “bracketing,” what Lichtman describes as “trying to identify your own views on the topic and then putting them aside” (2006, p. 13). Like Slotnick and Janesick (2011) , we ultimately claim, “it is impossible to bracket yourself” (p. 1358). Instead, we take a balanced approach, like Eisner, understanding that subjectivity allows researchers to produce the rich, idiosyncratic, insightful, and yet data-based interpretations and accounts of lived experience that accomplish the primary purposes of qualitative inquiry. “Rather than regarding uniformity and standardization as the summum bonum, educational criticism [Eisner’s form of qualitative research] views unique insight as the higher good” ( Eisner, 1991 , p. 35). That said, we also claim that, just because we acknowledge and value the role of researcher subjectivity, researchers are still obligated to ground their findings in reasonable interpretations of the data. Eisner (1991) explains:
This appreciation for personal insight as a source of meaning does not provide a license for freedom. Educational critics must provide evidence and reasons. But they reject the assumption that unique interpretation is a conceptual liability in understanding, and they see the insights secured from multiple views as more attractive than the comforts provided by a single right one. (p. 35)
Connected to this participant/observer continuum is the way the researcher positions him- or herself in relation to the “subjects” of the study. Traditionally, researchers, including early qualitative researchers, anthropologists, and ethnographers, referenced those studied as “subjects.” More recently, qualitative researchers better understand that research should be a reciprocal process in which both researcher and the foci of the research should derive meaningful benefit. Researchers aligned with this thinking frequently use the term “participants” to describe those groups and individuals included in a study. Going a step farther, some researchers view research participants as experts on the studied topic and as equal collaborators in the meaning-making process. In these instances, researchers often use the terms “co-researchers” or “co-investigators.”
The qualitative researcher, then, plays significant roles throughout the inquiry process. These roles include transforming data, collaborating with research participants or co-researchers, determining appropriate points to situate along the participant/observer continuum, and ascribing personal insights, meanings, and interpretations that are both unique and justified with data exemplars. Performing these roles unavoidably impacts and changes the researcher. “Since, in qualitative research the individual is the research instrument through which all data are passed, interpreted, and reported, the scholar’s role is constantly evolving as self evolves” ( Slotnick & Janesick, 2011 , p. 1358).
As we note later, key in all this is for researchers to be transparent about the topics discussed in the preceding section: what methodological conventions have been employed and why? How have data been treated throughout the inquiry to arrive at assertions and findings that may or may not be transferable to other idiosyncratic contexts? And, finally, in what ways has the researcher/self been situated in and impacted the inquiry? Unavoidably, we assert, the self lies at the critical intersection of data and theory, and, as such, two legs of this stool, data and researcher, interact to create the third, theory.
How Do Qualitative Researchers Engage in the Process of Interpretation?
Theorists seem to have a propensity to dichotomize concepts, pulling them apart and placing binary opposites on far ends of conceptual continuums. Qualitative research theorists are no different, and we have already mentioned some of these continua in this chapter. For example, in the last section, we discussed the participant–observer continuum. Earlier, we referenced both Willis’s (2007) conceptualization of “atomistic” versus “holistic” approaches to qualitative analysis and interpretation and Ellingson’s (2011) science–art continuum. Each of these latter two conceptualizations inform “how qualitative researchers engage in the process of interpretation.”
Willis (2007) shares that the purpose of a qualitative project might be explained as “what we expect to gain from research” (p. 288). The purpose, or “what we expect to gain,” then guides and informs the approaches researchers might take to interpretation. Some researchers, typically positivist/postpositivist, conduct studies that aim to test theories about how the world works and/or people behave. These researchers attempt to discover general laws, truths, or relationships that can be generalized. Others, less confident in the ability of research to attain a single, generalizable law or truth, might seek “local theory.” These researchers still seek truths, but “instead of generalizable laws or rules, they search for truths about the local context... to understand what is really happening and then to communicate the essence of this to others” ( Willis, 2007 , p. 291). In both of these purposes, researchers employ atomistic strategies in an inductive process in which researchers “break the data down into small units and then build broader and broader generalizations as the data analysis proceeds” (p. 317). The earlier mentioned processes of analytic induction, constant comparison, and grounded theory fit within this conceptualization of atomistic approaches to interpretation. For example, a line-by-line coding of a transcript might begin an atomistic approach to data analysis.
Alternatively, other researchers pursue distinctly different aims. Researchers with an “objective description” purpose focus on accurately describing the people and context under study. These researchers adhere to standards and practices designed to achieve objectivity, and their approach to interpretation falls between the binary atomistic/holistic distinction.
The purpose of hermeneutic approaches to research is to “understand the perspectives of humans. And because understanding is situational, hermeneutic research tends to look at the details of the context in which the study occurred. The result is generally rich data reports that include multiple perspectives” ( Willis, 2007 , p. 293).
Still other researchers see their purpose as the creation of stories or narratives that utilize “a social process that constructs meaning through interaction... it is an effort to represent in detail the perspectives of participants... whereas description produces one truth about the topic of study, storytelling may generate multiple perspectives, interpretations, and analyses by the researcher and participants” ( Willis, 2007 , p. 295).
In these latter purposes (hermeneutic, storytelling, narrative production), researchers typically employ more holistic strategies. “Holistic approaches tend to leave the data intact and to emphasize that meaning must be derived for a contextual reading of the data rather than the extraction of data segments for detailed analysis” (p. 297). This was the case with the “Dreams as Data” project mentioned earlier.
We understand the propensity to dichotomize, situate concepts as binary opposites, and to create neat continua between these polar descriptors. These sorts of reduction and deconstruction support our understandings and, hopefully, enable us to eventually reconstruct these ideas in meaningful ways. Still, in reality, we realize most of us will, and should, work in the middle of these conceptualizations in fluid ways that allow us to pursue strategies, processes, and theories most appropriate for the research task at hand. As noted, Ellingson (2011) sets up another conceptual continuum, but, like ours, her advice is to “straddle multiple points across the field of qualitative methods” (p. 595). She explains, “I make the case for qualitative methods to be conceptualized as a continuum anchored by art and science, with vast middle spaces that embody infinite possibilities for blending artistic, expository, and social scientific ways of analysis and representation” (p. 595).
We explained at the beginning of this chapter that we view analysis as organizing and summarizing qualitative data, and interpretation as constructing meaning. In this sense, analysis allows us to “describe” the phenomena under study. It enables us to succinctly answer “what” and “how” questions and ensures that our descriptions are grounded in the data collected. Descriptions, however, rarely respond to questions of “why?” Why questions are the domain of interpretation, and, as noted throughout this text, interpretation is complex. “Traditionally, qualitative inquiry has concerned itself with what and how questions... qualitative researchers typically approach why questions cautiously, explanation is tricky business” ( Gubrium & Holstein, 2000 , p. 502). Eisner (1991) describes this distinctive nature of interpretation: “it means that inquirers try to account for [interpretation] what they have given account of ” (p. 35).
Our focus here is on interpretation, but interpretation requires analysis, for without having clear understandings of the data and its characteristics, derived through systematic examination and organization (e.g., coding, memoing, categorizing, etc.), “interpretations” resulting from inquiry will likely be incomplete, uninformed, and inconsistent with the constructed perspectives of the study participants. Fortunately for qualitative researchers, we have many sources that lead us through analytic processes. We earlier mentioned the accepted processes of analytic induction and the constant comparison method. These detailed processes (see e.g., Bogdan & Biklen, 2003 ) combine the inextricably linked activities of analysis and interpretation, with “analysis” more typically appearing as earlier steps in the process and meaning construction—“interpretation”—happening later.
A wide variety of resources support researchers engaged in the processes of analysis and interpretation. Saldaña (2011) , for example, provides a detailed description of coding types and processes. He shows researchers how to use process coding (uses gerunds, “-ing” words to capture action), in vivo coding (uses the actual words of the research participants/subjects), descriptive coding (uses nouns to summarize the data topics), versus coding (uses “vs.” to identify conflicts and power issues), and values coding (identifies participants’ values, attitudes, and/or beliefs). To exemplify some of these coding strategies, we include an excerpt from a transcript of a meeting of a school improvement committee. In this study, the collaborators were focused on building “school community.” This excerpt illustrates the application of a variety of codes described by Saldaña to this text:
To connect and elaborate the ideas developed in coding, Saldaña (2011) suggests researchers categorize the applied codes, write memos to deepen understandings and illuminate additional questions, and identify emergent themes. To begin the categorization process, Saldaña recommends all codes be “classified into similar clusters... once the codes have been classified, a category label is applied to them” (p. 97). So, in continuing with the study of school community example coded here, the researcher might create a cluster/category called: “Value of Collaboration,” and in this category might include the codes, “relationships,” “building community,” and “effective strategies.”
Having coded and categorized a study’s various data forms, a typical next step for researchers is to write “memos” or “analytic memos.” Writing analytic memos allows the researcher(s) to “set in words your interpretation of the data... an analytic memo further articulates your... thinking processes on what things may mean... as the study proceeds, however, initial and substantive analytic memos can be revisited and revised for eventual integration into the report itself” ( Saldaña, 2011 , p. 98). In the study of student teaching from K–12 students’ perspectives ( Trent & Zorko, 2006 ), we noticed throughout our analysis a series of focus group interview quotes coded “names.” The following quote from a high school student is representative of many others:
I think that, ah, they [student teachers] should like know your face and your name because, uh, I don’t like it if they don’t and they’ll just like... cause they’ll blow you off a lot easier if they don’t know, like our new principal is here... he is, like, he always, like, tries to make sure to say hi even to the, like, not popular people if you can call it that, you know, and I mean, yah, and the people that don’t usually socialize a lot, I mean he makes an effort to know them and know their name like so they will cooperate better with him.
Although we didn’t ask the focus groups a specific question about whether or not student teachers knew the K–12 students’ names, the topic came up in every focus group interview. We coded the above excerpt and the others, “knowing names,” and these data were grouped with others under the category “relationships.” In an initial analytic memo about this, the researchers wrote:
STUDENT TEACHING STUDY—MEMO #3 “Knowing Names as Relationship Building” Most groups made unsolicited mentions of student teachers knowing, or not knowing, their names. We haven’t asked students about this, but it must be important to them because it always seems to come up. Students expected student teachers to know their names. When they did, students noticed and seemed pleased. When they didn’t, students seemed disappointed, even annoyed. An elementary student told us that early in the semester, “she knew our names... cause when we rose [sic] our hands, she didn’t have to come and look at our name tags... it made me feel very happy.” A high schooler, expressing displeasure that his student teacher didn’t know students’ names, told us, “They should like know your name because it shows they care about you as a person. I mean, we know their names, so they should take the time to learn ours too.” Another high school student said that even after 3 months, she wasn’t sure the student teacher knew her name. Another student echoed, “same here.” Each of these students asserted that this (knowing students’ names) had impacted their relationship with the student teacher. This high school student focus group stressed that a good relationship, built early, directly impacts classroom interaction and student learning. A student explained it like this: “If you get to know each other, you can have fun with them... they seem to understand you more, you’re more relaxed, and learning seems easier.” Meeting Transcript . Process Coding . Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Talking Sharing Building Listening Collaborating Understanding IN VIVO CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Talking about what we want to get out of this Each of us sharing Hearing each of us reflecting Collaboration will be extremely valuable Relationships DESCRIPTIVE CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Open, participatory discussion Identification of effective strategies Collaborative, productive relationships Robust Understandings VERSUS CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Effective vs. Ineffective strategies Positive reflections vs. negative reflections VALUES CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Sharing Building community Reflection Collaboration Relationships Deeper Understandings Meeting Transcript . Process Coding . Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Talking Sharing Building Listening Collaborating Understanding IN VIVO CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Talking about what we want to get out of this Each of us sharing Hearing each of us reflecting Collaboration will be extremely valuable Relationships DESCRIPTIVE CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Open, participatory discussion Identification of effective strategies Collaborative, productive relationships Robust Understandings VERSUS CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Effective vs. Ineffective strategies Positive reflections vs. negative reflections VALUES CODING Let’s start talking about what we want to get out of this. What I’d like to hear is each of us sharing what we’re doing relative to this idea of building community. “Here’s what I’m doing. Here’s what worked. Here’s what didn’t work. I’m happy with this. I’m sad with this,” and just hearing each of us reflecting about what we’re doing I think will be interesting. That collaboration will be extremely valuable in terms of not only our relationships with one another, but also understanding the idea of community in more specific and concrete ways. Sharing Building community Reflection Collaboration Relationships Deeper Understandings Open in new tab
As noted in these brief examples, coding, categorizing, and writing memos about a study’s data are all accepted processes for data analysis and allow researchers to begin constructing new understandings and forming interpretations of the studied phenomena. We find the qualitative research literature to be particularly strong in offering support and guidance for researchers engaged in these analytic practices. In addition to those already noted in this chapter, we have found the following resources provide practical, yet theoretically grounded approaches to qualitative data analysis. For more detailed, procedural, or atomistic approaches to data analysis, we direct researchers to Miles and Huberman’s classic 1994 text, Qualitative Data Analysis , and Ryan and Bernard’s (2000) chapter on “Data Management and Analysis Methods.” For analysis and interpretation strategies falling somewhere between the atomistic and holistic poles, we suggest Hesse-Biber and Leavy’s (2011) chapter, “Analysis and Interpretation of Qualitative Data,” in their book, The Practice of Qualitative Research (2nd edition); Lichtman’s chapter, “Making Meaning From Your Data,” in her book Qualitative Research in Education: A User’s Guide; and “Processing Fieldnotes: Coding and Memoing” a chapter in Emerson, Fretz, and Shaw’s (1995) book, Writing Ethnographic Fieldnotes . Each of these sources succinctly describes the processes of data preparation, data reduction, coding and categorizing data, and writing memos about emergent ideas and findings. For more holistic approaches, we have found Denzin and Lincoln’s (2007) Collecting and Interpreting Qualitative Materials , and Ellis and Bochner’s (2000) chapter “Autoethnography, Personal Narrative, Reflexivity,” to both be very informative.
We have not yet mentioned the use of computer software for data analysis. The use of CAQDAS (Computer Assisted Qualitative Data Analysis Software) has become prevalent. That said, it is beyond the scope of this chapter because, generally, the software is very useful for analysis, but only human researchers can interpret in the ways we describe. Multiple sources are readily available for those interested in exploring computer-assisted analysis. We have found the software to be particularly useful when working with large sets of data.
Even after reviewing the multiple resources for treating data included here, qualitative researchers might still be wondering, “but exactly how do we interpret?” In the remainder of this section, and in the concluding section of this chapter, we more concretely provide responses to this question, and, in closing, propose a framework for researchers to utilize as they engage in the complex, ambiguous, and yet exciting process of constructing meanings and new understandings from qualitative sources.
These meanings and understandings are often presented as theory, but theories in this sense should be viewed more as “guides to perception” as opposed to “devices that lead to the tight control or precise prediction of events” ( Eisner, 1991 , p. 95). Perhaps Erickson’s (1986) concept of “assertions” is a more appropriate aim for qualitative researchers. He claimed that assertions are declarative statements; they include a summary of the new understandings, and they are supported by evidence/data. These assertions are open to revision and are revised when disconfirming evidence requires modification. Assertions, theories, or other explanations resulting from interpretation in research are typically presented as “findings” in written research reports. Belgrave and Smith (2002) emphasize the importance of these interpretations (as opposed to descriptions), “the core of the report is not the events reported by the respondent, but rather the subjective meaning of the reported events for the respondent” (p. 248).
Mills (2007) views interpretation as responding to the question, “So what?” He provides researchers a series of concrete strategies for both analysis and interpretation. Specific to interpretation, Mills suggests a variety of techniques, including the following:
“ Extend the Analysis ”: In doing so, researchers ask additional questions about the research. The data appear to say X, but could it be otherwise? In what ways do the data support emergent finding X? And, in what ways do they not?
“ Connect Findings with Personal Experience ”: Using this technique, researchers share interpretations based on their intimate knowledge of the context, the observed actions of the individuals in the studied context, and the data points that support emerging interpretations, as well as their awareness of discrepant events or outlier data. In a sense, the researcher is saying, “based on my experiences in conducting this study, this is what I make of it all.”
“ Seek the Advice of ‘Critical’ Friends ”: In doing so, researchers utilize trusted colleagues, fellow researchers, experts in the field of study, and others to offer insights, alternative interpretations, and the application of their own unique lenses to a researcher’s initial findings. We especially like this strategy because we acknowledge that, too often, qualitative interpretation is a “solo” affair.
“ Contextualize the Findings in the Literature ”: This allows researchers to compare their interpretations to others writing about and studying the same/similar phenomena. The results of this contextualization may be that the current study’s findings correspond with the findings of other researchers. The results might, alternatively, differ from the findings of other researchers. In either instance, the researcher can highlight his or her unique contributions to our understanding of the topic under study.
“ Turn to Theory” : Mills defines theory as “an analytical and interpretive framework that helps the researcher make sense of ‘what is going on’ in the social setting being studied.” In turning to theory, researchers search for increasing levels of abstraction and move beyond purely descriptive accounts. Connecting to extant or generating new theory enables researchers to link their work to the broader contemporary issues in the field. (p. 136)
Other theorists offer additional advice for researchers engaged in the act of interpretation. Richardson (1995) reminds us to account for the power dynamics in the researcher–researched relationship and notes that, in doing so, we can allow for oppressed and marginalized voices to be heard in context. Bogdan and Biklen (2003) suggest that researchers engaged in interpretation revisit foundational writing about qualitative research, read studies related to the current research, ask evaluative questions (e.g., is what I’m seeing here good or bad?), ask about implications of particular findings/interpretations, think about the audience for interpretations, look for stories and incidents that illustrate a specific finding/interpretation, and attempt to summarize key interpretations in a succinct paragraph. All of these suggestions can be pertinent in certain situations and with particular methodological approaches. In the next and closing section of this chapter, we present a framework for interpretive strategies we believe will support, guide, and be applicable to qualitative researchers across multiple methodologies and paradigms.
In What Ways Can a Framework for Interpretation Strategies Support Qualitative Researchers Across Multiple Methodological and Paradigmatic Views?
The process of qualitative research is often compared to a journey, one without a detailed itinerary and ending, but instead a journey with general direction and aims and yet an open-endedness that adds excitement and thrives on curiosity. Qualitative researchers are travelers. They travel physically to field sites; they travel mentally through various epistemological, theoretical, and methodological grounds; they travel through a series of problem finding, access, data collection, and data analysis processes; and, finally—the topic of this chapter—they travel through the process of making meaning out of all this physical and cognitive travel via interpretation.
Although travel is an appropriate metaphor to describe the journey of qualitative researchers, we’ll also use “travel” to symbolize a framework for qualitative research interpretation strategies. By design, this is a framework that applies across multiple paradigmatic, epistemological, and methodological traditions. The application of this framework is not formulaic or highly prescriptive, it is also not an “anything goes” approach. It falls, and is applicable, between these poles, giving concrete (suggested) direction to qualitative researchers wanting to make the most out of the interpretations that result from their research, and yet allows the necessary flexibility for researchers to employ the methods, theories, and approaches they deem most appropriate to the research problem(s) under study.
TRAVEL, a Comprehensive Approach to Qualitative Interpretation
In using the word “TRAVEL” as a mnemonic device, our aim is to highlight six essential concepts we argue all qualitative researchers should attend to in the interpretive process: Transparency, Reflexivity, Analysis, Validity, Evidence, and Literature. The importance of each is addressed here.
Transparency , as a research concept seems, well... transparent. But, too often, we read qualitative research reports and are left with many questions: How were research participants and the topic of study selected/excluded? How were the data collected, when, and for how long? Who analyzed and interpreted these data? A single researcher? Multiple? What interpretive strategies were employed? Are there data points that substantiate these interpretations/findings? What analytic procedures were used to organize the data prior to making the presented interpretations? In being transparent about data collection, analysis, and interpretation processes, researchers allow reviewers/readers insight into the research endeavor, and this transparency leads to credibility for both researcher and researcher’s claims. Altheide and Johnson (2011) explain, “There is great diversity of qualitative research.... While these approaches differ, they also share an ethical obligation to make public their claims, to show the reader, audience, or consumer why they should be trusted as faithful accounts of some phenomenon” (p. 584). This includes, they note, articulating “what the different sources of data were, how they were interwoven, and... how subsequent interpretations and conclusions are more or less closely tied to the various data... the main concern is that the connection be apparent, and to the extent possible, transparent” (p. 590).
In the “Dreams as Data” art and research project noted earlier, transparency was addressed in multiple ways. Readers of the project write-up were informed that interpretations resulting from the study, framed as “themes,” were a result of collaborative analysis that included insights from both students and instructor. Viewers of the art installation/data display had the rare opportunity to see all participant responses. In other words, viewers had access to the entire raw dataset (see Trent, 2002 ). More frequently, we encounter only research “findings” already distilled, analyzed, and interpreted in research accounts, often by a single researcher. Allowing research consumers access to the data to interpret for themselves in the “dreams” project was an intentional attempt at transparency.
Reflexivity , the second of our concepts for interpretive researcher consideration, has garnered a great deal of attention in qualitative research literature. Some have called this increased attention the “reflexive turn” (see e.g., Denzin & Lincoln, 2004 :
Although you can find many meanings for the term reflexivity, it is usually associated with a critical reflection on the practice and process of research and the role of the researcher. It concerns itself with the impact of the researcher on the system and the system on the researcher. It acknowledges the mutual relationships between the researcher and who and what is studied... by acknowledging the role of the self in qualitative research, the researcher is able to sort through biases and think about how they affect various aspects of the research, especially interpretation of meanings. ( Lichtman, 2006 , pp. 206–207)
As with transparency, attending to reflexivity allows researchers to attach credibility to presented findings. Providing a reflexive account of researcher subjectivity and the interactions of this subjectivity within the research process is a way for researchers to communicate openly with their audience. Instead of trying to exhume inherent bias from the process, qualitative researchers share with readers the value of having a specific, idiosyncratic positionality. As a result, situated, contextualized interpretations are viewed as an asset, as opposed to a liability.
LaBanca (2011) , acknowledging the often solitary nature of qualitative research, calls for researchers to engage others in the reflexive process. Like many other researchers, LaBanca utilizes a researcher journal to chronicle reflexive thoughts, explorations and understandings, but he takes this a step farther. Realizing the value of others’ input, LaBanca posts his reflexive journal entries on a blog (what he calls an “online reflexivity blog”) and invites critical friends, other researchers, and interested members of the community to audit his reflexive moves, providing insights, questions, and critique that inform his research and study interpretations.
We agree this is a novel approach worth considering. We, too, understand that multiple interpreters will undoubtedly produce multiple interpretations, a richness of qualitative research. So, we suggest researchers consider bringing others in before the production of the report. This could be fruitful in multiple stages of the inquiry process, but especially so in the complex, idiosyncratic processes of reflexivity and interpretation. We are both educators and educational researchers. Historically, each of these roles has tended to be constructed as an isolated endeavor, the solitary teacher, the solo researcher/fieldworker. As noted earlier and in the “analysis” section that follows, introducing collaborative processes to what has often been a solitary activity offers much promise for generating rich interpretations that benefit from multiple perspectives.
Being consciously reflexive throughout our practice as researchers has benefitted us in many ways. In a study of teacher education curricula designed to prepare preservice teachers to support second-language learners, we realized hard truths that caused us to reflect on and adapt our own practices as teacher educators. Reflexivity can inform a researcher at all parts of the inquiry, even in early stages. For example, one of us was beginning a study of instructional practices in an elementary school. The communicated methods of the study indicated that the researcher would be largely an observer. Early fieldwork revealed that the researcher became much more involved as a participant than anticipated. Deep reflection and writing about the classroom interactions allowed the researcher to realize that the initial purpose of the research was not being accomplished, and the researcher believed he was having a negative impact on the classroom culture. Reflexivity in this instance prompted the researcher to leave the field and abandon the project as it was just beginning. Researchers should plan to openly engage in reflexive activities, including writing about their ongoing reflections and subjectivities. Including excerpts of this writing in research account supports our earlier recommendation of transparency.
Early in this chapter, for the purposes of discussion and examination, we defined analysis as “summarizing and organizing” data in a qualitative study, and interpretation as “finding” or “making” meaning. Although our focus has been on interpretation as the primary topic here, the importance of good analysis cannot be underestimated for, without it, resultant interpretations are likely incomplete and potentially uninformed. Comprehensive analysis puts researchers in a position to be deeply familiar with collected data and to organize these data into forms that lead to rich, unique interpretations, and yet to interpretations clearly connected to data exemplars. Although we find it advantageous to examine analysis and interpretation as different but related practices, in reality, the lines blur as qualitative researchers engage in these recursive processes.
We earlier noted our affinity for a variety of approaches to analysis (see e.g., Lichtman, 2006 ; Saldaña, 2011 ; or Hesse-Biber & Leavy 2011 ). Emerson, Fretz, and Shaw (1995) present a grounded approach to qualitative data analysis: in early stages, researchers engage in a close, line-by-line reading of data/collected text and accompany this reading with open coding , a process of categorizing and labeling the inquiry data. Next, researchers write initial memos to describe and organize the data under analysis. These analytic phases allow the researcher(s) to prepare, organize, summarize, and understand the data, in preparation for the more interpretive processes of focused coding and the writing up of interpretations and themes in the form of integrative memos .
Similarly, Mills (2007) provides guidance on the process of analysis for qualitative action researchers. His suggestions for organizing and summarizing data include coding (labeling data and looking for patterns), asking key questions about the study data (who, what, where, when, why, and how), developing concept maps (graphic organizers that show initial organization and relationships in the data), and stating what’s missing by articulating what data are not present (pp. 124–132).
Many theorists, like Emerson, Fretz, and Shaw (1995) and Mills (2007) noted here, provide guidance for individual researchers engaged in individual data collection, analysis, and interpretation; others, however, invite us to consider the benefits of collaboratively engaging in these processes through the use of collaborative research and analysis teams. Paulus, Woodside, and Ziegler (2008) wrote about their experiences in collaborative qualitative research: “Collaborative research often refers to collaboration among the researcher and the participants. Few studies investigate the collaborative process among researchers themselves” (p. 226).
Paulus, Woodside, and Ziegler (2008) claim that the collaborative process “challenged and transformed our assumptions about qualitative research” (p. 226). Engaging in reflexivity, analysis, and interpretation as a collaborative enabled these researchers to reframe their views about the research process, finding that the process was much more recursive, as opposed to following a linear progression. They also found that cooperatively analyzing and interpreting data yielded “collaboratively constructed meanings” as opposed to “individual discoveries.” And finally, instead of the traditional “individual products” resulting from solo research, collaborative interpretation allowed researchers to participate in an “ongoing conversation” (p. 226).
These researchers explain that engaging in collaborative analysis and interpretation of qualitative data challenged their previously held assumptions. They note, “through collaboration, procedures are likely to be transparent to the group and can, therefore, be made public. Data analysis benefits from an iterative, dialogic, and collaborative process because thinking is made explicit in a way that is difficult to replicate as a single researcher” ( Paulus, Woodside, & Ziegler, 2008 , p. 236). They share that during the collaborative process, “we constantly checked our interpretation against the text, the context, prior interpretations, and each other’s interpretations” (p. 234).
We, too, have engaged in analysis similar to these described processes, including working on research teams. We encourage other researchers to find processes that fit with the methodology and data of a particular study, use the techniques and strategies most appropriate, and then cite to the utilized authority to justify the selected path. We urge traditionally solo researchers to consider trying a collaborative approach. Generally, we suggest researchers be familiar with a wide repertoire of practices. In doing so, they’ll be in better positions to select and use strategies most appropriate for their studies and data. Succinctly preparing, organizing, categorizing, and summarizing data sets the researcher(s) up to construct meaningful interpretations in the forms of assertions, findings, themes, and theories.
Researchers want their findings to be sound, backed by evidence, justifiable, and to accurately represent the phenomena under study. In short, researchers seek validity for their work. We assert that qualitative researchers should attend to validity concepts as a part of their interpretive practices. We have previously written and theorized about validity, and, in doing so, we have highlighted and labeled what we consider to be two distinctly different approaches, transactional and transformational ( Cho & Trent, 2006 ). We define transactional validity in qualitative research as an interactive process occurring among the researcher, the researched, and the collected data, one that is aimed at achieving a relatively higher level of accuracy. Techniques, methods, and/or strategies are employed during the conduct of the inquiry. These techniques, such as member checking and triangulation, are seen as a medium with which to ensure an accurate reflection of reality (or, at least, participants’ constructions of reality). Lincoln and Guba’s (1985) widely known notion of trustworthiness in “naturalistic inquiry” is grounded in this approach. In seeking trustworthiness, researchers attend to research credibility, transferability, dependability, and confirmability. Validity approaches described by Maxwell (1992) as “descriptive” and “interpretive” also proceed in the usage of transactional processes.
For example, in the write-up of a study on the facilitation of teacher research, one of us ( Trent, 2012 , p. 44) wrote about the use of transactional processes: “‘Member checking is asking the members of the population being studied for their reaction to the findings’ ( Sagor, 2000 , p. 136). Interpretations and findings of this research, in draft form, were shared with teachers (for member checking) on multiple occasions throughout the study. Additionally, teachers reviewed and provided feedback on the final draft of this article.” This member checking led to changes in some resultant interpretations (called findings in this particular study) and to adaptations of others that shaped these findings in ways that made them both richer and more contextualized.
Alternatively, in transformational approaches, validity is not so much something that can be achieved solely by way of certain techniques. Transformationalists assert that because traditional or positivist inquiry is no longer seen as an absolute means to truth in the realm of human science, alternative notions of validity should be considered to achieve social justice, deeper understandings, broader visions, and other legitimate aims of qualitative research. In this sense, it is the ameliorative aspects of the research that achieve (or don’t achieve) its validity. Validity is determined by the resultant actions prompted by the research endeavor.
Lather (1993) , Richardson (1997) , and others (e.g., Lenzo, 1995 ; Scheurich, 1996 ) propose a transgressive approach to validity that emphasizes a higher degree of self-reflexivity. For example, Lather has proposed a “catalytic validity” described as “the degree to which the research empowers and emancipates the research subjects” ( Scheurich, 1996 , p. 4). Beverley (2000 , p. 556) has proposed “testimonio” as a qualitative research strategy. These first-person narratives find their validity in their ability to raise consciousness and thus provoke political action to remedy problems of oppressed peoples (e.g., poverty, marginality, exploitation).
We, too, have pursued research with transformational aims. In the earlier mentioned study of preservice teachers’ experiences learning to teach second-language learners ( Cho, Rios, Trent, & Mayfield, 2012 ), our aims were to empower faculty members, evolve the curriculum, and, ultimately, better serve preservice teachers so that they might better serve English-language learners in their classrooms. As program curricula and activities have changed as a result, we claim a degree of transformational validity for this research.
Important, then, for qualitative researchers throughout the inquiry, but especially when engaged in the process of interpretation, is to determine the type(s) of validity applicable to the study. What are the aims of the study? Providing an “accurate” account of studied phenomena? Empowering participants to take action for themselves and others? The determination of this purpose will, in turn, inform researchers’ analysis and interpretation of data. Understanding and attending to the appropriate validity criteria will bolster researcher claims to meaningful findings and assertions.
Regardless of purpose or chosen validity considerations, qualitative research depends on evidence . Researchers in different qualitative methodologies rely on different types of evidence to support their claims. Qualitative researchers typically utilize a variety of forms of evidence including texts (written notes, transcripts, images, etc.), audio and video recordings, cultural artifacts, documents related to the inquiry, journal entries, and field notes taken during observations of social contexts and interactions. “Evidence is essential to justification, and justification takes the form of an argument about the merit(s) of a given claim. It is generally accepted that no evidence is conclusive or unassailable (and hence, no argument is foolproof). Thus, evidence must often be judged for its credibility, and that typically means examining its source and the procedures by which it was produced [thus the need for transparency discussed earlier]” ( Schwandt, 2001 , p. 82).
Qualitative researchers distinguish evidence from facts. Evidence and facts are similar but not identical. We can often agree on facts, e.g., there is a rock, it is harder than cotton candy. Evidence involves an assertion that some facts are relevant to an argument or claim about a relationship. Since a position in an argument is likely tied to an ideological or even epistemological position, evidence is not completely bound by facts, but it is more problematic and subject to disagreement. ( Altheide & Johnson, 2011 , p. 586)
Inquirers should make every attempt to link evidence to claims (or findings, interpretations, assertions, conclusions, etc.). There are many strategies for making these connections. Induction involves accumulating multiple data points to infer a general conclusion. Confirmation entails directly linking evidence to resultant interpretations. Testability/falsifiability means illustrating that evidence does not necessarily contradict the claim/interpretation, and so increases the credibility of the claim ( Schwandt, 2001 ). In the “learning to teach second-language learners” study, for example, a study finding ( Cho, Rios, Trent, & Mayfield, 2012 , p. 77) was that “as a moral claim , candidates increasingly [in higher levels of the teacher education program] feel more responsible and committed to ELLs [English language learners].” We supported this finding with a series of data points that included the following preservice teacher response: “It is as much the responsibility of the teacher to help teach second-language learners the English language as it is our responsibility to teach traditional English speakers to read or correctly perform math functions.” Claims supported by evidence allow readers to see for themselves and to both examine researcher assertions in tandem with evidence and to form further interpretations of their own.
Some postmodernists reject the notion that qualitative interpretations are arguments based on evidence. Instead, they argue that qualitative accounts are not intended to faithfully represent that experience, but instead are designed to evoke some feelings or reactions in the reader of the account ( Schwandt, 2001 ). We argue that, even in these instances where transformational validity concerns take priority over transactional processes, evidence still matters. Did the assertions accomplish the evocative aims? What evidence/arguments were used to evoke these reactions? Does the presented claim correspond with the study’s evidence? Is the account inclusive? In other words, does it attend to all evidence or selectively compartmentalize some data while capitalizing on other evidentiary forms?
Researchers, we argue, should be both transparent and reflexive about these questions and, regardless of research methodology or purpose, should share with readers of the account their evidentiary moves and aims. Altheide and Johnson (2011) call this an “evidentiary narrative” and explain:
Ultimately, evidence is bound up with our identity in a situation.... An “evidentiary narrative” emerges from a reconsideration of how knowledge and belief systems in everyday life are tied to epistemic communities that provide perspectives, scenarios, and scripts that reflect symbolic and social moral orders. An “evidentiary narrative” symbolically joins an actor, an audience, a point of view (definition of a situation), assumptions, and a claim about a relationship between two or more phenomena. If any of these factors are not part of the context of meaning for a claim, it will not be honored, and thus, not seen as evidence. (p. 686)
In sum, readers/consumers of a research account deserve to know how evidence was treated and viewed in an inquiry. They want and should be aware of accounts that aim to evoke versus represent, and then they can apply their own criteria (including the potential transferability to their situated context). Renowned ethnographer and qualitative research theorist Harry Wolcott (1990) urges researchers to “let readers ‘see’ for themselves” by providing more detail rather than less and by sharing primary data/evidence to support interpretations. In the end, readers don’t expect perfection. Writer Eric Liu (2010) explains, “we don’t expect flawless interpretation. We expect good faith. We demand honesty.”
Last, in this journey through concepts we assert are pertinent to researchers engaged in interpretive processes, we include attention to the “ literature .” In discussing “literature,” qualitative researchers typically mean publications about the prior research conducted on topics aligned with or related to a study. Most often, this research/literature is reviewed and compiled by researchers in a section of the research report titled, “literature review.” It is here we find others’ studies, methods, and theories related to our topics of study, and it is here we hope the assertions and theories that result from our studies will someday reside.
We acknowledge the value of being familiar with research related to topics of study. This familiarity can inform multiple phases of the inquiry process. Understanding the extant knowledge base can inform research questions and topic selection, data collection and analysis plans, and the interpretive process. In what ways do the interpretations from this study correspond with other research conducted on this topic? Do findings/interpretations corroborate, expand, or contradict other researchers’ interpretations of similar phenomena? In any of these scenarios (correspondence, expansion, contradiction), new findings and interpretations from a study add to and deepen the knowledge base, or literature, on a topic of investigation.
For example, in our literature review for the study of student teaching, we quickly determined that the knowledge base and extant theories related to the student teaching experience was immense, but also quickly realized that few if any studies had examined student teaching from the perspective of the K–12 students who had the student teachers. This focus on the literature related to our topic of student teaching prompted us to embark on a study that would fill a gap in this literature: most of the knowledge base focused on the experiences and learning of the student teachers themselves. Our study then, by focusing on the K–12 students’ perspectives, added literature/theories/assertions to a previously untapped area. The “literature” in this area (at least we’d like to think) is now more robust as a result.
In another example, a research team ( Trent et al., 2003 ) focused on institutional diversity efforts, mined the literature, found an appropriate existing (a priori) set of theories/assertions, and then used this existing theoretical framework from the literature as a framework to analyze data; in this case, a variety of institutional activities related to diversity.
Conducting a literature review to explore extant theories on a topic of study can serve a variety of purposes. As evidenced in these examples, consulting the literature/extant theory can reveal gaps in the literature. A literature review might also lead researchers to existing theoretical frameworks that support analysis and interpretation of their data (as in the use of the a priori framework example). Finally, a review of current theories related to a topic of inquiry might confirm that much theory already exists, but that further study may add to, bolster, and/or elaborate on the current knowledge base.
Guidance for researchers conducting literature reviews is plentiful. Lichtman (2006) suggests researchers conduct a brief literature review, begin research, and then update and modify the literature review as the inquiry unfolds. She suggests reviewing a wide range of related materials (not just scholarly journals) and additionally suggests researchers attend to literature on methodology, not just the topic of study. She also encourages researchers to bracket and write down thoughts on the research topic as they review the literature, and, important for this chapter, she suggests researchers “integrate your literature review throughout your writing rather than using a traditional approach of placing it in a separate chapter [or section]” (p. 105).
We agree that the power of a literature review to provide context for a study can be maximized when this information isn’t compartmentalized apart from a study’s findings. Integrating (or at least revisiting) reviewed literature juxtaposed alongside findings can illustrate how new interpretations add to an evolving story. Eisenhart (1998) expands the traditional conception of the literature review and discusses the concept of an “interpretive review.” By taking this interpretive approach, Eisenhart claims that reviews, alongside related interpretations/findings on a specific topic, have the potential to allow readers to see the studied phenomena in entirely new ways, through new lenses, revealing heretofore unconsidered perspectives. Reviews that offer surprising and enriching perspectives on meanings and circumstances “shake things up, break down boundaries, and cause things (or thinking) to expand” (p. 394). Coupling reviews of this sort with current interpretations will “give us stories that startle us with what we have failed to notice” (p. 395).
In reviews of research studies, it can certainly be important to evaluate the findings in light of established theories and methods [the sorts of things typically included in literature reviews]. However, it also seems important to ask how well the studies disrupt conventional assumptions and help us to reconfigure new, more inclusive, and more promising perspectives on human views and actions. From an interpretivist perspective, it would be most important to review how well methods and findings permit readers to grasp the sense of unfamiliar perspectives and actions. ( Eisenhart, 1998 , p. 397)
And so, our journey through qualitative research interpretation and the selected concepts we’ve treated in this chapter nears an end, an end in the written text, but a hopeful beginning of multiple new conversations among ourselves and in concert with other qualitative researchers. Our aims here have been to circumscribe interpretation in qualitative research; emphasize the importance of interpretation in achieving the aims of the qualitative project; discuss the interactions of methodology, data, and the researcher/self as these concepts and theories intertwine with interpretive processes; describe some concrete ways that qualitative inquirers engage the process of interpretation; and, finally, to provide a framework of interpretive strategies that may serve as a guide for ourselves and other researchers.
In closing, we note that this “travel” framework, construed as a journey to be undertaken by researchers engaged in the interpretive process, is not designed to be rigid or prescriptive, but instead is designed to be a flexible set of concepts that will inform researchers across multiple epistemological, methodological, and theoretical paradigms. We chose the concepts of transparency, reflexivity, analysis, validity, evidence, and literature (TRAVEL) because they are applicable to the infinite journeys undertaken by qualitative researchers who have come before and to those who will come after us. As we journeyed through our interpretations of interpretation, we have discovered new things about ourselves and our work. We hope readers also garner insights that enrich their interpretive excursions. Happy travels to all— Bon Voyage !
Altheide, D. , & Johnson, J. M. ( 2011 ). Reflections on interpretive adequacy in qualitative research. In N. M. Denzin & Y. S. Lincoln (Eds.), The Sage handbook of qualitative research (pp. 595–610). Thousand Oaks, CA: Sage.
Google Scholar
Google Preview
Barrett, T. ( 2000 ). Criticizing art: Understanding the contemporary . New York: McGraw Hill.
Barrett, J. ( 2007 ). The researcher as instrument: learning to conduct qualitative research through analyzing and interpreting a choral rehearsal. Music Education Research , 9 (3), 417–433.
Belgrave, L. L. , & Smith, K. J. ( 2002 ). Negotiated validity in collaborative ethnography. In N. M. Denzin & Y. S. Lincoln (Eds.), The qualitative inquiry reader (pp. 233–255). Thousand Oaks, CA: Sage.
Beverly, J. ( 2000 ). Testimonio, subalternity, and narrative authority. In N. M. Denzin & Y. S. Lincoln (Eds.), Handbook of qualitative research, second edition (pp. 555–566). Thousand Oaks, CA: Sage.
Bogdan, R. C. , & Biklen, S. K. ( 2003 ). Qualitative research for education: An introduction to theories and methods . Boston: Allyn and Bacon.
Cho, J. , Rios, F. , Trent, A. , & Mayfield, K. ( 2012 ). Integrating language diversity into teacher education curricula in a rural context: Candidates’ developmental perspectives and understandings. Teacher Education Quarterly , 39 (2), 63–85.
Cho, J. , & Trent, A. ( 2006 ). Validity in qualitative research revisited. QR—Qualitative Research Journal , 6 (3), 319–340.
Denzin, N. M. , & Lincoln, Y. S. (Eds.). ( 2004 ). Handbook of qualitative research . Newbury Park, CA: Sage.
Denzin, N. M. , & Lincoln, Y. S. ( 2007 ). Collecting and interpreting qualitative materials . Thousand Oaks, CA: Sage.
Eisenhart, M. ( 1998 ). On the subject of interpretive reviews. Review of Educational Research , 68 (4), 391–393.
Eisner, E. ( 1991 ). The enlightened eye: Qualitative inquiry and the enhancement of educational practice . New York: Macmillan.
Ellingson, L. L. ( 2011 ). Analysis and representation across the continuum. In N. M. Denzin & Y. S. Lincoln (Eds.), The Sage handbook of qualitative research (pp. 595–610). Thousand Oaks, CA: Sage.
Ellis, C. , & Bochner, A. P. ( 2000 ). Autoethnography, personal narrative, reflexivity: Researcher as subject. In N. M. Denzin & Y. S. Lincoln (Eds.), Handbook of qualitative research , second edition (pp. 733–768). Thousand Oaks, CA: Sage.
Emerson, R. , Fretz, R. , & Shaw, L. ( 1995 ). Writing ethnographic fieldwork . Chicago: University of Chicago Press.
Erickson, F. ( 1986 ). Qualitative methods in research in teaching and learning. In M. C. Wittrock Ed.), Handbook of research on teaching (3rd ed., pp 119–161). New York: Macmillan.
Glaser, B. ( 1965 ). The constant comparative method of qualitative analysis. Social Problems , 12 (4), 436–445.
Gubrium, J. F. , & Holstein, J. A. ( 2000 ). Analyzing interpretive practice. In N. M. Denzin & Y. S. Lincoln (Eds.), Handbook of qualitative research , second edition (pp. 487–508). Thousand Oaks, CA: Sage.
Hesse-Biber, S. N. , & Leavy, P. ( 2011 ). The practice of qualitative research (2nd ed.). Thousand Oaks, CA: Sage.
Hubbard, R. S. , & Power, B. M. ( 2003 ). The art of classroom inquiry: A handbook for teacher researchers . Portsmouth, NH: Heinemann.
Husserl, E. ( 1962 ). Ideas: general introduction to pure phenomenology . ( W. R. Boyce Gibson , Trans.). London, New York: Collier, Macmillan. (Original work published 1913)
LaBanca, F. ( 2011 ). Online dynamic asynchronous audit strategy for reflexivity in the qualitative paradigm. Qualitative Report , 16 (4), 1160–1171.
Lather, P. ( 1993 ). Fertile obsession: Validity after poststructuralism. Sociological Quarterly , 34 (4), 673–693.
Lenzo, K. ( 1995 ). Validity and self reflexivity meet poststructuralism: Scientific ethos and the transgressive self. Educational Researcher , 24 (4), 17–23, 45.
Lichtman, M. ( 2006 ). Qualitative research in education: A user’s guide . Thousand Oaks, CA: Sage.
Liu, E. (2010). The real meaning of balls and strikes. Retrieved September 20, 2012, from http://www.huffingtonpost.com/eric-liu/the-real-meaning-of-balls_b_660915.html
Lincoln, Y. S. , & Guba, E. G. ( 1985 ). Naturalistic inquiry . Beverly Hills, CA: Sage.
Maxwell, J. ( 1992 ). Understanding and validity in qualitative research. Harvard Educational Review , 62 (3), 279–300.
Miles, M. B. , & Huberman, A. M. ( 1994 ). Qualitative data analysis . Thousand Oaks, CA: Sage.
Mills, G. E. ( 2007 ). Action research: A guide for the teacher researcher . Upper Saddle River, NJ: Pearson.
Paulus, T. , Woodside, M. , & Ziegler, M. ( 2008 ). Extending the conversation: Qualitative research as dialogic collaborative process. Qualitative Report , 13 (2), 226–243.
Richardson, L. ( 1995 ). Writing stories: Co-authoring the “sea monster,” a writing story. Qualitative Inquiry , 1 , 189–203.
Richardson, L. ( 1997 ). Fields of play: Constructing an academic life . New Brunswick, NJ: Rutgers University Press.
Ryan, G. W. , & Bernard, H. R. ( 2000 ). Data management and analysis methods. In N. M. Denzin & Y. S. Lincoln (Eds.), Handbook of qualitative research , second edition (pp. 769–802). Thousand Oaks, CA: Sage.
Sagor, R. ( 2000 ). Guiding school improvement with action research . Alexandria, VA: ASCD.
Saldaña, J. ( 2011 ). Fundamentals of qualitative research . New York: Oxford University Press.
Scheurich, J. ( 1996 ). The masks of validity: A deconstructive investigation. Qualitative Studies in Education , 9 (1), 49–60.
Slotnick, R. C. , & Janesick, V. J. ( 2011 ). Conversations on method: Deconstructing policy through the researcher reflective journal. Qualitative Report , 16 (5), 1352–1360.
Schwandt, T. A. ( 2001 ). Dictionary of qualitative inquiry . Thousand Oaks, CA: Sage.
Trent, A. ( 2002 ). Dreams as data: Art installation as heady research, Teacher Education Quarterly , 29 (4), 39–51.
Trent, A. ( 2012 ). Action research on action research: A facilitator’s account. Action Learning and Action Research Journal , 18 (1), 35–67.
Trent, A. , Rios, F. , Antell, J. , Berube, W. , Bialostok, S. , Cardona, D. , et al. ( 2003 ). Problems and possibilities in the pursuit of diversity: An institutional analysis. Equity & Excellence , 36(3), 213–224.
Trent, A. , & Zorko, L. ( 2006 ). Listening to students: “New” perspectives on student teaching. Teacher Education & Practice , 19 (1), 55–70.
Willis, J. W. ( 2007 ). Foundations of qualitative research: Interpretive and critical approaches . Thousand Oaks, CA: Sage.
Wolcott, H. ( 1990 ). On seeking-and rejecting-validity in qualitative research. In E. Eisner & A. Peshkin (Eds.), Qualitative inquiry in education: The continuing debate (pp. 121–152). New York: Teachers College Press.
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
- Skip to main content
- Skip to primary sidebar
- Skip to footer
- QuestionPro

- Solutions Industries Gaming Automotive Sports and events Education Government Travel & Hospitality Financial Services Healthcare Cannabis Technology Use Case NPS+ Communities Audience Contactless surveys Mobile LivePolls Member Experience GDPR Positive People Science 360 Feedback Surveys
- Resources Blog eBooks Survey Templates Case Studies Training Help center
Home Market Research
Data Analysis in Research: Types & Methods

Content Index
Why analyze data in research?
Types of data in research, finding patterns in the qualitative data, methods used for data analysis in qualitative research, preparing data for analysis, methods used for data analysis in quantitative research, considerations in research data analysis, what is data analysis in research.
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense.
Three essential things occur during the data analysis process — the first is data organization . Summarization and categorization together contribute to becoming the second known method used for data reduction. It helps find patterns and themes in the data for easy identification and linking. The third and last way is data analysis – researchers do it in both top-down and bottom-up fashion.
LEARN ABOUT: Research Process Steps
On the other hand, Marshall and Rossman describe data analysis as a messy, ambiguous, and time-consuming but creative and fascinating process through which a mass of collected data is brought to order, structure and meaning.
We can say that “the data analysis and data interpretation is a process representing the application of deductive and inductive logic to the research and data analysis.”
Researchers rely heavily on data as they have a story to tell or research problems to solve. It starts with a question, and data is nothing but an answer to that question. But, what if there is no question to ask? Well! It is possible to explore data even without a problem – we call it ‘Data Mining’, which often reveals some interesting patterns within the data that are worth exploring.
Irrelevant to the type of data researchers explore, their mission and audiences’ vision guide them to find the patterns to shape the story they want to tell. One of the essential things expected from researchers while analyzing data is to stay open and remain unbiased toward unexpected patterns, expressions, and results. Remember, sometimes, data analysis tells the most unforeseen yet exciting stories that were not expected when initiating data analysis. Therefore, rely on the data you have at hand and enjoy the journey of exploratory research.
Create a Free Account
Every kind of data has a rare quality of describing things after assigning a specific value to it. For analysis, you need to organize these values, processed and presented in a given context, to make it useful. Data can be in different forms; here are the primary data types.
- Qualitative data: When the data presented has words and descriptions, then we call it qualitative data . Although you can observe this data, it is subjective and harder to analyze data in research, especially for comparison. Example: Quality data represents everything describing taste, experience, texture, or an opinion that is considered quality data. This type of data is usually collected through focus groups, personal qualitative interviews , qualitative observation or using open-ended questions in surveys.
- Quantitative data: Any data expressed in numbers of numerical figures are called quantitative data . This type of data can be distinguished into categories, grouped, measured, calculated, or ranked. Example: questions such as age, rank, cost, length, weight, scores, etc. everything comes under this type of data. You can present such data in graphical format, charts, or apply statistical analysis methods to this data. The (Outcomes Measurement Systems) OMS questionnaires in surveys are a significant source of collecting numeric data.
- Categorical data: It is data presented in groups. However, an item included in the categorical data cannot belong to more than one group. Example: A person responding to a survey by telling his living style, marital status, smoking habit, or drinking habit comes under the categorical data. A chi-square test is a standard method used to analyze this data.
Learn More : Examples of Qualitative Data in Education
Data analysis in qualitative research
Data analysis and qualitative data research work a little differently from the numerical data as the quality data is made up of words, descriptions, images, objects, and sometimes symbols. Getting insight from such complicated information is a complicated process. Hence it is typically used for exploratory research and data analysis .
Although there are several ways to find patterns in the textual information, a word-based method is the most relied and widely used global technique for research and data analysis. Notably, the data analysis process in qualitative research is manual. Here the researchers usually read the available data and find repetitive or commonly used words.
For example, while studying data collected from African countries to understand the most pressing issues people face, researchers might find “food” and “hunger” are the most commonly used words and will highlight them for further analysis.
LEARN ABOUT: Level of Analysis
The keyword context is another widely used word-based technique. In this method, the researcher tries to understand the concept by analyzing the context in which the participants use a particular keyword.
For example , researchers conducting research and data analysis for studying the concept of ‘diabetes’ amongst respondents might analyze the context of when and how the respondent has used or referred to the word ‘diabetes.’
The scrutiny-based technique is also one of the highly recommended text analysis methods used to identify a quality data pattern. Compare and contrast is the widely used method under this technique to differentiate how a specific text is similar or different from each other.
For example: To find out the “importance of resident doctor in a company,” the collected data is divided into people who think it is necessary to hire a resident doctor and those who think it is unnecessary. Compare and contrast is the best method that can be used to analyze the polls having single-answer questions types .
Metaphors can be used to reduce the data pile and find patterns in it so that it becomes easier to connect data with theory.
Variable Partitioning is another technique used to split variables so that researchers can find more coherent descriptions and explanations from the enormous data.
LEARN ABOUT: Qualitative Research Questions and Questionnaires
There are several techniques to analyze the data in qualitative research, but here are some commonly used methods,
- Content Analysis: It is widely accepted and the most frequently employed technique for data analysis in research methodology. It can be used to analyze the documented information from text, images, and sometimes from the physical items. It depends on the research questions to predict when and where to use this method.
- Narrative Analysis: This method is used to analyze content gathered from various sources such as personal interviews, field observation, and surveys . The majority of times, stories, or opinions shared by people are focused on finding answers to the research questions.
- Discourse Analysis: Similar to narrative analysis, discourse analysis is used to analyze the interactions with people. Nevertheless, this particular method considers the social context under which or within which the communication between the researcher and respondent takes place. In addition to that, discourse analysis also focuses on the lifestyle and day-to-day environment while deriving any conclusion.
- Grounded Theory: When you want to explain why a particular phenomenon happened, then using grounded theory for analyzing quality data is the best resort. Grounded theory is applied to study data about the host of similar cases occurring in different settings. When researchers are using this method, they might alter explanations or produce new ones until they arrive at some conclusion.
LEARN ABOUT: 12 Best Tools for Researchers
Data analysis in quantitative research
The first stage in research and data analysis is to make it for the analysis so that the nominal data can be converted into something meaningful. Data preparation consists of the below phases.
Phase I: Data Validation
Data validation is done to understand if the collected data sample is per the pre-set standards, or it is a biased data sample again divided into four different stages
- Fraud: To ensure an actual human being records each response to the survey or the questionnaire
- Screening: To make sure each participant or respondent is selected or chosen in compliance with the research criteria
- Procedure: To ensure ethical standards were maintained while collecting the data sample
- Completeness: To ensure that the respondent has answered all the questions in an online survey. Else, the interviewer had asked all the questions devised in the questionnaire.
Phase II: Data Editing
More often, an extensive research data sample comes loaded with errors. Respondents sometimes fill in some fields incorrectly or sometimes skip them accidentally. Data editing is a process wherein the researchers have to confirm that the provided data is free of such errors. They need to conduct necessary checks and outlier checks to edit the raw edit and make it ready for analysis.
Phase III: Data Coding
Out of all three, this is the most critical phase of data preparation associated with grouping and assigning values to the survey responses . If a survey is completed with a 1000 sample size, the researcher will create an age bracket to distinguish the respondents based on their age. Thus, it becomes easier to analyze small data buckets rather than deal with the massive data pile.
LEARN ABOUT: Steps in Qualitative Research
After the data is prepared for analysis, researchers are open to using different research and data analysis methods to derive meaningful insights. For sure, statistical analysis plans are the most favored to analyze numerical data. In statistical analysis, distinguishing between categorical data and numerical data is essential, as categorical data involves distinct categories or labels, while numerical data consists of measurable quantities. The method is again classified into two groups. First, ‘Descriptive Statistics’ used to describe data. Second, ‘Inferential statistics’ that helps in comparing the data .
Descriptive statistics
This method is used to describe the basic features of versatile types of data in research. It presents the data in such a meaningful way that pattern in the data starts making sense. Nevertheless, the descriptive analysis does not go beyond making conclusions. The conclusions are again based on the hypothesis researchers have formulated so far. Here are a few major types of descriptive analysis methods.
Measures of Frequency
- Count, Percent, Frequency
- It is used to denote home often a particular event occurs.
- Researchers use it when they want to showcase how often a response is given.
Measures of Central Tendency
- Mean, Median, Mode
- The method is widely used to demonstrate distribution by various points.
- Researchers use this method when they want to showcase the most commonly or averagely indicated response.
Measures of Dispersion or Variation
- Range, Variance, Standard deviation
- Here the field equals high/low points.
- Variance standard deviation = difference between the observed score and mean
- It is used to identify the spread of scores by stating intervals.
- Researchers use this method to showcase data spread out. It helps them identify the depth until which the data is spread out that it directly affects the mean.
Measures of Position
- Percentile ranks, Quartile ranks
- It relies on standardized scores helping researchers to identify the relationship between different scores.
- It is often used when researchers want to compare scores with the average count.
For quantitative research use of descriptive analysis often give absolute numbers, but the in-depth analysis is never sufficient to demonstrate the rationale behind those numbers. Nevertheless, it is necessary to think of the best method for research and data analysis suiting your survey questionnaire and what story researchers want to tell. For example, the mean is the best way to demonstrate the students’ average scores in schools. It is better to rely on the descriptive statistics when the researchers intend to keep the research or outcome limited to the provided sample without generalizing it. For example, when you want to compare average voting done in two different cities, differential statistics are enough.
Descriptive analysis is also called a ‘univariate analysis’ since it is commonly used to analyze a single variable.
Inferential statistics
Inferential statistics are used to make predictions about a larger population after research and data analysis of the representing population’s collected sample. For example, you can ask some odd 100 audiences at a movie theater if they like the movie they are watching. Researchers then use inferential statistics on the collected sample to reason that about 80-90% of people like the movie.
Here are two significant areas of inferential statistics.
- Estimating parameters: It takes statistics from the sample research data and demonstrates something about the population parameter.
- Hypothesis test: I t’s about sampling research data to answer the survey research questions. For example, researchers might be interested to understand if the new shade of lipstick recently launched is good or not, or if the multivitamin capsules help children to perform better at games.
These are sophisticated analysis methods used to showcase the relationship between different variables instead of describing a single variable. It is often used when researchers want something beyond absolute numbers to understand the relationship between variables.
Here are some of the commonly used methods for data analysis in research.
- Correlation: When researchers are not conducting experimental research or quasi-experimental research wherein the researchers are interested to understand the relationship between two or more variables, they opt for correlational research methods.
- Cross-tabulation: Also called contingency tables, cross-tabulation is used to analyze the relationship between multiple variables. Suppose provided data has age and gender categories presented in rows and columns. A two-dimensional cross-tabulation helps for seamless data analysis and research by showing the number of males and females in each age category.
- Regression analysis: For understanding the strong relationship between two variables, researchers do not look beyond the primary and commonly used regression analysis method, which is also a type of predictive analysis used. In this method, you have an essential factor called the dependent variable. You also have multiple independent variables in regression analysis. You undertake efforts to find out the impact of independent variables on the dependent variable. The values of both independent and dependent variables are assumed as being ascertained in an error-free random manner.
- Frequency tables: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Analysis of variance: The statistical procedure is used for testing the degree to which two or more vary or differ in an experiment. A considerable degree of variation means research findings were significant. In many contexts, ANOVA testing and variance analysis are similar.
- Researchers must have the necessary research skills to analyze and manipulation the data , Getting trained to demonstrate a high standard of research practice. Ideally, researchers must possess more than a basic understanding of the rationale of selecting one statistical method over the other to obtain better data insights.
- Usually, research and data analytics projects differ by scientific discipline; therefore, getting statistical advice at the beginning of analysis helps design a survey questionnaire, select data collection methods , and choose samples.
LEARN ABOUT: Best Data Collection Tools
- The primary aim of data research and analysis is to derive ultimate insights that are unbiased. Any mistake in or keeping a biased mind to collect data, selecting an analysis method, or choosing audience sample il to draw a biased inference.
- Irrelevant to the sophistication used in research data and analysis is enough to rectify the poorly defined objective outcome measurements. It does not matter if the design is at fault or intentions are not clear, but lack of clarity might mislead readers, so avoid the practice.
- The motive behind data analysis in research is to present accurate and reliable data. As far as possible, avoid statistical errors, and find a way to deal with everyday challenges like outliers, missing data, data altering, data mining , or developing graphical representation.
LEARN MORE: Descriptive Research vs Correlational Research The sheer amount of data generated daily is frightening. Especially when data analysis has taken center stage. in 2018. In last year, the total data supply amounted to 2.8 trillion gigabytes. Hence, it is clear that the enterprises willing to survive in the hypercompetitive world must possess an excellent capability to analyze complex research data, derive actionable insights, and adapt to the new market needs.
LEARN ABOUT: Average Order Value
QuestionPro is an online survey platform that empowers organizations in data analysis and research and provides them a medium to collect data by creating appealing surveys.
MORE LIKE THIS

NPS Survey Platform: Types, Tips, 11 Best Platforms & Tools
Apr 26, 2024

User Journey vs User Flow: Differences and Similarities

Best 7 Gap Analysis Tools to Empower Your Business
Apr 25, 2024

12 Best Employee Survey Tools for Organizational Excellence
Other categories.
- Academic Research
- Artificial Intelligence
- Assessments
- Brand Awareness
- Case Studies
- Communities
- Consumer Insights
- Customer effort score
- Customer Engagement
- Customer Experience
- Customer Loyalty
- Customer Research
- Customer Satisfaction
- Employee Benefits
- Employee Engagement
- Employee Retention
- Friday Five
- General Data Protection Regulation
- Insights Hub
- Life@QuestionPro
- Market Research
- Mobile diaries
- Mobile Surveys
- New Features
- Online Communities
- Question Types
- Questionnaire
- QuestionPro Products
- Release Notes
- Research Tools and Apps
- Revenue at Risk
- Survey Templates
- Training Tips
- Uncategorized
- Video Learning Series
- What’s Coming Up
- Workforce Intelligence
Quantitative Data Analysis 101
The lingo, methods and techniques, explained simply.
By: Derek Jansen (MBA) and Kerryn Warren (PhD) | December 2020
Quantitative data analysis is one of those things that often strikes fear in students. It’s totally understandable – quantitative analysis is a complex topic, full of daunting lingo , like medians, modes, correlation and regression. Suddenly we’re all wishing we’d paid a little more attention in math class…
The good news is that while quantitative data analysis is a mammoth topic, gaining a working understanding of the basics isn’t that hard , even for those of us who avoid numbers and math . In this post, we’ll break quantitative analysis down into simple , bite-sized chunks so you can approach your research with confidence.

Overview: Quantitative Data Analysis 101
- What (exactly) is quantitative data analysis?
- When to use quantitative analysis
- How quantitative analysis works
The two “branches” of quantitative analysis
- Descriptive statistics 101
- Inferential statistics 101
- How to choose the right quantitative methods
- Recap & summary
What is quantitative data analysis?
Despite being a mouthful, quantitative data analysis simply means analysing data that is numbers-based – or data that can be easily “converted” into numbers without losing any meaning.
For example, category-based variables like gender, ethnicity, or native language could all be “converted” into numbers without losing meaning – for example, English could equal 1, French 2, etc.
This contrasts against qualitative data analysis, where the focus is on words, phrases and expressions that can’t be reduced to numbers. If you’re interested in learning about qualitative analysis, check out our post and video here .
What is quantitative analysis used for?
Quantitative analysis is generally used for three purposes.
- Firstly, it’s used to measure differences between groups . For example, the popularity of different clothing colours or brands.
- Secondly, it’s used to assess relationships between variables . For example, the relationship between weather temperature and voter turnout.
- And third, it’s used to test hypotheses in a scientifically rigorous way. For example, a hypothesis about the impact of a certain vaccine.
Again, this contrasts with qualitative analysis , which can be used to analyse people’s perceptions and feelings about an event or situation. In other words, things that can’t be reduced to numbers.
How does quantitative analysis work?
Well, since quantitative data analysis is all about analysing numbers , it’s no surprise that it involves statistics . Statistical analysis methods form the engine that powers quantitative analysis, and these methods can vary from pretty basic calculations (for example, averages and medians) to more sophisticated analyses (for example, correlations and regressions).
Sounds like gibberish? Don’t worry. We’ll explain all of that in this post. Importantly, you don’t need to be a statistician or math wiz to pull off a good quantitative analysis. We’ll break down all the technical mumbo jumbo in this post.
Need a helping hand?
As I mentioned, quantitative analysis is powered by statistical analysis methods . There are two main “branches” of statistical methods that are used – descriptive statistics and inferential statistics . In your research, you might only use descriptive statistics, or you might use a mix of both , depending on what you’re trying to figure out. In other words, depending on your research questions, aims and objectives . I’ll explain how to choose your methods later.
So, what are descriptive and inferential statistics?
Well, before I can explain that, we need to take a quick detour to explain some lingo. To understand the difference between these two branches of statistics, you need to understand two important words. These words are population and sample .
First up, population . In statistics, the population is the entire group of people (or animals or organisations or whatever) that you’re interested in researching. For example, if you were interested in researching Tesla owners in the US, then the population would be all Tesla owners in the US.
However, it’s extremely unlikely that you’re going to be able to interview or survey every single Tesla owner in the US. Realistically, you’ll likely only get access to a few hundred, or maybe a few thousand owners using an online survey. This smaller group of accessible people whose data you actually collect is called your sample .
So, to recap – the population is the entire group of people you’re interested in, and the sample is the subset of the population that you can actually get access to. In other words, the population is the full chocolate cake , whereas the sample is a slice of that cake.
So, why is this sample-population thing important?
Well, descriptive statistics focus on describing the sample , while inferential statistics aim to make predictions about the population, based on the findings within the sample. In other words, we use one group of statistical methods – descriptive statistics – to investigate the slice of cake, and another group of methods – inferential statistics – to draw conclusions about the entire cake. There I go with the cake analogy again…
With that out the way, let’s take a closer look at each of these branches in more detail.

Branch 1: Descriptive Statistics
Descriptive statistics serve a simple but critically important role in your research – to describe your data set – hence the name. In other words, they help you understand the details of your sample . Unlike inferential statistics (which we’ll get to soon), descriptive statistics don’t aim to make inferences or predictions about the entire population – they’re purely interested in the details of your specific sample .
When you’re writing up your analysis, descriptive statistics are the first set of stats you’ll cover, before moving on to inferential statistics. But, that said, depending on your research objectives and research questions , they may be the only type of statistics you use. We’ll explore that a little later.
So, what kind of statistics are usually covered in this section?
Some common statistical tests used in this branch include the following:
- Mean – this is simply the mathematical average of a range of numbers.
- Median – this is the midpoint in a range of numbers when the numbers are arranged in numerical order. If the data set makes up an odd number, then the median is the number right in the middle of the set. If the data set makes up an even number, then the median is the midpoint between the two middle numbers.
- Mode – this is simply the most commonly occurring number in the data set.
- In cases where most of the numbers are quite close to the average, the standard deviation will be relatively low.
- Conversely, in cases where the numbers are scattered all over the place, the standard deviation will be relatively high.
- Skewness . As the name suggests, skewness indicates how symmetrical a range of numbers is. In other words, do they tend to cluster into a smooth bell curve shape in the middle of the graph, or do they skew to the left or right?
Feeling a bit confused? Let’s look at a practical example using a small data set.

On the left-hand side is the data set. This details the bodyweight of a sample of 10 people. On the right-hand side, we have the descriptive statistics. Let’s take a look at each of them.
First, we can see that the mean weight is 72.4 kilograms. In other words, the average weight across the sample is 72.4 kilograms. Straightforward.
Next, we can see that the median is very similar to the mean (the average). This suggests that this data set has a reasonably symmetrical distribution (in other words, a relatively smooth, centred distribution of weights, clustered towards the centre).
In terms of the mode , there is no mode in this data set. This is because each number is present only once and so there cannot be a “most common number”. If there were two people who were both 65 kilograms, for example, then the mode would be 65.
Next up is the standard deviation . 10.6 indicates that there’s quite a wide spread of numbers. We can see this quite easily by looking at the numbers themselves, which range from 55 to 90, which is quite a stretch from the mean of 72.4.
And lastly, the skewness of -0.2 tells us that the data is very slightly negatively skewed. This makes sense since the mean and the median are slightly different.
As you can see, these descriptive statistics give us some useful insight into the data set. Of course, this is a very small data set (only 10 records), so we can’t read into these statistics too much. Also, keep in mind that this is not a list of all possible descriptive statistics – just the most common ones.
But why do all of these numbers matter?
While these descriptive statistics are all fairly basic, they’re important for a few reasons:
- Firstly, they help you get both a macro and micro-level view of your data. In other words, they help you understand both the big picture and the finer details.
- Secondly, they help you spot potential errors in the data – for example, if an average is way higher than you’d expect, or responses to a question are highly varied, this can act as a warning sign that you need to double-check the data.
- And lastly, these descriptive statistics help inform which inferential statistical techniques you can use, as those techniques depend on the skewness (in other words, the symmetry and normality) of the data.
Simply put, descriptive statistics are really important , even though the statistical techniques used are fairly basic. All too often at Grad Coach, we see students skimming over the descriptives in their eagerness to get to the more exciting inferential methods, and then landing up with some very flawed results.
Don’t be a sucker – give your descriptive statistics the love and attention they deserve!

Branch 2: Inferential Statistics
As I mentioned, while descriptive statistics are all about the details of your specific data set – your sample – inferential statistics aim to make inferences about the population . In other words, you’ll use inferential statistics to make predictions about what you’d expect to find in the full population.
What kind of predictions, you ask? Well, there are two common types of predictions that researchers try to make using inferential stats:
- Firstly, predictions about differences between groups – for example, height differences between children grouped by their favourite meal or gender.
- And secondly, relationships between variables – for example, the relationship between body weight and the number of hours a week a person does yoga.
In other words, inferential statistics (when done correctly), allow you to connect the dots and make predictions about what you expect to see in the real world population, based on what you observe in your sample data. For this reason, inferential statistics are used for hypothesis testing – in other words, to test hypotheses that predict changes or differences.

Of course, when you’re working with inferential statistics, the composition of your sample is really important. In other words, if your sample doesn’t accurately represent the population you’re researching, then your findings won’t necessarily be very useful.
For example, if your population of interest is a mix of 50% male and 50% female , but your sample is 80% male , you can’t make inferences about the population based on your sample, since it’s not representative. This area of statistics is called sampling, but we won’t go down that rabbit hole here (it’s a deep one!) – we’ll save that for another post .
What statistics are usually used in this branch?
There are many, many different statistical analysis methods within the inferential branch and it’d be impossible for us to discuss them all here. So we’ll just take a look at some of the most common inferential statistical methods so that you have a solid starting point.
First up are T-Tests . T-tests compare the means (the averages) of two groups of data to assess whether they’re statistically significantly different. In other words, do they have significantly different means, standard deviations and skewness.
This type of testing is very useful for understanding just how similar or different two groups of data are. For example, you might want to compare the mean blood pressure between two groups of people – one that has taken a new medication and one that hasn’t – to assess whether they are significantly different.
Kicking things up a level, we have ANOVA, which stands for “analysis of variance”. This test is similar to a T-test in that it compares the means of various groups, but ANOVA allows you to analyse multiple groups , not just two groups So it’s basically a t-test on steroids…
Next, we have correlation analysis . This type of analysis assesses the relationship between two variables. In other words, if one variable increases, does the other variable also increase, decrease or stay the same. For example, if the average temperature goes up, do average ice creams sales increase too? We’d expect some sort of relationship between these two variables intuitively , but correlation analysis allows us to measure that relationship scientifically .
Lastly, we have regression analysis – this is quite similar to correlation in that it assesses the relationship between variables, but it goes a step further to understand cause and effect between variables, not just whether they move together. In other words, does the one variable actually cause the other one to move, or do they just happen to move together naturally thanks to another force? Just because two variables correlate doesn’t necessarily mean that one causes the other.
Stats overload…
I hear you. To make this all a little more tangible, let’s take a look at an example of a correlation in action.
Here’s a scatter plot demonstrating the correlation (relationship) between weight and height. Intuitively, we’d expect there to be some relationship between these two variables, which is what we see in this scatter plot. In other words, the results tend to cluster together in a diagonal line from bottom left to top right.

As I mentioned, these are are just a handful of inferential techniques – there are many, many more. Importantly, each statistical method has its own assumptions and limitations.
For example, some methods only work with normally distributed (parametric) data, while other methods are designed specifically for non-parametric data. And that’s exactly why descriptive statistics are so important – they’re the first step to knowing which inferential techniques you can and can’t use.

How to choose the right analysis method
To choose the right statistical methods, you need to think about two important factors :
- The type of quantitative data you have (specifically, level of measurement and the shape of the data). And,
- Your research questions and hypotheses
Let’s take a closer look at each of these.
Factor 1 – Data type
The first thing you need to consider is the type of data you’ve collected (or the type of data you will collect). By data types, I’m referring to the four levels of measurement – namely, nominal, ordinal, interval and ratio. If you’re not familiar with this lingo, check out the video below.
Why does this matter?
Well, because different statistical methods and techniques require different types of data. This is one of the “assumptions” I mentioned earlier – every method has its assumptions regarding the type of data.
For example, some techniques work with categorical data (for example, yes/no type questions, or gender or ethnicity), while others work with continuous numerical data (for example, age, weight or income) – and, of course, some work with multiple data types.
If you try to use a statistical method that doesn’t support the data type you have, your results will be largely meaningless . So, make sure that you have a clear understanding of what types of data you’ve collected (or will collect). Once you have this, you can then check which statistical methods would support your data types here .
If you haven’t collected your data yet, you can work in reverse and look at which statistical method would give you the most useful insights, and then design your data collection strategy to collect the correct data types.
Another important factor to consider is the shape of your data . Specifically, does it have a normal distribution (in other words, is it a bell-shaped curve, centred in the middle) or is it very skewed to the left or the right? Again, different statistical techniques work for different shapes of data – some are designed for symmetrical data while others are designed for skewed data.
This is another reminder of why descriptive statistics are so important – they tell you all about the shape of your data.
Factor 2: Your research questions
The next thing you need to consider is your specific research questions, as well as your hypotheses (if you have some). The nature of your research questions and research hypotheses will heavily influence which statistical methods and techniques you should use.
If you’re just interested in understanding the attributes of your sample (as opposed to the entire population), then descriptive statistics are probably all you need. For example, if you just want to assess the means (averages) and medians (centre points) of variables in a group of people.
On the other hand, if you aim to understand differences between groups or relationships between variables and to infer or predict outcomes in the population, then you’ll likely need both descriptive statistics and inferential statistics.
So, it’s really important to get very clear about your research aims and research questions, as well your hypotheses – before you start looking at which statistical techniques to use.
Never shoehorn a specific statistical technique into your research just because you like it or have some experience with it. Your choice of methods must align with all the factors we’ve covered here.
Time to recap…
You’re still with me? That’s impressive. We’ve covered a lot of ground here, so let’s recap on the key points:
- Quantitative data analysis is all about analysing number-based data (which includes categorical and numerical data) using various statistical techniques.
- The two main branches of statistics are descriptive statistics and inferential statistics . Descriptives describe your sample, whereas inferentials make predictions about what you’ll find in the population.
- Common descriptive statistical methods include mean (average), median , standard deviation and skewness .
- Common inferential statistical methods include t-tests , ANOVA , correlation and regression analysis.
- To choose the right statistical methods and techniques, you need to consider the type of data you’re working with , as well as your research questions and hypotheses.

Psst... there’s more!
This post was based on one of our popular Research Bootcamps . If you're working on a research project, you'll definitely want to check this out ...
You Might Also Like:
")
74 Comments

Hi, I have read your article. Such a brilliant post you have created.

Thank you for the feedback. Good luck with your quantitative analysis.

Thank you so much.

Thank you so much. I learnt much well. I love your summaries of the concepts. I had love you to explain how to input data using SPSS

Amazing and simple way of breaking down quantitative methods.

This is beautiful….especially for non-statisticians. I have skimmed through but I wish to read again. and please include me in other articles of the same nature when you do post. I am interested. I am sure, I could easily learn from you and get off the fear that I have had in the past. Thank you sincerely.

Send me every new information you might have.

i need every new information

Thank you for the blog. It is quite informative. Dr Peter Nemaenzhe PhD

It is wonderful. l’ve understood some of the concepts in a more compréhensive manner

Your article is so good! However, I am still a bit lost. I am doing a secondary research on Gun control in the US and increase in crime rates and I am not sure which analysis method I should use?

Based on the given learning points, this is inferential analysis, thus, use ‘t-tests, ANOVA, correlation and regression analysis’

Well explained notes. Am an MPH student and currently working on my thesis proposal, this has really helped me understand some of the things I didn’t know.

I like your page..helpful

wonderful i got my concept crystal clear. thankyou!!

This is really helpful , thank you

Thank you so much this helped

Wonderfully explained

thank u so much, it was so informative

THANKYOU, this was very informative and very helpful

This is great GRADACOACH I am not a statistician but I require more of this in my thesis
Include me in your posts.

This is so great and fully useful. I would like to thank you again and again.

Glad to read this article. I’ve read lot of articles but this article is clear on all concepts. Thanks for sharing.

Thank you so much. This is a very good foundation and intro into quantitative data analysis. Appreciate!

You have a very impressive, simple but concise explanation of data analysis for Quantitative Research here. This is a God-send link for me to appreciate research more. Thank you so much!

Avery good presentation followed by the write up. yes you simplified statistics to make sense even to a layman like me. Thank so much keep it up. The presenter did ell too. i would like more of this for Qualitative and exhaust more of the test example like the Anova.

This is a very helpful article, couldn’t have been clearer. Thank you.

Awesome and phenomenal information.Well done

The video with the accompanying article is super helpful to demystify this topic. Very well done. Thank you so much.

thank you so much, your presentation helped me a lot

I don’t know how should I express that ur article is saviour for me 🥺😍

It is well defined information and thanks for sharing. It helps me a lot in understanding the statistical data.

I gain a lot and thanks for sharing brilliant ideas, so wish to be linked on your email update.

Very helpful and clear .Thank you Gradcoach.

Thank for sharing this article, well organized and information presented are very clear.

VERY INTERESTING AND SUPPORTIVE TO NEW RESEARCHERS LIKE ME. AT LEAST SOME BASICS ABOUT QUANTITATIVE.

An outstanding, well explained and helpful article. This will help me so much with my data analysis for my research project. Thank you!

wow this has just simplified everything i was scared of how i am gonna analyse my data but thanks to you i will be able to do so

simple and constant direction to research. thanks

This is helpful

Great writing!! Comprehensive and very helpful.

Do you provide any assistance for other steps of research methodology like making research problem testing hypothesis report and thesis writing?

Thank you so much for such useful article!

Amazing article. So nicely explained. Wow

Very insightfull. Thanks

I am doing a quality improvement project to determine if the implementation of a protocol will change prescribing habits. Would this be a t-test?

The is a very helpful blog, however, I’m still not sure how to analyze my data collected. I’m doing a research on “Free Education at the University of Guyana”

tnx. fruitful blog!

So I am writing exams and would like to know how do establish which method of data analysis to use from the below research questions: I am a bit lost as to how I determine the data analysis method from the research questions.
Do female employees report higher job satisfaction than male employees with similar job descriptions across the South African telecommunications sector? – I though that maybe Chi Square could be used here. – Is there a gender difference in talented employees’ actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – Is there a gender difference in the cost of actual turnover decisions across the South African telecommunications sector? T-tests or Correlation in this one. – What practical recommendations can be made to the management of South African telecommunications companies on leveraging gender to mitigate employee turnover decisions?
Your assistance will be appreciated if I could get a response as early as possible tomorrow

This was quite helpful. Thank you so much.

wow I got a lot from this article, thank you very much, keep it up

Thanks for yhe guidance. Can you send me this guidance on my email? To enable offline reading?

Thank you very much, this service is very helpful.

Every novice researcher needs to read this article as it puts things so clear and easy to follow. Its been very helpful.

Wonderful!!!! you explained everything in a way that anyone can learn. Thank you!!

I really enjoyed reading though this. Very easy to follow. Thank you

Many thanks for your useful lecture, I would be really appreciated if you could possibly share with me the PPT of presentation related to Data type?

Thank you very much for sharing, I got much from this article

This is a very informative write-up. Kindly include me in your latest posts.

Very interesting mostly for social scientists

Thank you so much, very helpfull
You’re welcome 🙂

woow, its great, its very informative and well understood because of your way of writing like teaching in front of me in simple languages.

I have been struggling to understand a lot of these concepts. Thank you for the informative piece which is written with outstanding clarity.

very informative article. Easy to understand

Beautiful read, much needed.

Always greet intro and summary. I learn so much from GradCoach

Quite informative. Simple and clear summary.

I thoroughly enjoyed reading your informative and inspiring piece. Your profound insights into this topic truly provide a better understanding of its complexity. I agree with the points you raised, especially when you delved into the specifics of the article. In my opinion, that aspect is often overlooked and deserves further attention.

Absolutely!!! Thank you

Thank you very much for this post. It made me to understand how to do my data analysis.
Submit a Comment Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
- Print Friendly

A Step-by-Step Guide to the Data Analysis Process

Like any scientific discipline, data analysis follows a rigorous step-by-step process. Each stage requires different skills and know-how. To get meaningful insights, though, it’s important to understand the process as a whole. An underlying framework is invaluable for producing results that stand up to scrutiny.
In this post, we’ll explore the main steps in the data analysis process. This will cover how to define your goal, collect data, and carry out an analysis. Where applicable, we’ll also use examples and highlight a few tools to make the journey easier. When you’re done, you’ll have a much better understanding of the basics. This will help you tweak the process to fit your own needs.
Here are the steps we’ll take you through:
- Defining the question
- Collecting the data
- Cleaning the data
- Analyzing the data
- Sharing your results
- Embracing failure
On popular request, we’ve also developed a video based on this article. Scroll further along this article to watch that.

Ready? Let’s get started with step one.
1. Step one: Defining the question
The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the ‘problem statement’.
Defining your objective means coming up with a hypothesis and figuring how to test it. Start by asking: What business problem am I trying to solve? While this might sound straightforward, it can be trickier than it seems. For instance, your organization’s senior management might pose an issue, such as: “Why are we losing customers?” It’s possible, though, that this doesn’t get to the core of the problem. A data analyst’s job is to understand the business and its goals in enough depth that they can frame the problem the right way.
Let’s say you work for a fictional company called TopNotch Learning. TopNotch creates custom training software for its clients. While it is excellent at securing new clients, it has much lower repeat business. As such, your question might not be, “Why are we losing customers?” but, “Which factors are negatively impacting the customer experience?” or better yet: “How can we boost customer retention while minimizing costs?”
Now you’ve defined a problem, you need to determine which sources of data will best help you solve it. This is where your business acumen comes in again. For instance, perhaps you’ve noticed that the sales process for new clients is very slick, but that the production team is inefficient. Knowing this, you could hypothesize that the sales process wins lots of new clients, but the subsequent customer experience is lacking. Could this be why customers don’t come back? Which sources of data will help you answer this question?
Tools to help define your objective
Defining your objective is mostly about soft skills, business knowledge, and lateral thinking. But you’ll also need to keep track of business metrics and key performance indicators (KPIs). Monthly reports can allow you to track problem points in the business. Some KPI dashboards come with a fee, like Databox and DashThis . However, you’ll also find open-source software like Grafana , Freeboard , and Dashbuilder . These are great for producing simple dashboards, both at the beginning and the end of the data analysis process.
2. Step two: Collecting the data
Once you’ve established your objective, you’ll need to create a strategy for collecting and aggregating the appropriate data. A key part of this is determining which data you need. This might be quantitative (numeric) data, e.g. sales figures, or qualitative (descriptive) data, such as customer reviews. All data fit into one of three categories: first-party, second-party, and third-party data. Let’s explore each one.
What is first-party data?
First-party data are data that you, or your company, have directly collected from customers. It might come in the form of transactional tracking data or information from your company’s customer relationship management (CRM) system. Whatever its source, first-party data is usually structured and organized in a clear, defined way. Other sources of first-party data might include customer satisfaction surveys, focus groups, interviews, or direct observation.
What is second-party data?
To enrich your analysis, you might want to secure a secondary data source. Second-party data is the first-party data of other organizations. This might be available directly from the company or through a private marketplace. The main benefit of second-party data is that they are usually structured, and although they will be less relevant than first-party data, they also tend to be quite reliable. Examples of second-party data include website, app or social media activity, like online purchase histories, or shipping data.
What is third-party data?
Third-party data is data that has been collected and aggregated from numerous sources by a third-party organization. Often (though not always) third-party data contains a vast amount of unstructured data points (big data). Many organizations collect big data to create industry reports or to conduct market research. The research and advisory firm Gartner is a good real-world example of an organization that collects big data and sells it on to other companies. Open data repositories and government portals are also sources of third-party data .
Tools to help you collect data
Once you’ve devised a data strategy (i.e. you’ve identified which data you need, and how best to go about collecting them) there are many tools you can use to help you. One thing you’ll need, regardless of industry or area of expertise, is a data management platform (DMP). A DMP is a piece of software that allows you to identify and aggregate data from numerous sources, before manipulating them, segmenting them, and so on. There are many DMPs available. Some well-known enterprise DMPs include Salesforce DMP , SAS , and the data integration platform, Xplenty . If you want to play around, you can also try some open-source platforms like Pimcore or D:Swarm .
Want to learn more about what data analytics is and the process a data analyst follows? We cover this topic (and more) in our free introductory short course for beginners. Check out tutorial one: An introduction to data analytics .
3. Step three: Cleaning the data
Once you’ve collected your data, the next step is to get it ready for analysis. This means cleaning, or ‘scrubbing’ it, and is crucial in making sure that you’re working with high-quality data . Key data cleaning tasks include:
- Removing major errors, duplicates, and outliers —all of which are inevitable problems when aggregating data from numerous sources.
- Removing unwanted data points —extracting irrelevant observations that have no bearing on your intended analysis.
- Bringing structure to your data —general ‘housekeeping’, i.e. fixing typos or layout issues, which will help you map and manipulate your data more easily.
- Filling in major gaps —as you’re tidying up, you might notice that important data are missing. Once you’ve identified gaps, you can go about filling them.
A good data analyst will spend around 70-90% of their time cleaning their data. This might sound excessive. But focusing on the wrong data points (or analyzing erroneous data) will severely impact your results. It might even send you back to square one…so don’t rush it! You’ll find a step-by-step guide to data cleaning here . You may be interested in this introductory tutorial to data cleaning, hosted by Dr. Humera Noor Minhas.
Carrying out an exploratory analysis
Another thing many data analysts do (alongside cleaning data) is to carry out an exploratory analysis. This helps identify initial trends and characteristics, and can even refine your hypothesis. Let’s use our fictional learning company as an example again. Carrying out an exploratory analysis, perhaps you notice a correlation between how much TopNotch Learning’s clients pay and how quickly they move on to new suppliers. This might suggest that a low-quality customer experience (the assumption in your initial hypothesis) is actually less of an issue than cost. You might, therefore, take this into account.
Tools to help you clean your data
Cleaning datasets manually—especially large ones—can be daunting. Luckily, there are many tools available to streamline the process. Open-source tools, such as OpenRefine , are excellent for basic data cleaning, as well as high-level exploration. However, free tools offer limited functionality for very large datasets. Python libraries (e.g. Pandas) and some R packages are better suited for heavy data scrubbing. You will, of course, need to be familiar with the languages. Alternatively, enterprise tools are also available. For example, Data Ladder , which is one of the highest-rated data-matching tools in the industry. There are many more. Why not see which free data cleaning tools you can find to play around with?
4. Step four: Analyzing the data
Finally, you’ve cleaned your data. Now comes the fun bit—analyzing it! The type of data analysis you carry out largely depends on what your goal is. But there are many techniques available. Univariate or bivariate analysis, time-series analysis, and regression analysis are just a few you might have heard of. More important than the different types, though, is how you apply them. This depends on what insights you’re hoping to gain. Broadly speaking, all types of data analysis fit into one of the following four categories.
Descriptive analysis
Descriptive analysis identifies what has already happened . It is a common first step that companies carry out before proceeding with deeper explorations. As an example, let’s refer back to our fictional learning provider once more. TopNotch Learning might use descriptive analytics to analyze course completion rates for their customers. Or they might identify how many users access their products during a particular period. Perhaps they’ll use it to measure sales figures over the last five years. While the company might not draw firm conclusions from any of these insights, summarizing and describing the data will help them to determine how to proceed.
Learn more: What is descriptive analytics?
Diagnostic analysis
Diagnostic analytics focuses on understanding why something has happened . It is literally the diagnosis of a problem, just as a doctor uses a patient’s symptoms to diagnose a disease. Remember TopNotch Learning’s business problem? ‘Which factors are negatively impacting the customer experience?’ A diagnostic analysis would help answer this. For instance, it could help the company draw correlations between the issue (struggling to gain repeat business) and factors that might be causing it (e.g. project costs, speed of delivery, customer sector, etc.) Let’s imagine that, using diagnostic analytics, TopNotch realizes its clients in the retail sector are departing at a faster rate than other clients. This might suggest that they’re losing customers because they lack expertise in this sector. And that’s a useful insight!
Predictive analysis
Predictive analysis allows you to identify future trends based on historical data . In business, predictive analysis is commonly used to forecast future growth, for example. But it doesn’t stop there. Predictive analysis has grown increasingly sophisticated in recent years. The speedy evolution of machine learning allows organizations to make surprisingly accurate forecasts. Take the insurance industry. Insurance providers commonly use past data to predict which customer groups are more likely to get into accidents. As a result, they’ll hike up customer insurance premiums for those groups. Likewise, the retail industry often uses transaction data to predict where future trends lie, or to determine seasonal buying habits to inform their strategies. These are just a few simple examples, but the untapped potential of predictive analysis is pretty compelling.
Prescriptive analysis
Prescriptive analysis allows you to make recommendations for the future. This is the final step in the analytics part of the process. It’s also the most complex. This is because it incorporates aspects of all the other analyses we’ve described. A great example of prescriptive analytics is the algorithms that guide Google’s self-driving cars. Every second, these algorithms make countless decisions based on past and present data, ensuring a smooth, safe ride. Prescriptive analytics also helps companies decide on new products or areas of business to invest in.
Learn more: What are the different types of data analysis?
5. Step five: Sharing your results
You’ve finished carrying out your analyses. You have your insights. The final step of the data analytics process is to share these insights with the wider world (or at least with your organization’s stakeholders!) This is more complex than simply sharing the raw results of your work—it involves interpreting the outcomes, and presenting them in a manner that’s digestible for all types of audiences. Since you’ll often present information to decision-makers, it’s very important that the insights you present are 100% clear and unambiguous. For this reason, data analysts commonly use reports, dashboards, and interactive visualizations to support their findings.
How you interpret and present results will often influence the direction of a business. Depending on what you share, your organization might decide to restructure, to launch a high-risk product, or even to close an entire division. That’s why it’s very important to provide all the evidence that you’ve gathered, and not to cherry-pick data. Ensuring that you cover everything in a clear, concise way will prove that your conclusions are scientifically sound and based on the facts. On the flip side, it’s important to highlight any gaps in the data or to flag any insights that might be open to interpretation. Honest communication is the most important part of the process. It will help the business, while also helping you to excel at your job!
Tools for interpreting and sharing your findings
There are tons of data visualization tools available, suited to different experience levels. Popular tools requiring little or no coding skills include Google Charts , Tableau , Datawrapper , and Infogram . If you’re familiar with Python and R, there are also many data visualization libraries and packages available. For instance, check out the Python libraries Plotly , Seaborn , and Matplotlib . Whichever data visualization tools you use, make sure you polish up your presentation skills, too. Remember: Visualization is great, but communication is key!
You can learn more about storytelling with data in this free, hands-on tutorial . We show you how to craft a compelling narrative for a real dataset, resulting in a presentation to share with key stakeholders. This is an excellent insight into what it’s really like to work as a data analyst!
6. Step six: Embrace your failures
The last ‘step’ in the data analytics process is to embrace your failures. The path we’ve described above is more of an iterative process than a one-way street. Data analytics is inherently messy, and the process you follow will be different for every project. For instance, while cleaning data, you might spot patterns that spark a whole new set of questions. This could send you back to step one (to redefine your objective). Equally, an exploratory analysis might highlight a set of data points you’d never considered using before. Or maybe you find that the results of your core analyses are misleading or erroneous. This might be caused by mistakes in the data, or human error earlier in the process.
While these pitfalls can feel like failures, don’t be disheartened if they happen. Data analysis is inherently chaotic, and mistakes occur. What’s important is to hone your ability to spot and rectify errors. If data analytics was straightforward, it might be easier, but it certainly wouldn’t be as interesting. Use the steps we’ve outlined as a framework, stay open-minded, and be creative. If you lose your way, you can refer back to the process to keep yourself on track.
In this post, we’ve covered the main steps of the data analytics process. These core steps can be amended, re-ordered and re-used as you deem fit, but they underpin every data analyst’s work:
- Define the question —What business problem are you trying to solve? Frame it as a question to help you focus on finding a clear answer.
- Collect data —Create a strategy for collecting data. Which data sources are most likely to help you solve your business problem?
- Clean the data —Explore, scrub, tidy, de-dupe, and structure your data as needed. Do whatever you have to! But don’t rush…take your time!
- Analyze the data —Carry out various analyses to obtain insights. Focus on the four types of data analysis: descriptive, diagnostic, predictive, and prescriptive.
- Share your results —How best can you share your insights and recommendations? A combination of visualization tools and communication is key.
- Embrace your mistakes —Mistakes happen. Learn from them. This is what transforms a good data analyst into a great one.
What next? From here, we strongly encourage you to explore the topic on your own. Get creative with the steps in the data analysis process, and see what tools you can find. As long as you stick to the core principles we’ve described, you can create a tailored technique that works for you.
To learn more, check out our free, 5-day data analytics short course . You might also be interested in the following:
- These are the top 9 data analytics tools
- 10 great places to find free datasets for your next project
- How to build a data analytics portfolio
- AI & NLP
- Churn & Loyalty
- Customer Experience
- Customer Journeys
- Customer Metrics
- Feedback Analysis
- Product Experience
- Product Updates
- Sentiment Analysis
- Surveys & Feedback Collection
- Try Thematic
Welcome to the community

Qualitative Data Analysis: Step-by-Step Guide (Manual vs. Automatic)
When we conduct qualitative methods of research, need to explain changes in metrics or understand people's opinions, we always turn to qualitative data. Qualitative data is typically generated through:
- Interview transcripts
- Surveys with open-ended questions
- Contact center transcripts
- Texts and documents
- Audio and video recordings
- Observational notes
Compared to quantitative data, which captures structured information, qualitative data is unstructured and has more depth. It can answer our questions, can help formulate hypotheses and build understanding.
It's important to understand the differences between quantitative data & qualitative data . But unfortunately, analyzing qualitative data is difficult. While tools like Excel, Tableau and PowerBI crunch and visualize quantitative data with ease, there are a limited number of mainstream tools for analyzing qualitative data . The majority of qualitative data analysis still happens manually.
That said, there are two new trends that are changing this. First, there are advances in natural language processing (NLP) which is focused on understanding human language. Second, there is an explosion of user-friendly software designed for both researchers and businesses. Both help automate the qualitative data analysis process.
In this post we want to teach you how to conduct a successful qualitative data analysis. There are two primary qualitative data analysis methods; manual & automatic. We will teach you how to conduct the analysis manually, and also, automatically using software solutions powered by NLP. We’ll guide you through the steps to conduct a manual analysis, and look at what is involved and the role technology can play in automating this process.
More businesses are switching to fully-automated analysis of qualitative customer data because it is cheaper, faster, and just as accurate. Primarily, businesses purchase subscriptions to feedback analytics platforms so that they can understand customer pain points and sentiment.

We’ll take you through 5 steps to conduct a successful qualitative data analysis. Within each step we will highlight the key difference between the manual, and automated approach of qualitative researchers. Here's an overview of the steps:
The 5 steps to doing qualitative data analysis
- Gathering and collecting your qualitative data
- Organizing and connecting into your qualitative data
- Coding your qualitative data
- Analyzing the qualitative data for insights
- Reporting on the insights derived from your analysis
What is Qualitative Data Analysis?
Qualitative data analysis is a process of gathering, structuring and interpreting qualitative data to understand what it represents.
Qualitative data is non-numerical and unstructured. Qualitative data generally refers to text, such as open-ended responses to survey questions or user interviews, but also includes audio, photos and video.
Businesses often perform qualitative data analysis on customer feedback. And within this context, qualitative data generally refers to verbatim text data collected from sources such as reviews, complaints, chat messages, support centre interactions, customer interviews, case notes or social media comments.
How is qualitative data analysis different from quantitative data analysis?
Understanding the differences between quantitative & qualitative data is important. When it comes to analyzing data, Qualitative Data Analysis serves a very different role to Quantitative Data Analysis. But what sets them apart?
Qualitative Data Analysis dives into the stories hidden in non-numerical data such as interviews, open-ended survey answers, or notes from observations. It uncovers the ‘whys’ and ‘hows’ giving a deep understanding of people’s experiences and emotions.
Quantitative Data Analysis on the other hand deals with numerical data, using statistics to measure differences, identify preferred options, and pinpoint root causes of issues. It steps back to address questions like "how many" or "what percentage" to offer broad insights we can apply to larger groups.
In short, Qualitative Data Analysis is like a microscope, helping us understand specific detail. Quantitative Data Analysis is like the telescope, giving us a broader perspective. Both are important, working together to decode data for different objectives.
Qualitative Data Analysis methods
Once all the data has been captured, there are a variety of analysis techniques available and the choice is determined by your specific research objectives and the kind of data you’ve gathered. Common qualitative data analysis methods include:
Content Analysis
This is a popular approach to qualitative data analysis. Other qualitative analysis techniques may fit within the broad scope of content analysis. Thematic analysis is a part of the content analysis. Content analysis is used to identify the patterns that emerge from text, by grouping content into words, concepts, and themes. Content analysis is useful to quantify the relationship between all of the grouped content. The Columbia School of Public Health has a detailed breakdown of content analysis .
Narrative Analysis
Narrative analysis focuses on the stories people tell and the language they use to make sense of them. It is particularly useful in qualitative research methods where customer stories are used to get a deep understanding of customers’ perspectives on a specific issue. A narrative analysis might enable us to summarize the outcomes of a focused case study.
Discourse Analysis
Discourse analysis is used to get a thorough understanding of the political, cultural and power dynamics that exist in specific situations. The focus of discourse analysis here is on the way people express themselves in different social contexts. Discourse analysis is commonly used by brand strategists who hope to understand why a group of people feel the way they do about a brand or product.
Thematic Analysis
Thematic analysis is used to deduce the meaning behind the words people use. This is accomplished by discovering repeating themes in text. These meaningful themes reveal key insights into data and can be quantified, particularly when paired with sentiment analysis . Often, the outcome of thematic analysis is a code frame that captures themes in terms of codes, also called categories. So the process of thematic analysis is also referred to as “coding”. A common use-case for thematic analysis in companies is analysis of customer feedback.
Grounded Theory
Grounded theory is a useful approach when little is known about a subject. Grounded theory starts by formulating a theory around a single data case. This means that the theory is “grounded”. Grounded theory analysis is based on actual data, and not entirely speculative. Then additional cases can be examined to see if they are relevant and can add to the original grounded theory.

Challenges of Qualitative Data Analysis
While Qualitative Data Analysis offers rich insights, it comes with its challenges. Each unique QDA method has its unique hurdles. Let’s take a look at the challenges researchers and analysts might face, depending on the chosen method.
- Time and Effort (Narrative Analysis): Narrative analysis, which focuses on personal stories, demands patience. Sifting through lengthy narratives to find meaningful insights can be time-consuming, requires dedicated effort.
- Being Objective (Grounded Theory): Grounded theory, building theories from data, faces the challenges of personal biases. Staying objective while interpreting data is crucial, ensuring conclusions are rooted in the data itself.
- Complexity (Thematic Analysis): Thematic analysis involves identifying themes within data, a process that can be intricate. Categorizing and understanding themes can be complex, especially when each piece of data varies in context and structure. Thematic Analysis software can simplify this process.
- Generalizing Findings (Narrative Analysis): Narrative analysis, dealing with individual stories, makes drawing broad challenging. Extending findings from a single narrative to a broader context requires careful consideration.
- Managing Data (Thematic Analysis): Thematic analysis involves organizing and managing vast amounts of unstructured data, like interview transcripts. Managing this can be a hefty task, requiring effective data management strategies.
- Skill Level (Grounded Theory): Grounded theory demands specific skills to build theories from the ground up. Finding or training analysts with these skills poses a challenge, requiring investment in building expertise.
Benefits of qualitative data analysis
Qualitative Data Analysis (QDA) is like a versatile toolkit, offering a tailored approach to understanding your data. The benefits it offers are as diverse as the methods. Let’s explore why choosing the right method matters.
- Tailored Methods for Specific Needs: QDA isn't one-size-fits-all. Depending on your research objectives and the type of data at hand, different methods offer unique benefits. If you want emotive customer stories, narrative analysis paints a strong picture. When you want to explain a score, thematic analysis reveals insightful patterns
- Flexibility with Thematic Analysis: thematic analysis is like a chameleon in the toolkit of QDA. It adapts well to different types of data and research objectives, making it a top choice for any qualitative analysis.
- Deeper Understanding, Better Products: QDA helps you dive into people's thoughts and feelings. This deep understanding helps you build products and services that truly matches what people want, ensuring satisfied customers
- Finding the Unexpected: Qualitative data often reveals surprises that we miss in quantitative data. QDA offers us new ideas and perspectives, for insights we might otherwise miss.
- Building Effective Strategies: Insights from QDA are like strategic guides. They help businesses in crafting plans that match people’s desires.
- Creating Genuine Connections: Understanding people’s experiences lets businesses connect on a real level. This genuine connection helps build trust and loyalty, priceless for any business.
How to do Qualitative Data Analysis: 5 steps
Now we are going to show how you can do your own qualitative data analysis. We will guide you through this process step by step. As mentioned earlier, you will learn how to do qualitative data analysis manually , and also automatically using modern qualitative data and thematic analysis software.
To get best value from the analysis process and research process, it’s important to be super clear about the nature and scope of the question that’s being researched. This will help you select the research collection channels that are most likely to help you answer your question.
Depending on if you are a business looking to understand customer sentiment, or an academic surveying a school, your approach to qualitative data analysis will be unique.
Once you’re clear, there’s a sequence to follow. And, though there are differences in the manual and automatic approaches, the process steps are mostly the same.
The use case for our step-by-step guide is a company looking to collect data (customer feedback data), and analyze the customer feedback - in order to improve customer experience. By analyzing the customer feedback the company derives insights about their business and their customers. You can follow these same steps regardless of the nature of your research. Let’s get started.
Step 1: Gather your qualitative data and conduct research (Conduct qualitative research)
The first step of qualitative research is to do data collection. Put simply, data collection is gathering all of your data for analysis. A common situation is when qualitative data is spread across various sources.
Classic methods of gathering qualitative data
Most companies use traditional methods for gathering qualitative data: conducting interviews with research participants, running surveys, and running focus groups. This data is typically stored in documents, CRMs, databases and knowledge bases. It’s important to examine which data is available and needs to be included in your research project, based on its scope.
Using your existing qualitative feedback
As it becomes easier for customers to engage across a range of different channels, companies are gathering increasingly large amounts of both solicited and unsolicited qualitative feedback.
Most organizations have now invested in Voice of Customer programs , support ticketing systems, chatbot and support conversations, emails and even customer Slack chats.
These new channels provide companies with new ways of getting feedback, and also allow the collection of unstructured feedback data at scale.
The great thing about this data is that it contains a wealth of valubale insights and that it’s already there! When you have a new question about user behavior or your customers, you don’t need to create a new research study or set up a focus group. You can find most answers in the data you already have.
Typically, this data is stored in third-party solutions or a central database, but there are ways to export it or connect to a feedback analysis solution through integrations or an API.
Utilize untapped qualitative data channels
There are many online qualitative data sources you may not have considered. For example, you can find useful qualitative data in social media channels like Twitter or Facebook. Online forums, review sites, and online communities such as Discourse or Reddit also contain valuable data about your customers, or research questions.
If you are considering performing a qualitative benchmark analysis against competitors - the internet is your best friend. Gathering feedback in competitor reviews on sites like Trustpilot, G2, Capterra, Better Business Bureau or on app stores is a great way to perform a competitor benchmark analysis.
Customer feedback analysis software often has integrations into social media and review sites, or you could use a solution like DataMiner to scrape the reviews.

Step 2: Connect & organize all your qualitative data
Now you all have this qualitative data but there’s a problem, the data is unstructured. Before feedback can be analyzed and assigned any value, it needs to be organized in a single place. Why is this important? Consistency!
If all data is easily accessible in one place and analyzed in a consistent manner, you will have an easier time summarizing and making decisions based on this data.
The manual approach to organizing your data
The classic method of structuring qualitative data is to plot all the raw data you’ve gathered into a spreadsheet.
Typically, research and support teams would share large Excel sheets and different business units would make sense of the qualitative feedback data on their own. Each team collects and organizes the data in a way that best suits them, which means the feedback tends to be kept in separate silos.
An alternative and a more robust solution is to store feedback in a central database, like Snowflake or Amazon Redshift .
Keep in mind that when you organize your data in this way, you are often preparing it to be imported into another software. If you go the route of a database, you would need to use an API to push the feedback into a third-party software.
Computer-assisted qualitative data analysis software (CAQDAS)
Traditionally within the manual analysis approach (but not always), qualitative data is imported into CAQDAS software for coding.
In the early 2000s, CAQDAS software was popularised by developers such as ATLAS.ti, NVivo and MAXQDA and eagerly adopted by researchers to assist with the organizing and coding of data.
The benefits of using computer-assisted qualitative data analysis software:
- Assists in the organizing of your data
- Opens you up to exploring different interpretations of your data analysis
- Allows you to share your dataset easier and allows group collaboration (allows for secondary analysis)
However you still need to code the data, uncover the themes and do the analysis yourself. Therefore it is still a manual approach.

Organizing your qualitative data in a feedback repository
Another solution to organizing your qualitative data is to upload it into a feedback repository where it can be unified with your other data , and easily searchable and taggable. There are a number of software solutions that act as a central repository for your qualitative research data. Here are a couple solutions that you could investigate:
- Dovetail: Dovetail is a research repository with a focus on video and audio transcriptions. You can tag your transcriptions within the platform for theme analysis. You can also upload your other qualitative data such as research reports, survey responses, support conversations, and customer interviews. Dovetail acts as a single, searchable repository. And makes it easier to collaborate with other people around your qualitative research.
- EnjoyHQ: EnjoyHQ is another research repository with similar functionality to Dovetail. It boasts a more sophisticated search engine, but it has a higher starting subscription cost.
Organizing your qualitative data in a feedback analytics platform
If you have a lot of qualitative customer or employee feedback, from the likes of customer surveys or employee surveys, you will benefit from a feedback analytics platform. A feedback analytics platform is a software that automates the process of both sentiment analysis and thematic analysis . Companies use the integrations offered by these platforms to directly tap into their qualitative data sources (review sites, social media, survey responses, etc.). The data collected is then organized and analyzed consistently within the platform.
If you have data prepared in a spreadsheet, it can also be imported into feedback analytics platforms.
Once all this rich data has been organized within the feedback analytics platform, it is ready to be coded and themed, within the same platform. Thematic is a feedback analytics platform that offers one of the largest libraries of integrations with qualitative data sources.

Step 3: Coding your qualitative data
Your feedback data is now organized in one place. Either within your spreadsheet, CAQDAS, feedback repository or within your feedback analytics platform. The next step is to code your feedback data so we can extract meaningful insights in the next step.
Coding is the process of labelling and organizing your data in such a way that you can then identify themes in the data, and the relationships between these themes.
To simplify the coding process, you will take small samples of your customer feedback data, come up with a set of codes, or categories capturing themes, and label each piece of feedback, systematically, for patterns and meaning. Then you will take a larger sample of data, revising and refining the codes for greater accuracy and consistency as you go.
If you choose to use a feedback analytics platform, much of this process will be automated and accomplished for you.
The terms to describe different categories of meaning (‘theme’, ‘code’, ‘tag’, ‘category’ etc) can be confusing as they are often used interchangeably. For clarity, this article will use the term ‘code’.
To code means to identify key words or phrases and assign them to a category of meaning. “I really hate the customer service of this computer software company” would be coded as “poor customer service”.
How to manually code your qualitative data
- Decide whether you will use deductive or inductive coding. Deductive coding is when you create a list of predefined codes, and then assign them to the qualitative data. Inductive coding is the opposite of this, you create codes based on the data itself. Codes arise directly from the data and you label them as you go. You need to weigh up the pros and cons of each coding method and select the most appropriate.
- Read through the feedback data to get a broad sense of what it reveals. Now it’s time to start assigning your first set of codes to statements and sections of text.
- Keep repeating step 2, adding new codes and revising the code description as often as necessary. Once it has all been coded, go through everything again, to be sure there are no inconsistencies and that nothing has been overlooked.
- Create a code frame to group your codes. The coding frame is the organizational structure of all your codes. And there are two commonly used types of coding frames, flat, or hierarchical. A hierarchical code frame will make it easier for you to derive insights from your analysis.
- Based on the number of times a particular code occurs, you can now see the common themes in your feedback data. This is insightful! If ‘bad customer service’ is a common code, it’s time to take action.
We have a detailed guide dedicated to manually coding your qualitative data .

Using software to speed up manual coding of qualitative data
An Excel spreadsheet is still a popular method for coding. But various software solutions can help speed up this process. Here are some examples.
- CAQDAS / NVivo - CAQDAS software has built-in functionality that allows you to code text within their software. You may find the interface the software offers easier for managing codes than a spreadsheet.
- Dovetail/EnjoyHQ - You can tag transcripts and other textual data within these solutions. As they are also repositories you may find it simpler to keep the coding in one platform.
- IBM SPSS - SPSS is a statistical analysis software that may make coding easier than in a spreadsheet.
- Ascribe - Ascribe’s ‘Coder’ is a coding management system. Its user interface will make it easier for you to manage your codes.
Automating the qualitative coding process using thematic analysis software
In solutions which speed up the manual coding process, you still have to come up with valid codes and often apply codes manually to pieces of feedback. But there are also solutions that automate both the discovery and the application of codes.
Advances in machine learning have now made it possible to read, code and structure qualitative data automatically. This type of automated coding is offered by thematic analysis software .
Automation makes it far simpler and faster to code the feedback and group it into themes. By incorporating natural language processing (NLP) into the software, the AI looks across sentences and phrases to identify common themes meaningful statements. Some automated solutions detect repeating patterns and assign codes to them, others make you train the AI by providing examples. You could say that the AI learns the meaning of the feedback on its own.
Thematic automates the coding of qualitative feedback regardless of source. There’s no need to set up themes or categories in advance. Simply upload your data and wait a few minutes. You can also manually edit the codes to further refine their accuracy. Experiments conducted indicate that Thematic’s automated coding is just as accurate as manual coding .
Paired with sentiment analysis and advanced text analytics - these automated solutions become powerful for deriving quality business or research insights.
You could also build your own , if you have the resources!
The key benefits of using an automated coding solution
Automated analysis can often be set up fast and there’s the potential to uncover things that would never have been revealed if you had given the software a prescribed list of themes to look for.
Because the model applies a consistent rule to the data, it captures phrases or statements that a human eye might have missed.
Complete and consistent analysis of customer feedback enables more meaningful findings. Leading us into step 4.
Step 4: Analyze your data: Find meaningful insights
Now we are going to analyze our data to find insights. This is where we start to answer our research questions. Keep in mind that step 4 and step 5 (tell the story) have some overlap . This is because creating visualizations is both part of analysis process and reporting.
The task of uncovering insights is to scour through the codes that emerge from the data and draw meaningful correlations from them. It is also about making sure each insight is distinct and has enough data to support it.
Part of the analysis is to establish how much each code relates to different demographics and customer profiles, and identify whether there’s any relationship between these data points.
Manually create sub-codes to improve the quality of insights
If your code frame only has one level, you may find that your codes are too broad to be able to extract meaningful insights. This is where it is valuable to create sub-codes to your primary codes. This process is sometimes referred to as meta coding.
Note: If you take an inductive coding approach, you can create sub-codes as you are reading through your feedback data and coding it.
While time-consuming, this exercise will improve the quality of your analysis. Here is an example of what sub-codes could look like.

You need to carefully read your qualitative data to create quality sub-codes. But as you can see, the depth of analysis is greatly improved. By calculating the frequency of these sub-codes you can get insight into which customer service problems you can immediately address.
Correlate the frequency of codes to customer segments
Many businesses use customer segmentation . And you may have your own respondent segments that you can apply to your qualitative analysis. Segmentation is the practise of dividing customers or research respondents into subgroups.
Segments can be based on:
- Demographic
- And any other data type that you care to segment by
It is particularly useful to see the occurrence of codes within your segments. If one of your customer segments is considered unimportant to your business, but they are the cause of nearly all customer service complaints, it may be in your best interest to focus attention elsewhere. This is a useful insight!
Manually visualizing coded qualitative data
There are formulas you can use to visualize key insights in your data. The formulas we will suggest are imperative if you are measuring a score alongside your feedback.
If you are collecting a metric alongside your qualitative data this is a key visualization. Impact answers the question: “What’s the impact of a code on my overall score?”. Using Net Promoter Score (NPS) as an example, first you need to:
- Calculate overall NPS
- Calculate NPS in the subset of responses that do not contain that theme
- Subtract B from A
Then you can use this simple formula to calculate code impact on NPS .

You can then visualize this data using a bar chart.
You can download our CX toolkit - it includes a template to recreate this.
Trends over time
This analysis can help you answer questions like: “Which codes are linked to decreases or increases in my score over time?”
We need to compare two sequences of numbers: NPS over time and code frequency over time . Using Excel, calculate the correlation between the two sequences, which can be either positive (the more codes the higher the NPS, see picture below), or negative (the more codes the lower the NPS).
Now you need to plot code frequency against the absolute value of code correlation with NPS. Here is the formula:

The visualization could look like this:

These are two examples, but there are more. For a third manual formula, and to learn why word clouds are not an insightful form of analysis, read our visualizations article .
Using a text analytics solution to automate analysis
Automated text analytics solutions enable codes and sub-codes to be pulled out of the data automatically. This makes it far faster and easier to identify what’s driving negative or positive results. And to pick up emerging trends and find all manner of rich insights in the data.
Another benefit of AI-driven text analytics software is its built-in capability for sentiment analysis, which provides the emotive context behind your feedback and other qualitative textual data therein.
Thematic provides text analytics that goes further by allowing users to apply their expertise on business context to edit or augment the AI-generated outputs.
Since the move away from manual research is generally about reducing the human element, adding human input to the technology might sound counter-intuitive. However, this is mostly to make sure important business nuances in the feedback aren’t missed during coding. The result is a higher accuracy of analysis. This is sometimes referred to as augmented intelligence .

Step 5: Report on your data: Tell the story
The last step of analyzing your qualitative data is to report on it, to tell the story. At this point, the codes are fully developed and the focus is on communicating the narrative to the audience.
A coherent outline of the qualitative research, the findings and the insights is vital for stakeholders to discuss and debate before they can devise a meaningful course of action.
Creating graphs and reporting in Powerpoint
Typically, qualitative researchers take the tried and tested approach of distilling their report into a series of charts, tables and other visuals which are woven into a narrative for presentation in Powerpoint.
Using visualization software for reporting
With data transformation and APIs, the analyzed data can be shared with data visualisation software, such as Power BI or Tableau , Google Studio or Looker. Power BI and Tableau are among the most preferred options.
Visualizing your insights inside a feedback analytics platform
Feedback analytics platforms, like Thematic, incorporate visualisation tools that intuitively turn key data and insights into graphs. This removes the time consuming work of constructing charts to visually identify patterns and creates more time to focus on building a compelling narrative that highlights the insights, in bite-size chunks, for executive teams to review.
Using a feedback analytics platform with visualization tools means you don’t have to use a separate product for visualizations. You can export graphs into Powerpoints straight from the platforms.

Conclusion - Manual or Automated?
There are those who remain deeply invested in the manual approach - because it’s familiar, because they’re reluctant to spend money and time learning new software, or because they’ve been burned by the overpromises of AI.
For projects that involve small datasets, manual analysis makes sense. For example, if the objective is simply to quantify a simple question like “Do customers prefer X concepts to Y?”. If the findings are being extracted from a small set of focus groups and interviews, sometimes it’s easier to just read them
However, as new generations come into the workplace, it’s technology-driven solutions that feel more comfortable and practical. And the merits are undeniable. Especially if the objective is to go deeper and understand the ‘why’ behind customers’ preference for X or Y. And even more especially if time and money are considerations.
The ability to collect a free flow of qualitative feedback data at the same time as the metric means AI can cost-effectively scan, crunch, score and analyze a ton of feedback from one system in one go. And time-intensive processes like focus groups, or coding, that used to take weeks, can now be completed in a matter of hours or days.
But aside from the ever-present business case to speed things up and keep costs down, there are also powerful research imperatives for automated analysis of qualitative data: namely, accuracy and consistency.
Finding insights hidden in feedback requires consistency, especially in coding. Not to mention catching all the ‘unknown unknowns’ that can skew research findings and steering clear of cognitive bias.
Some say without manual data analysis researchers won’t get an accurate “feel” for the insights. However, the larger data sets are, the harder it is to sort through the feedback and organize feedback that has been pulled from different places. And, the more difficult it is to stay on course, the greater the risk of drawing incorrect, or incomplete, conclusions grows.
Though the process steps for qualitative data analysis have remained pretty much unchanged since psychologist Paul Felix Lazarsfeld paved the path a hundred years ago, the impact digital technology has had on types of qualitative feedback data and the approach to the analysis are profound.
If you want to try an automated feedback analysis solution on your own qualitative data, you can get started with Thematic .

Community & Marketing
Tyler manages our community of CX, insights & analytics professionals. Tyler's goal is to help unite insights professionals around common challenges.
We make it easy to discover the customer and product issues that matter.
Unlock the value of feedback at scale, in one platform. Try it for free now!
- Questions to ask your Feedback Analytics vendor
- How to end customer churn for good
- Scalable analysis of NPS verbatims
- 5 Text analytics approaches
- How to calculate the ROI of CX
Our experts will show you how Thematic works, how to discover pain points and track the ROI of decisions. To access your free trial, book a personal demo today.
Recent posts
Watercare is New Zealand's largest water and wastewater service provider. They are responsible for bringing clean water to 1.7 million people in Tamaki Makaurau (Auckland) and safeguarding the wastewater network to minimize impact on the environment. Water is a sector that often gets taken for granted, with drainage and
Become a qualitative theming pro! Creating a perfect code frame is hard, but thematic analysis software makes the process much easier.
Qualtrics is one of the most well-known and powerful Customer Feedback Management platforms. But even so, it has limitations. We recently hosted a live panel where data analysts from two well-known brands shared their experiences with Qualtrics, and how they extended this platform’s capabilities. Below, we’ll share the

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Indian J Anaesth
- v.60(9); 2016 Sep
Basic statistical tools in research and data analysis
Zulfiqar ali.
Department of Anaesthesiology, Division of Neuroanaesthesiology, Sheri Kashmir Institute of Medical Sciences, Soura, Srinagar, Jammu and Kashmir, India
S Bala Bhaskar
1 Department of Anaesthesiology and Critical Care, Vijayanagar Institute of Medical Sciences, Bellary, Karnataka, India
Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise only if proper statistical tests are used. This article will try to acquaint the reader with the basic research tools that are utilised while conducting various studies. The article covers a brief outline of the variables, an understanding of quantitative and qualitative variables and the measures of central tendency. An idea of the sample size estimation, power analysis and the statistical errors is given. Finally, there is a summary of parametric and non-parametric tests used for data analysis.
INTRODUCTION
Statistics is a branch of science that deals with the collection, organisation, analysis of data and drawing of inferences from the samples to the whole population.[ 1 ] This requires a proper design of the study, an appropriate selection of the study sample and choice of a suitable statistical test. An adequate knowledge of statistics is necessary for proper designing of an epidemiological study or a clinical trial. Improper statistical methods may result in erroneous conclusions which may lead to unethical practice.[ 2 ]
Variable is a characteristic that varies from one individual member of population to another individual.[ 3 ] Variables such as height and weight are measured by some type of scale, convey quantitative information and are called as quantitative variables. Sex and eye colour give qualitative information and are called as qualitative variables[ 3 ] [ Figure 1 ].

Classification of variables
Quantitative variables
Quantitative or numerical data are subdivided into discrete and continuous measurements. Discrete numerical data are recorded as a whole number such as 0, 1, 2, 3,… (integer), whereas continuous data can assume any value. Observations that can be counted constitute the discrete data and observations that can be measured constitute the continuous data. Examples of discrete data are number of episodes of respiratory arrests or the number of re-intubations in an intensive care unit. Similarly, examples of continuous data are the serial serum glucose levels, partial pressure of oxygen in arterial blood and the oesophageal temperature.
A hierarchical scale of increasing precision can be used for observing and recording the data which is based on categorical, ordinal, interval and ratio scales [ Figure 1 ].
Categorical or nominal variables are unordered. The data are merely classified into categories and cannot be arranged in any particular order. If only two categories exist (as in gender male and female), it is called as a dichotomous (or binary) data. The various causes of re-intubation in an intensive care unit due to upper airway obstruction, impaired clearance of secretions, hypoxemia, hypercapnia, pulmonary oedema and neurological impairment are examples of categorical variables.
Ordinal variables have a clear ordering between the variables. However, the ordered data may not have equal intervals. Examples are the American Society of Anesthesiologists status or Richmond agitation-sedation scale.
Interval variables are similar to an ordinal variable, except that the intervals between the values of the interval variable are equally spaced. A good example of an interval scale is the Fahrenheit degree scale used to measure temperature. With the Fahrenheit scale, the difference between 70° and 75° is equal to the difference between 80° and 85°: The units of measurement are equal throughout the full range of the scale.
Ratio scales are similar to interval scales, in that equal differences between scale values have equal quantitative meaning. However, ratio scales also have a true zero point, which gives them an additional property. For example, the system of centimetres is an example of a ratio scale. There is a true zero point and the value of 0 cm means a complete absence of length. The thyromental distance of 6 cm in an adult may be twice that of a child in whom it may be 3 cm.
STATISTICS: DESCRIPTIVE AND INFERENTIAL STATISTICS
Descriptive statistics[ 4 ] try to describe the relationship between variables in a sample or population. Descriptive statistics provide a summary of data in the form of mean, median and mode. Inferential statistics[ 4 ] use a random sample of data taken from a population to describe and make inferences about the whole population. It is valuable when it is not possible to examine each member of an entire population. The examples if descriptive and inferential statistics are illustrated in Table 1 .
Example of descriptive and inferential statistics

Descriptive statistics
The extent to which the observations cluster around a central location is described by the central tendency and the spread towards the extremes is described by the degree of dispersion.
Measures of central tendency
The measures of central tendency are mean, median and mode.[ 6 ] Mean (or the arithmetic average) is the sum of all the scores divided by the number of scores. Mean may be influenced profoundly by the extreme variables. For example, the average stay of organophosphorus poisoning patients in ICU may be influenced by a single patient who stays in ICU for around 5 months because of septicaemia. The extreme values are called outliers. The formula for the mean is

where x = each observation and n = number of observations. Median[ 6 ] is defined as the middle of a distribution in a ranked data (with half of the variables in the sample above and half below the median value) while mode is the most frequently occurring variable in a distribution. Range defines the spread, or variability, of a sample.[ 7 ] It is described by the minimum and maximum values of the variables. If we rank the data and after ranking, group the observations into percentiles, we can get better information of the pattern of spread of the variables. In percentiles, we rank the observations into 100 equal parts. We can then describe 25%, 50%, 75% or any other percentile amount. The median is the 50 th percentile. The interquartile range will be the observations in the middle 50% of the observations about the median (25 th -75 th percentile). Variance[ 7 ] is a measure of how spread out is the distribution. It gives an indication of how close an individual observation clusters about the mean value. The variance of a population is defined by the following formula:

where σ 2 is the population variance, X is the population mean, X i is the i th element from the population and N is the number of elements in the population. The variance of a sample is defined by slightly different formula:

where s 2 is the sample variance, x is the sample mean, x i is the i th element from the sample and n is the number of elements in the sample. The formula for the variance of a population has the value ‘ n ’ as the denominator. The expression ‘ n −1’ is known as the degrees of freedom and is one less than the number of parameters. Each observation is free to vary, except the last one which must be a defined value. The variance is measured in squared units. To make the interpretation of the data simple and to retain the basic unit of observation, the square root of variance is used. The square root of the variance is the standard deviation (SD).[ 8 ] The SD of a population is defined by the following formula:

where σ is the population SD, X is the population mean, X i is the i th element from the population and N is the number of elements in the population. The SD of a sample is defined by slightly different formula:

where s is the sample SD, x is the sample mean, x i is the i th element from the sample and n is the number of elements in the sample. An example for calculation of variation and SD is illustrated in Table 2 .
Example of mean, variance, standard deviation

Normal distribution or Gaussian distribution
Most of the biological variables usually cluster around a central value, with symmetrical positive and negative deviations about this point.[ 1 ] The standard normal distribution curve is a symmetrical bell-shaped. In a normal distribution curve, about 68% of the scores are within 1 SD of the mean. Around 95% of the scores are within 2 SDs of the mean and 99% within 3 SDs of the mean [ Figure 2 ].

Normal distribution curve
Skewed distribution
It is a distribution with an asymmetry of the variables about its mean. In a negatively skewed distribution [ Figure 3 ], the mass of the distribution is concentrated on the right of Figure 1 . In a positively skewed distribution [ Figure 3 ], the mass of the distribution is concentrated on the left of the figure leading to a longer right tail.

Curves showing negatively skewed and positively skewed distribution
Inferential statistics
In inferential statistics, data are analysed from a sample to make inferences in the larger collection of the population. The purpose is to answer or test the hypotheses. A hypothesis (plural hypotheses) is a proposed explanation for a phenomenon. Hypothesis tests are thus procedures for making rational decisions about the reality of observed effects.
Probability is the measure of the likelihood that an event will occur. Probability is quantified as a number between 0 and 1 (where 0 indicates impossibility and 1 indicates certainty).
In inferential statistics, the term ‘null hypothesis’ ( H 0 ‘ H-naught ,’ ‘ H-null ’) denotes that there is no relationship (difference) between the population variables in question.[ 9 ]
Alternative hypothesis ( H 1 and H a ) denotes that a statement between the variables is expected to be true.[ 9 ]
The P value (or the calculated probability) is the probability of the event occurring by chance if the null hypothesis is true. The P value is a numerical between 0 and 1 and is interpreted by researchers in deciding whether to reject or retain the null hypothesis [ Table 3 ].
P values with interpretation

If P value is less than the arbitrarily chosen value (known as α or the significance level), the null hypothesis (H0) is rejected [ Table 4 ]. However, if null hypotheses (H0) is incorrectly rejected, this is known as a Type I error.[ 11 ] Further details regarding alpha error, beta error and sample size calculation and factors influencing them are dealt with in another section of this issue by Das S et al .[ 12 ]
Illustration for null hypothesis

PARAMETRIC AND NON-PARAMETRIC TESTS
Numerical data (quantitative variables) that are normally distributed are analysed with parametric tests.[ 13 ]
Two most basic prerequisites for parametric statistical analysis are:
- The assumption of normality which specifies that the means of the sample group are normally distributed
- The assumption of equal variance which specifies that the variances of the samples and of their corresponding population are equal.
However, if the distribution of the sample is skewed towards one side or the distribution is unknown due to the small sample size, non-parametric[ 14 ] statistical techniques are used. Non-parametric tests are used to analyse ordinal and categorical data.
Parametric tests
The parametric tests assume that the data are on a quantitative (numerical) scale, with a normal distribution of the underlying population. The samples have the same variance (homogeneity of variances). The samples are randomly drawn from the population, and the observations within a group are independent of each other. The commonly used parametric tests are the Student's t -test, analysis of variance (ANOVA) and repeated measures ANOVA.
Student's t -test
Student's t -test is used to test the null hypothesis that there is no difference between the means of the two groups. It is used in three circumstances:

where X = sample mean, u = population mean and SE = standard error of mean

where X 1 − X 2 is the difference between the means of the two groups and SE denotes the standard error of the difference.
- To test if the population means estimated by two dependent samples differ significantly (the paired t -test). A usual setting for paired t -test is when measurements are made on the same subjects before and after a treatment.
The formula for paired t -test is:

where d is the mean difference and SE denotes the standard error of this difference.
The group variances can be compared using the F -test. The F -test is the ratio of variances (var l/var 2). If F differs significantly from 1.0, then it is concluded that the group variances differ significantly.
Analysis of variance
The Student's t -test cannot be used for comparison of three or more groups. The purpose of ANOVA is to test if there is any significant difference between the means of two or more groups.
In ANOVA, we study two variances – (a) between-group variability and (b) within-group variability. The within-group variability (error variance) is the variation that cannot be accounted for in the study design. It is based on random differences present in our samples.
However, the between-group (or effect variance) is the result of our treatment. These two estimates of variances are compared using the F-test.
A simplified formula for the F statistic is:

where MS b is the mean squares between the groups and MS w is the mean squares within groups.
Repeated measures analysis of variance
As with ANOVA, repeated measures ANOVA analyses the equality of means of three or more groups. However, a repeated measure ANOVA is used when all variables of a sample are measured under different conditions or at different points in time.
As the variables are measured from a sample at different points of time, the measurement of the dependent variable is repeated. Using a standard ANOVA in this case is not appropriate because it fails to model the correlation between the repeated measures: The data violate the ANOVA assumption of independence. Hence, in the measurement of repeated dependent variables, repeated measures ANOVA should be used.
Non-parametric tests
When the assumptions of normality are not met, and the sample means are not normally, distributed parametric tests can lead to erroneous results. Non-parametric tests (distribution-free test) are used in such situation as they do not require the normality assumption.[ 15 ] Non-parametric tests may fail to detect a significant difference when compared with a parametric test. That is, they usually have less power.
As is done for the parametric tests, the test statistic is compared with known values for the sampling distribution of that statistic and the null hypothesis is accepted or rejected. The types of non-parametric analysis techniques and the corresponding parametric analysis techniques are delineated in Table 5 .
Analogue of parametric and non-parametric tests

Median test for one sample: The sign test and Wilcoxon's signed rank test
The sign test and Wilcoxon's signed rank test are used for median tests of one sample. These tests examine whether one instance of sample data is greater or smaller than the median reference value.
This test examines the hypothesis about the median θ0 of a population. It tests the null hypothesis H0 = θ0. When the observed value (Xi) is greater than the reference value (θ0), it is marked as+. If the observed value is smaller than the reference value, it is marked as − sign. If the observed value is equal to the reference value (θ0), it is eliminated from the sample.
If the null hypothesis is true, there will be an equal number of + signs and − signs.
The sign test ignores the actual values of the data and only uses + or − signs. Therefore, it is useful when it is difficult to measure the values.
Wilcoxon's signed rank test
There is a major limitation of sign test as we lose the quantitative information of the given data and merely use the + or – signs. Wilcoxon's signed rank test not only examines the observed values in comparison with θ0 but also takes into consideration the relative sizes, adding more statistical power to the test. As in the sign test, if there is an observed value that is equal to the reference value θ0, this observed value is eliminated from the sample.
Wilcoxon's rank sum test ranks all data points in order, calculates the rank sum of each sample and compares the difference in the rank sums.
Mann-Whitney test
It is used to test the null hypothesis that two samples have the same median or, alternatively, whether observations in one sample tend to be larger than observations in the other.
Mann–Whitney test compares all data (xi) belonging to the X group and all data (yi) belonging to the Y group and calculates the probability of xi being greater than yi: P (xi > yi). The null hypothesis states that P (xi > yi) = P (xi < yi) =1/2 while the alternative hypothesis states that P (xi > yi) ≠1/2.
Kolmogorov-Smirnov test
The two-sample Kolmogorov-Smirnov (KS) test was designed as a generic method to test whether two random samples are drawn from the same distribution. The null hypothesis of the KS test is that both distributions are identical. The statistic of the KS test is a distance between the two empirical distributions, computed as the maximum absolute difference between their cumulative curves.
Kruskal-Wallis test
The Kruskal–Wallis test is a non-parametric test to analyse the variance.[ 14 ] It analyses if there is any difference in the median values of three or more independent samples. The data values are ranked in an increasing order, and the rank sums calculated followed by calculation of the test statistic.
Jonckheere test
In contrast to Kruskal–Wallis test, in Jonckheere test, there is an a priori ordering that gives it a more statistical power than the Kruskal–Wallis test.[ 14 ]
Friedman test
The Friedman test is a non-parametric test for testing the difference between several related samples. The Friedman test is an alternative for repeated measures ANOVAs which is used when the same parameter has been measured under different conditions on the same subjects.[ 13 ]
Tests to analyse the categorical data
Chi-square test, Fischer's exact test and McNemar's test are used to analyse the categorical or nominal variables. The Chi-square test compares the frequencies and tests whether the observed data differ significantly from that of the expected data if there were no differences between groups (i.e., the null hypothesis). It is calculated by the sum of the squared difference between observed ( O ) and the expected ( E ) data (or the deviation, d ) divided by the expected data by the following formula:

A Yates correction factor is used when the sample size is small. Fischer's exact test is used to determine if there are non-random associations between two categorical variables. It does not assume random sampling, and instead of referring a calculated statistic to a sampling distribution, it calculates an exact probability. McNemar's test is used for paired nominal data. It is applied to 2 × 2 table with paired-dependent samples. It is used to determine whether the row and column frequencies are equal (that is, whether there is ‘marginal homogeneity’). The null hypothesis is that the paired proportions are equal. The Mantel-Haenszel Chi-square test is a multivariate test as it analyses multiple grouping variables. It stratifies according to the nominated confounding variables and identifies any that affects the primary outcome variable. If the outcome variable is dichotomous, then logistic regression is used.
SOFTWARES AVAILABLE FOR STATISTICS, SAMPLE SIZE CALCULATION AND POWER ANALYSIS
Numerous statistical software systems are available currently. The commonly used software systems are Statistical Package for the Social Sciences (SPSS – manufactured by IBM corporation), Statistical Analysis System ((SAS – developed by SAS Institute North Carolina, United States of America), R (designed by Ross Ihaka and Robert Gentleman from R core team), Minitab (developed by Minitab Inc), Stata (developed by StataCorp) and the MS Excel (developed by Microsoft).
There are a number of web resources which are related to statistical power analyses. A few are:
- StatPages.net – provides links to a number of online power calculators
- G-Power – provides a downloadable power analysis program that runs under DOS
- Power analysis for ANOVA designs an interactive site that calculates power or sample size needed to attain a given power for one effect in a factorial ANOVA design
- SPSS makes a program called SamplePower. It gives an output of a complete report on the computer screen which can be cut and paste into another document.
It is important that a researcher knows the concepts of the basic statistical methods used for conduct of a research study. This will help to conduct an appropriately well-designed study leading to valid and reliable results. Inappropriate use of statistical techniques may lead to faulty conclusions, inducing errors and undermining the significance of the article. Bad statistics may lead to bad research, and bad research may lead to unethical practice. Hence, an adequate knowledge of statistics and the appropriate use of statistical tests are important. An appropriate knowledge about the basic statistical methods will go a long way in improving the research designs and producing quality medical research which can be utilised for formulating the evidence-based guidelines.
Financial support and sponsorship
Conflicts of interest.
There are no conflicts of interest.
Numbers, Facts and Trends Shaping Your World
Read our research on:
Full Topic List
Regions & Countries
- Publications
- Our Methods
- Short Reads
- Tools & Resources
Read Our Research On:
How Pew Research Center will report on generations moving forward
Journalists, researchers and the public often look at society through the lens of generation, using terms like Millennial or Gen Z to describe groups of similarly aged people. This approach can help readers see themselves in the data and assess where we are and where we’re headed as a country.
Pew Research Center has been at the forefront of generational research over the years, telling the story of Millennials as they came of age politically and as they moved more firmly into adult life . In recent years, we’ve also been eager to learn about Gen Z as the leading edge of this generation moves into adulthood.
But generational research has become a crowded arena. The field has been flooded with content that’s often sold as research but is more like clickbait or marketing mythology. There’s also been a growing chorus of criticism about generational research and generational labels in particular.
Recently, as we were preparing to embark on a major research project related to Gen Z, we decided to take a step back and consider how we can study generations in a way that aligns with our values of accuracy, rigor and providing a foundation of facts that enriches the public dialogue.
A typical generation spans 15 to 18 years. As many critics of generational research point out, there is great diversity of thought, experience and behavior within generations.
We set out on a yearlong process of assessing the landscape of generational research. We spoke with experts from outside Pew Research Center, including those who have been publicly critical of our generational analysis, to get their take on the pros and cons of this type of work. We invested in methodological testing to determine whether we could compare findings from our earlier telephone surveys to the online ones we’re conducting now. And we experimented with higher-level statistical analyses that would allow us to isolate the effect of generation.
What emerged from this process was a set of clear guidelines that will help frame our approach going forward. Many of these are principles we’ve always adhered to , but others will require us to change the way we’ve been doing things in recent years.
Here’s a short overview of how we’ll approach generational research in the future:
We’ll only do generational analysis when we have historical data that allows us to compare generations at similar stages of life. When comparing generations, it’s crucial to control for age. In other words, researchers need to look at each generation or age cohort at a similar point in the life cycle. (“Age cohort” is a fancy way of referring to a group of people who were born around the same time.)
When doing this kind of research, the question isn’t whether young adults today are different from middle-aged or older adults today. The question is whether young adults today are different from young adults at some specific point in the past.
To answer this question, it’s necessary to have data that’s been collected over a considerable amount of time – think decades. Standard surveys don’t allow for this type of analysis. We can look at differences across age groups, but we can’t compare age groups over time.
Another complication is that the surveys we conducted 20 or 30 years ago aren’t usually comparable enough to the surveys we’re doing today. Our earlier surveys were done over the phone, and we’ve since transitioned to our nationally representative online survey panel , the American Trends Panel . Our internal testing showed that on many topics, respondents answer questions differently depending on the way they’re being interviewed. So we can’t use most of our surveys from the late 1980s and early 2000s to compare Gen Z with Millennials and Gen Xers at a similar stage of life.
This means that most generational analysis we do will use datasets that have employed similar methodologies over a long period of time, such as surveys from the U.S. Census Bureau. A good example is our 2020 report on Millennial families , which used census data going back to the late 1960s. The report showed that Millennials are marrying and forming families at a much different pace than the generations that came before them.
Even when we have historical data, we will attempt to control for other factors beyond age in making generational comparisons. If we accept that there are real differences across generations, we’re basically saying that people who were born around the same time share certain attitudes or beliefs – and that their views have been influenced by external forces that uniquely shaped them during their formative years. Those forces may have been social changes, economic circumstances, technological advances or political movements.
When we see that younger adults have different views than their older counterparts, it may be driven by their demographic traits rather than the fact that they belong to a particular generation.
The tricky part is isolating those forces from events or circumstances that have affected all age groups, not just one generation. These are often called “period effects.” An example of a period effect is the Watergate scandal, which drove down trust in government among all age groups. Differences in trust across age groups in the wake of Watergate shouldn’t be attributed to the outsize impact that event had on one age group or another, because the change occurred across the board.
Changing demographics also may play a role in patterns that might at first seem like generational differences. We know that the United States has become more racially and ethnically diverse in recent decades, and that race and ethnicity are linked with certain key social and political views. When we see that younger adults have different views than their older counterparts, it may be driven by their demographic traits rather than the fact that they belong to a particular generation.
Controlling for these factors can involve complicated statistical analysis that helps determine whether the differences we see across age groups are indeed due to generation or not. This additional step adds rigor to the process. Unfortunately, it’s often absent from current discussions about Gen Z, Millennials and other generations.
When we can’t do generational analysis, we still see value in looking at differences by age and will do so where it makes sense. Age is one of the most common predictors of differences in attitudes and behaviors. And even if age gaps aren’t rooted in generational differences, they can still be illuminating. They help us understand how people across the age spectrum are responding to key trends, technological breakthroughs and historical events.
Each stage of life comes with a unique set of experiences. Young adults are often at the leading edge of changing attitudes on emerging social trends. Take views on same-sex marriage , for example, or attitudes about gender identity .
Many middle-aged adults, in turn, face the challenge of raising children while also providing care and support to their aging parents. And older adults have their own obstacles and opportunities. All of these stories – rooted in the life cycle, not in generations – are important and compelling, and we can tell them by analyzing our surveys at any given point in time.
When we do have the data to study groups of similarly aged people over time, we won’t always default to using the standard generational definitions and labels. While generational labels are simple and catchy, there are other ways to analyze age cohorts. For example, some observers have suggested grouping people by the decade in which they were born. This would create narrower cohorts in which the members may share more in common. People could also be grouped relative to their age during key historical events (such as the Great Recession or the COVID-19 pandemic) or technological innovations (like the invention of the iPhone).
By choosing not to use the standard generational labels when they’re not appropriate, we can avoid reinforcing harmful stereotypes or oversimplifying people’s complex lived experiences.
Existing generational definitions also may be too broad and arbitrary to capture differences that exist among narrower cohorts. A typical generation spans 15 to 18 years. As many critics of generational research point out, there is great diversity of thought, experience and behavior within generations. The key is to pick a lens that’s most appropriate for the research question that’s being studied. If we’re looking at political views and how they’ve shifted over time, for example, we might group people together according to the first presidential election in which they were eligible to vote.
With these considerations in mind, our audiences should not expect to see a lot of new research coming out of Pew Research Center that uses the generational lens. We’ll only talk about generations when it adds value, advances important national debates and highlights meaningful societal trends.
- Age & Generations
- Demographic Research
- Generation X
- Generation Z
- Generations
- Greatest Generation
- Methodological Research
- Millennials
- Silent Generation

Kim Parker is director of social trends research at Pew Research Center
How Teens and Parents Approach Screen Time
Who are you the art and science of measuring identity, u.s. centenarian population is projected to quadruple over the next 30 years, older workers are growing in number and earning higher wages, teens, social media and technology 2023, most popular.
1615 L St. NW, Suite 800 Washington, DC 20036 USA (+1) 202-419-4300 | Main (+1) 202-857-8562 | Fax (+1) 202-419-4372 | Media Inquiries
Research Topics
- Coronavirus (COVID-19)
- Economy & Work
- Family & Relationships
- Gender & LGBTQ
- Immigration & Migration
- International Affairs
- Internet & Technology
- News Habits & Media
- Non-U.S. Governments
- Other Topics
- Politics & Policy
- Race & Ethnicity
- Email Newsletters
ABOUT PEW RESEARCH CENTER Pew Research Center is a nonpartisan fact tank that informs the public about the issues, attitudes and trends shaping the world. It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It is a subsidiary of The Pew Charitable Trusts .
Copyright 2024 Pew Research Center
Terms & Conditions
Privacy Policy
Cookie Settings
Reprints, Permissions & Use Policy

An official website of the United States government
Here’s how you know
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Report Fraud
- Get Consumer Alerts
- Search the Legal Library
- Submit Public Comments
Take action
- Report an antitrust violation
- File adjudicative documents
- Find banned debt collectors
- View competition guidance
- Competition Matters Blog
New HSR thresholds and filing fees for 2024
View all Competition Matters Blog posts
We work to advance government policies that protect consumers and promote competition.
View Policy
Search or browse the Legal Library
Find legal resources and guidance to understand your business responsibilities and comply with the law.
Browse legal resources
- Find policy statements
- Submit a public comment

Vision and Priorities
Memo from Chair Lina M. Khan to commission staff and commissioners regarding the vision and priorities for the FTC.
Technology Blog
Consumer facing applications: a quote book from the tech summit on ai.
View all Technology Blog posts
Advice and Guidance
Learn more about your rights as a consumer and how to spot and avoid scams. Find the resources you need to understand how consumer protection law impacts your business.
- Report fraud
- Report identity theft
- Register for Do Not Call
- Sign up for consumer alerts
- Get Business Blog updates
- Get your free credit report
- Find refund cases
- Order bulk publications
- Consumer Advice
- Shopping and Donating
- Credit, Loans, and Debt
- Jobs and Making Money
- Unwanted Calls, Emails, and Texts
- Identity Theft and Online Security
- Business Guidance
- Advertising and Marketing
- Credit and Finance
- Privacy and Security
- By Industry
- For Small Businesses
- Browse Business Guidance Resources
- Business Blog
Servicemembers: Your tool for financial readiness
Visit militaryconsumer.gov
Get consumer protection basics, plain and simple
Visit consumer.gov
Learn how the FTC protects free enterprise and consumers
Visit Competition Counts
Looking for competition guidance?
- Competition Guidance
News and Events
Latest news, williams-sonoma will pay record $3.17 million civil penalty for violating ftc made in usa order.
View News and Events
Upcoming Event
Older adults and fraud: what you need to know.
View more Events
Sign up for the latest news
Follow us on social media
--> --> --> --> -->

Playing it Safe: Explore the FTC's Top Video Game Cases
Learn about the FTC's notable video game cases and what our agency is doing to keep the public safe.
Latest Data Visualization

FTC Refunds to Consumers
Explore refund statistics including where refunds were sent and the dollar amounts refunded with this visualization.
About the FTC
Our mission is protecting the public from deceptive or unfair business practices and from unfair methods of competition through law enforcement, advocacy, research, and education.
Learn more about the FTC

Meet the Chair
Lina M. Khan was sworn in as Chair of the Federal Trade Commission on June 15, 2021.
Chair Lina M. Khan
Looking for legal documents or records? Search the Legal Library instead.
- Cases and Proceedings
- Premerger Notification Program
- Merger Review
- Anticompetitive Practices
- Competition and Consumer Protection Guidance Documents
- Warning Letters
- Consumer Sentinel Network
- Criminal Liaison Unit
- FTC Refund Programs
- Notices of Penalty Offenses
- Advocacy and Research
- Advisory Opinions
- Cooperation Agreements
- Federal Register Notices
- Public Comments
- Policy Statements
- International
- Office of Technology Blog
- Military Consumer
- Consumer.gov
- Bulk Publications
- Data and Visualizations
- Stay Connected
- Commissioners and Staff
- Bureaus and Offices
- Budget and Strategy
- Office of Inspector General
- Careers at the FTC
Fact Sheet on FTC’s Proposed Final Noncompete Rule
- Competition
- Office of Policy Planning
- Bureau of Competition
The following outline provides a high-level overview of the FTC’s proposed final rule :
- Specifically, the final rule provides that it is an unfair method of competition—and therefore a violation of Section 5 of the FTC Act—for employers to enter into noncompetes with workers after the effective date.
- Fewer than 1% of workers are estimated to be senior executives under the final rule.
- Specifically, the final rule defines the term “senior executive” to refer to workers earning more than $151,164 annually who are in a “policy-making position.”
- Reduced health care costs: $74-$194 billion in reduced spending on physician services over the next decade.
- New business formation: 2.7% increase in the rate of new firm formation, resulting in over 8,500 additional new businesses created each year.
- This reflects an estimated increase of about 3,000 to 5,000 new patents in the first year noncompetes are banned, rising to about 30,000-53,000 in the tenth year.
- This represents an estimated increase of 11-19% annually over a ten-year period.
- The average worker’s earnings will rise an estimated extra $524 per year.
The Federal Trade Commission develops policy initiatives on issues that affect competition, consumers, and the U.S. economy. The FTC will never demand money, make threats, tell you to transfer money, or promise you a prize. Follow the FTC on social media , read consumer alerts and the business blog , and sign up to get the latest FTC news and alerts .
Press Release Reference
Contact information, media contact.
Victoria Graham Office of Public Affairs 415-848-5121
The independent source for health policy research, polling, and news.
A New Use for Wegovy Opens the Door to Medicare Coverage for Millions of People with Obesity
Juliette Cubanski , Tricia Neuman , Nolan Sroczynski , and Anthony Damico Published: Apr 24, 2024
The FDA recently approved a new use for Wegovy (semaglutide), the blockbuster anti-obesity drug, to reduce the risk of heart attacks and stroke in people with cardiovascular disease who are overweight or obese. Wegovy belongs to a class of medications called GLP-1 (glucagon-like peptide-1) agonists that were initially approved to treat type 2 diabetes but are also highly effective anti-obesity drugs. The new FDA-approved indication for Wegovy paves the way for Medicare coverage of this drug and broader coverage by other insurers. Medicare is currently prohibited by law from covering Wegovy and other medications when used specifically for obesity. However, semaglutide is covered by Medicare as a treatment for diabetes, branded as Ozempic.
What does the FDA’s decision mean for Medicare coverage of Wegovy?
The FDA’s decision opens the door to Medicare coverage of Wegovy, which was first approved by the FDA as an anti-obesity medication. Soon after the FDA’s approval of the new use for Wegovy, the Centers for Medicare & Medicaid Services (CMS) issued a memo indicating that Medicare Part D plans can add Wegovy to their formularies now that it has a medically-accepted indication that is not specifically excluded from Medicare coverage . Because Wegovy is a self-administered injectable drug, coverage will be provided under Part D , Medicare’s outpatient drug benefit offered by private stand-alone drug plans and Medicare Advantage plans, not Part B, which covers physician-administered drugs.
How many Medicare beneficiaries could be eligible for coverage of Wegovy for its new use?

Of these 3.6 million beneficiaries, 1.9 million also had diabetes (other than Type 1) and may already have been eligible for Medicare coverage of GLP-1s as diabetes treatments prior to the FDA’s approval of the new use of Wegovy.
Not all people who are eligible based on the new indication are likely to take Wegovy, however. Some might be dissuaded by the potential side effects and adverse reactions . Out-of-pocket costs could also be a barrier. Based on the list price of $1,300 per month (not including rebates or other discounts negotiated by pharmacy benefit managers), Wegovy could be covered as a specialty tier drug, where Part D plans are allowed to charge coinsurance of 25% to 33%. Because coinsurance amounts are pegged to the list price, Medicare beneficiaries required to pay coinsurance could face monthly costs of $325 to $430 before they reach the new cap on annual out-of-pocket drug spending established by the Inflation Reduction Act – around $3,300 in 2024, based on brand drugs only, and $2,000 in 2025. But even paying $2,000 out of pocket would still be beyond the reach of many people with Medicare who live on modest incomes . Ultimately, how much beneficiaries pay out of pocket will depend on Part D plan coverage and formulary tier placement of Wegovy.
Further, some people may have difficulty accessing Wegovy if Part D plans apply prior authorization and step therapy tools to manage costs and ensure appropriate use. These factors could have a dampening effect on use by Medicare beneficiaries, even among the target population.
When will Medicare Part D plans begin covering Wegovy?
Some Part D plans have already announced that they will begin covering Wegovy this year, although it is not yet clear how widespread coverage will be in 2024. While Medicare drug plans can add new drugs to their formularies during the year to reflect new approvals and expanded indications, plans are not required to cover every new drug that comes to market. Part D plans are required to cover at least two drugs in each category or class and all or substantially all drugs in six protected classes . However, facing a relatively high price and potentially large patient population for Wegovy, many Part D plans might be reluctant to expand coverage now, since they can’t adjust their premiums mid-year to account for higher costs associated with use of this drug. So, broader coverage in 2025 could be more likely.
How might expanded coverage of Wegovy affect Medicare spending?
The impact on Medicare spending associated with expanded coverage of Wegovy will depend in part on how many Part D plans add coverage for it and the extent to which plans apply restrictions on use like prior authorization; how many people who qualify to take the drug use it; and negotiated prices paid by plans. For example, if plans receive a 50% rebate on the list price of $1,300 per month (or $15,600 per year), that could mean annual net costs per person around $7,800. If 10% of the target population (an estimated 360,000 people) uses Wegovy for a full year, that would amount to additional net Medicare Part D spending of $2.8 billion for one year for this one drug alone.
It’s possible that Medicare could select semaglutide for drug price negotiation as early as 2025, based on the earliest FDA approval of Ozempic in late 2017 . For small-molecule drugs like semaglutide, at least seven years must have passed from its FDA approval date to be eligible for selection, and for drugs with multiple FDA approvals, CMS will use the earliest approval date to make this determination. If semaglutide is selected for negotiation next year, a negotiated price would be available beginning in 2027. This could help to lower Medicare and out-of-pocket spending on semaglutide products, including Wegovy as well as Ozempic and Rybelsus, the oral formulation approved for type 2 diabetes. As of 2022, gross Medicare spending on Ozempic alone placed it sixth among the 10 top-selling drugs in Medicare Part D, with annual gross spending of $4.6 billion, based on KFF analysis . This estimate does not include rebates, which Medicare’s actuaries estimated to be 31.5% overall in 2022 but could be as high as 69% for Ozempic, according to one estimate.
What does this mean for Medicare coverage of anti-obesity drugs?
For now, use of GLP-1s specifically for obesity continues to be excluded from Medicare coverage by law. But the FDA’s decision signals a turning point for broader Medicare coverage of GLP-1s since Wegovy can now be used to reduce the risk of heart attack and stroke by people with cardiovascular disease and obesity or overweight, and not only as an anti-obesity drug. And more pathways to Medicare coverage could open up if these drugs gain FDA approval for other uses . For example, Eli Lilly has just reported clinical trial results showing the benefits of its GLP-1, Zepbound (tirzepatide), in reducing the occurrence of sleep apnea events among people with obesity or overweight. Lilly reportedly plans to seek FDA approval for this use and if approved, the drug would be the first pharmaceutical treatment on the market for sleep apnea.
If more Medicare beneficiaries with obesity or overweight gain access to GLP-1s based on other approved uses for these medications, that could reduce the cost of proposed legislation to lift the statutory prohibition on Medicare coverage of anti-obesity drugs. This is because the Congressional Budget Office (CBO), Congress’s official scorekeeper for proposed legislation, would incorporate the cost of coverage for these other uses into its baseline estimates for Medicare spending, which means that the incremental cost of changing the law to allow Medicare coverage for anti-obesity drugs would be lower than it would be without FDA’s approval of these drugs for other uses. Ultimately how widely Medicare Part D coverage of GLP-1s expands could have far-reaching effects on people with obesity and on Medicare spending.
- Medicare Part D
- Chronic Diseases
- Heart Disease
- Medicare Advantage
news release
- An Estimated 1 in 4 Medicare Beneficiaries With Obesity or Overweight Could Be Eligible for Medicare Coverage of Wegovy, an Anti-Obesity Drug, to Reduce Heart Risk
Also of Interest
- An Overview of the Medicare Part D Prescription Drug Benefit
- FAQs about the Inflation Reduction Act’s Medicare Drug Price Negotiation Program
- What Could New Anti-Obesity Drugs Mean for Medicare?
- Medicare Spending on Ozempic and Other GLP-1s Is Skyrocketing
IMAGES
VIDEO
COMMENTS
The purpose of data interpretation is to make sense of complex data by analyzing and drawing insights from it. The process of data interpretation involves identifying patterns and trends, making comparisons, and drawing conclusions based on the data. The ultimate goal of data interpretation is to use the insights gained from the analysis to ...
Data interpretation is the process of reviewing data and arriving at relevant conclusions using various analytical research methods. Data analysis assists researchers in categorizing, manipulating data, and summarizing data to answer critical questions. LEARN ABOUT: Level of Analysis. In business terms, the interpretation of data is the ...
2. Brand Analysis Dashboard. Next, in our list of data interpretation examples, we have a template that shows the answers to a survey on awareness for Brand D. The sample size is listed on top to get a perspective of the data, which is represented using interactive charts and graphs. **click to enlarge**.
The quantitative data interpretation method is used to analyze quantitative data, which is also known as numerical data. This data type contains numbers and is therefore analyzed with the use of numbers and not texts. Quantitative data are of 2 main types, namely; discrete and continuous data. Continuous data is further divided into interval ...
The role of data interpretation. The data collection process is just one part of research, and one that can often provide a lot of data without any easy answers that instantly stick out to researchers or their audiences. An example of data that requires an interpretation process is a corpus, or a large body of text, meant to represent some language use (e.g., literature, conversation).
Qualitative Data Interpretation Method. This is a method for breaking down or analyzing so-called qualitative data, also known as categorical data. It is important to note that no bar graphs or line charts are used in this method. Instead, they rely on text. Because qualitative data is collected through person-to-person techniques, it isn't ...
Data interpretation is a crucial part of statistical analysis, as it is used to draw conclusions and make recommendations based on the data. When interpreting data, it is important to consider the context in which the data was collected. This includes factors such as the sample size, the sampling method, and the population being studied.
Data interpretation is a crucial aspect of data analysis and enables organizations to turn large amounts of data into actionable insights. The guide covered the definition, importance, types, methods, benefits, process, analysis, tools, use cases, and best practices of data interpretation. As technology continues to advance, the methods and ...
Step 1: Write your hypotheses and plan your research design. To collect valid data for statistical analysis, you first need to specify your hypotheses and plan out your research design. Writing statistical hypotheses. The goal of research is often to investigate a relationship between variables within a population. You start with a prediction ...
Interpretation of qualitative data can be presented as a narrative. The themes identified from the research can be organised and integrated with themes in the existing literature to give further weight and meaning to the research. The interpretation should also state if the aims and objectives of the research were met.
Data analysis is a comprehensive method of inspecting, cleansing, transforming, and modeling data to discover useful information, draw conclusions, and support decision-making. It is a multifaceted process involving various techniques and methodologies to interpret data from various sources in different formats, both structured and unstructured.
Data analysis: A complex and challenging process. Though it may sound straightforward to take 150 years of air temperature data and describe how global climate has changed, the process of analyzing and interpreting those data is actually quite complex. Consider the range of temperatures around the world on any given day in January (see Figure 2): In Johannesburg, South Africa, where it is ...
Abstract. This essay addresses a wide range of concepts related to interpretation in qualitative research, examines the meaning and importance of interpretation in qualitative inquiry, and explores the ways methodology, data, and the self/researcher as instrument interact and impact interpretive processes.
It is important to know w hat kind of data you are planning to collect or analyse as this w ill. affect your analysis method. A 12 step approach to quantitative data analysis. Step 1: Start with ...
Definition of research in data analysis: According to LeCompte and Schensul, research data analysis is a process used by researchers to reduce data to a story and interpret it to derive insights. The data analysis process helps reduce a large chunk of data into smaller fragments, which makes sense. Three essential things occur during the data ...
For many researchers unfamiliar with qualitative research, determining how to conduct qualitative analyses is often quite challenging. Part of this challenge is due to the seemingly limitless approaches that a qualitative researcher might leverage, as well as simply learning to think like a qualitative researcher when analyzing data. From framework analysis (Ritchie & Spencer, 1994) to content ...
Factor 1 - Data type. The first thing you need to consider is the type of data you've collected (or the type of data you will collect). By data types, I'm referring to the four levels of measurement - namely, nominal, ordinal, interval and ratio. If you're not familiar with this lingo, check out the video below.
Turning monitoring data into useful information a process that involves several steps: 1) Data Entry : This involves getting your raw data into a computer so that you can store it and retrieve it for analysis. It includes two steps: a. Entry: Data should be entered into a computer data management application. b.
Let's get started with step one. 1. Step one: Defining the question. The first step in any data analysis process is to define your objective. In data analytics jargon, this is sometimes called the 'problem statement'. Defining your objective means coming up with a hypothesis and figuring how to test it.
From Analysis to Interpretation in Qualitative Studies. Data Analysis. Sep 1, 2023. by Janet Salmons, PhD Research Community Manager for Sage Methodspace. Data analysis can only get you so far - then you need to make sense of what you have found. This stage of interpretation can be challenging for qualitative researchers.
Step 1: Gather your qualitative data and conduct research (Conduct qualitative research) The first step of qualitative research is to do data collection. Put simply, data collection is gathering all of your data for analysis. A common situation is when qualitative data is spread across various sources.
Abstract. Statistical methods involved in carrying out a study include planning, designing, collecting data, analysing, drawing meaningful interpretation and reporting of the research findings. The statistical analysis gives meaning to the meaningless numbers, thereby breathing life into a lifeless data. The results and inferences are precise ...
from this study. The analysis and interpretation of data is carried out in two phases. The. first part, which is based on the results of the questionnaire, deals with a quantitative. analysis of data. The second, which is based on the results of the interview and focus group. discussions, is a qualitative interpretation.
2Review Data. Once you've established the basis of the disagreement, revisit the data together. Scrutinize your methods and results with a critical eye. It's essential to ensure that your ...
Pew Research Center has deep roots in U.S. public opinion research. Launched initially as a project focused primarily on U.S. policy and politics in the early 1990s, the Center has grown over time to study a wide range of topics vital to explaining America to itself and to the world.Our hallmarks: a rigorous approach to methodological quality, complete transparency as to our methods, and a ...
The analysis relies on statistics published by the FBI, which we accessed through the Crime Data Explorer, and the Bureau of Justice Statistics (BJS), which we accessed through the National Crime Victimization Survey data analysis tool. To measure public attitudes about crime in the U.S., we relied on survey data from Pew Research Center and ...
When we do have the data to study groups of similarly aged people over time, we won't always default to using the standard generational definitions and labels. ... It conducts public opinion polling, demographic research, media content analysis and other empirical social science research. Pew Research Center does not take policy positions. It ...
This report highlights persistent racial and ethnic disparities in health care across the United States. These disparities are fueled by inequities in access to high-quality care that affect health outcomes. Advancing equity in health and health care should be a top priority of health care leaders and policymakers.
Fewer than 1% of workers are estimated to be senior executives under the final rule. Specifically, the final rule defines the term "senior executive" to refer to workers earning more than $151,164 annually who are in a "policy-making position.". The FTC estimates that banning noncompetes will result in: Reduced health care costs: $74 ...
The independent source for health policy research, polling, and news. menu ... Based on KFF analysis of Medicare data from 2020, an estimated 7% of Medicare beneficiaries, or 3.6 million overall ...